Tworzenie, eksportowanie i ocenianie modeli uczenia maszynowego platformy Spark w klastrach danych big data programu SQL Server
Ważny
Dodatek Microsoft SQL Server 2019 Big Data Clusters zostanie wycofany. Obsługa klastrów danych big data programu SQL Server 2019 zakończy się 28 lutego 2025 r. Wszyscy istniejący użytkownicy programu SQL Server 2019 z pakietem Software Assurance będą w pełni obsługiwani na platformie, a oprogramowanie będzie nadal utrzymywane za pośrednictwem aktualizacji zbiorczych programu SQL Server do tego czasu. Aby uzyskać więcej informacji, zobacz wpis na blogu ogłoszenia i opcje dużych zbiorów danych na platformie Microsoft SQL Server.
W poniższym przykładzie pokazano, jak utworzyć model przy użyciu Spark ML, wyeksportować model do MLeapi ocenić model w programie SQL Server przy użyciu rozszerzenia języka Java. Odbywa się to w kontekście klastra danych big data programu SQL Server.
Na poniższym diagramie przedstawiono pracę wykonaną w tym przykładzie:
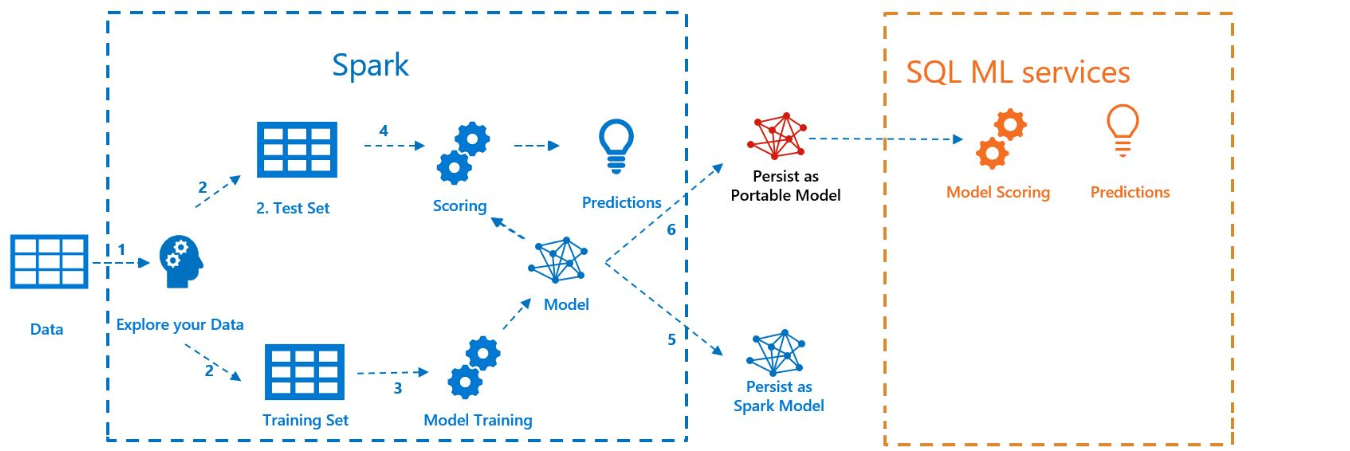
Warunki wstępne
Wszystkie pliki dla tego przykładu znajdują się w https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Aby uruchomić ten przykład, musisz spełniać następujące wymagania wstępne:
-
- kubectl
- curl
- Azure Data Studio
Trenowanie modelu za pomocą usługi Spark ML
W tym przykładzie dane spisu (AdultCensusIncome.csv) są używane do budowy modelu pipeline Spark ML.
Użyj pliku mleap_sql_test/setup.sh, aby pobrać zestaw danych z Internetu i umieścić go w systemie plików HDFS w klastrze danych big data programu SQL Server. Dzięki temu platforma Spark może uzyskiwać do niej dostęp.
Następnie pobierz przykładowy notatnik train_score_export_ml_models_with_spark.ipynb. W wierszu poleceń PowerShell lub bash uruchom następujące polecenie, aby pobrać notebooka:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Ten notes zawiera komórki z wymaganymi poleceniami dla tej sekcji przykładu.
Otwórz notes w narzędziu Azure Data Studio i uruchom każdy blok kodu. Aby uzyskać więcej informacji na temat pracy z notesami, zobacz Jak używać notesów z programem SQL Server.
Dane są najpierw odczytywane na platformie Spark i podzielone na zestawy danych trenowania i testowania. Następnie kod trenuje model pipeline'u przy użyciu danych treningowych. Na koniec eksportuje model do pakietu MLeap.
Napiwek
Możesz również przejrzeć lub uruchomić kod języka Python skojarzony z tymi krokami poza notesem w pliku mleap_sql_test/mleap_pyspark.py.
Ocenianie modelu za pomocą programu SQL Server
Teraz, gdy model potoku Spark ML znajduje się w typowym formacie serializacji pakietu MLeap, możesz przeprowadzić ocenę modelu w Javie bez użycia Spark.
W tym przykładzie użyto rozszerzenia językowego Java w programie SQL Server. Aby ocenić model w programie SQL Server, najpierw musisz utworzyć aplikację Java, która może załadować model do języka Java i ocenić go. Przykładowy kod dla tej aplikacji Java można znaleźć w folderze mssql-mleap-app.
Po utworzeniu przykładu możesz użyć Transact-SQL, aby wywołać aplikację Java i ocenić model za pomocą tabeli bazy danych. Można to zobaczyć w pliku źródłowym mleap_sql_test/mleap_sql_tests.py.
Następne kroki
Aby uzyskać więcej informacji na temat klastrów danych big data, zobacz Jak wdrożyć klastry danych big data programu SQL Server na platformie Kubernetes