Ćwiczenie — tworzenie i trenowanie sieci neuronowej
W tej lekcji użyjesz interfejsu Keras do utworzenia i wytrenowania sieci neuronowej, która analizuje tekst pod kątem tonacji. Aby móc wytrenować sieć neuronową, potrzebujesz danych, na których można przeprowadzić trenowanie. Zamiast pobierać zewnętrzny zestaw danych, użyjesz zestawu danych IMDB movie reviews sentiment classification dołączonego do interfejsu Keras. Zestaw danych IMDB zawiera 50 000 recenzji filmów, które zostały indywidualnie ocenione jako pozytywne (1) lub negatywne (0). Na ten zestaw danych składa się 25 000 recenzji na potrzeby trenowania i 25 000 recenzji na potrzeby testowania. Tonacja wyrażana w tych recenzjach jest bazą, na podstawie której Twoja sieć neuronowa przeanalizuje zaprezentowany tekst i wygeneruje wyniki na potrzeby tonacji.
Zestaw danych IMDB jest jednym z kilku przydatnych zestawów danych dołączonych do interfejsu Keras. Aby uzyskać pełną listę wbudowanych zestawów danych, zobacz https://keras.io/datasets/.
Wpisz lub wklej następujący kod do pierwszej komórki notesu i kliknij przycisk Uruchom (lub naciśnij klawisze Shift+Enter), aby wykonać go, a następnie dodaj nową komórkę poniżej:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)Ten kod ładuje dołączony do interfejsu Keras zestaw danych IMDB i tworzy słownik, mapując słowa ze wszystkich 50 000 recenzji na liczby całkowite wskazujące względną częstotliwość występowania słowa. Do poszczególnych słów przypisano unikatowe liczby całkowite. Najczęściej spotykane słowo ma przypisaną liczbę 1, drugie z kolei najczęściej występujące słowo ma przypisaną liczbę 2 itd. Funkcja
load_datazwraca również parę krotek zawierających recenzje filmów (w tym przykładziex_trainix_test) oraz jedynki i zera klasyfikujące te recenzje jako pozytywne lub negatywne (y_trainiy_test).Upewnij się, że widać komunikat „Using TensorFlow backend” (Korzystanie z zaplecza TensorFlow) wskazujący, że interfejs Keras używa narzędzia TensorFlow jako zaplecza.
Ładowanie zestawu danych IMDB
Jeżeli chcesz, aby interfejs Keras używał jako zaplecza zestawu Microsoft Cognitive Toolkit, znanego także jako CNTK, dodaj kilka wierszy kodu na początku notesu. Aby uzyskać przykład, zobacz CNTK and Keras in Azure Notebooks (CNTK i Keras w usłudze Azure Notebooks).
Co właściwie ładuje funkcja
load_data? Zmienna o nazwiex_trainto lista 25 000 list, z których każda reprezentuje jedną recenzję filmu. (x_testjest również listą 25 000 list reprezentujących 25 000 przeglądów.x_trainBędą one używane do trenowania, ax_testbędą używane do testowania). Ale wewnętrzne listy — te reprezentujące recenzje filmów — nie zawierają słów; zawierają liczby całkowite. Poniżej przedstawiono, jak opisano je w dokumentacji interfejsu Keras:
Powód, dla którego wewnętrzne listy zawierają liczby zamiast tekstu, jest taki, że sieci neuronowe nie trenuje się za pomocą słów tylko liczb. Dokładnie mówiąc, trenuje się je za pomocą tensorów. W tym przypadku każda recenzja jest 1-wymiarowym tensorem (wyobraź go sobie jako 1-wymiarową tablicę) zawierającym liczby całkowite identyfikujące słowa składające się na recenzję. Aby to zademonstrować, wpisz następującą instrukcję języka Python do pustej komórki, a następnie wykonaj ją, aby zobaczyć liczby całkowite reprezentujące pierwszą recenzję z zestawu szkoleniowego:
x_train[0]
Liczby całkowite składające się na pierwszą recenzję z zestawu szkoleniowego IMDB
Pierwsza liczba na liście — 1 — nie reprezentuje wcale słowa. Oznacza ona początek recenzji i jest taka sama dla wszystkich recenzji w zestawie danych. Liczby 0 i 2 są również zarezerwowane. Od pozostałych liczb należy odjąć 3, aby zamapować liczbę całkowitą w recenzji na odpowiednią liczbę całkowitą w słowniku. Druga liczba — 14 — odwołuje się do słowa odpowiadającego liczbie 11 w słowniku. Trzecia liczba reprezentuje słowo przypisane do liczby 19 w słowniku i tak dalej.
Zastanawiasz się, jak wygląda słownik? Wykonaj następującą instrukcję w nowej komórce notesu:
imdb.get_word_index()Pokazano tylko podzbiór pozycji słownika. Cały słownik zawiera ponad 88 000 słów oraz liczb całkowitych, które im odpowiadają. Wyświetlane tutaj dane wyjściowe prawdopodobnie będą się różniły od danych wyjściowych na Twoim ekranie, ponieważ słownik jest generowany od nowa po każdym wywołaniu funkcji
load_data.
Mapowanie słów na liczby całkowite w słowniku
Jak już wiesz, każda recenzja w zestawie danych jest kodowana jako zbiór liczb całkowitych, a nie słów. Czy jest możliwe odkodowanie recenzji i zobaczenie jej oryginalnego tekstu? Wprowadź następujące instrukcje do nowej komórki i wykonaj je, aby wyświetlić pierwszą recenzję w zmiennej
x_trainw formacie tekstowym:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))W danych wyjściowych znak ">" oznacza początek przeglądu, podczas gdy znak "?" oznacza wyrazy, które nie należą do najczęściej występujących 10 000 wyrazów w zestawie danych. Te „nieznane” słowa są reprezentowane przez liczby 2 na liście liczb całkowitych reprezentujących recenzję. Czy pamiętasz parametr
num_wordsprzekazany do funkcjiload_data? To tutaj odgrywa on swoją rolę. Nie zmniejsza on rozmiaru słownika, ale ogranicza zakres liczb całkowitych używanych do kodowania recenzji.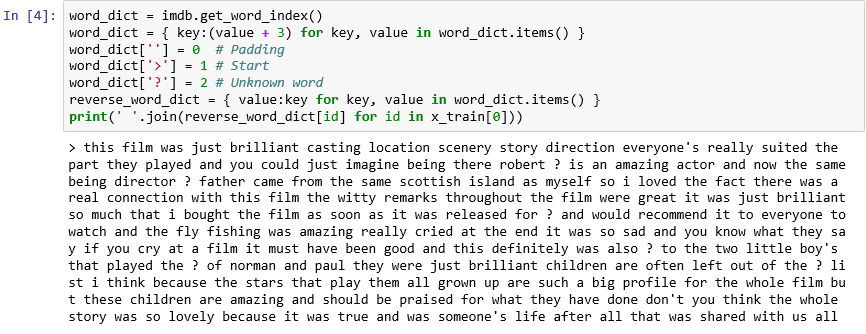
Pierwsza recenzja w formacie tekstowym
Recenzje są „wyczyszczone” w takim sensie, że wszystkie litery zostały przekształcone w małe litery i usunięto znaki interpunkcyjne. Nie są one jednak gotowe do trenowania sieci neuronowej na potrzeby analizowania tekstu pod kątem tonacji. W przypadku trenowania sieci neuronowej za pomocą kolekcji tensorów każdy tensor powinien być takiej samej długości. Obecnie listy reprezentujące recenzje w zmiennych
x_trainix_testmają różne długości.Na szczęście interfejs Keras zawiera funkcję, która pobiera listę list jako dane wejściowe i konwertuje wewnętrzne listy do określonej długości obcinając je w razie potrzeby lub dopełniając zerami. Wprowadź następujący kod w notesie, a następnie uruchom go, aby wymusić zmianę długości wszystkich list reprezentujących recenzje filmów w zmiennych
x_trainix_testna 500 liczb całkowitych:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)Teraz, po przygotowaniu danych trenowania i testowania, można utworzyć model! Uruchom następujący kod w notesie, aby utworzyć sieć neuronową, która przeprowadzi analizę tonacji:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())Sprawdź, czy dane wyjściowe wyglądają następująco:
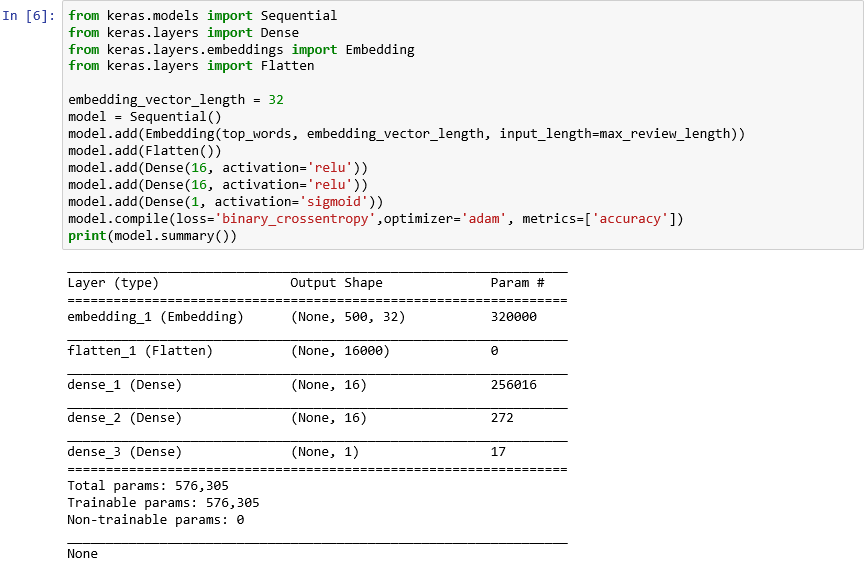
Tworzenie sieci neuronowej za pomocą interfejsu Keras
Ten kod jest kluczowy w kwestii sposobu konstruowania sieci neuronowej za pomocą interfejsu Keras. Najpierw tworzone są wystąpienia obiektu
Sequentialreprezentujące „sekwencyjny” model składający się z kompleksowego stosu warstw, w którym dane wyjściowe z jednej warstwy stają się danymi wejściowymi dla następnej.Kilka następnych instrukcji dodaje warstwy do modelu. Pierwszą jest warstwa osadzania, która ma kluczowe znaczenie dla sieci neuronowych przetwarzających słowa. Warstwa osadzania zasadniczo mapuje wielowymiarowe tablice zawierające indeksy liczb całkowitych reprezentujących słowa na tablice liczb zmiennoprzecinkowych zawierające mniej wymiarów. Ta warstwa umożliwia także identyczne traktowanie słów o podobnym znaczeniu. Pełny opis przetwarzania osadzonych słów wykracza poza zakres tego laboratorium, ale możesz dowiedzieć się więcej z artykułu Why You Need to Start Using Embedding Layers (Dlaczego należy rozpocząć korzystanie z warstw osadzania). Jeśli wolisz bardziej naukowe wyjaśnienie, zapoznaj się z dokumentem Efficient Estimation of Word Representations in Vector Space (Wydajne szacowanie reprezentacji słów w przestrzeni wektorowej). Wywołanie warstwy Flatten po dodaniu warstwy osadzania przekształca dane wyjściowe w dane wejściowe dla następnej warstwy.
Następne trzy warstwy dodane do modelu są warstwami gęstymi znanymi również jako warstwy w pełni połączone. Są to tradycyjne warstwy, które są często używane w sieciach neuronowych. Każda warstwa zawiera n węzłów lub neuronów, a każdy neuron odbiera dane wejściowe z każdego neuronu w poprzedniej warstwie, stąd termin "w pełni połączony". Są to te warstwy, które pozwalają sieci neuronowej "uczyć się" na podstawie danych wejściowych przez iteracyjne odgadywanie danych wyjściowych, sprawdzanie wyników i dostrajanie połączeń w celu uzyskania lepszych wyników. Dwie pierwsze gęste warstwy w tej sieci zawierają po 16 neuronów każda. Ta liczba została wybrana arbitralnie. Można zwiększyć dokładność modelu, eksperymentując z różnymi rozmiarami. Ostatnia gęsta warstwa zawiera tylko jeden neuron, ponieważ ostatecznym celem sieci jest określenie jednej przewidywanej wartości wyjściowej — to znaczy tonacji z wynikiem od 0,0 do 1,0.
Wynikiem jest sieć neuronowa przedstawiona poniżej. Sieć zawiera warstwę danych wejściowych, warstwę danych wyjściowych i dwie warstwy ukryte (gęste warstwy zawierające po 16 neuronów). Dla porównania niektóre współczesne, bardziej zaawansowane sieci neuronowe składają się z ponad 100 warstw. Przykładem jest sieć ResNet-152 firmy Microsoft Research, której dokładność identyfikowania obiektów na zdjęciach czasami wykracza poza możliwości człowieka. Można utworzyć sieć ResNet-152 za pomocą interfejsu Keras, ale aby tego dokonać, byłby potrzebny klaster komputerów wyposażonych w procesory GPU do trenowania od podstaw.
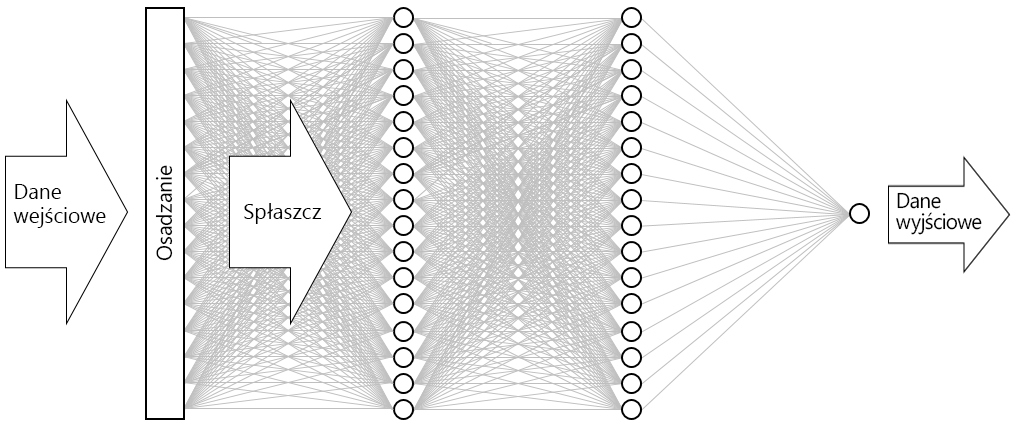
Wizualizacja sieci neuronowej
Wywołanie funkcji compile „kompiluje” model przez określenie ważnych parametrów, takich jak wybór optymalizatora i metryk, których należy użyć do ocenienia dokładności modelu w każdym kroku trenowania. Trenowanie rozpoczyna się dopiero po wywołaniu funkcji
fitmodelu, dlatego wykonanie funkcjicompiletrwa zwykle szybko.Teraz wywołaj funkcję fit w celu wytrenowania sieci neuronowej:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)Trenowanie powinno zająć około 6 minut, czyli nieco więcej niż 1 minutę na każdą epokę. Parametr
epochs=5informuje interfejs Keras, że w modelu powinno się odbyć 5 przebiegów do przodu i do tyłu. Podczas każdego przebiegu model uczy się na danych szkoleniowych i mierzy („waliduje”), z jaką skutecznością przebiega trenowanie przy użyciu danych testowych. Następnie dokonuje korekt i wraca do następnego przebiegu lub epoki. Znajduje to odzwierciedlenie w danych wyjściowych funkcjifit, które pokazują dokładność trenowania (acc) i dokładność walidacji (val_acc) dla każdego epoki.Parametr
batch_size=128informuje interfejs Keras, aby jednorazowo użyć 128 przykładów szkoleniowych do trenowania sieci. Partie o większych rozmiarach skracają czas trenowania (w każdej epoce jest wymagana mniejsza liczba przebiegów do przetworzenia wszystkich danych szkoleniowych), ale partie o mniejszych rozmiarach czasami zwiększają dokładność. Po ukończeniu tego laboratorium możesz tu wrócić i spróbować ponownie przetrenować model za pomocą partii zawierających 32 przykłady, aby zobaczyć, jaki będzie to miało wpływ, jeśli w ogóle będzie miało, na dokładności modelu. Czas trenowania wydłuży się mniej więcej dwukrotnie.
Trenowanie modelu
Ten model jest nietypowy, ponieważ dobrze się trenuje za pomocą zaledwie kilku epok. Dokładność trenowania szybko powiększa się do blisko 100%, podczas gdy dokładność walidacji wzrasta do epoki lub dwóch, a następnie spłaszcza się. Zazwyczaj nie chcesz trenować modelu dłużej niż jest to wymagane, aby te dokładności ustabilizowały się. Występuje ryzyko wystąpienia nadmiernego dopasowania, co przejawia się tym, że model zachowuje się dobrze z danymi testowymi, ale gorzej z rzeczywistymi danymi. Jedną z oznak nadmiernego dopasowania modelu jest rosnąca rozbieżność między dokładnością trenowania i dokładnością walidacji. Aby zapoznać się z doskonałym wprowadzeniem do nadmiernego dopasowania, zobacz Overfitting in Machine Learning: What It Is and How to Prevent It (Overfitting in Machine Learning: What It Is and How to Prevent It).
Aby zwizualizować zmiany w dokładności trenowania i walidacji jako postęp trenowania, wykonaj następujące instrukcje w nowej komórce notesu:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()Dane dotyczące dokładności pochodzą z obiektu
historyzwróconego przez funkcjęfitmodelu. Czy w oparciu o widoczny wykres uważasz, że należy zalecić zwiększenie, zmniejszenie czy pozostawienie takiej samej liczby epok trenowania?Innym sposobem wykrycia nadmiernego dopasowania jest porównywanie utraty trenowania z utratą walidacji w miarę postępu trenowania. Tego typu problemy z optymalizacją występują podczas minimalizowania funkcji utraty. Więcej informacji znajduje się tutaj. Jeśli dla danej epoki utrata trenowania jest o wiele większa niż utrata walidacji, może to być dowodem na nadmierne dopasowanie. W poprzednim kroku użyliśmy właściwości
accival_accwłaściwościhistoryobiektuhistoryw celu wykreślenia dokładności trenowania i dokładności walidacji. Ta sama właściwość zawiera również wartości o nazwielossival_lossreprezentujące odpowiednio utratę trenowania i utratę walidacji. Jak należy zmodyfikować powyższy kod, aby utworzyć wykres podobny do poniższego?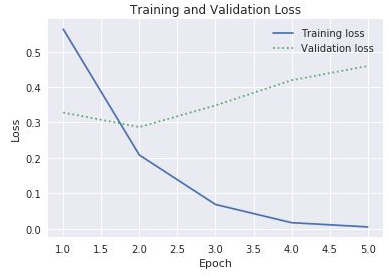
Utrata trenowania i walidacji
Biorąc pod uwagę, że rozbieżność między utratą trenowania i walidacji zaczyna się zwiększać w trzeciej epoce, co należałoby odpowiedzieć komuś, kto zaleca zwiększenie liczby epok do 10 lub 20?
Na koniec wywołaj metodę
evaluatemodelu, aby zmierzyć dokładność, z jaką model jest w stanie określić ilościowo tonację wyrażoną w tekstowych danych testowych zawartych w zmiennychx_test(recenzje) iy_test(zera i jedynki, czyli „etykiety” wskazujące, które recenzje są pozytywne, a które negatywne):scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))Co to jest obliczana dokładność modelu?
Prawdopodobnie osiągnięto dokładność na poziomie od 85% do 90%. Jest to wartość akceptowalna, biorąc pod uwagę, że model został utworzony od podstaw (w przeciwieństwie do używania wstępnie wytrenowanej sieci neuronowej), a czas trenowania był krótki nawet bez procesora GPU. Możliwe jest uzyskanie dokładności na poziomie 95% lub wyższym przy użyciu alternatywnych architektur sieci neuronowych, w szczególności takich jak rekurencyjne sieci neuronowe (RNN), które wykorzystują warstwy długiej krótkoterminowej pamięci (LSTM). Interfejs Keras ułatwia tworzenie takich sieci, ale czas ich trenowania może się wydłużać wykładniczo. Utworzony model stanowi rozsądny kompromis między dokładnością i czasem trenowania. Jednak jeśli chcesz dowiedzieć się więcej o tworzeniu sieci RNN przy użyciu interfejsu Keras, zobacz Understanding LSTM and its Quick Implementation in Keras for Sentiment Analysis (Warstwy LSTM i ich szybka implementacja w interfejsie Keras na potrzeby analizy tonacji).