Koncepcja — wdrażanie aplikacji
Przed wdrożeniem aplikacji na platformie Kubernetes przejrzyjmy wdrożenia platformy Kubernetes i omówimy ich ograniczenia w naszym scenariuszu.
Co to są wdrożenia platformy Kubernetes?
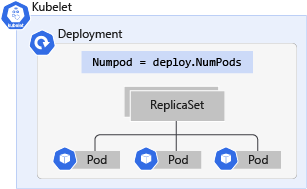
Wdrożenie Kubernetes to ewolucja podów. Wdrożenia opakowują zasobniki w inteligentne obiekty, które umożliwiają im skalowanie w poziomie. Możesz łatwo zduplikować i skalować swoją aplikację, aby obsłużyć większe obciążenie bez potrzeby konfigurowania skomplikowanych reguł sieciowych.
Wdrożenia umożliwiają aktualizowanie aplikacji bez przestojów przez zmianę tagu obrazu. Aktualizowanie wdrożenia wyłącza aplikacje online jeden po drugim i zastępuje je najnowszą wersją zamiast usuwać wszystkie aplikacje i tworzyć nowe, co oznacza, że wdrożenie może zaktualizować zasobniki w nim bez widocznego wpływu na dostępność.
pl-PL: Pomimo, że istnieje wiele korzyści związanych z używaniem Deployments w porównaniu do zasobników, nie są one w stanie odpowiednio sprostać naszemu scenariuszowi.
Ten scenariusz obejmuje aplikację sterowaną zdarzeniami, która odbiera dużą liczbę zdarzeń w różnym czasie. Bez obiektu KEDA Scaler lub HPA należy ręcznie dostosować liczbę replik, aby przetworzyć liczbę zdarzeń i skalować w dół wdrożenie, gdy obciążenie powróci do normalnego.
Przykładowy manifest wdrożenia
Oto przykładowy fragment naszego manifestu wdrożenia:
apiVersion: apps/v1
kind: Deployment
metadata:
name: contoso-microservice
spec:
replicas: 10 # Tells K8S the number of pods needed to process the Redis list items
selector: # Define the wrapping strategy
matchLabels: # Match all pods with the defined labels
app: contoso-microservice # Labels follow the `name: value` template
template: # Template of the pod inside the deployment
metadata:
labels:
app: contoso-microservice
spec:
containers:
- image: mcr.microsoft.com/mslearn/samples/redis-client:latest
name: contoso-microservice
W przykładowym manifeście replicas jest ustawiona na 10, która jest największą liczbą, którą można ustawić dla niezbędnych replik dostępnych do przetwarzania szczytowej liczby zdarzeń. Jednak powoduje to, że aplikacja zużywa zbyt wiele zasobów w czasie poza szczytem, co może powodować braki zasobów dla innych wdrożeń w klastrze.
Jednym z rozwiązań jest użycie autonomicznego HPA do monitorowania użycia CPU przez zasobniki, co jest lepsze niż ręczne skalowanie w obu kierunkach. Jednak HPA nie koncentruje się na liczbie zdarzeń odebranych na liście Redis.
Najlepszym rozwiązaniem jest użycie KEDA i skalera Redis do zapytań o listę i określenia, czy potrzebne są więcej lub mniej podów do przetwarzania zdarzeń.