Skalowanie za pomocą usługi KEDA
Skalowanie automatyczne oparte na zdarzeniach kubernetes
Narzędzie Kubernetes do automatycznego skalowania opartego na zdarzeniach (KEDA) to pojedynczy i lekki składnik, który upraszcza skalowanie automatyczne aplikacji. Możesz dodać narzędzie KEDA do dowolnego klastra Kubernetes i używać go wraz ze standardowymi składnikami Kubernetes, takimi jak narzędzie Horizontal Pod Autoscaler (HPA) lub narzędzie do automatycznego skalowania klastra, aby rozszerzyć ich funkcjonalność. Za pomocą usługi KEDA można kierować do określonych aplikacji, które mają korzystać ze skalowania opartego na zdarzeniach i zezwalać innym aplikacjom na korzystanie z różnych metod skalowania. KEDA to elastyczna i bezpieczna opcja uruchamiania obok dowolnej liczby aplikacji lub struktur Kubernetes.
Kluczowe możliwości i funkcje
- Tworzenie zrównoważonych i oszczędnych aplikacji dzięki możliwościom skalowania do zera
- Skalowanie obciążeń aplikacji w celu spełnienia wymagań przy użyciu narzędzi skalowania KEDA
- Automatyczne skalowanie aplikacji za pomocą polecenia
ScaledObjects - Zadania skalowania automatycznego za pomocą polecenia
ScaledJobs - Używanie zabezpieczeń klasy produkcyjnej przez oddzielenie automatycznego skalowania i uwierzytelniania z obciążeń
- Korzystanie z własnego zewnętrznego modułu skalowania w celu używania dostosowanych konfiguracji skalowania automatycznego
Architektura
Usługa KEDA udostępnia dwa główne składniki:
- Operator KEDA: umożliwia użytkownikom końcowym skalowanie obciążeń z zera do N wystąpień z obsługą wdrożeń Kubernetes, zadań, stanowychset lub dowolnego zasobu klienta definiującego
/scalepodźródło. - Serwer metryk: uwidacznia zewnętrzne metryki do obliczeń HPA, takich jak komunikaty w temacie platformy Kafka lub zdarzeniach w usłudze Azure Event Hubs, w celu kierowania akcji skalowania automatycznego. Ze względu na ograniczenia nadrzędne serwer metryk KEDA musi być jedyną zainstalowaną kartą metryk w klastrze.
Na poniższym diagramie pokazano, jak usługa KEDA integruje się z platformą Kubernetes HPA, zewnętrznymi źródłami zdarzeń i serwerem INTERFEJSu API Kubernetes w celu zapewnienia funkcji skalowania automatycznego:
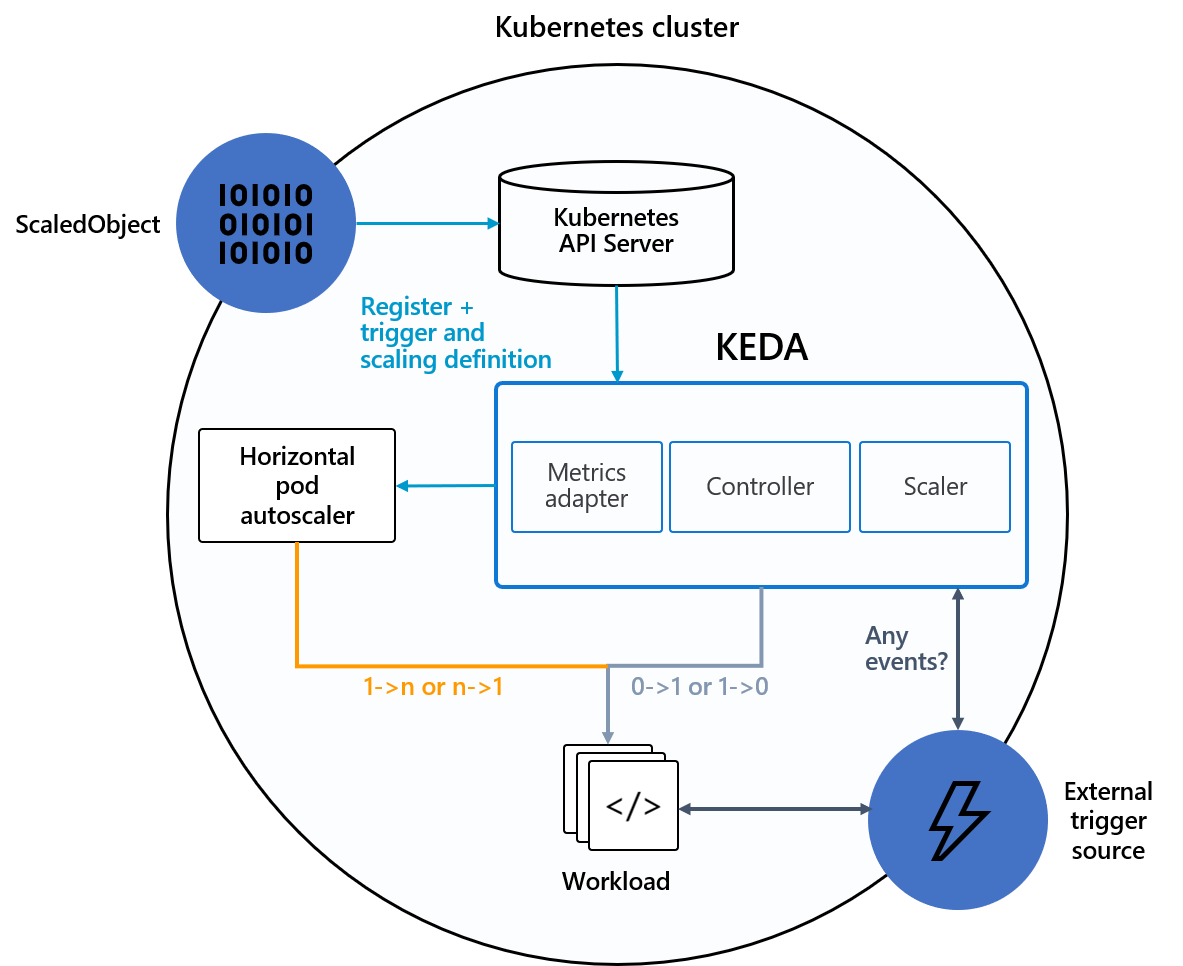
Źródła zdarzeń i skalatory
Moduły skalowania KEDA mogą wykryć, czy wdrożenie powinno zostać aktywowane lub zdezaktywowane, i przekaże metryki niestandardowe dla określonego źródła zdarzeń. Wdrożenia i zestawy stanowe to najbardziej typowy sposób skalowania obciążeń za pomocą usługi KEDA. Możesz również skalować zasoby niestandardowe, które implementują /scale podźródło. Możesz zdefiniować wdrożenie kubernetes lub stanowy zestaw KEDA do skalowania na podstawie wyzwalacza skalowania. Usługa KEDA monitoruje te usługi i automatycznie skaluje je w poziomie na podstawie występujących zdarzeń.
W tle usługa KEDA monitoruje źródło zdarzeń i generuje te dane na platformie Kubernetes i HPA w celu zapewnienia szybkiego skalowania zasobów. Każda replika zasobu aktywnie ściąga elementy ze źródła zdarzeń. Za pomocą KEDA i Deployments/StatefulSets, można skalować na podstawie zdarzeń, zachowując jednocześnie zaawansowane połączenia i semantyki przetwarzania ze źródłem zdarzeń (na przykład przetwarzanie w kolejności, ponawianie prób, deadletter lub punktów kontrolnych).
Specyfikacja obiektu skalowalnego
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Specyfikacja zadania skalowalnego
Alternatywą dla skalowania kodu sterowanego zdarzeniami jako wdrożenia jest również uruchamianie i skalowanie kodu jako zadania kubernetes. Główną przyczyną, dla której należy rozważyć tę opcję, jest przetworzenie długotrwałych wykonań. Zamiast przetwarzać wiele zdarzeń w ramach wdrożenia, każde wykryte zdarzenie planuje własne zadanie Kubernetes. Takie podejście umożliwia przetwarzanie każdego zdarzenia w izolacji i skalowanie liczby współbieżnych wykonań na podstawie liczby zdarzeń w kolejce.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}