Zasady i wytyczne dotyczące limitów czasu dzierżawy, klastra i monitorowania kondycji dla grup Always On dostępności
Różnice w konfiguracji sprzętu, oprogramowania i klastra, a także różne wymagania aplikacji dotyczące czasu pracy i wydajności wymagają określonej konfiguracji dla wartości limitu czasu dzierżawy, klastra i kontroli kondycji. Niektóre aplikacje i obciążenia wymagają bardziej agresywnego monitorowania, aby ograniczyć przestoje po twardych awariach. Inne wymagają większej tolerancji dla przejściowych problemów z siecią oraz akceptacji wysokiego obciążenia zasobów i są w porządku z wolniejszym przełączaniem awaryjnym.
Wiele usług w każdym węźle działa w celu wykrywania błędów. Usługa klastrowania może wykryć utratę kworum, biblioteka DLL zasobu może wykryć problem napotkany podczas wykrywania kondycji Always On, lub może zostać zainicjowane ręczne przejście w tryb failover bezpośrednio na wystąpieniu podstawowym. Usługa klastrowania, host zasobów i wystąpienie programu SQL Server są synchronizowane ze sobą za pośrednictwem procedury RPC, pamięci udostępnionej i języka T-SQL. W większości scenariuszy te usługi pomyślnie komunikują się, jednak ta komunikacja nie jest całkowicie niezawodna nawet między usługami na tym samym komputerze. Ponadto grupa dostępności (AG) musi być w stanie wytrzymać systemowe zdarzenia, takie jak awarie sieci i dysków, które mogą uniemożliwić komunikację lub zakłócić działanie. Przy wielu awariach i bez pełnej niezawodności komunikacji między usługami AG polega na różnych mechanizmach wykrywania i obsługi awarii w celu ich wykrywania i reagowania na nie niezależnie od siebie, co zapewnia, że stan klastra jest zawsze spójny dla wszystkich węzłów.
Wykrywanie węzła klastra i zasobów
Każdy węzeł w klastrze obsługuje jedną usługę klastra, która zarządza klasterem w trybie przełączenia awaryjnego i monitoruje wszystkie zasoby klastra. Host zasobów działa jako oddzielny proces i jest interfejsem między usługą klastra a zasobami klastra. Host zasobów wykonuje operacje na zasobach klastra, gdy jest wywoływany przez usługę klastra. Aplikacje obsługujące klaster, takie jak SQL Server, udostępniają niestandardowe interfejsy monitorowi zasobów za pośrednictwem bibliotek DLL zasobów. Biblioteka DLL zasobów implementuje operacje online i offline oraz monitorowanie kondycji zasobów niestandardowych. Host zasobów jest procesem podrzędnym usługi klastrowania i jest zabijany za każdym razem, gdy usługa klastra zostanie zabita.
W przypadku programu SQL Server biblioteka DLL zasobu AG określa kondycję AG na podstawie mechanizmu dzierżawy AG i wykrywania kondycji Always On. Biblioteka DLL zasobu AG prezentuje kondycję zasobu za pośrednictwem operacji IsAlive. Monitor zasobów sonduje IsAlive w interwale pulsu klastra, który jest ustawiany przez wartości CrossSubnetDelay i SameSubnetDelay w całym klastrze. Na węźle podstawowym usługa klastra inicjuje failover za każdym razem, gdy wywołanie IsAlive do biblioteki DLL zasobu zwróci, że grupa dostępności (AG) nie jest zdrowa.
Usługa klastrowania wysyła pulsy do innych węzłów w klastrze i potwierdza odebrane od nich pulsy. Gdy węzeł wykryje błąd komunikacji z serii niezaznaczonych pulsów, emituje komunikat powodujący, że wszystkie dostępne węzły uzgadniają ich widoki kondycji węzła klastra. To zdarzenie, nazywane zdarzeniem przegrupowania, zachowuje spójność stanu klastra między węzłami. Po zdarzeniu przegrupowania, jeśli kworum zostanie utracone, wszystkie zasoby klastra, w tym grupy AG w tej partycji, zostaną przełączone w tryb offline. Wszystkie węzły w tej partycji są przenoszone do stanu rozwiązywania. Jeśli istnieje partycja zawierająca kworum, AG jest przypisana do jednego węzła i staje się repliką podstawową, podczas gdy wszystkie pozostałe węzły stają się replikami pomocniczymi.
Zawsze włączone wykrywanie zdrowia
Biblioteka zasobów Always On monitoruje stan wewnętrznych składników programu SQL Server.
sp_server_diagnostics raportuje kondycję tych składników programu SQL Server w interwale kontrolowanym przez program HealthCheckTimeout.
sp_server_diagnostics raportuje stan kondycji pięciu składników na poziomie wystąpienia: system, zasób, przetwarzanie zapytań, podsystem io i zdarzenia. Raportuje również kondycję każdej AG. Podczas każdej aktualizacji biblioteka DLL zasobu aktualizuje stan kondycji zasobu AG w oparciu o poziom awarii AG. Kiedy dane są zwracane przez sp_server_diagnostics, pokazuje stan każdego składnika w stanie czystym, ostrzeżenia, błędu lub nieznanym, z danymi XML, które opisują stan składnika. W przypadku monitorowania stanu zdrowia biblioteka DLL zasobu podejmuje działania tylko wtedy, gdy składnik jest w stanie błędu.
Jeśli wykrywanie kondycji nie zgłosi aktualizacji do biblioteki DLL zasobu przez kilka interwałów, grupa dostępności zostanie uznana za niewłaściwą i zgłosi błędy podczas wywołań IsAlive.
Mechanizm dzierżawy
W przeciwieństwie do innych mechanizmów failover, instancja programu SQL Server odgrywa aktywną rolę w mechanizmie dzierżawy. Mechanizm dzierżawy jest używany jako Looks-Alive walidacji między hostem zasobów klastra a procesem programu SQL Server. Mechanizm służy do zapewnienia, że obie strony (usługa klastrowania i usługa SQL Server) pozostają w częstym kontakcie, sprawdzając wzajemnie swoje stany i ostatecznie uniemożliwiając scenariusz split-brain. Podczas przełączania grupy dostępności w tryb online jako repliki podstawowej wystąpienie programu SQL Server zduplikuje dedykowany wątek procesu roboczego dzierżawy dla grupy dostępności. Proces roboczy dzierżawy udostępnia mały region pamięci hostowi zasobów zawierającego zdarzenia odnawiania dzierżawy i zatrzymywania dzierżawy. Pracownik dzierżawy i gospodarz zasobów pracują w sposób cykliczny, sygnalizując swoje zdarzenie odnowienia dzierżawy, a następnie śpiąc, czekając, aż druga strona zasygnalizuje własne zdarzenie odnowienia dzierżawy lub zdarzenie zatrzymania. Zarówno host zasobów, jak i wątek dzierżawy programu SQL Server utrzymują wartość czasu życia, która jest aktualizowana za każdym razem, gdy wątek jest wznawiany po otrzymaniu sygnału od innego wątku. Jeśli czas wygaśnięcia zostanie osiągnięty podczas oczekiwania na sygnał, dzierżawa wygaśnie, a następnie nastąpi przejście repliki do stanu rozpoznawania dla tej konkretnej grupy dostępności. Jeśli zostanie zasygnalizowane zdarzenie zatrzymania dzierżawy, replika przechodzi do roli rozwiązywania.
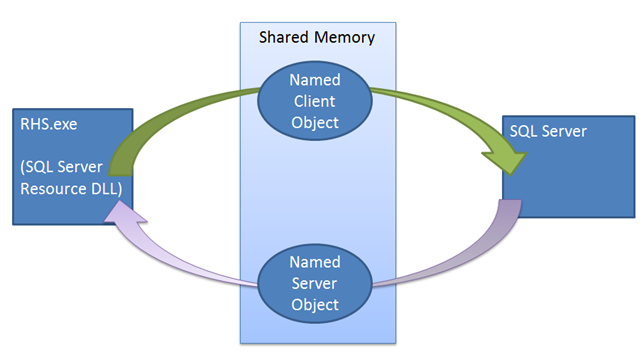
Mechanizm dzierżawy wymusza synchronizację między programem SQL Server i klastrem trybu failover systemu Windows Server. Po wydaniu polecenia trybu failover usługa klastra wykonuje wywołanie Offline do biblioteki DLL zasobu bieżącej repliki podstawowej. Biblioteka DLL zasobu najpierw próbuje przełączyć Grupę Dostępności w tryb offline przy użyciu procedury składowanej. Jeśli ta procedura składowana zakończy się niepowodzeniem lub upłynie limit czasu, błąd zostanie zgłoszony z powrotem do usługi klastra, która następnie wydaje polecenie zakończenia. Proces zakończenia ponownie próbuje wykonać tę samą procedurę składowaną, ale tym razem klaster nie czeka, aż biblioteka DLL zasobu zgłosi powodzenie lub niepowodzenie, zanim aktywuje grupę dostępności na nowej replice. Jeśli drugie wywołanie procedury zakończy się niepowodzeniem, host zasobów musi polegać na mechanizmie dzierżawy, aby przełączyć wystąpienie w tryb offline. Gdy biblioteka DLL zasobu jest wywoływana w celu przełączenia grupy dostępności w tryb offline, biblioteka DLL zasobu sygnalizuje zdarzenie zatrzymania dzierżawy, budząc wątek procesu roboczego dzierżawy programu SQL Server, aby przejąć grupę dostępności w tryb offline. Nawet jeśli to zdarzenie zatrzymania nie zostanie zasygnalizowane, dzierżawa wygaśnie, a replika przejdzie do trybu rozpoznawania.
Dzierżawa jest przede wszystkim mechanizmem synchronizacji między wystąpieniem pierwotnym a klastrem, ale może również tworzyć warunki awarii, w których nie było potrzeby przełączenia awaryjnego. Na przykład wysokie użycie CPU, brak pamięci (mała ilość pamięci wirtualnej, stronicowanie procesów), proces SQL nie odpowiada podczas generowania zrzutu pamięci, system nie odpowiada, klaster (WSFC) przechodzący w tryb offline (np. z powodu utraty kworum) może uniemożliwić odnowienie dzierżawy z instancji SQL i spowodować ponowne uruchomienie lub przełączenie awaryjne (failover).
Wskazówki dotyczące wartości limitu czasu klastra
Uważnie zastanów się nad kompromisami i zapoznaj się z konsekwencjami korzystania z mniej agresywnego monitorowania klastra programu SQL Server. Zwiększenie wartości limitu czasu klastra zwiększa tolerancję przejściowych problemów z siecią, ale spowalnia reakcje na twarde awarie. Zwiększenie limitów czasu w celu radzenia sobie z presją zasobów lub dużym opóźnieniem geograficznym zwiększy również czas odzyskiwania po awariach twardych lub nieodzyskiwalnych. Chociaż jest to akceptowalne dla wielu aplikacji, nie jest idealnym rozwiązaniem we wszystkich przypadkach.
Ustawienia domyślne są zoptymalizowane pod kątem szybkiego reagowania na objawy trudnych awarii i ograniczania przestojów, ale te ustawienia mogą być również nadmiernie agresywne dla niektórych obciążeń i konfiguracji. Nie zaleca się obniżenia wartości LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThresholdlub HealthCheckTimeout poza ich wartościami domyślnymi. Prawidłowe ustawienia dla każdego wdrożenia różnią się i prawdopodobnie wymagają dłuższego okresu doprecyzowania, aby je odkryć. Podczas wprowadzania zmian w dowolnej z tych wartości wprowadź je stopniowo i z uwzględnieniem relacji i zależności między tymi wartościami.
Relacja między limitem czasu klastra a limitem czasu dzierżawy
Podstawową funkcją mechanizmu dzierżawy jest przełączenie zasobu SQL Server do trybu offline, jeśli usługa klastrowania nie może się komunikować z instancją podczas przełączania awaryjnego do innego węzła. Gdy klaster wykonuje operację offline na zasobie grupy dostępności klastra, usługa klastrowania wykonuje wywołanie RPC, aby rhs.exe przejąć zasób w tryb offline. Biblioteka DLL zasobów używa procedur składowanych, aby poinformować program SQL Server o przełączeniu grupy dostępności w tryb offline, ale ta procedura składowana może zakończyć się niepowodzeniem lub przekroczeniem limitu czasu. Host zasobów zatrzymuje również własny wątek odnawiania dzierżawy podczas wywołania trybu offline. W najgorszym przypadku program SQL Server powoduje wygaśnięcie dzierżawy w 1/2 * LeaseTimeout i przeniesienie wystąpienia do stanu rozpoznawania. Przełączenia awaryjne mogą być inicjowane przez różne podmioty, ale niezwykle ważne jest, aby widok stanu klastra był spójny w klastrze i w instancjach SQL Server. Załóżmy na przykład scenariusz, w którym wystąpienie podstawowe traci połączenie z resztą klastra. Każdy węzeł w klastrze wykrywa awarię w podobnym czasie ze względu na wartości limitu czasu klastra, ale tylko węzeł podstawowy może wchodzić w interakcje z podstawowym wystąpieniem SQL Server, aby wymusić rezygnację z roli podstawowej.
Z perspektywy węzła podstawowego usługa klastra straciła kworum, a usługa zaczyna się kończyć. Usługa klastrowania wystawia wywołanie RPC do hosta zasobów w celu zakończenia procesu. To wywołanie zakończenia jest odpowiedzialne za przełączenie grupy dostępności w tryb offline w wystąpieniu programu SQL Server. To wywołanie offline odbywa się za pośrednictwem języka T-SQL, ale nie można zagwarantować, że uda się pomyślnie nawiązać połączenie między SQL a biblioteką DLL zasobów.
Z perspektywy pozostałej części klastra nie ma obecnie repliki podstawowej, więc klaster głosuje i ustanawia jedną nową replikę podstawową dla pozostałych węzłów klastra. Jeśli procedura składowana, która została wywołana przez bibliotekę DLL zasobu, zakończy się niepowodzeniem lub upłynął limit czasu, klaster może być narażony na scenariusz podziału mózgu.
Czas wygaśnięcia dzierżawy zapobiega scenariuszom typu 'split brain' w obliczu błędów komunikacji. Nawet jeśli cała komunikacja nie powiedzie się, proces biblioteki DLL zasobu zakończy się i nie będzie mógł zaktualizować dzierżawy. Po wygaśnięciu dzierżawy AG zostanie automatycznie przełączone do trybu offline. Wystąpienie programu SQL Server musi być świadome, że nie hostuje już repliki podstawowej, zanim klaster ustanowi nową. Ponieważ pozostała część klastra, która jest odpowiedzialna za wybranie nowej repliki podstawowej, nie ma możliwości koordynacji z bieżącą repliką podstawową, wartości limitu czasu zapewniają, że nowa replika podstawowa nie zostanie ustanowiona, zanim bieżący podstawowy przełączy się w tryb offline.
Gdy klaster przejdzie w tryb failover, instancja SQL Server, która hostuje poprzednią replikę podstawową, musi przejść do stanu rozwiązywania, zanim nowa replika podstawowa została uruchomiona. Wątek dzierżawy w SQL Server ma w każdej chwili pozostały czas życia równy ½ * LeaseTimeout, ponieważ za każdym razem, gdy dzierżawa zostanie odnowiona, nowy czas życia jest aktualizowany do LeaseInterval lub ½ * LeaseTimeout. Jeśli usługa klastra lub host zasobów zostaną zatrzymane lub zakończą się bez sygnalizowania zdarzenia zatrzymania dzierżawy, klaster uzna węzeł podstawowy za martwy po upływie SameSubnetThreshold\ SameSubnetDelay milisekund. W tym czasie dzierżawa musi wygasnąć, aby zagwarantować, że główna będzie w trybie offline. Ponieważ maksymalny limit czasu wygaśnięcia dla limitu czasu dzierżawy wynosi 1/2 * LeaseTimeout, 1/2 * LeaseTimeout musi być mniejszy niż SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold \<= CrossSubnetThreshold i SameSubnetDelay \<= CrossSubnetDelay powinny być prawdziwe dla wszystkich klastrów programu SQL Server.
Operacja limitu czasu sprawdzania stanu zdrowia
Limit czasu sprawdzenia kondycji jest bardziej elastyczny, ponieważ żaden inny mechanizm przełączania awaryjnego nie zależy od niego bezpośrednio. Domyślna wartość 30 sekund ustawia interwał sp_server_diagnostics na 10 sekund, z minimalną wartością limitu czasu wynoszącą 15 sekund i interwałem 5-sekundowym. Ogólnie rzecz biorąc, interwał aktualizacji sp_server_diagnostics zawsze wynosi 1/3 * HealthCheckTimeout. Gdy biblioteka DLL zasobu nie otrzymuje nowego zestawu danych kondycji w pewnych odstępach czasu, nadal używa danych kondycji z poprzedniego interwału w celu określenia bieżącej kondycji grupy dostępności i instancji. Zwiększenie wartości limitu czasu kontroli kondycji sprawia, że główny serwer staje się bardziej odporny na obciążenie procesora CPU, co może uniemożliwić sp_server_diagnostics dostarczanie nowych danych w każdym przedziale czasowym, jednak polega na przestarzałych informacjach o kondycji danych przez dłuższy czas. Niezależnie od wartości limitu czasu, po odebraniu danych wskazujących, że replika jest niezdrowa, następne wywołanie IsAlive zwróci, że instancja jest niezdrowa, a usługa klastra zainicjuje przełączenie awaryjne.
Poziom warunków awarii AG zmienia warunki niepowodzenia sprawdzenia kondycji. W przypadku dowolnego poziomu awarii, jeśli element AG jest zgłaszany przez sp_server_diagnostics jako w złej kondycji, kontrola kondycji kończy się niepowodzeniem. Każdy poziom dziedziczy wszystkie warunki awarii z poziomów poniżej.
| Poziom | Warunek, w którym instancja jest uznawana za martwą |
|---|---|
| 1: OnServerDown | Sprawdzanie kondycji nie podejmuje żadnych działań, jeśli jakiekolwiek zasoby zawiodą oprócz grupy dostępności (AG). Jeśli dane AG nie są odbierane w ciągu 5 interwałów lub 5/3 * HealthCheckTimeout |
| 2: OnServerUnresponsive | Jeśli żadne dane nie są odbierane z sp_server_diagnostics dla elementu HealthCheckTimeout |
| 3: OnCriticalServerError | (Ustawienie domyślne) Jeśli składnik systemowy zgłasza błąd |
| 4: OnModerateServerError | Jeśli składnik zasobu zgłasza błąd |
| 5: W przypadku jakichkolwiek kwalifikowanych warunków niepowodzenia | Jeśli składnik przetwarzania zapytań zgłasza błąd |
Aktualizacja wartości limitu czasu klastra i Always On
Wartości klastra
W konfiguracji usługi WSFC istnieją cztery wartości, które są odpowiedzialne za określanie wartości limitu czasu klastra:
- SameSubnetDelay
- Próg Tej Samej Podsieci
- CrossSubnetDelay
- Próg między podsieciami
Wartości opóźnienia określają czas oczekiwania między pulsami z usługi klastra, a wartości progowe określają liczbę pulsów, które nie mogą odbierać potwierdzenia z węzła docelowego lub zasobu, zanim obiekt zostanie zadeklarowany jako martwy przez klaster. Jeśli między węzłami w tej samej podsieci nie ma pomyślnego sygnału przez więcej niż SameSubnetDelay \* SameSubnetThreshold milisekund, wówczas węzeł jest uznawany za martwy. To samo dotyczy komunikacji między podsieciami z wykorzystaniem wartości przeznaczonych do komunikacji między podsieciami.
Aby wyświetlić listę wszystkich bieżących wartości klastra, w dowolnym węźle w klastrze docelowym otwórz terminal programu PowerShell z podwyższonym poziomem uprawnień. Uruchom następujące polecenie:
Get-Cluster | fl *
Aby zaktualizować dowolną z tych wartości, uruchom następujące polecenie w terminalu programu PowerShell z podwyższonym poziomem uprawnień:
(Get-Cluster).<ValueName> = <NewValue>
Przy zwiększaniu iloczynu opóźnienia i progu w celu uzyskania większej tolerancji limitu czasu klastra, bardziej skuteczne jest najpierw zwiększenie wartości opóźnienia przed zwiększeniem progu. Zwiększając opóźnienie, czas między poszczególnymi pulsami jest zwiększany. Większy odstęp między sygnałami serca daje więcej czasu na samoistne rozwiązanie przejściowych problemów z siecią i zmniejszenie przeciążenia sieci w porównaniu z wysyłaniem większej liczby sygnałów w tym samym okresie.
Limit czasu dzierżawy
Mechanizm dzierżawy jest kontrolowany przez jedną wartość specyficzną dla każdej grupy dostępności (AG) w klastrze WSFC. Przekroczenie limitu czasu dzierżawy może spowodować następujące błędy:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
Aby zmodyfikować wartość limitu czasu dzierżawy, użyj Menedżera Klastra Przełączania Awaryjnego i postępuj zgodnie z poniższym procesem:
Na karcie ról znajdź docelową rolę AG. Wybierz docelową rolę AG.
Kliknij prawym przyciskiem myszy zasób AG na dole okna i wybierz pozycję Właściwości.
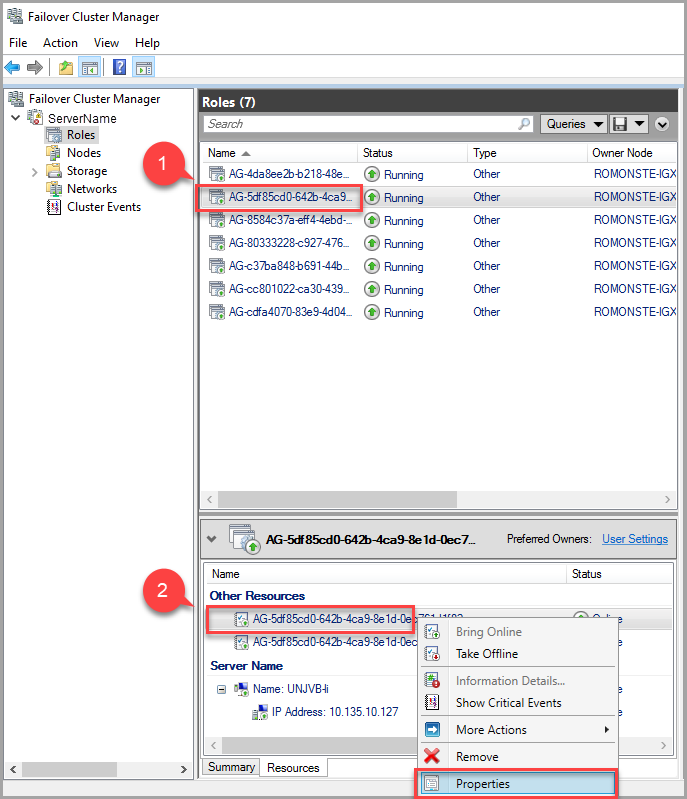
W oknie podręcznym przejdź do karty właściwości, aby wyświetlić listę wartości specyficznych dla tej grupy dostępności (AG). Wybierz wartość LeaseTimeout, aby ją zmienić.
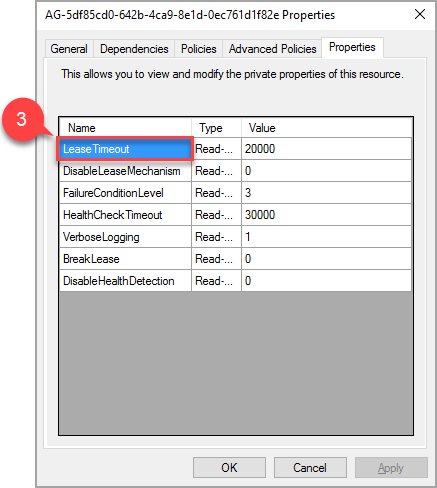
W zależności od konfiguracji grupy dostępności mogą istnieć dodatkowe zasoby dla odbiorników, dysków udostępnionych, udziałów plików itp., te zasoby nie wymagają żadnej dodatkowej konfiguracji.
Notatka
Nowa wartość właściwości "LeaseTimeout" zacznie obowiązywać po przełączeniu zasobu do trybu offline i przełączeniu go ponownie do trybu online.
Wskaźniki kontroli stanu zdrowia
Dwie wartości kontrolują sprawdzanie kondycji Always On: FailureConditionLevel i HealthCheckTimeout. Wartość FailureConditionLevel wskazuje poziom tolerancji do określonych warunków awarii zgłoszonych przez sp_server_diagnostics, a parametr HealthCheckTimeout konfiguruje czas, przez który biblioteka DLL zasobu może przejść bez otrzymywania aktualizacji z sp_server_diagnostics. Interwał aktualizacji dla sp_server_diagnostics jest zawsze HealthCheckTimeout / 3.
Aby skonfigurować poziom warunku failover, użyj opcji FAILURE_CONDITION_LEVEL = <n> w instrukcji CREATE lub ALTERAVAILABILITY GROUP, gdzie <n> jest liczbą całkowitą od 1 do 5. Następujące polecenie ustawia poziom kryterium awarii na 1 dla grupy dostępności "AG1":
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Aby skonfigurować limit czasu sprawdzania kondycji, użyj opcji HEALTH_CHECK_TIMEOUT instrukcji CREATE lub ALTERAVAILABILITY GROUP. Następujące polecenie ustawia limit czasu kontroli kondycji na 60 000 milisekund dla AG AG1.
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Podsumowanie wytycznych dotyczących limitu czasu
Obniżenie wartości limitu czasu poniżej wartości domyślnych nie jest zalecane.
Okres dzierżawy (½ * LeaseTimeout) musi być krótszy niż SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Ustawienie limitu czasu | Cel | Między | Zastosowania | IsAlive & LooksAlive | Przyczyny | Wynik |
|---|---|---|---|---|---|---|
| Limit czasu dzierżawy domyślna : 20000 |
Zapobieganie rozstaniu mózgu | Główny klaster (HADR) |
obiektów zdarzeń systemu Windows | Używane w obu | System operacyjny nie odpowiada, mała ilość pamięci wirtualnej, stronicowanie zestawu roboczego, generowanie zrzutu, maksymalne obciążenie CPU, awaria WSFC (utrata kworum) | Zasób AG w trybie offline-online, przełączenie awaryjne |
| Limit czasu sesji ustawienie domyślne : 10000 |
Zgłoś problem z komunikacją między głównym i pomocniczym | Z drugorzędnej do podstawowej (HADR) |
gniazda TCP (komunikaty wysyłane za pośrednictwem punktu końcowego DBM) | Nie używane w żadnym | Komunikacja sieciowa, Problemy z systemem pomocniczym — niedostępny, system operacyjny nie odpowiada, konkurencja o zasoby |
Pomocnicza — ROZŁĄCZONA |
| Limit czasu kontroli kondycji domyślna : 30000 |
Wskazuje limit czasu podczas próby określenia kondycji repliki podstawowej | Klaster do podstawowego (FCI & HADR) |
sp_server_diagnostics języka T-SQL | Używane w obu | Spełnione warunki awarii, system operacyjny nie odpowiada, mała ilość pamięci wirtualnej, przycinanie zestawu roboczego, generowanie zrzutu, WSFC (utrata kworum), problemy z harmonogramem (martwe zablokowane harmonogramy) | Zasób AG Offline-online lub Failover, ponowne uruchomienie/przełączenie awaryjne klastra FCI |