Uczenie maszynowe do przetwarzania obrazów
Możliwość stosowania filtrów do stosowania efektów do obrazów jest przydatna w zadaniach przetwarzania obrazów, takich jak w przypadku oprogramowania do edycji obrazów. Jednak celem przetwarzania obrazów jest często wyodrębnianie znaczenia lub przynajmniej praktycznych szczegółowych informacji z obrazów; które wymaga utworzenia modeli uczenia maszynowego, które są szkolone do rozpoznawania funkcji na podstawie dużych ilości istniejących obrazów.
Napiwek
W tej lekcji założono, że znasz podstawowe zasady uczenia maszynowego i masz koncepcyjną wiedzę na temat uczenia głębokiego z sieciami neuronowymi. Jeśli dopiero zaczynasz korzystać z uczenia maszynowego, rozważ ukończenie modułu Podstawy uczenia maszynowego w witrynie Microsoft Learn.
Konwolucyjne sieci neuronowe (CNN)
Jedną z najpopularniejszych architektur modelu uczenia maszynowego do przetwarzania obrazów jest splotowa sieć neuronowa (CNN), typu architektury uczenia głębokiego. Sieci CNN używają filtrów do wyodrębniania map cech liczbowych z obrazów, a następnie przekazywania wartości cech do modelu uczenia głębokiego w celu wygenerowania przewidywanej etykiety. Na przykład w scenariuszu klasyfikacji obrazów etykieta reprezentuje główny temat obrazu (innymi słowy, co to jest obraz?). Możesz wytrenować model CNN na obrazach różnych rodzajów owoców (takich jak jabłko, banan i pomarańcza), aby przewidywana etykieta była typem owocu na danym obrazie.
Podczas procesu treningowego dla sieci CNN jądra filtrów są początkowo definiowane przy użyciu losowo generowanych wartości wagowych. Następnie w miarę postępu procesu trenowania przewidywania modeli są oceniane względem znanych wartości etykiet, a wagi filtrów są dostosowywane w celu zwiększenia dokładności. W końcu wytrenowany model klasyfikacji obrazów owoców używa wag filtrów, które najlepiej wyodrębniają cechy, które pomagają zidentyfikować różne rodzaje owoców.
Na poniższym diagramie przedstawiono sposób działania sieci CNN dla modelu klasyfikacji obrazów:
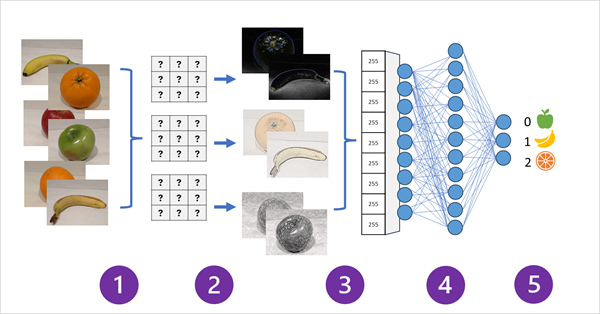
- Obrazy ze znanymi etykietami (na przykład 0: jabłko, 1: banan lub 2: pomarańczowy) są przekazywane do sieci w celu wytrenowania modelu.
- Co najmniej jedna warstwa filtrów służy do wyodrębniania funkcji z każdego obrazu, ponieważ jest on podawany za pośrednictwem sieci. Jądra filtru zaczynają się od losowo przypisanych wag i generują tablice wartości liczbowych o nazwie mapy cech.
- Mapy funkcji są spłaszczone w jednowymiarową tablicę wartości cech.
- Wartości funkcji są wprowadzane do w pełni połączonej sieci neuronowej.
- Warstwa wyjściowa sieci neuronowej używa softmax lub podobnej funkcji, aby wygenerować wynik zawierający wartość prawdopodobieństwa dla każdej możliwej klasy, na przykład [0.2, 0.5, 0.3].
Podczas trenowania prawdopodobieństwa danych wyjściowych są porównywane z rzeczywistą etykietą klasy — na przykład obraz bananu (klasa 1) powinien mieć wartość [0.0, 1.0, 0.0]. Różnica między przewidywanymi i rzeczywistymi wynikami klasy służy do obliczania straty w modelu, a wagi w w pełni połączonej sieci neuronowej oraz jądra filtrów w warstwach wyodrębniania cech są modyfikowane w celu zmniejszenia straty.
Proces trenowania powtarza się przez wiele epok do czasu uzyskania optymalnego zestawu wag. Następnie wagi są zapisywane i model może służyć do przewidywania etykiet dla nowych obrazów, dla których etykieta jest nieznana.
Notatka
Architektury sieci CNN zwykle obejmują wiele warstw filtrów splotowych i dodatkowych warstw, aby zmniejszyć rozmiar map funkcji, ograniczyć wyodrębnione wartości i w inny sposób manipulować wartościami funkcji. Te warstwy zostały pominięte w tym uproszczonym przykładzie, aby skupić się na kluczowej koncepcji, która polega na tym, że filtry są używane do wyodrębniania cech liczbowych z obrazów, które są następnie używane w sieci neuronowej do przewidywania etykiet obrazów.
Transformatory i modele wielomodalne
Sieci CNN są podstawą rozwiązań do przetwarzania obrazów od wielu lat. Chociaż są one często używane do rozwiązywania problemów z klasyfikacją obrazów zgodnie z wcześniejszym opisem, są one również podstawą bardziej złożonych modeli przetwarzania obrazów. Na przykład modele wykrywania obiektów łączą warstwy ekstrakcji cech CNN z identyfikacją obszarów zainteresowania na obrazach w celu zlokalizowania wielu klas obiektów na tym samym obrazie.
Transformatory
Większość postępów w przetwarzaniu obrazów w ciągu dziesięcioleci są napędzane przez ulepszenia modeli opartych na sieciach CNN. Jednak w innej dyscyplinie sztucznej inteligencji — przetwarzania języka naturalnego (NLP), inny typ architektury sieci neuronowej, nazywany transformerem, umożliwił opracowywanie zaawansowanych modeli językowych. Transformatory działają poprzez przetwarzanie ogromnych ilości danych i kodowanie tokenów (reprezentujących poszczególne wyrazy lub frazy) jako wektorowe osadzenia (tablice wartości liczbowych). Osadzanie można traktować jako reprezentujące zestaw wymiarów, które każdy z nich reprezentuje jakiś atrybut semantyczny tokenu. Osadzanie jest tworzone w taki sposób, że tokeny, które są często używane w tym samym kontekście, są bliżej siebie wymiarowo niż niepowiązane wyrazy.
W prostym przykładzie na poniższym diagramie przedstawiono kilka wyrazów zakodowanych jako wektory trójwymiarowe i wykreślionych w przestrzeni 3D:
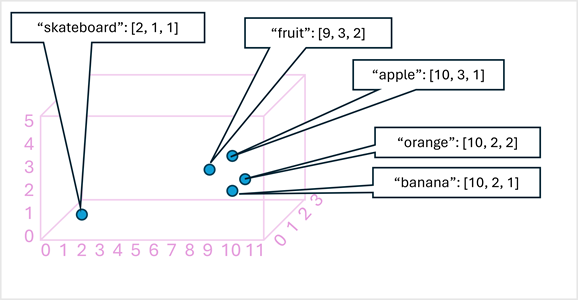
Tokeny, które są semantycznie podobne, są kodowane w podobnych pozycjach, tworząc semantyczny model języka, który umożliwia tworzenie zaawansowanych rozwiązań NLP do analizy tekstu, tłumaczenia, generowania języka i innych zadań.
Notatka
Użyliśmy tylko trzech wymiarów, ponieważ jest to łatwe do wizualizacji. W rzeczywistości kodery w sieciach przekształcania tworzą wektory o wielu innych wymiarach, definiując złożone relacje semantyczne między tokenami na podstawie obliczeń algebraicznych liniowych. Matematyka jest złożona, podobnie jak architektura modelu przekształcania. Naszym celem jest po prostu zapewnienie koncepcyjnego zrozumienia, jak kodowanie tworzy model, który ujmuje relacje między bytami.
Modele wielomodalne
Sukces transformerów jako sposobu tworzenia modeli językowych skłonił badaczy sztucznej inteligencji do rozważenia, czy to samo podejście byłoby skuteczne w przypadku danych obrazowych. Wynikiem jest rozwój wielomodalnych modeli , w których model jest trenowany przy użyciu dużego zbioru obrazów z podpisami, bez stałych etykiet . Koder obrazu wyodrębnia funkcje z obrazów na podstawie wartości pikseli i łączy je z osadzaniem tekstu utworzonym przez koder języka. Ogólny model ujmuje relacje między osadzaniem tokenów języka naturalnego a cechami obrazu, jak pokazano tutaj.
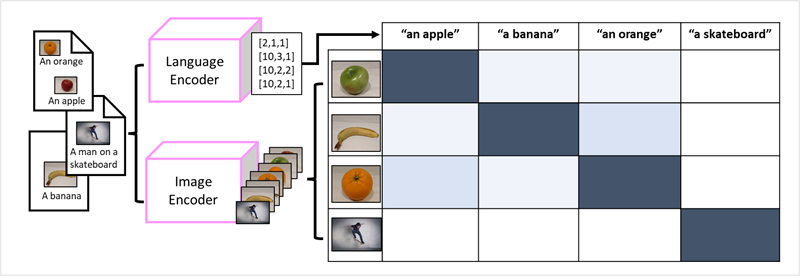
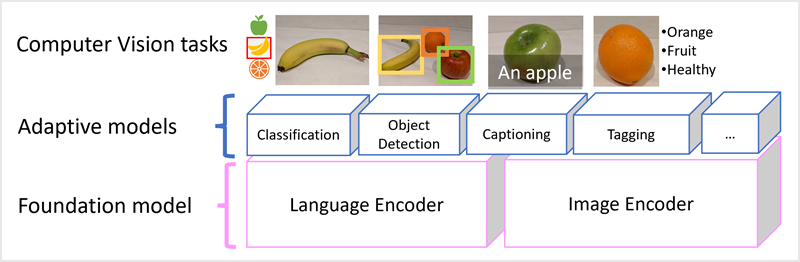
Model microsoft Florence jest tylko takim modelem. Trenowane na podstawie ogromnych ilości obrazów z podpisami z Internetu, obejmuje zarówno enkoder języka, jak i enkoder obrazu. Florence jest przykładem modelu bazowego . Innymi słowy, wstępnie wytrenowany ogólny model, na którym można utworzyć wiele adaptacyjnych modeli na potrzeby zadań specjalistycznych. Na przykład można użyć Florencji jako modelu podstawowego dla modeli adaptacyjnych, które wykonują:
- klasyfikacja obrazów: identyfikowanie kategorii, do której należy obraz.
- wykrywanie obiektów: lokalizowanie pojedynczych obiektów na obrazie.
- captioning: Generowanie odpowiednich opisów obrazów.
- Tagowanie: kompilowanie listy odpowiednich tagów tekstowych dla obrazu.
Modele wielomodalne, takie jak Florence, są ogólnie najnowocześniejsze w przetwarzaniu obrazów i sztucznej inteligencji i oczekuje się, że będą napędzać postępy w rodzajach rozwiązań, które sztuczna inteligencja umożliwia.