Scenariusze użycia tabeli czasowej
Dotyczy:![]() SQL Server 2016 (13.x) i nowsze wersje
SQL Server 2016 (13.x) i nowsze wersje ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL Database w Microsoft Fabric
SQL Database w Microsoft Fabric
Tabele czasowe w wersji systemowej są przydatne w scenariuszach, które wymagają śledzenia historii zmian danych. Zalecamy rozważenie tabel czasowych w następujących przypadkach użycia, aby uzyskać duże korzyści z produktywności.
Inspekcja danych
W tabelach przechowujących informacje o krytycznym znaczeniu można używać czasowego przechowywania wersji systemu, aby śledzić, co się zmieniło i kiedy, oraz wykonywać analizy danych w dowolnym momencie.
Tabele czasowe umożliwiają planowanie scenariuszy inspekcji danych na wczesnym etapie cyklu programowania lub dodawanie inspekcji danych do istniejących aplikacji lub rozwiązań, gdy są one potrzebne.
Na poniższym diagramie przedstawiono tabelę Employee z przykładowymi danymi, w tym bieżącą (oznaczoną kolorem niebieskim) i wersjami wierszy historycznych (oznaczonych szarym kolorem).
Część po prawej stronie diagramu ukazuje wersje wierszy w kontekście osi czasu oraz wiersze wybierane przy użyciu różnych typów zapytań w tabeli temporalnej, z użyciem klauzuli SYSTEM_TIME lub bez niej.

Włączanie przechowywania wersji systemu w nowej tabeli na potrzeby inspekcji danych
Jeśli zidentyfikujesz informacje, które wymagają inspekcji danych, utwórz tabele baz danych jako tabele czasowe w wersji systemowej. Poniższy przykład ilustruje scenariusz z tabelą o nazwie Employee w hipotetycznej bazie danych HR:
CREATE TABLE Employee (
[EmployeeID] INT NOT NULL PRIMARY KEY CLUSTERED,
[Name] NVARCHAR(100) NOT NULL,
[Position] VARCHAR(100) NOT NULL,
[Department] VARCHAR(100) NOT NULL,
[Address] NVARCHAR(1024) NOT NULL,
[AnnualSalary] DECIMAL(10, 2) NOT NULL,
[ValidFrom] DATETIME2(2) GENERATED ALWAYS AS ROW START,
[ValidTo] DATETIME2(2) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.EmployeeHistory));
Różne opcje tworzenia tabeli czasowej z wersjonowaniem systemowym opisano w Tworzenie tabeli czasowej wersjonowanej systemowo.
Włączanie przechowywania wersji systemu w istniejącej tabeli na potrzeby inspekcji danych
Jeśli musisz przeprowadzić inspekcję danych w istniejących bazach danych, użyj ALTER TABLE, aby rozszerzyć tabele nietemporarne, tak aby stały się wersjonowane przez system. Aby uniknąć zmian łamiących zgodność w aplikacji, dodaj kolumny okresu jako HIDDEN, zgodnie z opisem w Tworzenie tabeli czasowej wersjonowanej przez system.
Poniższy przykład ilustruje włączanie wersjonowania systemowego na istniejącej tabeli Employee w hipotetycznej bazie danych HR. Umożliwia przechowywanie wersji systemu w tabeli Employee w dwóch krokach. Najpierw nowe kolumny okresu są dodawane jako HIDDEN. Następnie tworzy domyślną tabelę historii.
ALTER TABLE Employee ADD
ValidFrom DATETIME2(2) GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2(2) GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Employee
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.Employee_History));
Ważny
Precyzja typu danych datetime2 musi być taka sama w tabeli źródłowej jak w tabeli historii wersji systemu.
Po wykonaniu poprzedniego skryptu wszystkie zmiany danych zostaną przejrzyście zebrane w tabeli historii. W typowym scenariuszu inspekcji danych należy wykonać zapytanie dotyczące wszystkich zmian danych, które zostały zastosowane do pojedynczego wiersza w danym okresie zainteresowania. Domyślna tabela historii jest tworzona jako klastrowane B-drzewo przechowujące wiersze, aby efektywnie rozwiązać ten przypadek użycia.
Notatka
W dokumentacji jest zwykle używany termin B-tree w odniesieniu do indeksów. W indeksach magazynu danych wierszowych silnik bazy danych implementuje drzewo B+. Nie dotyczy to indeksów magazynu kolumn ani indeksów w tabelach zoptymalizowanych pod kątem pamięci. Aby uzyskać więcej informacji, zobacz architektura usługi SQL Server i architektura indeksu usługi Azure SQL oraz przewodnik projektowania.
Przeprowadzanie analizy danych
Po włączeniu obsługi wersji systemu za pomocą jednego z poprzednich podejść, inspekcja danych to już kwestia jednego zapytania. Następujące zapytanie wyszukuje wersje wierszy dla rekordów w tabeli Employee, które związane są z EmployeeID = 1000 i były aktywne co najmniej przez część okresu między 1 stycznia 2021 r. a 1 stycznia 2022 r. (włącznie z górną granicą).
SELECT * FROM Employee
FOR SYSTEM_TIME BETWEEN '2021-01-01 00:00:00.0000000'
AND '2022-01-01 00:00:00.0000000'
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Zastąp FOR SYSTEM_TIME BETWEEN...ANDFOR SYSTEM_TIME ALL, aby przeanalizować całą historię zmian danych dla tego konkretnego pracownika:
SELECT * FROM Employee
FOR SYSTEM_TIME ALL
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Aby wyszukać wersje wierszy, które były aktywne tylko w określonym okresie (a nie poza nim), skorzystaj z CONTAINED IN. To zapytanie jest wydajne, ponieważ wykonuje zapytanie tylko w tabeli historii:
SELECT * FROM Employee
FOR SYSTEM_TIME CONTAINED IN (
'2021-01-01 00:00:00.0000000', '2022-01-01 00:00:00.0000000'
)
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Na koniec w niektórych scenariuszach inspekcji warto zobaczyć, jak wyglądała cała tabela w dowolnym momencie w przeszłości:
SELECT * FROM Employee
FOR SYSTEM_TIME AS OF '2021-01-01 00:00:00.0000000';
Tabele czasowe w wersji systemowej przechowują wartości kolumn okresów w strefie czasowej UTC, ale może się okazać bardziej wygodne pracowanie w lokalnej strefie czasowej, zarówno podczas filtrowania danych, jak i wyświetlania wyników. Poniższy przykładowy kod pokazuje, jak zastosować warunek filtrowania, który jest określony w lokalnej strefie czasowej, a następnie przekonwertowany na UTC przy użyciu AT TIME ZONE, który został wprowadzony w programie SQL Server 2016 (13.x):
/* Add offset of the local time zone to current time*/
DECLARE @asOf DATETIMEOFFSET = GETDATE() AT TIME ZONE 'Pacific Standard Time';
/* Convert AS OF filter to UTC*/
SET @asOf = DATEADD(HOUR, - 9, @asOf) AT TIME ZONE 'UTC';
SELECT EmployeeID,
[Name],
Position,
Department,
[Address],
[AnnualSalary],
ValidFrom AT TIME ZONE 'Pacific Standard Time' AS ValidFromPT,
ValidTo AT TIME ZONE 'Pacific Standard Time' AS ValidToPT
FROM Employee
FOR SYSTEM_TIME AS OF @asOf
WHERE EmployeeId = 1000;
Korzystanie z AT TIME ZONE jest przydatne we wszystkich innych scenariuszach, w których są używane tabele z wersjami systemu.
Warunki filtrowania określone w klauzulach czasowych z FOR SYSTEM_TIME są optymalizowalne za pomocą SARG (Search ARGument). SARG oznacza argument wyszukiwania, a sarg-able oznacza, że program SQL Server może używać bazowego indeksu klastrowanego do wykonywania wyszukiwania zamiast operacji skanowania. Aby uzyskać więcej informacji, zobacz Architektura indeksu programu SQL Server i przewodnik dotyczący projektowania.
Jeśli bezpośrednio zapytujesz tabelę historii, upewnij się, że warunek filtrowania jest również SARG-owalny, określając filtry w formie <period column> { < | > | =, ... } date_condition AT TIME ZONE 'UTC'.
W przypadku zastosowania AT TIME ZONE do kolumn okresowych program SQL Server wykonuje skanowanie tabeli lub indeksu, co może być bardzo kosztowne. Unikaj tego typu warunku w zapytaniach:
<period column> AT TIME ZONE '<your time zone>' > {< | > | =, ...} date_condition.
Aby uzyskać więcej informacji, zobacz Zapytania do danych w tabeli tymczasowej z wersjonowaniem systemowym.
Analiza punktowa w czasie (podróż w czasie)
Zamiast skupiać się na zmianach w poszczególnych rekordach, scenariusze podróży w czasie pokazują, jak zmieniają się całe zestawy danych w czasie. Czasami podróż w czasie obejmuje kilka powiązanych tabel czasowych, z których każda zmienia się w niezależnym tempie i które chcesz przeanalizować.
- Trendy dotyczące ważnych wskaźników w danych historycznych i bieżących
- Dokładna migawka wszystkich danych "od" dowolnego punktu w czasie w przeszłości (wczoraj, miesiąc temu itp.)
- Różnice między dwoma punktami w czasie zainteresowania (miesiąc temu a trzy miesiące temu, na przykład)
Istnieje wiele rzeczywistych scenariuszy, które wymagają analizy podróży w czasie. Aby zilustrować ten scenariusz użycia, przyjrzymy się OLTP z autogenerowaną historią.
OLTP z automatycznie wygenerowaną historią danych
W systemach przetwarzania transakcji można przeanalizować, jak ważne metryki zmieniają się w czasie. W idealnym przypadku analizowanie historii nie powinno naruszać wydajności aplikacji OLTP, w której dostęp do najnowszego stanu danych musi wystąpić z minimalnym opóźnieniem i blokowaniem danych. Tabele czasowe w wersji systemowej umożliwiają przezroczyste przechowywanie pełnej historii zmian na potrzeby późniejszej analizy, niezależnie od bieżących danych, przy minimalnym wpływie na główne obciążenie OLTP.
W przypadku dużych obciążeń przetwarzania transakcyjnego w programach SQL Server i Azure SQL Managed Instance zalecamy używanie tabel czasowych z wersjonowaniem systemowym oraz zoptymalizowanych pod kątem pamięci tabel, co pozwala przechowywać bieżące dane w pamięci i pełną historię zmian na dysku w sposób ekonomiczny.
W przypadku tabeli historii zalecamy użycie klastrowanego indeksu magazynującego kolumny z następujących powodów:
Typowe korzyści z analizy trendów wynikają z wydajności zapytań, jaką zapewnia klastrowany indeks Columnstore.
Zadanie czyszczenia danych z tabel pamięciowo zoptymalizowanych działa najlepiej przy dużym obciążeniu OLTP, gdy tabela historii ma indeks klastrowanego magazynu kolumn.
Indeks klastrowanego magazynu kolumn zapewnia doskonałą kompresję, szczególnie w scenariuszach, w których nie wszystkie kolumny są zmieniane w tym samym czasie.
Użycie tabel czasowych z funkcją OLTP w pamięci zmniejsza konieczność przechowywania całego zestawu danych w pamięci i umożliwia łatwe rozróżnienie między danymi gorącymi i zimnymi.
Przykłady rzeczywistych scenariuszy, które dobrze pasują do tej kategorii, to między innymi zarządzanie zapasami lub handel walutami.
Na poniższym diagramie przedstawiono uproszczony model danych używany do zarządzania zapasami:

Poniższy przykład kodu tworzy ProductInventory jako systemowo wersjonowaną tabelę czasową w pamięci, z klastrowanym indeksem magazynu kolumn w tabeli historii (co faktycznie zastępuje domyślnie utworzony indeks magazynu wierszy).
Notatka
Upewnij się, że baza danych umożliwia tworzenie tabel zoptymalizowanych pod kątem pamięci. Zobacz Tworzenie tabeli Memory-Optimized i tworzenie natywnie skompilowanej procedury składowanej.
USE TemporalProductInventory;
GO
BEGIN
--If table is system-versioned, SYSTEM_VERSIONING must be set to OFF first
IF ((SELECT temporal_type
FROM SYS.TABLES
WHERE object_id = OBJECT_ID('dbo.ProductInventory', 'U')) = 2)
BEGIN
ALTER TABLE [dbo].[ProductInventory]
SET (SYSTEM_VERSIONING = OFF);
END
DROP TABLE IF EXISTS [dbo].[ProductInventory];
DROP TABLE IF EXISTS [dbo].[ProductInventoryHistory];
END
GO
CREATE TABLE [dbo].[ProductInventory] (
ProductId INT NOT NULL,
LocationID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity >= 0),
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START NOT NULL,
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo),
--Primary key definition
CONSTRAINT PK_ProductInventory PRIMARY KEY NONCLUSTERED (
ProductId,
LocationId
)
)
WITH (
MEMORY_OPTIMIZED = ON,
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductInventoryHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
CREATE CLUSTERED COLUMNSTORE INDEX IX_ProductInventoryHistory
ON [ProductInventoryHistory] WITH (DROP_EXISTING = ON);
W przypadku poprzedniego modelu procedura konserwacji spisu może wyglądać następująco:
CREATE PROCEDURE [dbo].[spUpdateInventory]
@productId INT,
@locationId INT,
@quantityIncrement INT
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
UPDATE dbo.ProductInventory
SET Quantity = Quantity + @quantityIncrement
WHERE ProductId = @productId
AND LocationId = @locationId
-- If zero rows were updated then this is an insert
-- of the new product for a given location
IF @@rowcount = 0
BEGIN
IF @quantityIncrement < 0
SET @quantityIncrement = 0
INSERT INTO [dbo].[ProductInventory] (
[ProductId], [LocationID], [Quantity]
)
VALUES (@productId, @locationId, @quantityIncrement)
END
END;
Procedura składowana spUpdateInventory wstawia nowy produkt do magazynu lub aktualizuje ilość produktu dla określonej lokalizacji. Logika biznesowa jest prosta i koncentruje się na zachowaniu najnowszego stanu dokładnego przez cały czas przez zwiększanie/ dekrementowanie pola Quantity za pomocą aktualizacji tabeli, podczas gdy tabele z wersjami systemowymi w sposób przezroczysty dodają wymiar historii do danych, jak pokazano na poniższym diagramie.

Teraz wykonywanie zapytań o najnowszy stan można wydajnie wykonać z natywnie skompilowanego modułu:
CREATE PROCEDURE [dbo].[spQueryInventoryLatestState]
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
SELECT ProductId, LocationID, Quantity, ValidFrom
FROM dbo.ProductInventory
ORDER BY ProductId, LocationId
END;
GO
EXEC [dbo].[spQueryInventoryLatestState];
Analizowanie zmian danych w czasie staje się łatwe za pomocą klauzuli FOR SYSTEM_TIME ALL, jak pokazano w poniższym przykładzie:
DROP VIEW IF EXISTS vw_GetProductInventoryHistory;
GO
CREATE VIEW vw_GetProductInventoryHistory
AS
SELECT ProductId,
LocationId,
Quantity,
ValidFrom,
ValidTo
FROM [dbo].[ProductInventory]
FOR SYSTEM_TIME ALL;
GO
SELECT * FROM vw_GetProductInventoryHistory
WHERE ProductId = 2;
Na poniższym diagramie przedstawiono historię danych dla jednego produktu, który można łatwo renderować importując poprzedni widok w dodatku Power Query, usłudze Power BI lub podobnym narzędziu do analizy biznesowej:

Tabele czasowe mogą być używane w tym scenariuszu do wykonywania innych typów analizy podróży czasowych, takich jak odtworzenie stanu spisu AS OF dowolnym punkcie w czasie w przeszłości lub porównanie migawek należących do różnych momentów w czasie.
W tym scenariuszu użycia można również rozszerzyć tabele Product and Location, aby stały się tabelami czasowym, aby umożliwić późniejsze analizowanie historii zmian UnitPrice i NumberOfEmployee.
ALTER TABLE Product ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Product
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ProductHistory));
ALTER TABLE [Location] ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DFValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DFValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE [Location]
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.LocationHistory));
Ponieważ model danych obejmuje teraz wiele tabel czasowych, najlepszym rozwiązaniem dla analizy AS OF jest utworzenie widoku, który wyodrębnia niezbędne dane z powiązanych tabel i stosuje FOR SYSTEM_TIME AS OF do widoku, ponieważ znacznie upraszcza to odtworzenie stanu całego modelu danych:
DROP VIEW IF EXISTS vw_ProductInventoryDetails;
GO
CREATE VIEW vw_ProductInventoryDetails
AS
SELECT PrInv.ProductId,
PrInv.LocationId,
P.ProductName,
L.LocationName,
PrInv.Quantity,
P.UnitPrice,
L.NumberOfEmployees,
P.ValidFrom AS ProductStartTime,
P.ValidTo AS ProductEndTime,
L.ValidFrom AS LocationStartTime,
L.ValidTo AS LocationEndTime,
PrInv.ValidFrom AS InventoryStartTime,
PrInv.ValidTo AS InventoryEndTime
FROM dbo.ProductInventory AS PrInv
INNER JOIN dbo.Product AS P
ON PrInv.ProductId = P.ProductID
INNER JOIN dbo.Location AS L
ON PrInv.LocationId = L.LocationID;
GO
SELECT * FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF '2022-01-01';
Poniższy zrzut ekranu przedstawia plan wykonania wygenerowany dla zapytania SELECT. Pokazuje to, że aparat bazy danych obsługuje całą złożoność podczas pracy z relacjami czasowymi:

Użyj następującego kodu, aby porównać stan spisu produktów między dwoma punktami w czasie (dzień temu i miesiąc temu):
DECLARE @dayAgo DATETIME2 = DATEADD (DAY, -1, SYSUTCDATETIME());
DECLARE @monthAgo DATETIME2 = DATEADD (MONTH, -1, SYSUTCDATETIME());
SELECT inventoryDayAgo.ProductId,
inventoryDayAgo.ProductName,
inventoryDayAgo.LocationName,
inventoryDayAgo.Quantity AS QuantityDayAgo,
inventoryMonthAgo.Quantity AS QuantityMonthAgo,
inventoryDayAgo.UnitPrice AS UnitPriceDayAgo,
inventoryMonthAgo.UnitPrice AS UnitPriceMonthAgo
FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @dayAgo AS inventoryDayAgo
INNER JOIN vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @monthAgo AS inventoryMonthAgo
ON inventoryDayAgo.ProductId = inventoryMonthAgo.ProductId
AND inventoryDayAgo.LocationId = inventoryMonthAgo.LocationID;
Wykrywanie anomalii
Wykrywanie anomalii (lub wykrywanie wartości odstających) to identyfikacja elementów, które nie są zgodne z oczekiwanym wzorcem lub innymi elementami w zestawie danych. Tabele czasowe w wersji systemowej można używać do wykrywania anomalii, które występują okresowo lub nieregularnie, ponieważ można użyć wykonywania zapytań czasowych w celu szybkiego zlokalizowania określonych wzorców. Anomalia zależy od typu zbieranych danych i logiki biznesowej.
W poniższym przykładzie przedstawiono uproszczoną logikę wykrywania "skoków" w liczbach sprzedaży. Załóżmy, że pracujesz z tabelą czasową, która zbiera historię zakupionych produktów:
CREATE TABLE [dbo].[Product] (
[ProdID] [int] NOT NULL PRIMARY KEY CLUSTERED,
[ProductName] [varchar](100) NOT NULL,
[DailySales] INT NOT NULL,
[ValidFrom] [datetime2] GENERATED ALWAYS AS ROW START NOT NULL,
[ValidTo] [datetime2] GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME([ValidFrom], [ValidTo])
)
WITH (
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
Na poniższym diagramie przedstawiono zakupy w czasie:

Przy założeniu, że w zwykłe dni liczba zakupionych produktów ma niewielką wariancję, następujące zapytanie identyfikuje pojedyncze wartości odstające: próbki, których różnice w porównaniu do bezpośrednich sąsiadów są znaczące (dwukrotnie większe), podczas gdy sąsiednie próbki nie różnią się znacząco (mniej niż 20%):
WITH CTE (
ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo
)
AS (
SELECT ProdId,
LAG(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS PrevValue,
DailySales,
LEAD(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS NextValue,
ValidFrom,
ValidTo
FROM Product
FOR SYSTEM_TIME ALL
)
SELECT ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo,
ABS(PrevValue - NextValue) / convert(FLOAT, (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END)) AS PrevToNextDiff,
ABS(CurrentValue - PrevValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END)) AS CurrentToPrevDiff,
ABS(CurrentValue - NextValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END)) AS CurrentToNextDiff
FROM CTE
WHERE ABS(PrevValue - NextValue) / (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END) < 0.2
AND ABS(CurrentValue - PrevValue) / (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END) > 2
AND ABS(CurrentValue - NextValue) / (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END) > 2;
Notatka
Ten przykład jest celowo uproszczony. W scenariuszach produkcyjnych prawdopodobnie użyjesz zaawansowanych metod statystycznych, aby zidentyfikować próbki, które nie są zgodne ze wspólnym wzorcem.
Powolne zmienianie wymiarów
Wymiary magazynowania danych zwykle zawierają stosunkowo statyczne dane dotyczące jednostek, takich jak lokalizacje geograficzne, klienci lub produkty. Jednak niektóre scenariusze wymagają śledzenia zmian danych w tabelach wymiarów. Biorąc pod uwagę, że modyfikacje wymiarów występują znacznie rzadziej, w nieprzewidywalny sposób i poza regularnym harmonogramem aktualizacji, który ma zastosowanie do tabel faktów, te typy tabel wymiarów są nazywane powoli zmieniającymi się wymiarami (SCD).
Istnieje kilka kategorii wolno zmieniających się wymiarów na podstawie sposobu zachowania historii zmian:
| Typ wymiaru | Szczegóły |
|---|---|
| typ 0 | Historia nie jest zachowywana. Atrybuty wymiaru odzwierciedlają oryginalne wartości. |
| typ 1 | Atrybuty wymiaru odzwierciedlają najnowsze wartości (poprzednie wartości są zastępowane) |
| typ 2 | Każda wersja członka wymiaru jest reprezentowana jako oddzielny wiersz w tabeli, zwykle z kolumnami, które przedstawiają okres ważności. |
| typ 3 | Utrzymywanie ograniczonej historii wybranych atrybutów przy użyciu dodatkowych kolumn w tym samym wierszu |
| Typ 4 | Przechowywanie historii w oddzielnej tabeli, podczas gdy oryginalna tabela wymiarów przechowuje najnowsze (bieżące) wersje elementów członkowskich wymiaru |
Kiedy wybierasz strategię SCD, odpowiedzialność leży po stronie warstwy ETL (Extract-Transform-Load), aby utrzymać dokładność tabel wymiarów, co zwykle wymaga bardziej złożonego kodu i dodatkowej konserwacji.
Tabele czasowe w wersji systemowej mogą służyć do znacznego obniżenia złożoności kodu, ponieważ historia danych jest automatycznie zachowywana. Biorąc pod uwagę implementację przy użyciu dwóch tabel, tabele czasowe znajdują się najbliżej typu 4 SCD. Jednak ponieważ zapytania czasowe umożliwiają odwołanie tylko do bieżącej tabeli, można również rozważyć tabele czasowe w środowiskach, w których planujesz używać typu 2 SCD.
Aby przekonwertować zwykły wymiar na scD, można utworzyć nowy lub zmienić istniejącą, aby stać się tabelą czasową w wersji systemowej. Jeśli istniejąca tabela wymiarów zawiera dane historyczne, utwórz oddzielną tabelę i przenieś tam dane historyczne i zachowaj bieżące (rzeczywiste) wersje wymiarów w oryginalnej tabeli wymiarów. Następnie użyj składni ALTER TABLE, aby przekonwertować tabelę wymiarów na tabelę czasową z wersją systemową ze wstępnie zdefiniowaną tabelą historii.
Poniższy przykład ilustruje proces i zakłada, że tabela wymiarów DimLocation ma już ValidFrom i ValidTo jako datetime2 kolumn niepustych, które są wypełniane przez proces ETL:
/* Move "closed" row versions into newly created history table*/
SELECT * INTO DimLocationHistory
FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
GO
/* Create clustered columnstore index which is a very good choice in DW scenarios*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_DimLocationHistory ON DimLocationHistory;
/* Delete previous versions from DimLocation which will become current table in temporal-system-versioning configuration*/
DELETE FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
/* Add period definition*/
ALTER TABLE DimLocation
ADD PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
/* Enable system-versioning and bind history table to the DimLocation*/
ALTER TABLE DimLocation
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DimLocationHistory));
Nie jest wymagany dodatkowy kod do obsługi protokołu SCD podczas procesu ładowania magazynu danych po jego utworzeniu.
Na poniższej ilustracji pokazano, jak można używać tabel czasowych w prostym przypadku, który obejmuje dwa SCD (DimLocation i DimProduct) oraz jedną tabelę faktów.

Aby móc używać poprzednich SCD w raportach, należy efektywnie dostosowywać zapytania. Na przykład możesz chcieć obliczyć łączną kwotę sprzedaży i średnią liczbę sprzedanych produktów na mieszkańca w ciągu ostatnich sześciu miesięcy. Obie metryki wymagają korelacji danych z tabeli faktów i wymiarów, które mogły zmienić ich atrybuty ważne dla analizy (DimLocation.NumOfCustomers, DimProduct.UnitPrice). Następujące zapytanie prawidłowo oblicza wymagane metryki:
DECLARE @now DATETIME2 = SYSUTCDATETIME();
DECLARE @sixMonthsAgo DATETIME2;
SET @sixMonthsAgo = DATEADD(month, - 12, SYSUTCDATETIME());
SELECT DimProduct_History.ProductId,
DimLocation_History.LocationId,
SUM(F.Quantity * DimProduct_History.UnitPrice) AS TotalAmount,
AVG(F.Quantity / DimLocation_History.NumOfCustomers) AS AverageProductsPerCapita
FROM FactProductSales F
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimLocation
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimLocation_History
ON DimLocation_History.LocationId = F.LocationId
AND F.FactDate BETWEEN DimLocation_History.ValidFrom AND DimLocation_History.ValidTo
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimProduct
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimProduct_History
ON DimProduct_History.ProductId = F.ProductId
AND F.FactDate BETWEEN DimProduct_History.ValidFrom AND DimProduct_History.ValidTo
WHERE F.FactDate BETWEEN @sixMonthsAgo AND @now
GROUP BY DimProduct_History.ProductId, DimLocation_History.LocationId;
Zagadnienia dotyczące
Używanie tabel czasowych z wersją systemową dla SCD jest dopuszczalne, o ile okres ważności, liczony na podstawie czasu transakcji w bazie danych, jest zgodny z logiką biznesową. W przypadku ładowania danych z dużym opóźnieniem czas transakcji może nie być akceptowalny.
Domyślnie tabele czasowe w wersji systemowej nie zezwalają na zmianę danych historycznych po załadowaniu (można zmodyfikować historię po ustawieniu SYSTEM_VERSIONING na OFF). Może to być ograniczenie w przypadkach, w których zmiana danych historycznych odbywa się regularnie.
Tymczasowe tabele z wersjami systemu generują wersję wiersza dla każdej zmiany kolumny. Jeśli chcesz pominąć nowe wersje w przypadku określonej zmiany kolumny, musisz uwzględnić to ograniczenie w logice ETL.
Jeśli spodziewasz się znacznej liczby wierszy historycznych w tabelach SCD, rozważ użycie klastrowanego indeksu kolumnowego jako głównej opcji przechowywania dla tabeli historycznej. Użycie indeksu magazynu kolumn zmniejsza rozmiar tabeli historii i przyspiesza wykonywanie zapytań analitycznych.
Naprawianie uszkodzenia danych na poziomie wiersza
Możesz polegać na danych historycznych w tabelach czasowych z wersjonowaniem systemowym, aby szybko przywrócić poszczególne wiersze do dowolnego z wcześniej zapamiętanych stanów. Ta właściwość tabel czasowych jest przydatna, gdy można zlokalizować wiersze, których dotyczy problem, i/lub gdy znasz czas niepożądanej zmiany danych. Ta wiedza umożliwia wydajną naprawę bez konieczności obsługi kopii zapasowych.
Takie podejście ma kilka zalet:
Możesz dokładnie kontrolować zakres naprawy. Rekordy, których nie dotyczy problem, muszą pozostawać w stanie najnowszym, co często jest wymaganiem krytycznym.
Operacja jest wydajna, a baza danych pozostaje w trybie online dla wszystkich obciążeń korzystających z danych.
Sama operacja naprawy jest wersjonowana. Masz dziennik inspekcji dla samej operacji naprawy, więc w razie potrzeby możesz przeanalizować, co się stało później.
Akcja naprawy może być zautomatyzowana z względną łatwością. W następnym przykładzie kodu przedstawiono procedurę składowaną, która wykonuje naprawę danych dla tabeli Employee używanych w scenariuszu inspekcji danych.
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecord;
GO
CREATE PROCEDURE sp_RepairEmployeeRecord
@EmployeeID INT,
@versionNumber INT = 1
AS
WITH History
AS (
/* Order historical rows by their age in DESC order*/
SELECT
ROW_NUMBER() OVER (PARTITION BY EmployeeID
ORDER BY [ValidTo] DESC) AS RN,
*
FROM Employee FOR SYSTEM_TIME ALL
WHERE YEAR(ValidTo) < 9999 AND Employee.EmployeeID = @EmployeeID
)
/* Update current row by using N-th row version from history (default is 1 - i.e. last version) */
UPDATE Employee
SET [Position] = H.[Position],
[Department] = H.Department,
[Address] = H.[Address],
AnnualSalary = H.AnnualSalary
FROM Employee E
INNER JOIN History H ON E.EmployeeID = H.EmployeeID AND RN = @versionNumber
WHERE E.EmployeeID = @EmployeeID;
Ta procedura składowana przyjmuje @EmployeeID i @versionNumber jako parametry wejściowe. Ta procedura domyślnie przywraca stan wiersza do ostatniej wersji z historii (@versionNumber = 1).
Na poniższej ilustracji przedstawiono stan wiersza przed wywołaniem procedury i po nim. Czerwony prostokąt oznacza bieżącą wersję wiersza, która jest niepoprawna, podczas gdy zielony prostokąt oznacza poprawną wersję z historii.

EXEC sp_RepairEmployeeRecord @EmployeeID = 1, @versionNumber = 1;

Tę procedurę składowaną naprawy można zdefiniować tak, aby akceptowała dokładny znacznik czasu zamiast wersji wiersza. Przywraca wiersz do dowolnej wersji, która była aktywna w określonym momencie czasu (czyli w momencie AS OF).
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecordAsOf;
GO
CREATE PROCEDURE sp_RepairEmployeeRecordAsOf
@EmployeeID INT,
@asOf DATETIME2
AS
/* Update current row to the state that was actual AS OF provided date*/
UPDATE Employee
SET [Position] = History.[Position],
[Department] = History.Department,
[Address] = History.[Address],
AnnualSalary = History.AnnualSalary
FROM Employee AS E
INNER JOIN Employee FOR SYSTEM_TIME AS OF @asOf AS History
ON E.EmployeeID = History.EmployeeID
WHERE E.EmployeeID = @EmployeeID;
W przypadku tego samego przykładu danych na poniższej ilustracji przedstawiono scenariusz naprawy z warunkiem czasu. Wyróżnione są parametr @asOf, wybrany wiersz w historii, który był rzeczywisty w podanym punkcie w czasie, a nowa wersja wiersza w bieżącej tabeli po operacji naprawy:

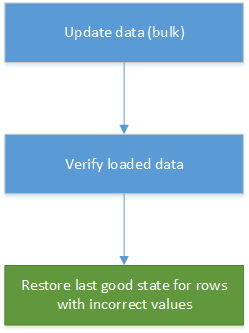
Korekta danych może stać się częścią zautomatyzowanego ładowania danych w systemach magazynowania i raportowania danych. Jeśli nowo zaktualizowana wartość nie jest poprawna, to w wielu scenariuszach przywrócenie poprzedniej wersji z historii jest wystarczającym rozwiązaniem. Na poniższym diagramie pokazano, jak można zautomatyzować ten proces:
Powiązana zawartość
- tabel czasowych
- Rozpoczynanie pracy z tabelami czasowymi w wersji systemowej
- sprawdzanie spójności systemu tabel czasowych
- partycja z tabelami czasowymi
- rozważania i ograniczenia dotyczące tabeli czasowej
- zabezpieczenia tabel czasowych
- Tabele z wersjonowaniem systemowym dla danych czasowych z tabelami zoptymalizowanymi pod kątem pamięci
- Widoki i funkcje metadanych tabeli czasowej