Serializacja modelu danych do i z różnych magazynów (wersja zapoznawcza)
Aby model danych był przechowywany w bazie danych, musi zostać przekonwertowany na format, który może zrozumieć baza danych. Różne bazy danych wymagają różnych schematów i formatów przechowywania. Niektóre mają ścisły schemat, który musi być zgodny, a inne umożliwiają definiowanie schematu przez użytkownika.
Opcje mapowania
Łączniki magazynu wektorów udostępniane przez jądro semantyczne zapewniają wiele sposobów osiągnięcia tego mapowania.
Wbudowane mapowania
Łączniki magazynu wektorów udostępniane przez Jądro Semantyczne mają wbudowane mapowania, które będą przeprowadzać model danych do i ze schematów bazy danych. Zobacz dla każdego łącznika stronę
Niestandardowe mapowniki
Udostępniane przez jądro semantyczne wiązania magazynu wektorów umożliwiają korzystanie z niestandardowych maperów w połączeniu z VectorStoreRecordDefinition. W takim przypadku VectorStoreRecordDefinition może różnić się od dostarczonego modelu danych.
VectorStoreRecordDefinition służy do definiowania schematu bazy danych, podczas gdy model danych jest używany przez dewelopera do interakcji z magazynem wektorów.
W tym przypadku maper niestandardowy jest wymagany do mapowania z modelu danych na niestandardowy schemat bazy danych zdefiniowany przez VectorStoreRecordDefinition.
Napiwek
Zobacz How to build a custom mapper for a Vector Store connector (Jak utworzyć niestandardowy maper dla łącznika magazynu wektorów), aby zapoznać się z przykładem tworzenia własnego niestandardowego mapowania.
Aby model danych został zdefiniowany jako klasa lub definicja do przechowywania w bazie danych, musi być serializowany do formatu, który może zrozumieć baza danych.
Istnieją dwa sposoby, które można wykonać, używając wbudowanej serializacji dostarczonej przez jądro semantyczne lub dostarczając własną logikę serializacji.
Na poniższych dwóch diagramach przedstawiono przepływy zarówno dla serializacji, jak i deserializacji modeli danych do i z modelu magazynu.
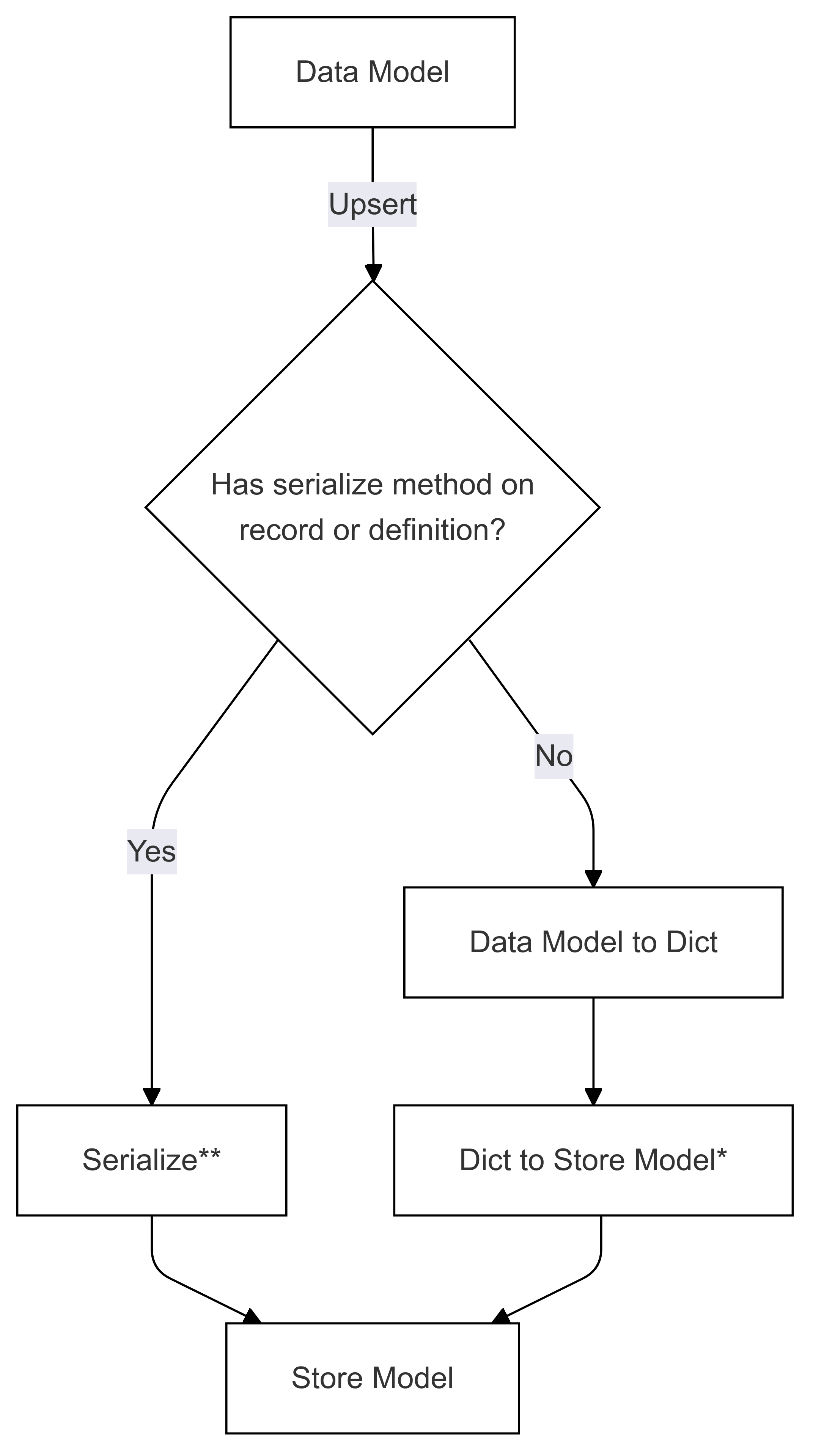
Przepływ serializacji (używany w operacji Upsert)
Przepływ deserializacji (używany w „Get” i „Search”)
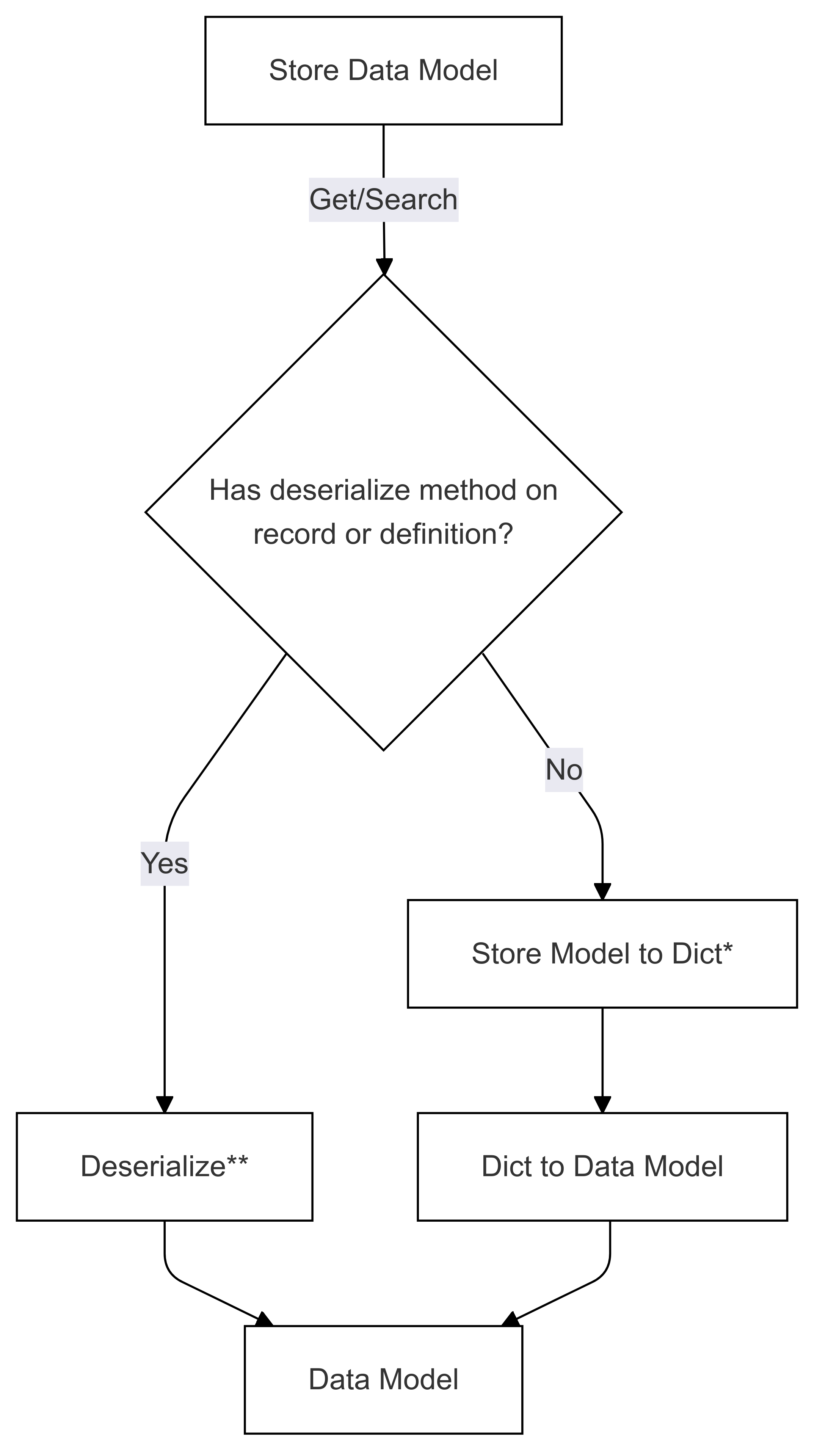
Kroki oznaczone znakiem * (w obu diagramach) są implementowane przez dewelopera określonego łącznika i są różne dla każdego magazynu. Kroki oznaczone znakiem ** (w obu diagramach) są dostarczane jako metoda w rekordzie lub w ramach definicji rekordu. Jest to zawsze dostarczane przez użytkownika. Aby uzyskać więcej informacji, zobacz Direct Serialization.
(De)Podejścia do serializacji
Serializacja bezpośrednia (model danych do modelu magazynu)
Serializacja bezpośrednia jest najlepszym sposobem zapewnienia pełnej kontroli nad sposobem serializacji modeli i optymalizacji wydajności. Wadą jest to, że jest on specyficzny dla magazynu danych, a zatem w przypadku korzystania z niego nie jest tak łatwo przełączać się między różnymi magazynami z tym samym modelem danych.
Można go użyć, implementując metodę zgodną z protokołem SerializeMethodProtocol w modelu danych lub dodając funkcje zgodne z SerializeFunctionProtocol do definicji rekordu, oba te elementy można znaleźć w semantic_kernel/data/vector_store_model_protocols.py.
Gdy jedna z tych funkcji jest obecna, będzie używana do bezpośredniego serializowania modelu danych w modelu magazynu.
Można nawet zaimplementować tylko jedną z tych dwóch metod, używając wbudowanej serializacji/deserializacji w przeciwnym kierunku. Może to być na przykład przydatne w przypadku obsługi kolekcji utworzonej poza Twoją kontrolą i trzeba wykonać pewne dostosowania w sposób, w jaki jest deserializowana, oraz nie możesz wykonać operacji upsert.
Wbudowana serializacja i deserializacja (model danych do słownika i słownik do modelu przechowywania i odwrotnie)
Wbudowana serializacja jest wykonywana przez najpierw przekonwertowanie modelu danych na słownik, a następnie serializacji go do modelu, który przechowuje rozumie, dla każdego magazynu, który jest inny i zdefiniowany jako część wbudowanego łącznika. Deserializacja jest wykonywana w odwrotnej kolejności.
Serializacja — krok 1. Model danych do Dyktowania
W zależności od rodzaju posiadanego modelu danych kroki są wykonywane na różne sposoby. Istnieją cztery sposoby próby serializacji modelu danych do słownika:
-
to_dictmetodę w definicji (dopasowuje się do atrybutu to_dict w modelu danych, zgodnie zToDictFunctionProtocol) - sprawdź, czy rekord jest
ToDictMethodProtocoli użyj metodyto_dict - Sprawdź, czy rekord jest modelem Pydantic i użyj
model_dumpmodelu; zapoznaj się z notatką poniżej, aby uzyskać więcej informacji. - Przejść przez pola w definicji i utworzyć słownik
Serializacja — krok 2. Dyktowanie do modelu magazynu
Metoda musi być dostarczona przez łącznik, aby przekonwertować słownik na model magazynu. Wykonywane jest to przez dewelopera łącznika i różni się dla każdego sklepu.
Deserializacja — krok 1. Przechowywanie modelu do dyktowania
Metoda musi zostać dostarczona przez łącznik, aby przekonwertować model magazynu na słownik. Jest to wykonywane przez dewelopera łącznika i różni się w zależności od sklepu.
Deserializacja — krok 2: Dyktowanie do modelu danych
Deserializacja jest wykonywana w odwrotnej kolejności, próbując następujące opcje:
- metoda
from_dictw definicji (jest zgodna z atrybutem from_dict modelu danych, zgodnie zFromDictFunctionProtocol) - sprawdź, czy rekord jest
FromDictMethodProtocoli użyj metodyfrom_dict - Sprawdź, czy rekord jest modelem Pydantic i użyj
model_validatemodelu. Więcej informacji znajduje się w poniższej notatce. - Przejdź przez pola w definicji i ustaw wartości, a następnie ten słownik jest przekazywany do konstruktora modelu danych jako argumenty nazwane (chyba że model danych jest sam w sobie słownikiem, w takim przypadku jest zwracany bez zmian).
Notatka
Używanie Pydantic z wbudowaną serializacją
Podczas definiowania modelu przy użyciu modelu Pydantic BaseModel użyje model_dump metod i model_validate do serializacji i deserializacji modelu danych do i z dyktowania. Jest to wykonywane przy użyciu metody model_dump bez żadnych parametrów, jeśli chcesz to kontrolować, rozważ zaimplementowanie ToDictMethodProtocol w modelu danych, tak jak to było wcześniej wypróbowane.
Serializacja wektorów
Jeśli masz wektor w modelu danych, musi być listą zmiennoprzecinkowych lub listą kropek, ponieważ jest to, czego potrzebuje większość magazynów, jeśli chcesz, aby klasa przechowywała wektor w innym formacie, możesz użyć serialize_function elementu i deserialize_function zdefiniowanego VectorStoreRecordVectorField w adnotacji. Na przykład dla tablicy numpy można użyć następującej adnotacji:
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
Jeśli używasz magazynu wektorów, który może obsługiwać natywne tablice numpy i nie chcesz ich konwertować tam i z powrotem, należy skonfigurować bezpośrednią serializacji i deserializacji metod dla modelu i tego magazynu.
Notatka
Jest to używane tylko w przypadku korzystania z wbudowanej serializacji, w przypadku korzystania z serializacji bezpośredniej można obsłużyć wektor w dowolny sposób.
Wkrótce
Więcej informacji wkrótce.