Pojęcia dotyczące skalowalności
Przed znalezieniem rozwiązania do skalowania należy zrozumieć, jaka jest skalowalność i jak ma zastosowanie do aplikacji Kubernetes.
W tej lekcji zapoznamy się z niektórymi pojęciami dotyczącymi skalowalności.
Skalowalność
Skalowalność opisuje zdolność aplikacji lub systemu do obsługi rosnącej ilości pracy przez dodanie do niej większej liczby zasobów.
W naszym przykładowym scenariuszu ilość pracy, której dotyczy wzrost, to liczba żądań klientów. Ilość dodanych zasobów można przedstawić na dwa sposoby: skalowalność w pionie i skalowalność poziomą.
Skalowalność pionowa
Skalowalność w pionie lub skalowanie w górę odnosi się do skalowania systemu przez dodanie większej ilości zasobów fizycznych, takich jak pamięć lub moc procesora CPU. Jeśli na przykład witryna internetowa twojej firmy zużywa zbyt dużo pamięci, możesz zaktualizować wystąpienie maszyny wirtualnej, aby uwzględnić więcej pamięci przy zachowaniu tej samej aplikacji źródłowej.
Krótko mówiąc, skalowanie w pionie polega na zwiększeniu rozmiaru maszyny wirtualnej przy zachowaniu tej samej liczby aplikacji. Takie podejście jest przydatne, jeśli masz monolityczne aplikacje, które wymagają dużej mocy obliczeniowej, ale są zbyt kosztowne, aby podzielić się na mniejsze części. Te aplikacje są w większości hostowane na maszynach wirtualnych, a nie w systemach rozproszonych.
Pomimo bardziej zarządzanych kosztów bardzo duże maszyny wirtualne mogą stać się bardzo kosztowne. Koszt dodawania większej mocy obliczeniowej jest wyższy niż koszt duplikowania małych maszyn wirtualnych. Istnieje górny limit liczby zasobów, które można dodać do pojedynczej maszyny wirtualnej, co oznacza, że po osiągnięciu górnej granicy należy ostatecznie zduplikować maszynę wirtualną.
Skalowalność w poziomie
Skalowalność w poziomie lub skalowanie w poziomie odnosi się do skalowania systemu przez duplikowanie aplikacji i równoważenie obciążenia w wystąpieniach aplikacji.
Skalowanie w poziomie jest przydatne w przypadku aplikacji rozproszonych, takich jak wdrożone w usłudze AKS, i systemów bezstanowych, ponieważ można uruchamiać kilka kontenerów z tą samą aplikacją na jednej maszynie wirtualnej. Skalowanie w górę umożliwia wyodrębnianie większości zasobów podczas płacenia za pojedynczą maszynę wirtualną.
W naszym przykładowym scenariuszu witryna firmy jest bezstanowa. Oznacza to, że skalowanie w górę jest najlepszym sposobem działania. Platforma Kubernetes udostępnia wbudowany zasób o nazwie HorizontalPodAutoscaler (HPA), który umożliwia skalowanie wdrożeń w poziomie.
Ręczna skalowalność na platformie Kubernetes
Zanim omówimy rozwiązanie HPA, sprawdźmy, jak ręcznie skalować aplikację Kubernetes.
Każde wdrożenie jest powiązane z innym zasobem o nazwie ReplicaSet. Zestaw replik jest odpowiedzialny za utrzymywanie "żądanego stanu repliki" i skalowanie rzeczywistej aplikacji w lub na wyjęcie, aby zachować żądany stan tak samo jak rzeczywisty. Liczbę replik we wdrożeniu można kontrolować za pomocą spec.replicas klucza w specyfikacji wdrożenia. Ten klucz ustawia liczbę żądanych replik w bazowym zestawie replik i wymusza zachowanie tej liczby replik w danym momencie przez kontroler replikacji.
Możesz również kontrolować liczbę replik we wdrożeniu kubectl scale deploy/contoso-website --replicas <number> za pomocą polecenia . To polecenie dynamicznie zmienia liczbę żądanych replik we wdrożeniu i skaluje aplikację w poziomie lub w poziomie.
HorizontalPodAutoscaler (HPA)
HpA to natywny zasób Kubernetes w wersji 1.8 lub nowszej, który zapewnia skalowalność poziomą zasobników w klastrze. Monitoruje interfejs API metryk co 30 sekund pod kątem wszelkich zmian w żądanej liczbie replik. Jeśli żądana liczba replik różni się od bieżącej liczby replik, menedżer kontrolera, który zarządza obiektami HPA, skaluje wdrożenie w poziomie lub w poziomie.
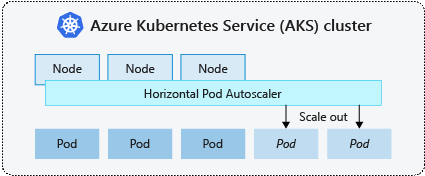
Narzędzia HPA współpracują z grupą interfejsów autoscaling API na platformie Kubernetes. Istnieją dwie wersje tej grupy interfejsów API: v1 i v2. Wersja v1 umożliwia skalowanie wdrożenia tylko na podstawie metryk procesora CPU. Wersja v2 umożliwia natywne monitorowanie procesora CPU i pamięci. W tym module używamy v2 wersji.
Każde narzędzie HPA jest dołączone do odwołania do skali, które jest zdefiniowane w spec.scaleTargetRef kluczu manifestu HPA. To odwołanie skalowania musi mieć bazowe zasobniki do skalowania, w przeciwnym razie hpa nie działa, ponieważ nie można zastosować skalowania do obiektów, których nie można skalować, takich jak DaemonSets.
Ważne jest, aby każdy zasobnik miał żądanie zasobu ustawione w specyfikacji. Algorytm HPA nie może poprawnie obliczyć metryk i określić wykorzystanie zasobów bez tego ustawienia. Ten limit można ustawić za pomocą spec.template.spec.containers[].resources klucza w manifeście wdrożenia, jak pokazano w poniższym przykładzie:
spec:
template:
spec:
containers:
- resources:
requests:
cpu: 250m
memory: 256M
limits:
cpu: 500m
memory: 512M
Przykładowy manifest HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50