Co to jest wtyczka?
Wtyczki są kluczowym składnikiem jądra semantycznego. Jeśli używasz już wtyczek z rozszerzeń ChatGPT lub Copilot na platformie Microsoft 365, znasz je już. Dzięki wtyczkom możesz zebrać istniejące interfejsy API w kolekcję, która może być używana przez sztuczną inteligencję. Dzięki temu można nadać sztucznej inteligencji możliwość wykonywania akcji, których nie będzie można wykonać w inny sposób.
W tle semantyczne jądro wykorzystuje funkcję wywołującą, natywną funkcję większości najnowszych modułów LLM, aby umożliwić maszynom LLM wykonywanie planowania i wywoływanie interfejsów API. W przypadku wywoływania funkcji maszyny LLM mogą żądać (tj. wywołania) określonej funkcji. Semantyczne jądro następnie przekazuje żądanie do odpowiedniej funkcji w repozytorium kodu i zwraca wyniki do modelu LLM, aby model LLM mógł wygenerować ostateczną odpowiedź.
Nie wszystkie zestawy SDK sztucznej inteligencji mają analogiczną koncepcję wtyczek (większość ma tylko funkcje lub narzędzia). Jednak w scenariuszach dla przedsiębiorstw wtyczki są cenne, ponieważ hermetyzują zestaw funkcji, które odzwierciedlają sposób, w jaki deweloperzy przedsiębiorstwa już opracowują usługi i interfejsy API. Wtyczki również dobrze współpracują z wstrzykiwaniem zależności. W konstruktorze wtyczki można wstrzyknąć usługi, które są niezbędne do wykonania pracy wtyczki (np. połączeń z bazą danych, klientów HTTP itp.). Jest to trudne do osiągnięcia w przypadku innych zestawów SDK, które nie mają wtyczek.
Anatomia wtyczki
Na wysokim poziomie wtyczka jest grupą funkcji , które mogą być widoczne dla aplikacji i usług sztucznej inteligencji. Funkcje w ramach wtyczek mogą być następnie orkiestrowane przez aplikację sztucznej inteligencji w celu realizacji żądań użytkowników. W ramach jądra semantycznego można automatycznie wywoływać te funkcje za pomocą wywoływania funkcji.
Notatka
Na innych platformach funkcje są często określane jako "narzędzia" lub "akcje". W semantycznym jądrze używamy terminu "functions", ponieważ są one zwykle definiowane jako funkcje natywne w bazie kodu.
Samo dostarczanie funkcji nie wystarczy, aby stworzyć wtyczkę. Aby zapewnić automatyczną aranżację za pomocą wywoływania funkcji, wtyczki muszą również podać szczegółowe informacje, które semantycznie opisują sposób ich działania. Wszystko, od danych wejściowych, wyjściowych i skutków ubocznych funkcji, należy opisać w sposób, w jaki sztuczna inteligencja może zrozumieć, w przeciwnym razie sztuczna inteligencja nie będzie poprawnie wywoływać funkcji.
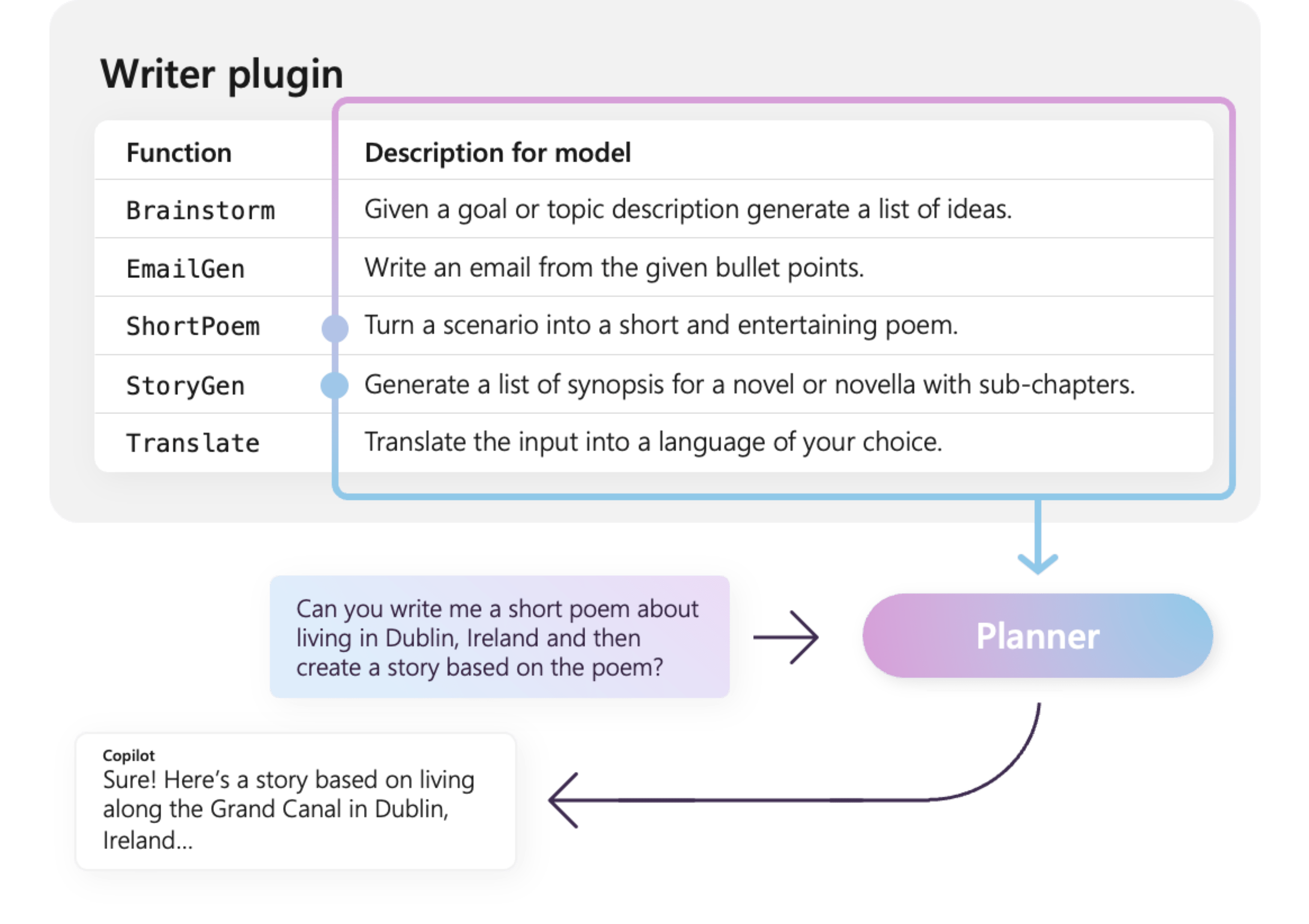
Na przykład przykładowa wtyczka WriterPlugin po prawej stronie zawiera funkcje z semantycznymi opisami, które opisują działanie każdej funkcji. LLM może następnie użyć tych opisów, aby wybrać najlepsze funkcje do wywołania w celu zaspokojenia prośby użytkownika.
Na zdjęciu po prawej stronie LLM prawdopodobnie wywoła funkcje ShortPoem i StoryGen, aby zrealizować prośbę użytkownika dzięki podanym opisom semantycznym.
Importowanie różnych typów wtyczek
Istnieją dwa podstawowe sposoby importowania wtyczek do jądra semantycznego: używanie kodu natywnego lub używanie specyfikacji interfejsu OpenAPI . Pierwsza umożliwia tworzenie wtyczek w istniejącej bazie kodu, które mogą korzystać z już posiadanych zależności i usług. Ten ostatni umożliwia importowanie wtyczek ze specyfikacji interfejsu OpenAPI, którą można udostępniać w różnych językach programowania i platformach.
Poniżej przedstawiono prosty przykład importowania i używania wtyczki natywnej. Aby dowiedzieć się więcej na temat importowania tych różnych typów wtyczek, zapoznaj się z następującymi artykułami:
Napiwek
Podczas rozpoczynania pracy zalecamy używanie wtyczek kodu natywnego. W miarę dojrzewania aplikacji i pracy w zespołach międzyplatformowych warto rozważyć użycie specyfikacji interfejsu OpenAPI do udostępniania wtyczek w różnych językach programowania i platformach.
Różne typy funkcji wtyczki
W ramach wtyczki zazwyczaj będziesz mieć dwa różne typy funkcji: takie, które pobierają dane na potrzeby rozszerzonej generacji (RAG), oraz takie, które automatyzują zadania. Mimo że każdy typ jest funkcjonalnie taki sam, są one zwykle używane inaczej w aplikacjach korzystających z jądra semantycznego.
Na przykład w przypadku funkcji pobierania warto użyć strategii w celu zwiększenia wydajności (np. buforowania i używania tańszych modeli pośrednich na potrzeby podsumowania). Podczas gdy w przypadku funkcji automatyzacji zadań prawdopodobnie będziesz chciał wdrożyć procesy zatwierdzania z udziałem człowieka, aby upewnić się, że zadania są wykonywane poprawnie.
Aby dowiedzieć się więcej o różnych typach funkcji wtyczek, zapoznaj się z następującymi artykułami:
Wprowadzenie do wtyczek
Używanie wtyczek w ramach jądra semantycznego jest zawsze procesem trzech kroków:
- Zdefiniuj swoją wtyczkę
- Dodaj wtyczkę do jądra
- a następnie wywołaj funkcje wtyczki, używając polecenia z funkcją wywołania
Poniżej przedstawimy ogólny przykład użycia wtyczki w ramach jądra semantycznego. Zapoznaj się z powyższymi linkami, aby uzyskać bardziej szczegółowe informacje na temat tworzenia wtyczek i korzystania z nich.
1) Definiowanie wtyczki
Najprostszym sposobem utworzenia wtyczki jest zdefiniowanie klasy i dodawanie adnotacji do jej metod za pomocą atrybutu KernelFunction. To informuje semantyczne jądro, że jest to funkcja, która może być wywoływana przez sztuczną inteligencję lub używana w zapytaniu.
Możesz również zaimportować wtyczki z specyfikacji OpenAPI .
Poniżej utworzymy wtyczkę, która może pobrać stan świateł i zmienić jego stan.
Napiwek
Ponieważ większość LLM została zaprogramowana z użyciem języka Python do wywoływania funkcji, zaleca się użycie notacji snake case dla nazw funkcji i nazw właściwości, nawet jeśli używasz SDK w językach C# lub Java.
using System.ComponentModel;
using Microsoft.SemanticKernel;
public class LightsPlugin
{
// Mock data for the lights
private readonly List<LightModel> lights = new()
{
new LightModel { Id = 1, Name = "Table Lamp", IsOn = false, Brightness = 100, Hex = "FF0000" },
new LightModel { Id = 2, Name = "Porch light", IsOn = false, Brightness = 50, Hex = "00FF00" },
new LightModel { Id = 3, Name = "Chandelier", IsOn = true, Brightness = 75, Hex = "0000FF" }
};
[KernelFunction("get_lights")]
[Description("Gets a list of lights and their current state")]
public async Task<List<LightModel>> GetLightsAsync()
{
return lights
}
[KernelFunction("get_state")]
[Description("Gets the state of a particular light")]
public async Task<LightModel?> GetStateAsync([Description("The ID of the light")] int id)
{
// Get the state of the light with the specified ID
return lights.FirstOrDefault(light => light.Id == id);
}
[KernelFunction("change_state")]
[Description("Changes the state of the light")]
public async Task<LightModel?> ChangeStateAsync(int id, LightModel LightModel)
{
var light = lights.FirstOrDefault(light => light.Id == id);
if (light == null)
{
return null;
}
// Update the light with the new state
light.IsOn = LightModel.IsOn;
light.Brightness = LightModel.Brightness;
light.Hex = LightModel.Hex;
return light;
}
}
public class LightModel
{
[JsonPropertyName("id")]
public int Id { get; set; }
[JsonPropertyName("name")]
public string Name { get; set; }
[JsonPropertyName("is_on")]
public bool? IsOn { get; set; }
[JsonPropertyName("brightness")]
public byte? Brightness { get; set; }
[JsonPropertyName("hex")]
public string? Hex { get; set; }
}
from typing import TypedDict, Annotated
class LightModel(TypedDict):
id: int
name: str
is_on: bool | None
brightness: int | None
hex: str | None
class LightsPlugin:
lights: list[LightModel] = [
{"id": 1, "name": "Table Lamp", "is_on": False, "brightness": 100, "hex": "FF0000"},
{"id": 2, "name": "Porch light", "is_on": False, "brightness": 50, "hex": "00FF00"},
{"id": 3, "name": "Chandelier", "is_on": True, "brightness": 75, "hex": "0000FF"},
]
@kernel_function
async def get_lights(self) -> List[LightModel]:
"""Gets a list of lights and their current state."""
return self.lights
@kernel_function
async def get_state(
self,
id: Annotated[int, "The ID of the light"]
) -> Optional[LightModel]:
"""Gets the state of a particular light."""
for light in self.lights:
if light["id"] == id:
return light
return None
@kernel_function
async def change_state(
self,
id: Annotated[int, "The ID of the light"],
new_state: LightModel
) -> Optional[LightModel]:
"""Changes the state of the light."""
for light in self.lights:
if light["id"] == id:
light["is_on"] = new_state.get("is_on", light["is_on"])
light["brightness"] = new_state.get("brightness", light["brightness"])
light["hex"] = new_state.get("hex", light["hex"])
return light
return None
public class LightsPlugin {
// Mock data for the lights
private final Map<Integer, LightModel> lights = new HashMap<>();
public LightsPlugin() {
lights.put(1, new LightModel(1, "Table Lamp", false));
lights.put(2, new LightModel(2, "Porch light", false));
lights.put(3, new LightModel(3, "Chandelier", true));
}
@DefineKernelFunction(name = "get_lights", description = "Gets a list of lights and their current state")
public List<LightModel> getLights() {
System.out.println("Getting lights");
return new ArrayList<>(lights.values());
}
@DefineKernelFunction(name = "change_state", description = "Changes the state of the light")
public LightModel changeState(
@KernelFunctionParameter(name = "id", description = "The ID of the light to change") int id,
@KernelFunctionParameter(name = "isOn", description = "The new state of the light") boolean isOn) {
System.out.println("Changing light " + id + " " + isOn);
if (!lights.containsKey(id)) {
throw new IllegalArgumentException("Light not found");
}
lights.get(id).setIsOn(isOn);
return lights.get(id);
}
}
Zwróć uwagę, że udostępniamy opisy funkcji i parametrów. Jest to ważne dla sztucznej inteligencji, aby zrozumieć, co robi funkcja i jak jej używać.
Napiwek
Nie bój się podawać szczegółowych opisów funkcji, jeśli sztuczna inteligencja ma problemy z ich wywoływaniem. Przykłady kilku strzałów, zalecenia dotyczące tego, kiedy należy użyć (i nie używać) funkcji, i wskazówki dotyczące tego, gdzie uzyskać wymagane parametry, mogą być przydatne.
2) Dodawanie wtyczki do jądra
Po zdefiniowaniu wtyczki możesz dodać ją do jądra, tworząc nowe wystąpienie wtyczki i dodając ją do kolekcji wtyczek jądra.
W tym przykładzie pokazano najprostszy sposób dodawania klasy jako wtyczki z metodą AddFromType. Aby dowiedzieć się więcej o innych sposobach dodawania wtyczek, zapoznaj się z artykułem dodawanie wtyczek natywnych.
var builder = new KernelBuilder();
builder.Plugins.AddFromType<LightsPlugin>("Lights")
Kernel kernel = builder.Build();
kernel = Kernel()
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
// Import the LightsPlugin
KernelPlugin lightPlugin = KernelPluginFactory.createFromObject(new LightsPlugin(),
"LightsPlugin");
// Create a kernel with Azure OpenAI chat completion and plugin
Kernel kernel = Kernel.builder()
.withAIService(ChatCompletionService.class, chatCompletionService)
.withPlugin(lightPlugin)
.build();
3) Wywoływanie funkcji wtyczki
Na koniec możesz użyć AI, aby wywołać funkcje wtyczki za pomocą wywołania funkcji. Poniżej przedstawiono przykład, który pokazuje, jak nakłonić AI do wywołania funkcji get_lights z pluginu Lights przed wywołaniem funkcji change_state, aby włączyć światło.
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Create a kernel with Azure OpenAI chat completion
var builder = Kernel.CreateBuilder().AddAzureOpenAIChatCompletion(modelId, endpoint, apiKey);
// Build the kernel
Kernel kernel = builder.Build();
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
// Add a plugin (the LightsPlugin class is defined below)
kernel.Plugins.AddFromType<LightsPlugin>("Lights");
// Enable planning
OpenAIPromptExecutionSettings openAIPromptExecutionSettings = new()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
// Create a history store the conversation
var history = new ChatHistory();
history.AddUserMessage("Please turn on the lamp");
// Get the response from the AI
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel);
// Print the results
Console.WriteLine("Assistant > " + result);
// Add the message from the agent to the chat history
history.AddAssistantMessage(result);
import asyncio
from semantic_kernel import Kernel
from semantic_kernel.functions import kernel_function
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.chat_completion_client_base import ChatCompletionClientBase
from semantic_kernel.contents.chat_history import ChatHistory
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.connectors.ai.open_ai.prompt_execution_settings.azure_chat_prompt_execution_settings import (
AzureChatPromptExecutionSettings,
)
async def main():
# Initialize the kernel
kernel = Kernel()
# Add Azure OpenAI chat completion
chat_completion = AzureChatCompletion(
deployment_name="your_models_deployment_name",
api_key="your_api_key",
base_url="your_base_url",
)
kernel.add_service(chat_completion)
# Add a plugin (the LightsPlugin class is defined below)
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
# Enable planning
execution_settings = AzureChatPromptExecutionSettings()
execution_settings.function_choice_behavior = FunctionChoiceBehavior.Auto()
# Create a history of the conversation
history = ChatHistory()
history.add_message("Please turn on the lamp")
# Get the response from the AI
result = await chat_completion.get_chat_message_content(
chat_history=history,
settings=execution_settings,
kernel=kernel,
)
# Print the results
print("Assistant > " + str(result))
# Add the message from the agent to the chat history
history.add_message(result)
# Run the main function
if __name__ == "__main__":
asyncio.run(main())
// Enable planning
InvocationContext invocationContext = new InvocationContext.Builder()
.withReturnMode(InvocationReturnMode.LAST_MESSAGE_ONLY)
.withToolCallBehavior(ToolCallBehavior.allowAllKernelFunctions(true))
.build();
// Create a history to store the conversation
ChatHistory history = new ChatHistory();
history.addUserMessage("Turn on light 2");
List<ChatMessageContent<?>> results = chatCompletionService
.getChatMessageContentsAsync(history, kernel, invocationContext)
.block();
System.out.println("Assistant > " + results.get(0));
Po wykonaniu powyższego kodu powinna zostać wyświetlona odpowiedź podobna do następującej:
| Rola | Komunikat |
|---|---|
| 🔵 użytkownika | Włącz lampę |
| 🔴 Asystent (wywołanie funkcji) | Lights.get_lights() |
| 🟢 narzędzia | [{ "id": 1, "name": "Table Lamp", "isOn": false, "brightness": 100, "hex": "FF0000" }, { "id": 2, "name": "Porch light", "isOn": false, "brightness": 50, "hex": "00FF00" }, { "id": 3, "name": "Chandelier", "isOn": true, "brightness": 75, "hex": "0000FF" }] |
| 🔴 Asystent (wywołanie funkcji) | Lights.change_state(1, { "isOn": true }) |
| 🟢 narzędzia | { "id": 1, "name": "Table Lamp", "isOn": true, "brightness": 100, "hex": "FF0000" } |
| 🔴 Asystent | Lampa jest teraz włączona |
Napiwek
Chociaż można bezpośrednio wywołać funkcję wtyczki, nie jest to zalecane, ponieważ sztuczna inteligencja powinna być jedyną decyzją o tym, które funkcje mają być wywoływane. Jeśli potrzebujesz jawnej kontroli nad wywoływanymi funkcjami, rozważ użycie standardowych metod w bazie kodu zamiast wtyczek.
Ogólne zalecenia dotyczące tworzenia wtyczek
Biorąc pod uwagę, że każdy scenariusz ma unikatowe wymagania, wykorzystuje różne projekty wtyczek i może zawierać wiele LLMs, trudno jest zapewnić uniwersalny przewodnik dotyczący projektowania wtyczek. Poniżej przedstawiono jednak kilka ogólnych zaleceń i wytycznych, aby zapewnić, że wtyczki są zgodne z zasadami sztucznej inteligencji i mogą być łatwo i efektywnie wykorzystywane przez LLMs.
Importowanie tylko niezbędnych wtyczek
Zaimportuj tylko wtyczki zawierające funkcje niezbędne do określonego scenariusza. Takie podejście nie tylko zmniejszy liczbę zużytych tokenów wejściowych, ale także zminimalizuje niezamierzone wywołania funkcji, które nie są używane w tym scenariuszu. Ogólnie rzecz biorąc, ta strategia powinna zwiększyć dokładność wywoływania funkcji i zmniejszyć liczbę wyników fałszywie dodatnich.
Ponadto OpenAI zaleca użycie nie więcej niż 20 narzędzi w jednym wywołaniu interfejsu API; najlepiej nie więcej niż 10 narzędzi. Jak stwierdzono przez OpenAI: "Zalecamy używanie nie więcej niż 20 narzędzi w jednym wywołaniu interfejsu API. Deweloperzy zazwyczaj zauważają zmniejszenie zdolności modelu do wyboru odpowiedniego narzędzia, gdy mają zdefiniowane od 10 do 20 narzędzi."* Aby uzyskać więcej informacji, zapoznaj się z dokumentacją w Przewodnik dotyczący wywoływania funkcji OpenAI.
Tworzenie wtyczek przyjaznych dla sztucznej inteligencji
Aby zwiększyć zdolność LLM do zrozumienia i korzystania z wtyczek, zalecane jest przestrzeganie następujących wytycznych:
Użyj opisowych i zwięzłych nazw funkcji: Upewnij się, że nazwy funkcji wyraźnie przekazują swój cel, aby ułatwić modelowi zrozumienie, kiedy wybrać każdą funkcję. Jeśli nazwa funkcji jest niejednoznaczna, rozważ zmianę jej nazwy w celu uzyskania jasności. Unikaj używania skrótów lub akronimów, aby skrócić nazwy funkcji. Skorzystaj z
DescriptionAttribute, aby udostępnić dodatkowy kontekst i instrukcje tylko wtedy, gdy jest to konieczne, minimalizując użycie tokenu.Minimalizuj parametry funkcji: Ograniczyć liczbę parametrów funkcji i używać typów pierwotnych zawsze, gdy jest to możliwe. Takie podejście zmniejsza zużycie tokenów i upraszcza sygnaturę funkcji, co ułatwia LLM efektywne dopasowywanie parametrów funkcji.
Wyraźnie nazwij parametry funkcji: Przypisz opisowe nazwy do parametrów funkcji, aby wyjaśnić ich przeznaczenie. Unikaj używania skrótów lub akronimów, aby skracać nazwy parametrów, ponieważ pomoże to LLM w rozumieniu parametrów i zapewnieniu dokładnych wartości. Podobnie jak w przypadku nazw funkcji, użyj
DescriptionAttributetylko wtedy, gdy jest to konieczne, aby zminimalizować użycie tokenu.
Znalezienie właściwej równowagi między liczbą funkcji a ich obowiązkami
Z jednej strony, posiadanie funkcji pełniących jedno zadanie jest dobrą praktyką, która pozwala zachować ich prostotę i możliwość ponownego użycia w różnych scenariuszach. Z drugiej strony każde wywołanie funkcji wiąże się z obciążeniem w zakresie opóźnienia rundy sieciowej oraz liczby użytych tokenów wejściowych i wyjściowych: tokeny wejściowe są używane do wysyłania definicji funkcji i wyniku wywołania do usługi LLM, podczas gdy tokeny wyjściowe są używane podczas odbierania wywołania funkcji z modelu.
Alternatywnie można zaimplementować jedną funkcję z wieloma obowiązkami, aby zmniejszyć liczbę wykorzystanych tokenów i mniejsze obciążenie sieci, chociaż wiąże się to z kosztem mniejszej możliwości ponownego zużycia w innych scenariuszach.
Jednak konsolidowanie wielu obowiązków w jednej funkcji może zwiększyć liczbę i złożoność parametrów funkcji oraz jej typ zwracany. Ta złożoność może prowadzić do sytuacji, w których model może mieć trudności z prawidłowym dopasowaniem parametrów funkcji, co skutkuje błędnymi parametrami lub wartościami nieprawidłowego typu. W związku z tym niezbędne jest określenie właściwej równowagi między liczbą funkcji w celu zmniejszenia obciążenia sieciowego a liczbą obowiązków, jakie ma każda funkcja, zapewniając, że model może dokładnie dopasować parametry funkcji.
Przekształcanie funkcji jądra semantycznego
Skorzystaj z technik przekształcania funkcji jądra semantycznego zgodnie z opisem w wpisie w blogu Transforming Semantic Kernel Functions:
Zmiana zachowania funkcji: Istnieją scenariusze, w których domyślne zachowanie funkcji może nie być zgodne z pożądanym wynikiem i nie ma możliwości zmodyfikowania implementacji oryginalnej funkcji. W takich przypadkach można utworzyć nową funkcję, która opakowuje oryginalną funkcję i odpowiednio modyfikuje jej zachowanie.
Podaj informacje kontekstowe: Funkcje mogą wymagać parametrów, których usługa LLM nie może lub nie powinna wywnioskować. Jeśli na przykład funkcja musi działać w imieniu bieżącego użytkownika lub wymaga informacji uwierzytelniania, ten kontekst jest zazwyczaj dostępny dla aplikacji hosta, ale nie dla usługi LLM. W takich przypadkach można przekształcić funkcję w celu wywołania oryginalnej, podając niezbędne informacje kontekstowe z aplikacji hostującej wraz z argumentami dostarczonymi przez LLM.
Zmień listę parametrów, typy i nazwy: Jeśli oryginalna funkcja ma złożony podpis, którego moduł LLM ma trudności z interpretacją, możesz przekształcić funkcję w taką z prostszym podpisem, który moduł LLM łatwiej zrozumie. Może to obejmować zmianę nazw parametrów, typów, liczby parametrów oraz spłaszczanie lub przywracanie struktury złożonych parametrów i inne korekty.
Wykorzystanie stanu lokalnego
Podczas projektowania wtyczek, które działają na stosunkowo dużych lub poufnych zestawach danych, takich jak dokumenty, artykuły lub wiadomości e-mail zawierające poufne informacje, rozważ użycie stanu lokalnego do przechowywania oryginalnych danych lub wyników pośrednich, które nie muszą być wysyłane do usługi LLM. Funkcje dla takich scenariuszy mogą akceptować i zwracać identyfikator stanu, co umożliwia wyszukiwanie danych i uzyskiwanie do niego dostępu lokalnie zamiast przekazywania rzeczywistych danych do usługi LLM, tylko w celu odebrania go z powrotem jako argumentu wywołania następnej funkcji.
Przechowując dane lokalnie, można przechowywać informacje prywatne i bezpieczne, unikając niepotrzebnego użycia tokenów podczas wywołań funkcji. Takie podejście nie tylko zwiększa prywatność danych, ale także zwiększa ogólną wydajność przetwarzania dużych lub poufnych zestawów danych.
Udostępnić schemat typu zwracanego funkcji do modelu AI
Użyj jednej z technik opisanych w sekcji dotyczącej zapewniania schematu typu zwracanego przez funkcję w modelu LLM, aby dostarczyć schemat typu zwracanego funkcji modelowi AI.
Korzystając ze dobrze zdefiniowanego schematu typu zwracanego, model sztucznej inteligencji może dokładnie zidentyfikować zamierzone właściwości, eliminując potencjalne niedokładności, które mogą wystąpić, gdy model przyjmuje założenia na podstawie niekompletnych lub niejednoznacznych informacji w przypadku braku schematu. W związku z tym zwiększa to dokładność wywołań funkcji, co prowadzi do bardziej niezawodnych i precyzyjnych wyników.