Bardziej zaawansowane scenariusze telemetrii
Uwaga
W tym artykule użyto pulpitu nawigacyjnego Aspirującego do ilustracji. Jeśli wolisz używać innych narzędzi, zapoznaj się z dokumentacją narzędzia, którego używasz, zgodnie z instrukcjami konfiguracji.
Automatyczne wywoływanie funkcji
Automatyczne wywoływanie funkcji to funkcja jądra semantycznego, która umożliwia jądro automatyczne wykonywanie funkcji, gdy model odpowiada za pomocą wywołań funkcji i dostarcza wyniki z powrotem do modelu. Ta funkcja jest przydatna w scenariuszach, w których zapytanie wymaga wielu iteracji wywołań funkcji w celu uzyskania ostatecznej odpowiedzi w języku naturalnym. Aby uzyskać więcej informacji, zobacz te przykłady usługi GitHub.
Uwaga
Wywoływanie funkcji nie jest obsługiwane przez wszystkie modele.
Napiwek
Będziesz słyszeć termin "narzędzia" i "wywoływanie narzędzi" czasami używane zamiennie z "funkcjami" i "wywoływanie funkcji".
Wymagania wstępne
- Wdrożenie uzupełniania czatu usługi Azure OpenAI, które obsługuje wywoływanie funkcji.
- Docker
- Najnowszy zestaw .Net SDK dla systemu operacyjnego.
- Wdrożenie uzupełniania czatu usługi Azure OpenAI, które obsługuje wywoływanie funkcji.
- Docker
- Na maszynie jest zainstalowany język Python 3.10, 3.11 lub 3.12 .
Uwaga
Możliwość obserwowania jądra semantycznego nie jest jeszcze dostępna dla języka Java.
Ustawienia
Tworzenie nowej aplikacji konsolowej
W terminalu uruchom następujące polecenie, aby utworzyć nową aplikację konsolową w języku C#:
dotnet new console -n TelemetryAutoFunctionCallingQuickstart
Przejdź do nowo utworzonego katalogu projektu po zakończeniu wykonywania polecenia.
Instalowanie wymaganych pakietów
Jądro semantyczne
dotnet add package Microsoft.SemanticKernelEksporter konsoli OpenTelemetry
dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol
Tworzenie prostej aplikacji za pomocą jądra semantycznego
W katalogu projektu otwórz plik za pomocą ulubionego Program.cs edytora. Utworzymy prostą aplikację, która używa jądra semantycznego do wysyłania monitu do modelu uzupełniania czatu. Zastąp istniejącą zawartość następującym kodem i wypełnij wymagane wartości dla deploymentName, endpointi apiKey:
using System.ComponentModel;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using OpenTelemetry;
using OpenTelemetry.Logs;
using OpenTelemetry.Metrics;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
namespace TelemetryAutoFunctionCallingQuickstart
{
class BookingPlugin
{
[KernelFunction("FindAvailableRooms")]
[Description("Finds available conference rooms for today.")]
public async Task<List<string>> FindAvailableRoomsAsync()
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return ["Room 101", "Room 201", "Room 301"];
}
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return $"Room {room} booked.";
}
}
class Program
{
static async Task Main(string[] args)
{
// Endpoint to the Aspire Dashboard
var endpoint = "http://localhost:4317";
var resourceBuilder = ResourceBuilder
.CreateDefault()
.AddService("TelemetryAspireDashboardQuickstart");
// Enable model diagnostics with sensitive data.
AppContext.SetSwitch("Microsoft.SemanticKernel.Experimental.GenAI.EnableOTelDiagnosticsSensitive", true);
using var traceProvider = Sdk.CreateTracerProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddSource("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var meterProvider = Sdk.CreateMeterProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddMeter("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var loggerFactory = LoggerFactory.Create(builder =>
{
// Add OpenTelemetry as a logging provider
builder.AddOpenTelemetry(options =>
{
options.SetResourceBuilder(resourceBuilder);
options.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint));
// Format log messages. This is default to false.
options.IncludeFormattedMessage = true;
options.IncludeScopes = true;
});
builder.SetMinimumLevel(LogLevel.Information);
});
IKernelBuilder builder = Kernel.CreateBuilder();
builder.Services.AddSingleton(loggerFactory);
builder.AddAzureOpenAIChatCompletion(
deploymentName: "your-deployment-name",
endpoint: "your-azure-openai-endpoint",
apiKey: "your-azure-openai-api-key"
);
builder.Plugins.AddFromType<BookingPlugin>();
Kernel kernel = builder.Build();
var answer = await kernel.InvokePromptAsync(
"Reserve a conference room for me today.",
new KernelArguments(
new OpenAIPromptExecutionSettings {
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
}
)
);
Console.WriteLine(answer);
}
}
}
W powyższym kodzie najpierw definiujemy makietową wtyczkę rezerwacji sali konferencyjnej z dwiema funkcjami: FindAvailableRoomsAsync i BookRoomAsync. Następnie utworzymy prostą aplikację konsolową, która rejestruje wtyczkę do jądra, i poprosimy jądro o automatyczne wywołanie funkcji w razie potrzeby.
Tworzenie nowego środowiska wirtualnego języka Python
python -m venv telemetry-auto-function-calling-quickstart
Aktywuj środowisko wirtualne.
telemetry-auto-function-calling-quickstart\Scripts\activate
Instalowanie wymaganych pakietów
pip install semantic-kernel opentelemetry-exporter-otlp-proto-grpc
Tworzenie prostego skryptu języka Python za pomocą jądra semantycznego
Utwórz nowy skrypt języka Python i otwórz go za pomocą ulubionego edytora.
New-Item -Path telemetry_auto_function_calling_quickstart.py -ItemType file
Utworzymy prosty skrypt języka Python, który używa jądra semantycznego do wysyłania monitu do modelu uzupełniania czatu. Zastąp istniejącą zawartość następującym kodem i wypełnij wymagane wartości dla deployment_name, endpointi api_key:
import asyncio
import logging
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.metrics import set_meter_provider
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.metrics.view import DropAggregation, View
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.semconv.resource import ResourceAttributes
from opentelemetry.trace import set_tracer_provider
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.prompt_execution_settings import PromptExecutionSettings
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.functions.kernel_function_decorator import kernel_function
class BookingPlugin:
@kernel_function(
name="find_available_rooms",
description="Find available conference rooms for today.",
)
def find_available_rooms(self,) -> list[str]:
return ["Room 101", "Room 201", "Room 301"]
@kernel_function(
name="book_room",
description="Book a conference room.",
)
def book_room(self, room: str) -> str:
return f"Room {room} booked."
# Endpoint to the Aspire Dashboard
endpoint = "http://localhost:4317"
# Create a resource to represent the service/sample
resource = Resource.create({ResourceAttributes.SERVICE_NAME: "telemetry-aspire-dashboard-quickstart"})
def set_up_logging():
exporter = OTLPLogExporter(endpoint=endpoint)
# Create and set a global logger provider for the application.
logger_provider = LoggerProvider(resource=resource)
# Log processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
logger_provider.add_log_record_processor(BatchLogRecordProcessor(exporter))
# Sets the global default logger provider
set_logger_provider(logger_provider)
# Create a logging handler to write logging records, in OTLP format, to the exporter.
handler = LoggingHandler()
# Add filters to the handler to only process records from semantic_kernel.
handler.addFilter(logging.Filter("semantic_kernel"))
# Attach the handler to the root logger. `getLogger()` with no arguments returns the root logger.
# Events from all child loggers will be processed by this handler.
logger = logging.getLogger()
logger.addHandler(handler)
logger.setLevel(logging.INFO)
def set_up_tracing():
exporter = OTLPSpanExporter(endpoint=endpoint)
# Initialize a trace provider for the application. This is a factory for creating tracers.
tracer_provider = TracerProvider(resource=resource)
# Span processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
tracer_provider.add_span_processor(BatchSpanProcessor(exporter))
# Sets the global default tracer provider
set_tracer_provider(tracer_provider)
def set_up_metrics():
exporter = OTLPMetricExporter(endpoint=endpoint)
# Initialize a metric provider for the application. This is a factory for creating meters.
meter_provider = MeterProvider(
metric_readers=[PeriodicExportingMetricReader(exporter, export_interval_millis=5000)],
resource=resource,
views=[
# Dropping all instrument names except for those starting with "semantic_kernel"
View(instrument_name="*", aggregation=DropAggregation()),
View(instrument_name="semantic_kernel*"),
],
)
# Sets the global default meter provider
set_meter_provider(meter_provider)
# This must be done before any other telemetry calls
set_up_logging()
set_up_tracing()
set_up_metrics()
async def main():
# Create a kernel and add a service
kernel = Kernel()
kernel.add_service(AzureChatCompletion(
api_key="your-azure-openai-api-key",
endpoint="your-azure-openai-endpoint",
deployment_name="your-deployment-name"
))
kernel.add_plugin(BookingPlugin(), "BookingPlugin")
answer = await kernel.invoke_prompt(
"Reserve a conference room for me today.",
arguments=KernelArguments(
settings=PromptExecutionSettings(
function_choice_behavior=FunctionChoiceBehavior.Auto(),
),
),
)
print(answer)
if __name__ == "__main__":
asyncio.run(main())
W powyższym kodzie najpierw definiujemy makietową wtyczkę rezerwacji sali konferencyjnej z dwiema funkcjami: find_available_rooms i book_room. Następnie utworzymy prosty skrypt języka Python, który rejestruje wtyczkę do jądra i prosi jądro o automatyczne wywołanie funkcji w razie potrzeby.
Zmienne środowiskowe
Zapoznaj się z tym artykułem , aby uzyskać więcej informacji na temat konfigurowania wymaganych zmiennych środowiskowych, aby umożliwić jądro emitowania zakresów dla łączników sztucznej inteligencji.
Uwaga
Możliwość obserwowania jądra semantycznego nie jest jeszcze dostępna dla języka Java.
Uruchamianie pulpitu nawigacyjnego Aspirującego
Postępuj zgodnie z instrukcjami podanymi tutaj , aby uruchomić pulpit nawigacyjny. Po uruchomieniu pulpitu nawigacyjnego otwórz przeglądarkę i przejdź do strony , aby http://localhost:18888 uzyskać dostęp do pulpitu nawigacyjnego.
Uruchom
Uruchom aplikację konsolową za pomocą następującego polecenia:
dotnet run
Uruchom skrypt języka Python za pomocą następującego polecenia:
python telemetry_auto_function_calling_quickstart.py
Uwaga
Możliwość obserwowania jądra semantycznego nie jest jeszcze dostępna dla języka Java.
Powinny pojawić się dane wyjściowe podobne do następujących:
Room 101 has been successfully booked for you today.
Inspekcja danych telemetrycznych
Po uruchomieniu aplikacji przejdź do pulpitu nawigacyjnego, aby sprawdzić dane telemetryczne.
Znajdź ślad aplikacji na karcie Ślady . W śladzie powinno znajdować się pięć zakresów:
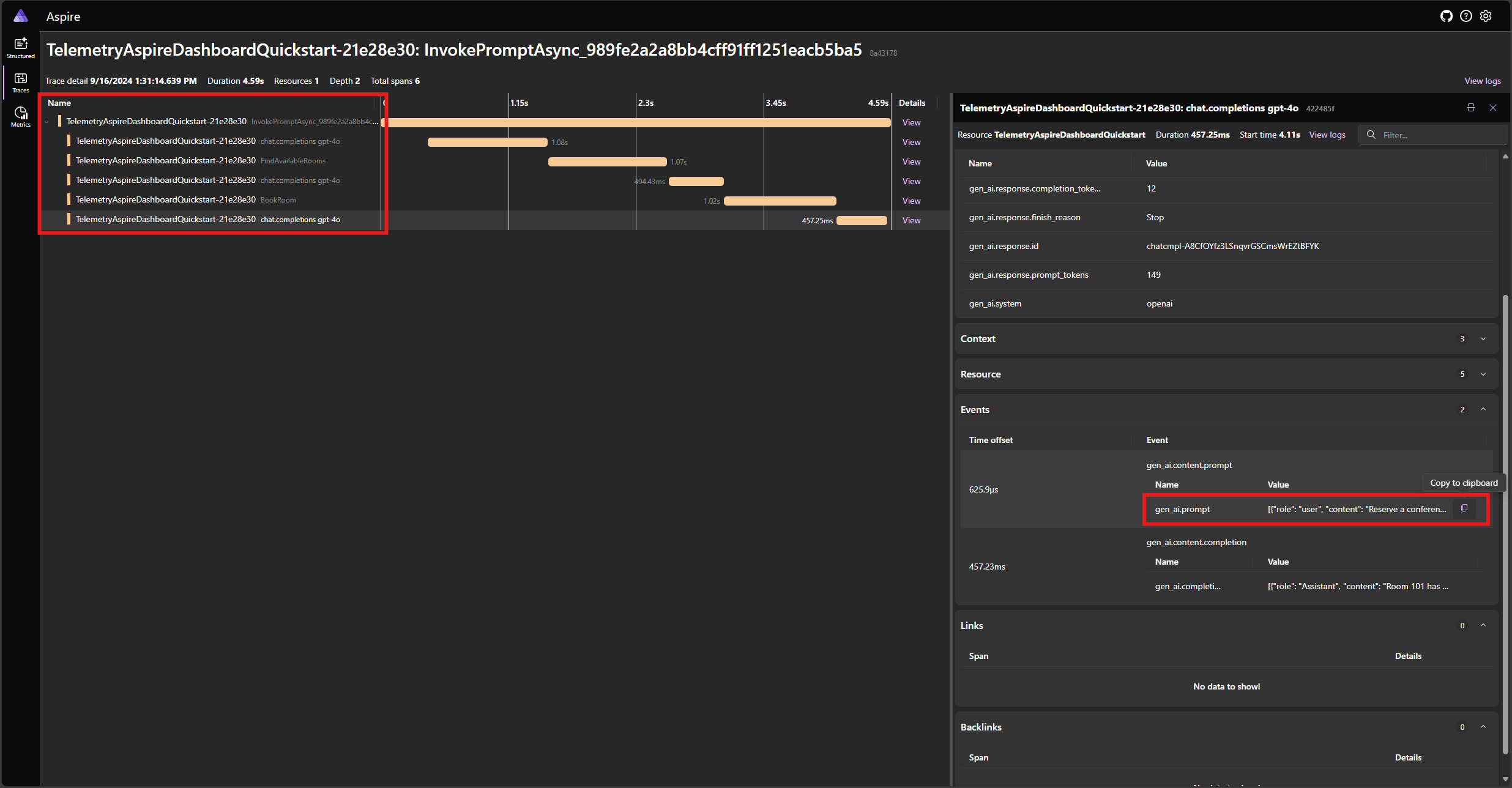
Te 5 zakresów reprezentuje wewnętrzne operacje jądra z włączoną funkcją automatycznego wywoływania. Najpierw wywołuje model, który żąda wywołania funkcji. Następnie jądro automatycznie wykonuje funkcję FindAvailableRoomsAsync i zwraca wynik do modelu. Następnie model żąda innego wywołania funkcji, aby dokonać rezerwacji, a jądro automatycznie wykonuje funkcję BookRoomAsync i zwraca wynik do modelu. Na koniec model zwraca odpowiedź języka naturalnego na użytkownika.
Jeśli klikniesz ostatni zakres i wyszukasz monit w gen_ai.content.prompt zdarzeniu, powinien zostać wyświetlony komunikat podobny do następującego:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_NtKi0OgOllJj1StLkOmJU8cP",
"function": { "arguments": {}, "name": "FindAvailableRooms" },
"type": "function"
}
]
},
{
"role": "tool",
"content": "[\u0022Room 101\u0022,\u0022Room 201\u0022,\u0022Room 301\u0022]"
},
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_mjQfnZXLbqp4Wb3F2xySds7q",
"function": { "arguments": { "room": "Room 101" }, "name": "BookRoom" },
"type": "function"
}
]
},
{ "role": "tool", "content": "Room Room 101 booked." }
]
Jest to historia czatów, która jest tworzona jako model i jądro współdziała ze sobą. Jest to wysyłane do modelu w ostatniej iteracji, aby uzyskać odpowiedź w języku naturalnym.
Znajdź ślad aplikacji na karcie Ślady . Należy uwzględnić pięć zakresów w śledzeniu pogrupowanych pod zakresem AutoFunctionInvocationLoop :
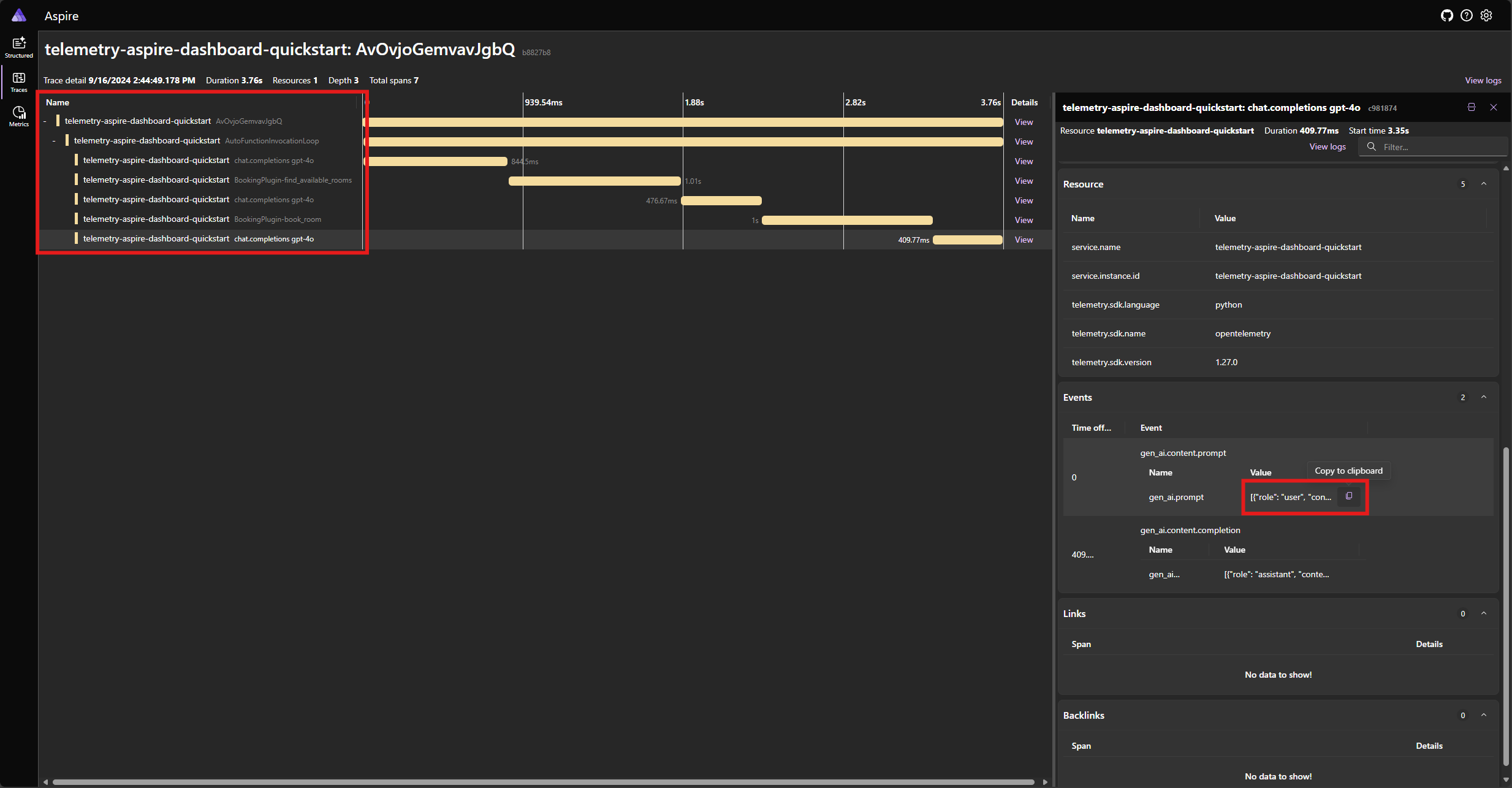
Te 5 zakresów reprezentuje wewnętrzne operacje jądra z włączoną funkcją automatycznego wywoływania. Najpierw wywołuje model, który żąda wywołania funkcji. Następnie jądro automatycznie wykonuje funkcję find_available_rooms i zwraca wynik do modelu. Następnie model żąda innego wywołania funkcji, aby dokonać rezerwacji, a jądro automatycznie wykonuje funkcję book_room i zwraca wynik do modelu. Na koniec model zwraca odpowiedź języka naturalnego na użytkownika.
Jeśli klikniesz ostatni zakres i wyszukasz monit w gen_ai.content.prompt zdarzeniu, powinien zostać wyświetlony komunikat podobny do następującego:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "assistant",
"tool_calls": [
{
"id": "call_ypqO5v6uTRlYH9sPTjvkGec8",
"type": "function",
"function": {
"name": "BookingPlugin-find_available_rooms",
"arguments": "{}"
}
}
]
},
{
"role": "tool",
"content": "['Room 101', 'Room 201', 'Room 301']",
"tool_call_id": "call_ypqO5v6uTRlYH9sPTjvkGec8"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_XDZGeTfNiWRpYKoHoH9TZRoX",
"type": "function",
"function": {
"name": "BookingPlugin-book_room",
"arguments": "{\"room\":\"Room 101\"}"
}
}
]
},
{
"role": "tool",
"content": "Room Room 101 booked.",
"tool_call_id": "call_XDZGeTfNiWRpYKoHoH9TZRoX"
}
]
Jest to historia czatów, która jest tworzona jako model i jądro współdziała ze sobą. Jest to wysyłane do modelu w ostatniej iteracji, aby uzyskać odpowiedź w języku naturalnym.
Uwaga
Możliwość obserwowania jądra semantycznego nie jest jeszcze dostępna dla języka Java.
Obsługa błędów
Jeśli podczas wykonywania funkcji wystąpi błąd, jądro automatycznie przechwyci błąd i zwróci komunikat o błędzie do modelu. Następnie model może użyć tego komunikatu o błędzie, aby udostępnić użytkownikowi odpowiedź w języku naturalnym.
Zmodyfikuj BookRoomAsync funkcję w kodzie języka C#, aby zasymulować błąd:
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
throw new Exception("Room is not available.");
}
Uruchom ponownie aplikację i obserwuj ślad na pulpicie nawigacyjnym. Powinien zostać wyświetlony zakres reprezentujący wywołanie funkcji jądra z błędem:
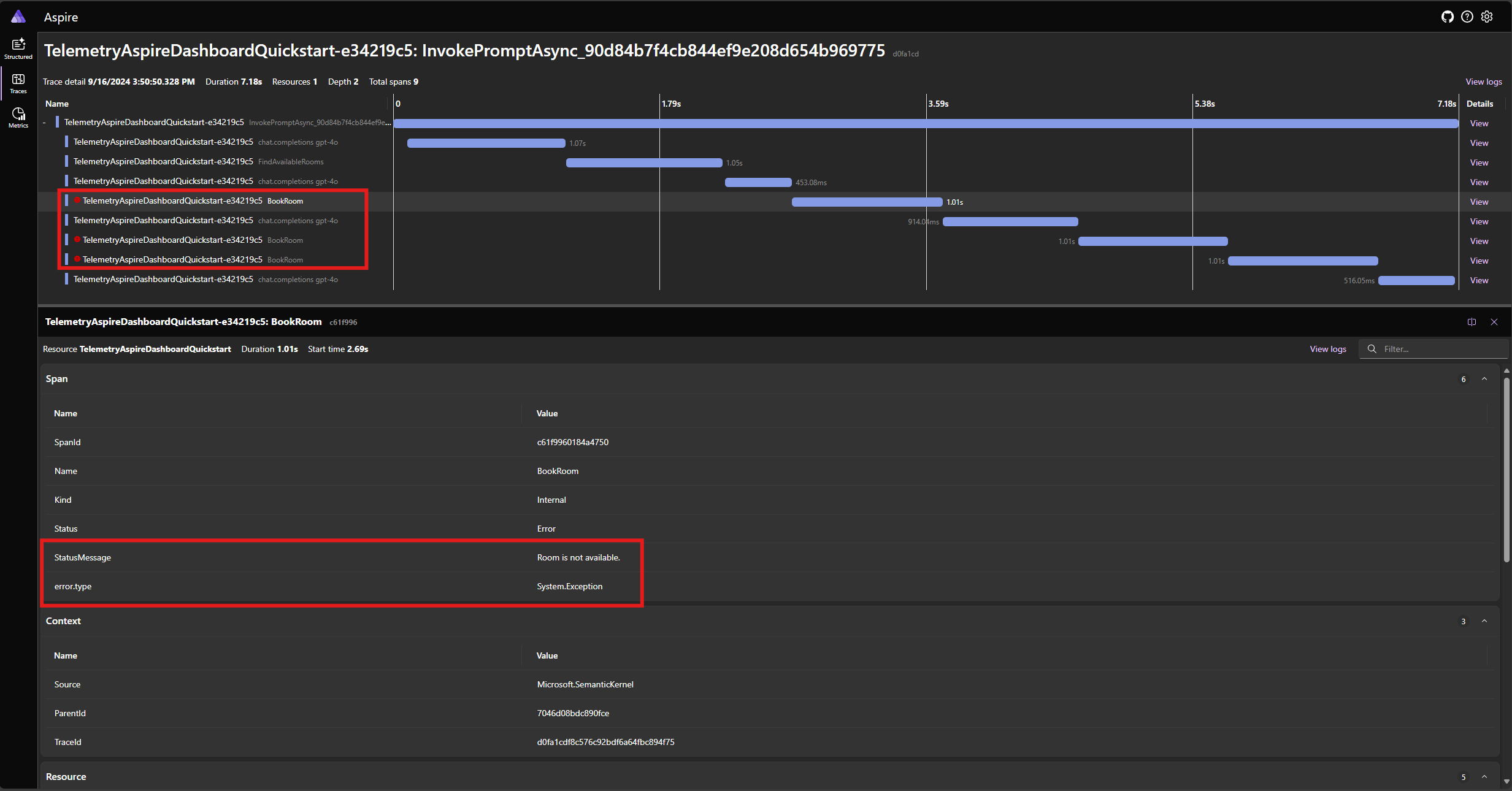
Uwaga
Bardzo prawdopodobne jest, że odpowiedzi modelu na błąd mogą się różnić za każdym razem, gdy uruchamiasz aplikację, ponieważ model jest stochastic. Model może być rezerwujący wszystkie trzy pokoje w tym samym czasie lub rezerwując jeden po raz pierwszy, a następnie rezerwując pozostałe dwa po raz drugi itd.
Zmodyfikuj book_room funkcję w kodzie języka Python, aby zasymulować błąd:
@kernel_function(
name="book_room",
description="Book a conference room.",
)
async def book_room(self, room: str) -> str:
# Simulate a remote call to a booking system
await asyncio.sleep(1)
raise Exception("Room is not available.")
Uruchom ponownie aplikację i obserwuj ślad na pulpicie nawigacyjnym. Powinien zostać wyświetlony zakres reprezentujący wywołanie funkcji jądra z błędem i śladem stosu:
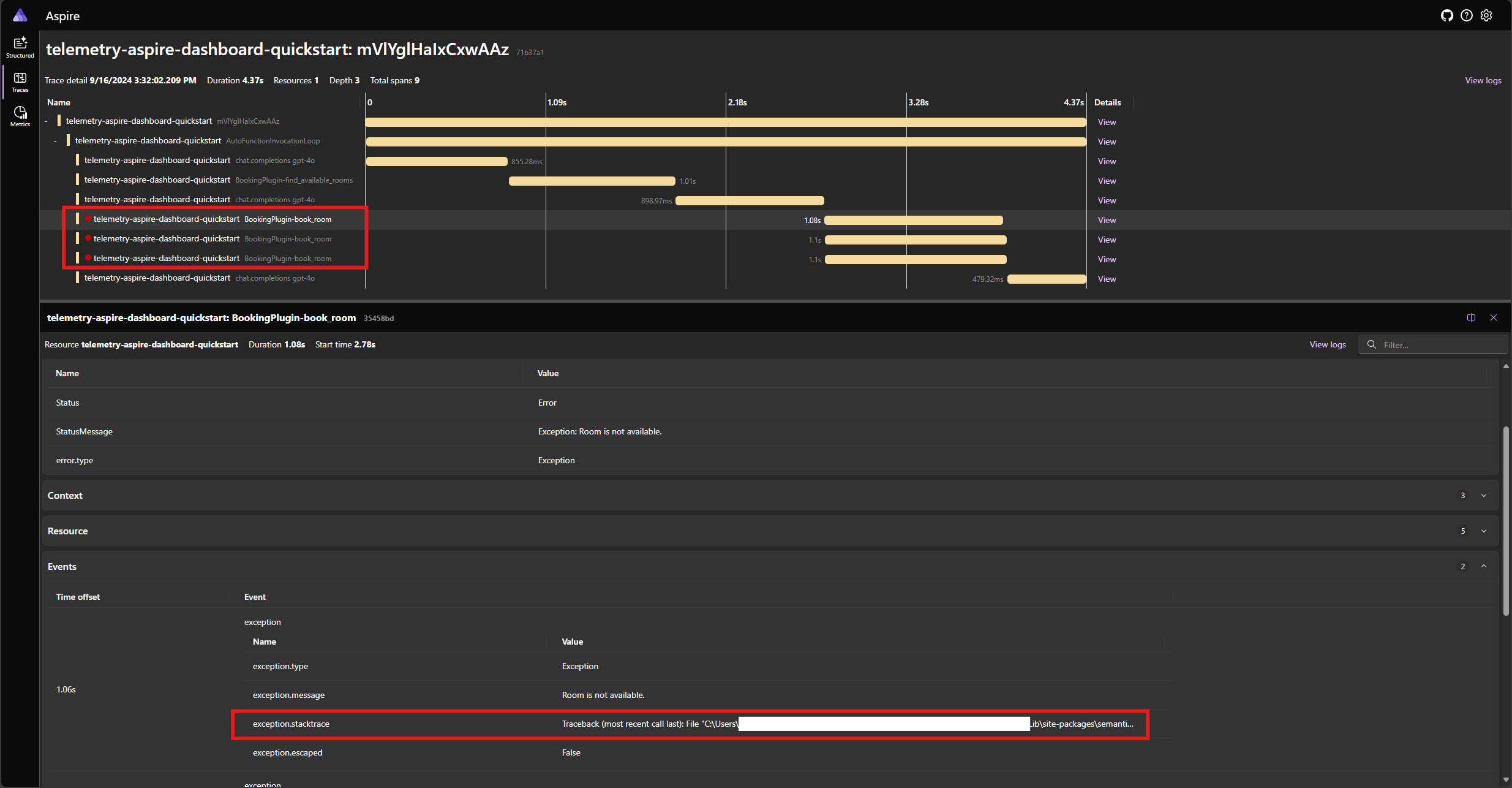
Uwaga
Bardzo prawdopodobne jest, że odpowiedzi modelu na błąd mogą się różnić za każdym razem, gdy uruchamiasz aplikację, ponieważ model jest stochastic. Model może być rezerwujący wszystkie trzy pokoje w tym samym czasie lub rezerwując jeden po raz pierwszy, a następnie rezerwując pozostałe dwa po raz drugi itd.
Uwaga
Możliwość obserwowania jądra semantycznego nie jest jeszcze dostępna dla języka Java.
Następne kroki i dalsze informacje
W środowisku produkcyjnym usługi mogą otrzymywać dużą liczbę żądań. Semantyczne jądro wygeneruje dużą ilość danych telemetrycznych. niektóre z nich mogą nie być przydatne w twoim przypadku użycia i wprowadzają niepotrzebne koszty przechowywania danych. Za pomocą funkcji próbkowania można zmniejszyć ilość zebranych danych telemetrycznych.
Możliwość obserwowania w jądrze semantycznym stale się poprawia. Najnowsze aktualizacje i nowe funkcje można znaleźć w repozytorium GitHub.