Wykonywanie skryptów uczenia maszynowego w języku Python w usłudze Machine Learning Studio (wersja klasyczna)
DOTYCZY:  Machine Learning Studio (wersja klasyczna)
Machine Learning Studio (wersja klasyczna)  Azure Machine Learning
Azure Machine Learning
Ważne
Obsługa programu Machine Learning Studio (wersja klasyczna) zakończy się 31 sierpnia 2024 r. Zalecamy przejście do usługi Azure Machine Learning przed tym terminem.
Od 1 grudnia 2021 r. nie będzie można tworzyć nowych zasobów programu Machine Learning Studio (wersja klasyczna). Do 31 sierpnia 2024 r. można będzie nadal korzystać z istniejących zasobów programu Machine Learning Studio (wersja klasyczna).
- Zobacz informacje na temat przenoszenia projektów uczenia maszynowego z usługi ML Studio (klasycznej) do usługi Azure Machine Learning.
- Dowiedz się więcej o usłudze Azure Machine Learning
Dokumentacja programu ML Studio (wersja klasyczna) jest wycofywana i może nie być aktualizowana w przyszłości.
Python to cenne narzędzie w klatce narzędzi wielu analityków danych. Jest on używany na każdym etapie typowych przepływów pracy uczenia maszynowego, w tym eksploracji danych, wyodrębniania funkcji, trenowania i walidacji modelu oraz wdrażania.
W tym artykule opisano sposób użycia modułu Execute Python Script (Wykonywanie skryptu języka Python) do używania kodu języka Python w eksperymentach usługi Machine Learning Studio (klasycznych) i usługach internetowych.
Korzystanie z modułu Execute Python Script (Wykonywanie skryptu języka Python)
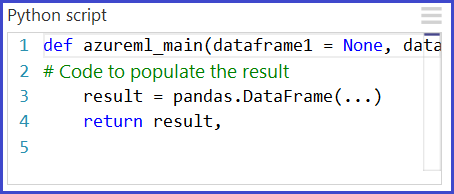
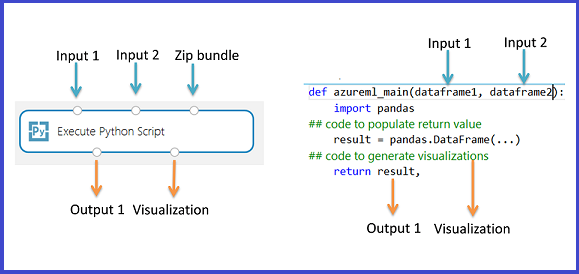
Podstawowym interfejsem języka Python w programie Studio (klasycznym) jest moduł Execute Python Script (Wykonywanie skryptu języka Python). Akceptuje maksymalnie trzy dane wejściowe i generuje maksymalnie dwa dane wyjściowe, podobnie jak w module Execute R Script (Wykonywanie skryptu języka R). Kod języka Python jest wprowadzany w polu parametrów za pomocą specjalnie nazwanej funkcji punktu wejścia o nazwie azureml_main.
Parametry wejściowe
Dane wejściowe modułu języka Python są widoczne jako ramki danych Biblioteki Pandas. Funkcja azureml_main akceptuje maksymalnie dwa opcjonalne ramki danych Biblioteki Pandas jako parametry.
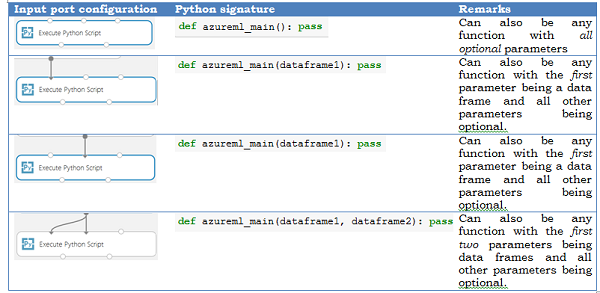
Mapowanie między portami wejściowymi i parametrami funkcji jest pozycyjne:
- Pierwszy połączony port wejściowy jest mapowany na pierwszy parametr funkcji.
- Drugie dane wejściowe (jeśli połączono) są mapowane na drugi parametr funkcji.
- Trzecie dane wejściowe są używane do importowania dodatkowych modułów języka Python.
Bardziej szczegółowe semantyka sposobu mapowania portów wejściowych na parametry azureml_main funkcji przedstawiono poniżej.
Zwracane wartości danych wyjściowych
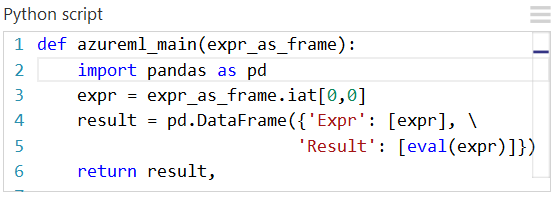
Funkcja azureml_main musi zwrócić pojedynczą ramkę danych biblioteki Pandas spakowana w sekwencji języka Python, taką jak krotka, lista lub tablica NumPy. Pierwszy element tej sekwencji jest zwracany do pierwszego portu wyjściowego modułu. Drugi port wyjściowy modułu jest używany do wizualizacji i nie wymaga wartości zwracanej. Ten schemat jest pokazany poniżej.
Tłumaczenie typów danych wejściowych i wyjściowych
Zestawy danych studio nie są takie same jak ramki danych Biblioteki Panda. W związku z tym wejściowe zestawy danych w programie Studio (klasycznym) są konwertowane na ramkę danych Biblioteki Pandas, a wyjściowe ramki danych są konwertowane z powrotem na zestawy danych programu Studio (klasyczne). Podczas tego procesu konwersji wykonywane są również następujące tłumaczenia:
| Typ danych języka Python | Procedura tłumaczenia w programie Studio |
|---|---|
| Ciągi i cyfry | Przetłumaczone w formacie is |
| Biblioteka Pandas "NA" | Przetłumaczone jako "Brak wartości" |
| Wektory indeksu | Nieobsługiwane* |
| Nazwy kolumn innych niż ciąg | Wywołanie str nazw kolumn |
| Zduplikowane nazwy kolumn | Dodaj sufiks liczbowy: (1), (2), (3) itd. |
*Wszystkie ramki danych wejściowych w funkcji języka Python zawsze mają 64-bitowy indeks liczbowy z zakresu od 0 do liczby wierszy minus 1
Importowanie istniejących modułów skryptów języka Python
Zaplecze używane do wykonywania języka Python jest oparte na anaconda, powszechnie używanej dystrybucji języka Python. Zawiera blisko 200 najpopularniejszych pakietów języka Python używanych w obciążeniach skoncentrowanych na danych. Program Studio (wersja klasyczna) nie obsługuje obecnie używania systemów zarządzania pakietami, takich jak lub Conda, do instalowania bibliotek zewnętrznych i zarządzania nimi. Jeśli okaże się, że konieczne jest dołączenie dodatkowych bibliotek, skorzystaj z poniższego scenariusza jako przewodnika.
Typowym przypadkiem użycia jest dołączenie istniejących skryptów języka Python do eksperymentów programu Studio (klasycznych). Moduł Execute Python Script (Wykonywanie skryptu języka Python) akceptuje plik zip zawierający moduły języka Python na trzecim porcie wejściowym. Plik jest rozpakowany przez strukturę wykonywania w czasie wykonywania, a zawartość jest dodawana do ścieżki biblioteki interpretera języka Python. azureml_main Funkcja punktu wejścia może następnie bezpośrednio zaimportować te moduły.
Rozważmy na przykład plik Hello.py zawierający prostą funkcję "Hello, World".
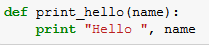
Następnie utworzymy Hello.zip pliku, który zawiera Hello.py:

Przekaż plik zip jako zestaw danych do programu Studio (wersja klasyczna). Następnie utwórz i uruchom eksperyment, który używa kodu języka Python w pliku Hello.zip, dołączając go do trzeciego portu wejściowego modułu Execute Python Script (Wykonywanie skryptu języka Python), jak pokazano na poniższej ilustracji.
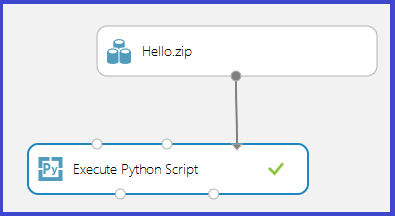
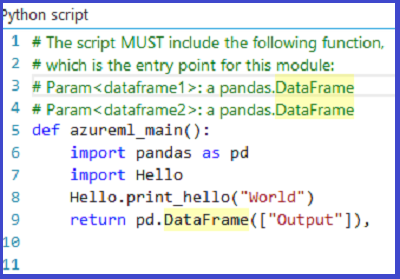
Dane wyjściowe modułu pokazują, że plik zip został rozpakowany i że funkcja print_hello została uruchomiona.

Uzyskiwanie dostępu do obiektów blob usługi Azure Storage
Dostęp do danych przechowywanych na koncie usługi Azure Blob Storage można uzyskać, wykonując następujące kroki:
- Pobierz lokalnie pakiet usługi Azure Blob Storage dla języka Python.
- Przekaż plik zip do obszaru roboczego programu Studio (wersja klasyczna) jako zestaw danych.
- Tworzenie obiektu BlobService za pomocą polecenia
protocol='http'
from azure.storage.blob import BlockBlobService
# Create the BlockBlockService that is used to call the Blob service for the storage account
block_blob_service = BlockBlobService(account_name='account_name', account_key='account_key', protocol='http')
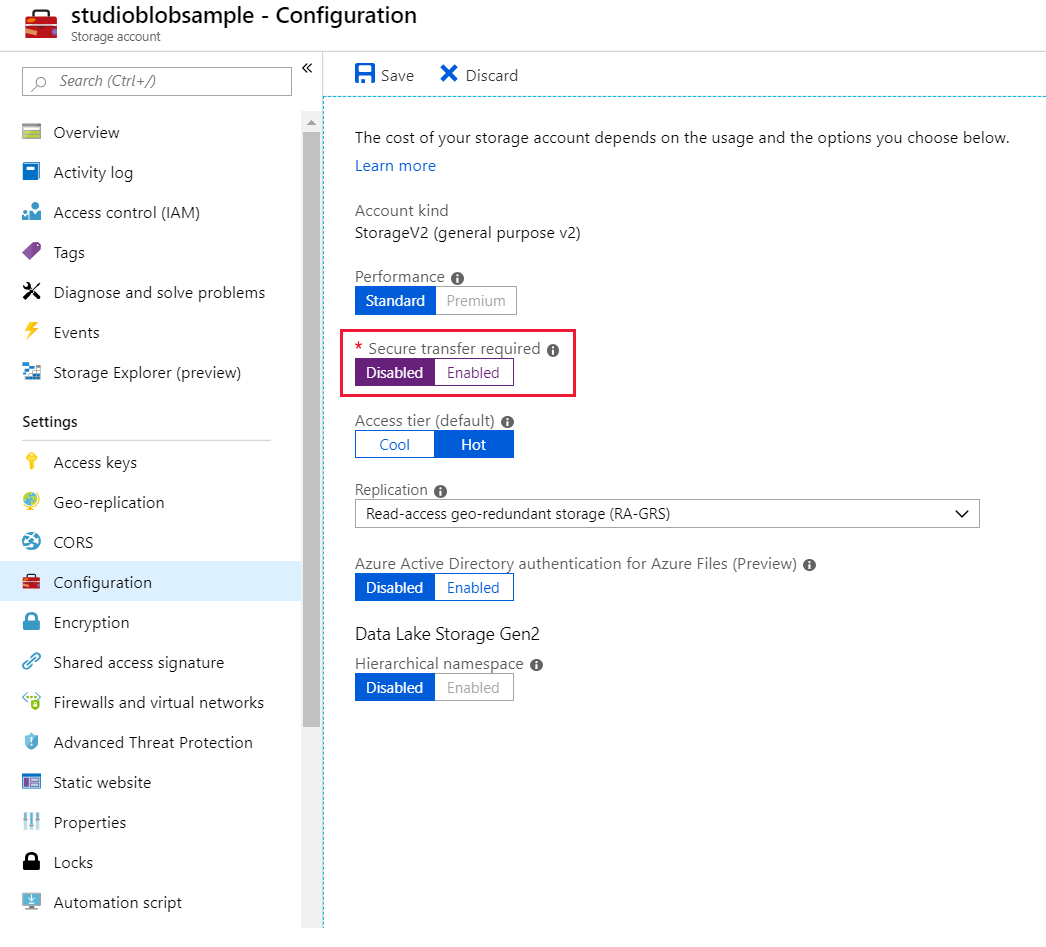
- Wyłącz wymagany bezpieczny transfer na karcie Ustawienia konfiguracji magazynu
Operacjonalizacja skryptów języka Python
Wszystkie moduły Execute Python Script używane w eksperymencie oceniania są wywoływane po opublikowaniu jako usługa internetowa. Na przykład na poniższej ilustracji przedstawiono eksperyment oceniania zawierający kod do oceny pojedynczego wyrażenia języka Python.
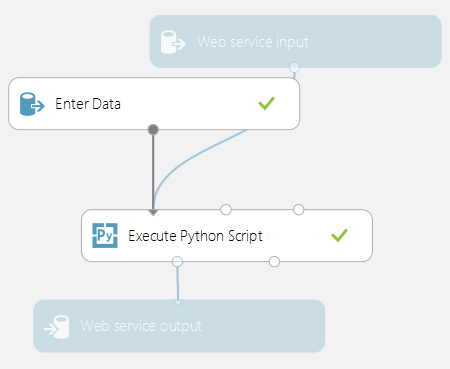
Usługa internetowa utworzona na podstawie tego eksperymentu podejmie następujące działania:
- Weź wyrażenie języka Python jako dane wejściowe (jako ciąg)
- Wysyłanie wyrażenia języka Python do interpretera języka Python
- Zwraca tabelę zawierającą zarówno wyrażenie, jak i obliczony wynik.
Praca z wizualizacjami
Wykresy utworzone przy użyciu biblioteki MatplotLib mogą być zwracane przez skrypt Execute Python. Jednak wykresy nie są automatycznie przekierowywane do obrazów, ponieważ są używane w języku R. Dlatego użytkownik musi jawnie zapisać wszystkie wykresy w plikach PNG.
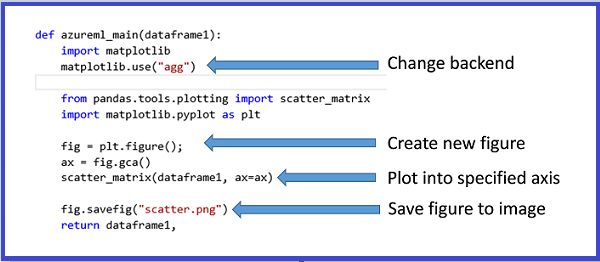
Aby wygenerować obrazy z biblioteki MatplotLib, należy wykonać następujące czynności:
- Przełącz zaplecze na "AGG" z domyślnego modułu renderowania opartego na qt.
- Utwórz nowy obiekt rysunku.
- Pobierz oś i wygeneruj do niej wszystkie wykresy.
- Zapisz rysunek w pliku PNG.
Ten proces przedstawiono na poniższych obrazach, które tworzą macierz wykresu punktowego przy użyciu funkcji scatter_matrix w bibliotece Pandas.
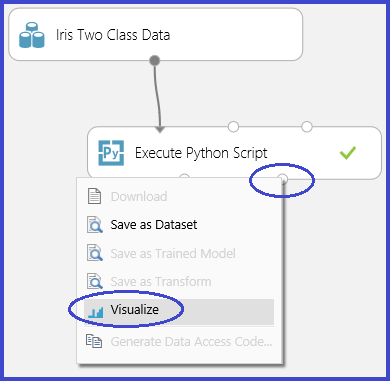
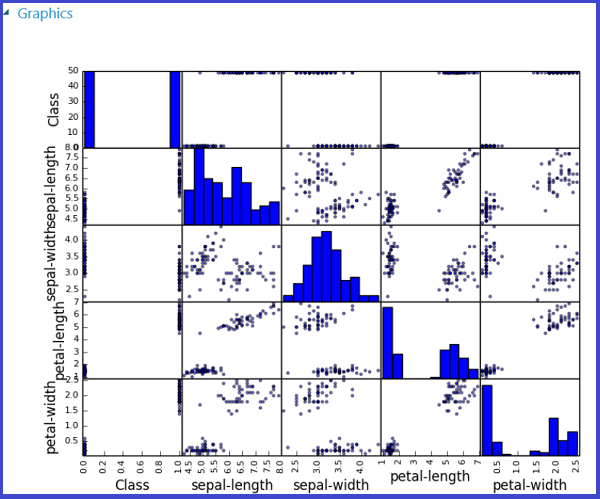
Można zwrócić wiele liczb, zapisując je na różnych obrazach. Środowisko uruchomieniowe programu Studio (wersja klasyczna) pobiera wszystkie obrazy i łączy je w celu wizualizacji.
Zaawansowane przykłady
Środowisko Anaconda zainstalowane w programie Studio (klasycznym) zawiera typowe pakiety, takie jak NumPy, SciPy i Scikits-Learn. Te pakiety mogą być skutecznie używane do przetwarzania danych w potoku uczenia maszynowego.
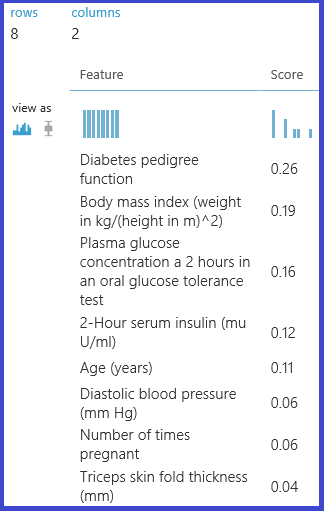
Na przykład poniższy eksperyment i skrypt ilustrują użycie osób uczących się w programie Scikits-Learn w celu obliczenia wyników ważności funkcji dla zestawu danych. Wyniki mogą służyć do przeprowadzania wyboru nadzorowanych funkcji przed wprowadzeniem ich do innego modelu.
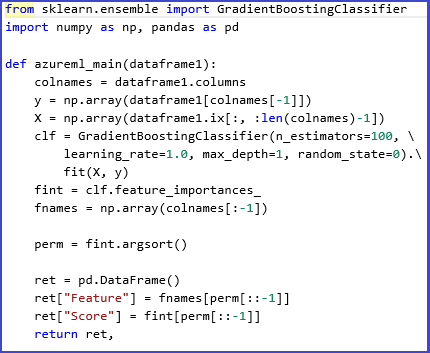
Oto funkcja języka Python służąca do obliczania ocen ważności i porządkowania funkcji na podstawie wyników:
Następnie poniższy eksperyment oblicza i zwraca wyniki ważności funkcji w zestawie danych "Pima Indian Diabetes" w usłudze Machine Learning Studio (wersja klasyczna):
Ograniczenia
Moduł Execute Python Script (Wykonywanie skryptu języka Python) ma obecnie następujące ograniczenia:
Wykonywanie w trybie piaskownicy
Środowisko uruchomieniowe języka Python jest obecnie w trybie piaskownicy i nie zezwala na dostęp do sieci ani lokalnego systemu plików w trwały sposób. Wszystkie pliki zapisane lokalnie są izolowane i usuwane po zakończeniu modułu. Kod języka Python nie może uzyskać dostępu do większości katalogów na maszynie, na której działa, wyjątek jest bieżącym katalogiem i jego podkatalogami.
Brak zaawansowanej obsługi programowania i debugowania
Moduł języka Python obecnie nie obsługuje funkcji IDE, takich jak intellisense i debugowanie. Ponadto jeśli moduł ulegnie awarii w czasie wykonywania, dostępny jest pełny ślad stosu języka Python. Należy jednak wyświetlić go w dzienniku danych wyjściowych modułu. Obecnie zalecamy opracowywanie i debugowanie skryptów języka Python w środowisku, takim jak IPython, a następnie importowanie kodu do modułu.
Dane wyjściowe pojedynczej ramki danych
Punkt wejścia języka Python może zwracać tylko jedną ramkę danych jako dane wyjściowe. Obecnie nie można zwrócić dowolnych obiektów języka Python, takich jak wytrenowane modele bezpośrednio do środowiska uruchomieniowego programu Studio (klasycznego). Podobnie jak wykonywanie skryptu języka R, które ma to samo ograniczenie, w wielu przypadkach można wybrać obiekty pickle do tablicy bajtów, a następnie zwrócić je wewnątrz ramki danych.
Brak możliwości dostosowywania instalacji języka Python
Obecnie jedynym sposobem dodawania niestandardowych modułów języka Python jest mechanizm plików zip opisany wcześniej. Chociaż jest to możliwe w przypadku małych modułów, jest to kłopotliwe w przypadku dużych modułów (zwłaszcza modułów z natywnymi bibliotekami DLL) lub dużą liczbą modułów.
Następne kroki
Więcej informacji możesz znaleźć w Centrum deweloperów języka Python.