How online index operations work
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
This article defines the structures that exist during an online index operation and shows the activities associated with these structures.
Online index structures
To allow for concurrent user activity during an index data definition language (DDL) operation, the following structures are used during the online index operation: source and preexisting indexes, target, and for rebuilding a heap or dropping a clustered index online, a temporary mapping index.
Source and preexisting indexes
The source is the original table or clustered index data. Preexisting indexes are any nonclustered indexes that are associated with the source structure. For example, if the online index operation is rebuilding a clustered index that has four associated nonclustered indexes, the source is the existing clustered index and the preexisting indexes are the nonclustered indexes.
The preexisting indexes are available to concurrent users for select, insert, update, and delete operations. This includes bulk inserts (supported but not recommended during an online index operation) and implicit updates by triggers and referential integrity constraints. All preexisting indexes are available for queries. This means they might be selected by the query optimizer and, if necessary, specified in index hints.
Target
The target or targets is the new index (or heap) or a set of new indexes that is being created or rebuilt. User insert, update, and delete operations to the source are applied by the Database Engine to the target during the index operation. For example, if the online index operation is rebuilding a clustered index, the target is the rebuilt clustered index; the Database Engine doesn't rebuild nonclustered indexes when a clustered index is rebuilt.
The target index isn't used until the index operation is committed. Internally, the index is marked as write-only.
Temporary mapping index
Online index operations that create, drop, or rebuild a clustered index also require a temporary mapping index. This temporary index is used by concurrent transactions to determine which records to delete in the new indexes that are being built when rows in the source table are updated or deleted. This nonclustered index is created in the same step as the new clustered index (or heap) and doesn't require a separate sort operation. Concurrent transactions maintain the temporary mapping index in all their insert, update, and delete operations.
Online index activities
During an online index operation, such as creating a clustered index on a nonindexed table (heap), the source and target go through three phases: preparation, build, and final.
You can use the progress_report_online_index_operation extended event to monitor the progress of an online index operation.
The following illustration shows the process for creating an initial clustered index online. The source object (the heap) has no other indexes. The source and target structure activities are shown for each phase; concurrent user SELECT, INSERT, UPDATE, and DELETE operations are also shown. The preparation, build, and final phases are indicated together with the lock modes used in each phase.
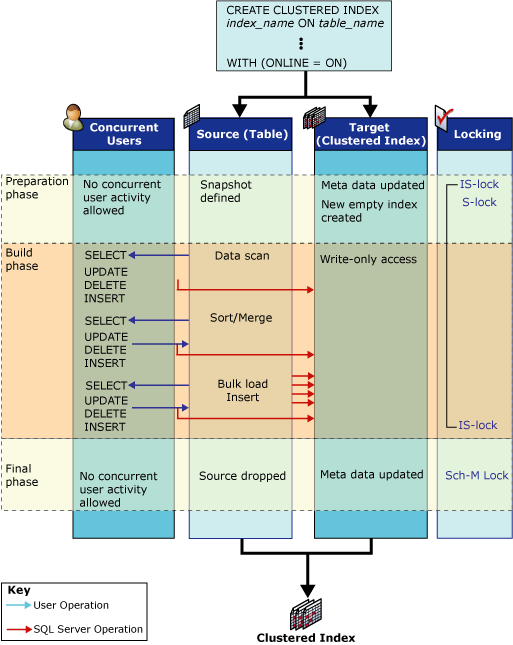
Source structure activities
The following table lists the activities involving the source structures during each phase of the index operation and the corresponding locking strategy.
| Phase | Source activity | Source locks |
|---|---|---|
| Preparation Short phase |
System metadata preparation to create the new empty index structure. A snapshot of the table is defined. That is, row versioning is used to provide transaction-level read consistency. Concurrent user write operations on the source are blocked for a short period. No concurrent DDL operations are allowed except creating multiple nonclustered indexes. |
Shared (S) on the table1Intent shared ( IS)Schema modification ( Sch-M) object lock with the resource subtype INDEX_OPERATION2 |
| Build Main phase |
The data is scanned, sorted, merged, and inserted into the target using bulk load operations. Concurrent user INSERT, UPDATE, DELETE, and MERGE operations are applied to both the preexisting indexes and any new indexes being built. |
Intent shared (IS)Sch-M object lock with the resource subtype INDEX_OPERATION2 |
| Final Short phase |
All uncommitted write transactions must complete before this phase starts. Depending on the acquired lock, all new user read or write transactions are blocked for a short period until this phase completes. System metadata is updated to replace the source with the target. The source is dropped if required, for example after rebuilding or dropping a clustered index. |
Sch-M object lock with the resource subtype INDEX_OPERATION2Shared ( S) on the table if creating a nonclustered index.1Sch-M if any source structure (index or table) is dropped.1 |
1 The index operation waits for any uncommitted write transactions to complete before acquiring the S lock or the Sch-M lock on the table. If a long running query is taking place, the online index operation waits until the query has finished. Unless low priority locks are used, this might form a blocking chain.
2 A Sch-M object lock with the resource subtype INDEX_OPERATION prevents the execution of concurrent data definition language (DDL) operations on the source and preexisting structures while the index operation is in progress. For example, this lock prevents concurrent rebuild of two indexes on the same table. Although this is a Sch-M lock, it doesn't prevent data manipulation statements.
The previous table shows a single shared (S) lock acquired during the build phase of an online index operation that involves a single index. When clustered and nonclustered indexes are built, or rebuilt, in a single online index operation (for example, during the initial clustered index creation on a table that contains one or more nonclustered indexes) two short-term S locks are acquired during the build phase followed by long-term intent shared (IS) locks. One S lock is acquired first for the clustered index creation. When the clustered index is created, a second short-term S lock is acquired for creating the nonclustered indexes. After the nonclustered indexes are created, the S lock is downgraded to an IS lock until the final phase of the online index operation.
For more information about how locks are used and how you can manage them, see WAIT_AT_LOW_PRIORITY with online index operations.
Target structure activities
The following table lists the activities that involve the target structure during each phase of the index operation and the corresponding locking strategy.
| Phase | Target activity | Target locks |
|---|---|---|
| Preparation | New index is created and set to write-only. | Intent shared (IS) |
| Build | Data is inserted from source. User modifications (inserts, updates, deletes) applied to the source are also applied to target. This activity is transparent to the user. |
Intent shared (IS) |
| Final | Index metadata is updated. Index is set to the read/write status. |
Shared (S) or schema modification (Sch-M) |
The target isn't accessed by user queries until the index operation is completed.
After the preparation or final phase is complete, query plans that are stored in the plan cache might be invalidated.
The lifetime of a cursor declared on a table that is involved in an online index operation is limited by the online index phases. Update cursors are invalidated at each phase. Read-only cursors are invalidated only after the final phase.