Przewodnik po architekturze wątków i zadań
Dotyczy:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Planowanie zadań systemu operacyjnego
Wątki to najmniejsze jednostki przetwarzania wykonywane przez system operacyjny i umożliwiają rozdzielenie logiki aplikacji na kilka współbieżnych ścieżek wykonywania. Wątki są przydatne, gdy złożone aplikacje mają wiele zadań, które można wykonywać w tym samym czasie.
Gdy system operacyjny wykonuje wystąpienie aplikacji, tworzy jednostkę o nazwie proces do zarządzania wystąpieniem. Proces ma wątek wykonywania. Jest to seria instrukcji programowania wykonywanych przez kod aplikacji. Jeśli na przykład prosta aplikacja ma pojedynczy zestaw instrukcji, które można wykonać szeregowo, ten zestaw instrukcji jest obsługiwany jako pojedyncze zadanie, i istnieje tylko jedna ścieżka wykonania (lub wątek) przez aplikację. Bardziej złożone aplikacje mogą mieć kilka zadań, które mogą być wykonywane współbieżnie zamiast szeregowo. Aplikacja może to zrobić, uruchamiając oddzielne procesy dla każdego zadania, które jest operacją intensywnie korzystającą z zasobów, lub uruchamiając oddzielne wątki, które są stosunkowo mniej intensywnie obciążane zasobami. Ponadto każdy wątek można zaplanować do wykonania niezależnie od innych wątków skojarzonych z procesem.
Wątki umożliwiają złożonym aplikacjom wydajniejsze korzystanie z procesora (CPU), nawet na komputerach z pojedynczym procesorem CPU. Przy użyciu jednego procesora CPU tylko jeden wątek może być wykonywany jednocześnie. Jeśli jeden wątek wykonuje długotrwałą operację, która nie używa procesora CPU, takiego jak odczyt dysku lub zapis, może zostać wykonana inna z wątków do momentu ukończenia pierwszej operacji. Dzięki możliwości wykonywania wątków, gdy inne wątki oczekują na ukończenie operacji, aplikacja może zmaksymalizować użycie procesora CPU. Dotyczy to szczególnie wielu użytkowników, aplikacji intensywnie korzystających z operacji we/wy dysku, takich jak serwer bazy danych. Komputery z wieloma procesorami mogą wykonywać jeden wątek na procesor jednocześnie. Na przykład jeśli komputer ma osiem procesorów CPU, może wykonać osiem wątków w tym samym czasie.
Planowanie zadań programu SQL Server
W zakresie programu SQL Server żądanie jest logiczną reprezentacją zapytania lub partii. Żądanie reprezentuje również operacje wymagane przez wątki systemowe, takie jak punkt kontrolny lub moduł zapisywania dzienników. Żądania istnieją w różnych stanach w całym swoim czasie istnienia i mogą gromadzić oczekiwanie, gdy zasoby wymagane do wykonania żądania nie są dostępne, takie jak blokady lub zatrzaski. Aby uzyskać więcej informacji na temat stanów żądań, zobacz sys.dm_exec_requests.
Zadania
Zadanie reprezentuje jednostkę pracy, która musi zostać ukończona w celu spełnienia żądania. Co najmniej jedno zadanie można przypisać do jednego żądania.
- Żądania równoległe mają kilka aktywnych zadań, które są wykonywane współbieżnie zamiast szeregowo, z jednym zadaniem nadrzędnym (lub zadaniem koordynującym) oraz wieloma podrzędnymi zadaniami . Plan wykonania dla żądania równoległego może mieć gałęzie szeregowe — obszary planu z operatorami, które nie są wykonywane równolegle. Zadanie nadrzędne jest również odpowiedzialne za wykonywanie tych operatorów seryjnych.
- Żądania szeregowe mają tylko jedno aktywne zadanie w dowolnym momencie w czasie wykonywania. Zadania istnieją w różnych stanach przez cały okres ich istnienia. Aby uzyskać więcej informacji na temat stanów zadań, zobacz sys.dm_os_tasks. Zadania w stanie ZAWIESZONE oczekują na zasoby niezbędne do ich wykonania, aby te zasoby stały się dostępne. Aby uzyskać więcej informacji na temat oczekujących zadań, zobacz sys.dm_os_waiting_tasks.
Pracownicy
Wątek roboczy programu SQL Server , znany również jako proces roboczy lub wątek, jest logiczną reprezentacją wątku systemu operacyjnego. Podczas wykonywania żądań szeregowychsilnik bazy danych programu SQL Server uruchamia proces roboczy w celu wykonania aktywnego zadania (1:1). Podczas wykonywania równoległych żądań w trybie wiersza aparat bazy danych programu SQL Server przypisuje proces roboczy do koordynowania podrzędnych procesów roboczych odpowiedzialnych za wykonywanie przydzielonych im zadań (również 1:1), nazywany wątku nadrzędnego (lub koordynującego wątek). Wątek nadrzędny ma skojarzone z nim zadanie główne. Wątek nadrzędny jest miejscem wejściowym dla żądania i istnieje jeszcze zanim silnik przeanalizuje zapytanie. Główne obowiązki wątku nadrzędnego to:
- Koordynowanie skanowania równoległego.
- Uruchamianie równoległych procesów roboczych podrzędnych.
- Zbieraj wiersze z równoległych wątków i wysyłaj je do klienta.
- Wykonywanie agregacji lokalnych i globalnych.
Notatka
Jeśli plan zapytania ma gałęzie szeregowe i równoległe, jedno z zadań równoległych będzie odpowiedzialne za wykonanie gałęzi szeregowej.
Liczba wątków roboczych uruchamianych dla każdego zadania zależy od:
Czy żądanie kwalifikowało się do przetwarzania równoległego, jak określił Optymalizator Zapytań.
Jaki jest rzeczywisty dostępny stopień równoległości (DOP) w systemie, na podstawie bieżącego obciążenia. Może to różnić się od szacowanej wartości DOP, która jest oparta na konfiguracji serwera dla maksymalnego stopnia równoległości (MAXDOP). Na przykład konfiguracja serwera dla MAXDOP może wynosić 8, ale dostępny DOP w czasie wykonywania może być tylko 2, co wpływa na efektywność zapytań. Presja pamięci i niedobór pracowników to dwa czynniki, które zmniejszają dostępność DOP w czasie wykonywania.
Notatka
Maksymalny stopień równoległości (MAXDOP) jest ustawiany na zadanie, a nie na żądanie. Oznacza to, że podczas równoległego wykonywania zapytania pojedyncze żądanie może uruchomić wiele zadań aż do limitu MAXDOP, a każde zadanie będzie używać jednego wątku roboczego. Aby uzyskać więcej informacji na temat opcji MAXDOP, zobacz Skonfiguruj opcję konfiguracji serwera maksymalnego stopnia równoległości.
Harmonogramiści
Harmonogram , znany również jako harmonogram SOS, zarządza wątkami procesów roboczych, które wymagają czasu przetwarzania do wykonywania pracy w imieniu zadań. Każdy harmonogram jest mapowany na pojedynczy procesor (CPU). Czas, przez który proces roboczy może pozostać aktywny w harmonogramie, jest nazywany kwantem systemu operacyjnego z maksymalnie 4 ms. Po wygaśnięciu czasu kwantowego proces roboczy oddaje swoje zasoby czasowe innym procesom, które muszą uzyskiwać dostęp do zasobów CPU, i zmienia swój stan. Ta współpraca między pracownikami w celu zmaksymalizowania dostępu do zasobów procesora CPU jest nazywana harmonogramem współpracy, znanym również jako planowanie niewłasne. Z kolei zmiana stanu jednostki roboczej jest propagowana do zadania skojarzonego z tą jednostką roboczą oraz do żądania skojarzonego z zadaniem. Aby uzyskać więcej informacji na temat stanów pracowników, zobacz sys.dm_os_workers. Aby uzyskać więcej informacji na temat harmonogramów, zobacz sys.dm_os_schedulers.
Podsumowując, żądanie może powodować powstawanie jednego lub więcej zadań w celu wykonywania jednostek pracy. Każde zadanie jest przypisywane do wątku roboczego , który jest odpowiedzialny za ukończenie zadania. Każdy wątek procesu roboczego musi być zaplanowany (umieszczony na harmonogramie) w celu aktywnego wykonywania zadania.
Rozważmy następujący scenariusz:
- Zadanie 1 to długotrwałe zadanie, na przykład zapytanie odczytu danych wykorzystujące tabeli oparte na dyskach. Pracownik 1 stwierdza, że wymagane strony danych są już w Puli Buforowej, więc nie musi czekać na operacje We/Wy i może wykorzystać pełny kwant czasu przed przekazaniem sterowania.
- Pracownik 2 wykonuje zadania krótsze niż milisekunda i dlatego musi ustąpić przed wyczerpaniem pełnego kwantu.
W tym scenariuszu i do programu SQL Server 2014 (12.x) proces roboczy 1 może zasadniczo zmonopolizować harmonogram, mając bardziej ogólny czas kwantowy.
Począwszy od wersji SQL Server 2016 (13.x), harmonogramowanie kooperatywne obejmuje algorytm Large Deficit First (LDF). W przypadku planowania LDF wzorce użycia kwantowego są monitorowane, a jeden wątek procesu roboczego nie monopolizuje harmonogramu. W tym samym scenariuszu pracownik 2 może korzystać z powtórzonych kwantów, zanim zezwoli się pracownikowi 1 na więcej kwantów, co uniemożliwia pracownikowi 1 monopolizowanie harmonogramu w nieprzyjazny sposób.
Harmonogram zadań równoległych
Wyobraź sobie, że program SQL Server skonfigurowany z programem MaxDOP 8, a koligacja procesora CPU jest skonfigurowana dla 24 procesorów CPU (harmonogramów) w węzłach NUMA 0 i 1. Harmonogramy od 0 do 11 należą do węzła NUMA 0, harmonogramy od 12 do 23 należą do węzła NUMA 1. Aplikacja wysyła następujące zapytanie (żądanie) do silnika bazy danych:
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
Napiwek
Przykładowe zapytanie można wykonać przy użyciu bazy danych AdventureWorks2016_EXT. Tabele Sales.SalesOrderHeader i Sales.SalesOrderDetail zostały powiększone 50 razy i zmieniono nazwę na Sales.SalesOrderHeaderBulk i Sales.SalesOrderDetailBulk.
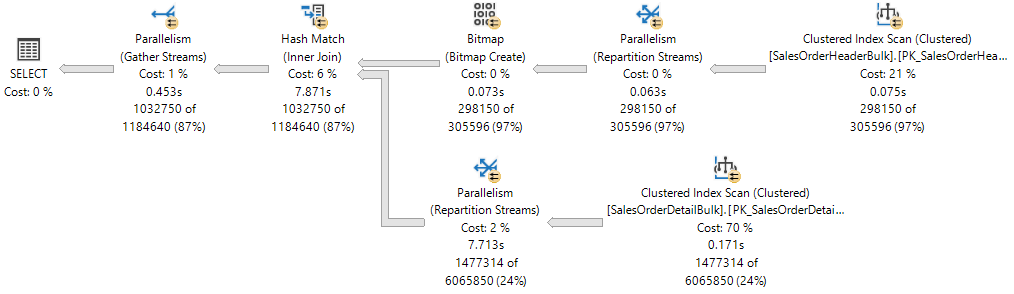
Plan wykonania przedstawia Hash Join między dwiema tabelami, a każdy z operatorów jest wykonywany równolegle, co jest wskazane przez żółty okrąg z dwiema strzałkami. Każdy operator równoległości jest inną gałęzią w planie. W związku z tym w poniższym planie wykonywania znajdują się trzy gałęzie.
Notatka
Jeśli myślisz o planie wykonywania jako drzewie, gałąź jest obszarem planu, który grupuje co najmniej jeden operator między operatorami równoległości, nazywanym również iteratorami programu Exchange. Aby uzyskać więcej informacji na temat operatorów planu, zobacz Showplan Logical and Physical Operators Reference (Dokumentacja operatorów logicznych i fizycznych programu Showplan).
Chociaż w planie wykonywania istnieją trzy gałęzie, w dowolnym momencie podczas wykonywania tylko dwie gałęzie mogą być wykonywane współbieżnie w tym planie wykonywania:
- Gałąź, w której stosowane jest skanowanie indeksu klastrowanego na w
Sales.SalesOrderHeaderBulk(jako dane wejściowe do kompilacji sprzężenia), wykonuje się samodzielnie. - Następnie gałąź, w której jest używany skanowanie indeksu klastrowanego na
Sales.SalesOrderDetailBulk(wejście próbne łączenia), jest wykonywana współbieżnie z gałęzią, w której utworzono mapę bitową, a obecnie wykonywane jest dopasowanie skrótu .
Plik XML programu Showplan pokazuje, że 16 wątków roboczych zostało zarezerwowanych i używanych w węźle NUMA 0:
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
Rezerwacja wątków zapewnia, że aparat bazy danych ma wystarczającą liczbę wątków roboczych, aby wykonywać wszystkie zadania potrzebne do wykonania żądania. Wątki mogą być rezerwowane w kilku węzłach NUMA lub tylko w jednym węźle NUMA. Rezerwacja wątków następuje w czasie działania programu, zanim rozpocznie się jego wykonanie, i jest zależna od obciążenia planera. Liczba zarezerwowanych wątków roboczych jest ogólnie wyprowadzana z formuły concurrent branches * runtime DOP i wyklucza nadrzędny wątek roboczy. Każda gałąź jest ograniczona do liczby wątków roboczych równej MaxDOP. W tym przykładzie istnieją dwie współbieżne gałęzie, a parametr MaxDOP ma wartość 8, dlatego 2 * 8 = 16.
Aby uzyskać informacje, sprawdź plan wykonywania na żywo ze statystyk zapytań na żywo , gdzie jedna gałąź została ukończona, a dwie gałęzie są wykonywane równocześnie.
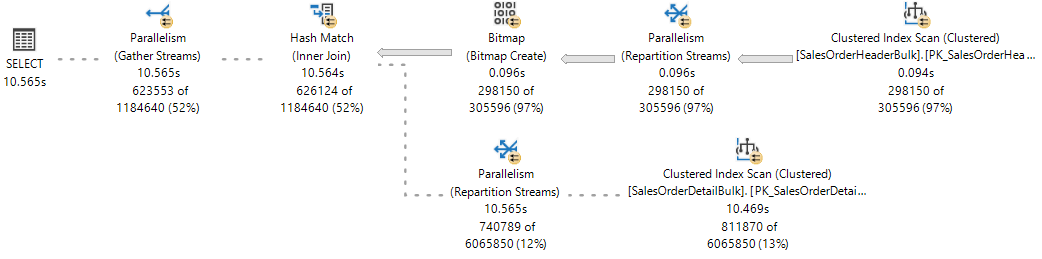
Aparat bazy danych programu SQL Server przypisuje wątek roboczy do wykonywania aktywnego zadania (1:1), które można zaobserwować podczas wykonywania zapytania, wykonując zapytanie o sys.dm_os_tasks widoku DMV, jak pokazano w poniższym przykładzie:
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
Napiwek
Kolumna parent_task_address zawsze ma wartość NULL dla zadania nadrzędnego.
Napiwek
Na bardzo obciążonym silniku bazy danych SQL Server można zobaczyć wiele aktywnych zadań, które przekraczają limit ustawiony dla zarezerwowanych wątków. Te zadania mogą należeć do gałęzi, która nie jest już używana, a znajdują się w stanie przejściowym, oczekując na oczyszczenie.
Oto zestaw wyników. Zwróć uwagę, że istnieje 17 aktywnych zadań dla gałęzi, które są obecnie wykonywane: 16 podrzędnych zadań odpowiadających zarezerwowanym wątkom oraz zadanie nadrzędne, czyli zadanie koordynujące.
| adres_zadania_nadrzędnego | adres zadania | stan_zadania | scheduler_id | adres_pracownika |
|---|---|---|---|---|
| ZERO | 0x000001EF4758ACA8 |
ZAWIESZONY | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | ZAWIESZONY | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | ZAWIESZONY | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | ZAWIESZONY | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | ZAWIESZONY | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | ZAWIESZONY | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | ZAWIESZONY | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | ZAWIESZONY | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | ZAWIESZONY | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | ZAWIESZONY | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | ZAWIESZONY | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | ZAWIESZONY | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | ZAWIESZONY | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | ZAWIESZONY | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | ZAWIESZONY | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | ZAWIESZONY | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | ZAWIESZONY | 11 | 0x000001EF6BD72160 |
Zwróć uwagę, że każdy z 16 podrzędnych zadań ma przypisany inny wątek roboczy (widoczny w kolumnie worker_address), ale wszyscy pracownicy są przypisani do tej samej puli ośmiu harmonogramów (0,5,6,7,8,9,10,11) i że zadanie nadrzędne jest przypisywane do harmonogramu poza tą pulą (3).
Ważny
Po zaplanowaniu pierwszego zestawu zadań równoległych w danej gałęzi aparat bazy danych będzie używać tej samej puli harmonogramów do wykonywania dodatkowych zadań w innych gałęziach. Oznacza to, że ten sam zestaw harmonogramów będzie używany dla wszystkich zadań równoległych w całym planie wykonywania, tylko ograniczony przez program MaxDOP.
Silnik bazy danych programu SQL Server zawsze spróbuje przypisać harmonogramy zadań z tego samego węzła NUMA do wykonywania zadań i przydzieli je sekwencyjnie (w sposób cykliczny), jeśli harmonogramy są dostępne. Jednak wątek roboczy przypisany do zadania nadrzędnego może zostać umieszczony w innym węźle NUMA niż inne zadania.
Wątek roboczy może pozostać aktywny w koordynatorze zadań tylko podczas swojego kwantu (4 ms) i musi oddać koordynatora zadań po upływie tego kwantu, aby wątek roboczy przypisany do innego zadania mógł stać się aktywny. Gdy kwant czasu pracownika wygasa i nie jest już aktywny, odpowiednie zadanie jest umieszczane w kolejce FIFO w stanie FUNKCJONALNYM, dopóki nie zostanie ponownie przeniesione do stanu DZIAŁAJĄCE, zakładając, że zadanie nie wymaga dostępu do zasobów, które nie są dostępne w danej chwili, takich jak przełącznik lub blokada. W takim przypadku zadanie zostanie umieszczone w stanie ZAWIESZONE, aż do momentu, gdy te zasoby będą dostępne.
Napiwek
W przypadku wyników widoku DMV widocznego powyżej wszystkie aktywne zadania są w stanie ZAWIESZONE. Więcej szczegółów na temat zadań oczekujących są dostępne za pomocą zapytania do sys.dm_os_waiting_tasks DMV.
Podsumowując, równoległe żądanie tworzy wiele zadań. Każde zadanie musi być przypisane do jednego wątku roboczego. Każdy wątek procesu roboczego musi być przypisany do jednego harmonogramu. W związku z tym liczba używanych harmonogramów nie może przekraczać liczby zadań równoległych na każdą gałąź, która jest ustawiana przez konfigurację MaxDOP lub parametr zapytania. Wątek koordynujący nie przyczynia się do limitu MaxDOP.
Alokacja wątków do procesorów
Domyślnie każde wystąpienie programu SQL Server uruchamia każdy wątek, a system operacyjny dystrybuuje wątki z wystąpień programu SQL Server między procesory (PROCESORy) na komputerze na podstawie obciążenia. Jeśli koligacja procesów została włączona na poziomie systemu operacyjnego, system operacyjny przypisuje każdy wątek do określonego procesora CPU. Z kolei silnik bazy danych SQL Server przypisuje wątki robocze do harmonogramów, które równomiernie dystrybuują wątki między procesory CPU w systemie rotacyjnym.
Aby przeprowadzić wielozadaniowość, na przykład gdy wiele aplikacji uzyskuje dostęp do tego samego zestawu procesorów CPU, system operacyjny czasami przenosi wątki procesów roboczych między różnymi procesorami CPU. Chociaż jest to efektywne z punktu widzenia systemu operacyjnego, to działanie może zmniejszyć wydajność programu SQL Server przy dużych obciążeniach systemowych, ponieważ każda pamięć podręczna procesora jest wielokrotnie ładowana na nowo danymi. Przypisywanie jednostek CPU do określonych wątków może poprawić wydajność w tych warunkach, eliminując ponowne ładowanie procesora i zmniejszając migrację wątków pomiędzy jednostkami CPU (a tym samym redukując przełączanie kontekstu); takie przypisanie wątku do procesora nazywane jest afinitetem procesora. Jeśli koligacja została włączona, system operacyjny przypisuje każdy wątek do określonego procesora CPU.
Opcja maski afinitetu jest konfigurowana przy użyciu ALTER SERVER CONFIGURATION. Gdy maska koligacji nie jest ustawiona, wystąpienie programu SQL Server przydziela wątki robocze równomiernie wśród harmonogramów, które nie zostały zamaskowane.
Ostrożność
Nie należy konfigurować koligacji CPU w systemie operacyjnym ani maski koligacji w programie SQL Server. Te ustawienia próbują osiągnąć ten sam wynik, a jeśli konfiguracje są niespójne, wyniki mogą być nieprzewidywalne. Aby uzyskać więcej informacji, zobacz opcję maski koligacji .
Buforowanie wątków pomaga zoptymalizować wydajność, gdy duża liczba klientów jest połączona z serwerem. Zazwyczaj oddzielny wątek systemu operacyjnego jest tworzony dla każdego żądania zapytania. Jednak w przypadku setek połączeń z serwerem użycie jednego wątku na żądanie zapytania może zużywać duże ilości zasobów systemowych. Opcja maksymalnych wątków roboczych umożliwia programowi SQL Server utworzenie puli wątków roboczych w celu obsługi większej liczby żądań zapytań, co zwiększa wydajność.
Korzystanie z lekkiej opcji konsolidacji zasobów
Obciążenie związane z przełączaniem kontekstów wątków może nie być bardzo duże. Większość wystąpień programu SQL Server nie widzi żadnych różnic w wydajności między ustawieniem uproszczonego buforowania opcji 0 lub 1. Jedynymi wystąpieniami programu SQL Server, które mogą korzystać z uproszczonego współdzielenia zasobów, są te, które działają na komputerze o następujących cechach:
- Duży wieloprocesorowy serwer
- Wszystkie procesory działają blisko maksymalnej wydajności
- Istnieje wysoki poziom przełączania kontekstu
Systemy te mogą spowodować niewielki wzrost wydajności, jeśli uproszczona wartość buforowania jest ustawiona na 1.
Ważny
Nie należy używać planowania w trybie światłowodowym w codziennej operacji. Może to zmniejszyć wydajność, hamując regularne korzyści wynikające z przełączania kontekstu i ponieważ niektóre składniki programu SQL Server nie mogą działać poprawnie w trybie światłowodowym. Aby uzyskać więcej informacji, zobacz uproszczone buforowanie.
Wykonywanie wątków i włókien
Microsoft Windows używa systemu priorytetów liczbowych z zakresu od 1 do 31 do planowania wykonania wątków. Zero jest zarezerwowane do użytku systemu operacyjnego. Gdy kilka wątków oczekuje na wykonanie, system Windows wysyła wątek z najwyższym priorytetem.
Domyślnie każde wystąpienie programu SQL Server ma priorytet 7, który jest określany jako normalny priorytet. To ustawienie domyślne zapewnia wątkom programu SQL Server wystarczająco wysoki priorytet, aby uzyskać wystarczające zasoby procesora CPU bez negatywnego wpływu na inne aplikacje.
Ważny
Ta funkcja zostanie usunięta w przyszłej wersji programu SQL Server. Unikaj używania tej funkcji w nowych pracach programistycznych i zaplanuj modyfikowanie aplikacji, które obecnie korzystają z tej funkcji.
Opcja konfiguracji priorytetu może służyć do zwiększenia priorytetu wątków z wystąpienia programu SQL Server do 13. Jest to określane jako wysoki priorytet. To ustawienie zapewnia wątkom programu SQL Server wyższy priorytet niż większość innych aplikacji. W związku z tym wątki programu SQL Server są zwykle wysyłane zawsze, gdy są gotowe do uruchomienia i nie są wywłaszczone przez wątki z innych aplikacji. Może to poprawić wydajność, gdy na serwerze uruchomione są tylko instancje programu SQL Server i brak innych aplikacji. Jednak jeśli w programie SQL Server wystąpi operacja intensywnie korzystająca z pamięci, inne aplikacje prawdopodobnie nie będą miały wystarczająco wysokiego priorytetu, aby przejąć wątek programu SQL Server.
W przypadku uruchamiania wielu wystąpień programu SQL Server na komputerze i włączenia zwiększenia priorytetu tylko dla niektórych wystąpień wydajność wszystkich wystąpień uruchomionych z normalnym priorytetem może mieć negatywny wpływ. Ponadto wydajność innych aplikacji i składników na serwerze może spaść, jeśli zwiększenie priorytetu jest włączone. W związku z tym należy go używać tylko w ściśle kontrolowanych warunkach.
Dodawanie procesora na gorąco
Gorące dodawanie procesorów to możliwość dynamicznego dodawania procesorów do działającego systemu. Dodanie procesorów może wystąpić fizycznie przez dodanie nowego sprzętu, logicznie przez partycjonowanie sprzętu online lub wirtualnie przez warstwę wirtualizacji. Program SQL Server obsługuje funkcję hot add CPU.
Wymagania dotyczące dynamicznego dodawania procesora:
- Wymaga sprzętu, który obsługuje możliwość dodawania procesorów CPU na gorąco.
- Wymaga obsługiwanej wersji systemu Windows Server Datacenter lub Enterprise. Począwszy od systemu Windows Server 2012, dodatek hot jest obsługiwany w wersji Standard.
- Wymaga wersji SQL Server Enterprise.
- Nie można skonfigurować programu SQL Server do używania soft NUMA. Aby uzyskać więcej informacji na temat miękkiej NUMA, zobacz Soft-NUMA (SQL Server).
Program SQL Server nie używa samoczynnie procesorów po dodaniu. Uniemożliwia to programowi SQL Server używanie procesorów CPU, które mogą być dodawane w innym celu. Po dodaniu procesorów należy wykonać instrukcję RECONFIGURE, aby program SQL Server rozpoznał nowe procesory jako dostępne zasoby.
Notatka
Jeśli skonfigurowano maskę koligacji64 , należy zmodyfikować maskę koligacji64, aby używać nowych procesorów.
Najlepsze rozwiązania dotyczące uruchamiania programu SQL Server na komputerach z więcej niż 64 procesorami CPU
Przypisywanie wątków sprzętowych do procesorów
Nie używaj maski koligacji i opcji konfiguracji serwera maskowania64 do powiązania procesorów z określonymi wątkami. Opcje te są ograniczone do 64 CPU. Zamiast tego użyj opcji SET PROCESS AFFINITYALTER SERVER CONFIGURATION.
Zarządzanie rozmiarem pliku dziennika transakcji
Nie należy polegać na automatycznym zwiększaniu rozmiaru pliku dziennika transakcji. Zwiększenie dziennika transakcji musi być procesem szeregowym. Rozszerzenie dziennika może uniemożliwić kontynuowanie operacji zapisu transakcji do momentu zakończenia rozszerzenia dziennika. Zamiast tego należy wstępnie przydzielić miejsce dla plików dziennika, ustawiając rozmiar pliku na wartość wystarczająco dużą, aby obsługiwać typowe obciążenie w środowisku.
Ustawianie maksymalnego stopnia równoległości dla operacji indeksowania
Wydajność operacji indeksowania, takich jak tworzenie lub ponowne kompilowanie indeksów, można poprawić na komputerach, które mają wiele procesorów CPU, tymczasowo ustawiając model odzyskiwania bazy danych na model odzyskiwania rejestrowany zbiorczo lub prosty model odzyskiwania. Te operacje indeksowe mogą generować znaczną aktywność dziennika, a zawężenie dziennika może wpływać na najlepszy wybór stopnia równoległości (DOP) dokonany przez program SQL Server.
Oprócz dostosowania maksymalnego stopnia równoległości (MAXDOP) opcji konfiguracji serwera rozważ dostosowanie równoległości operacji indeksowania przy użyciu opcji MAXDOP. Aby uzyskać więcej informacji, zobacz Configure Parallel Index Operations. Aby uzyskać więcej informacji i wskazówek dotyczących dostosowywania maksymalnego stopnia konfiguracji serwera równoległości, zobacz Konfigurowanie maksymalnego stopnia konfiguracji serwera równoległości.
Maksymalna liczba wątków roboczych
Program SQL Server dynamicznie konfiguruje maksymalne wątki robocze opcji konfiguracji serwera podczas uruchamiania. Program SQL Server używa liczby dostępnych procesorów CPU i architektury systemu, aby określić tę konfigurację serwera podczas uruchamiania przy użyciu udokumentowanej formuły .
Ta opcja jest opcją zaawansowaną i powinna zostać zmieniona tylko przez doświadczonego administratora bazy danych lub certyfikowanego specjalistę programu SQL Server. Jeśli podejrzewasz, że występuje problem z wydajnością, prawdopodobnie nie jest to dostępność wątków roboczych. Bardziej prawdopodobne jest, że przyczyną są operacje we/wy, które powodują oczekiwanie wątków roboczych. Najlepiej jest znaleźć główną przyczynę problemu z wydajnością przed zmianą ustawienia maksymalnej liczby wątków roboczych. Jeśli jednak musisz ręcznie ustawić maksymalną liczbę wątków roboczych, ta wartość konfiguracji musi być zawsze ustawiona na wartość co najmniej siedmiu razy więcej procesorów CPU, które znajdują się w systemie. Aby uzyskać więcej informacji, zobacz Konfigurowanie maksymalnej liczby wątków roboczych.
Unikaj używania funkcji śledzenia SQL i profilera programu SQL Server
Zalecamy, aby w środowisku produkcyjnym nie używać narzędzia SQL Trace i SQL Profiler. Obciążenie związane z uruchamianiem tych narzędzi zwiększa się również wraz ze wzrostem liczby procesorów CPU. Jeśli musisz użyć funkcji SQL Trace w środowisku produkcyjnym, ogranicz liczbę zdarzeń śledzenia do minimum. Starannie profiluj i przetestuj każde zdarzenie śledzenia pod obciążeniem i unikaj używania kombinacji zdarzeń, które znacząco wpływają na wydajność.
Ważny
Śledzenie SQL i program SQL Server Profiler są przestarzałe. Przestrzeń nazw Microsoft.SqlServer.Management.Trace, która zawiera obiekty śledzenia i odtwarzania programu SQL Server, jest również przestarzała.
Ta funkcja zostanie usunięta w przyszłej wersji programu SQL Server. Unikaj używania tej funkcji w nowych pracach programistycznych i zaplanuj modyfikowanie aplikacji, które obecnie korzystają z tej funkcji.
Zamiast tego użyj zdarzeń rozszerzonych. Aby uzyskać więcej informacji na temat zdarzeń rozszerzonych , zobacz Quick Start: Extended events in SQL Server and SSMS XEvent Profiler.
Notatka
Program SQL Server Profiler dla obciążeń usług Analysis Services nie jest przestarzały i nadal będzie obsługiwany.
Ustawianie liczby plików danych tempdb
Liczba plików zależy od liczby procesorów (logicznych) na maszynie. Ogólnie rzecz biorąc, jeśli liczba procesorów logicznych jest mniejsza lub równa ośmiu, należy użyć tej samej liczby plików danych co procesory logiczne. Jeśli liczba procesorów logicznych jest większa niż osiem, użyj ośmiu plików danych, a następnie jeśli rywalizacja będzie kontynuowana, zwiększ liczbę plików danych o wielokrotność 4, dopóki rywalizacja nie zostanie zmniejszona do akceptowalnych poziomów lub wprowadź zmiany w obciążeniu/kodzie. Należy również pamiętać o innych zaleceniach dotyczących tempdb, dostępnych w Optymalizowanie wydajności bazy danych tempdb w programie SQL Server.
Jednak starannie biorąc pod uwagę potrzeby współbieżności tempdb, można zmniejszyć nakład pracy związany z zarządzaniem bazami danych. Jeśli na przykład system ma 64 procesory CPU i zwykle tylko 32 zapytania używają tempdb, zwiększenie liczby plików tempdb do 64 nie poprawi wydajności.
Składniki programu SQL Server, które mogą używać więcej niż 64 procesorów CPU
W poniższej tabeli wymieniono składniki programu SQL Server i wskazuje, czy mogą używać więcej niż 64 procesorów CPU.
| Nazwa procesu | Program wykonywalny | Używanie więcej niż 64 procesorów CPU |
|---|---|---|
| Aparat bazy danych programu SQL Server | Sqlserver.exe | Tak |
| Usługi raportowania | Rs.exe | Nie |
| Usługi Analityczne | As.exe | Nie |
| Usługi integracyjne | Is.exe | Nie |
| Broker usług | Sb.exe | Nie |
| wyszukiwanie Full-Text | Fts.exe | Nie |
| SQL Server Agent | Sqlagent.exe | Nie |
| SQL Server Management Studio | Ssms.exe | Nie |
| Konfiguracja programu SQL Server | Setup.exe | Nie |