Co to jest Apache Spark™ w HDInsight na AKS? (Wersja zapoznawcza)
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej z tym ogłoszeniem.
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki korzystania z platformy Microsoft Azure dla wersji wstępnych zawierają więcej warunków prawnych dotyczących funkcji platformy Azure, które są w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze publicznie udostępnione. Aby uzyskać informacje na temat tej konkretnej wersji zapoznawczej, zobacz informacje o wersji zapoznawczej dla Azure HDInsight na AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie na AskHDInsight z szczegółami i śledź nas, aby uzyskać więcej aktualizacji na społeczności Azure HDInsight.
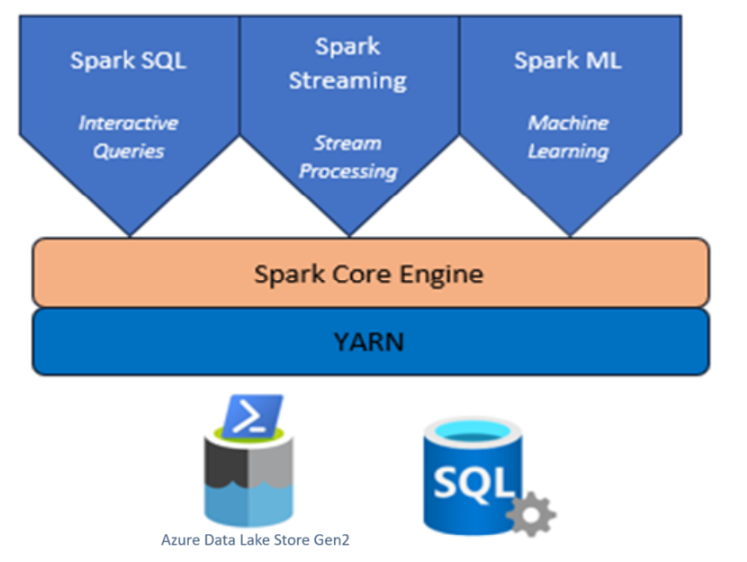
Apache Spark™ to platforma przetwarzania równoległego, która obsługuje przetwarzanie w pamięci w celu zwiększenia wydajności aplikacji analitycznych big data.
Platforma Apache Spark™ udostępnia elementy pierwotne na potrzeby przetwarzania w klastrze w pamięci. Zadanie platformy Spark może ładować i buforować dane do pamięci i wykonywać zapytania dotyczące ich wielokrotnie. Przetwarzanie w pamięci jest szybsze niż aplikacje oparte na dyskach, takie jak Hadoop, które udostępniają dane za pośrednictwem rozproszonego systemu plików Hadoop (HDFS). Platforma Apache Spark umożliwia integrację z językami programowania Scala i Python, aby umożliwić manipulowanie rozproszonymi zestawami danych, takimi jak kolekcje lokalne. Nie ma potrzeby tworzenia struktury wszystkich elementów w ramach operacji mapowania i redukcji.
Klaster Apache Spark z usługą HDInsight w usłudze AKS
Azure HDInsight to zarządzana usługa analizy typu open source o pełnym spektrum dla przedsiębiorstw.
Apache Spark™ w Azure HDInsight na AKS to zarządzana usługa Spark w Microsoft Azure. Za pomocą platformy Apache Spark w usłudze Azure HDInsight w usłudze AKS możesz przechowywać i przetwarzać dane na platformie Azure. Klastry Spark w usłudze HDInsight są zgodne z usługą Azure Data Lake Storage Gen2 lub, dzięki czemu można zastosować przetwarzanie platformy Spark w istniejących magazynach danych.
Platforma Apache Spark dla usługi HDInsight w usłudze AKS umożliwia szybką analizę danych i przetwarzanie klastrów przy użyciu przetwarzania w pamięci. Jupyter Notebook umożliwia interakcję z danymi, łączenie kodu z tekstem w formacie markdown oraz wykonywanie prostych wizualizacji.
Platforma Apache Spark na AKS w usłudze HDInsight składa się z wielu składników jako podów.
Kontrolery klastra
Kontrolery klastrów są odpowiedzialne za instalowanie odpowiednich usług i zarządzanie nimi. Różne kontrolery są instalowane i zarządzane w klastrze Spark.
Składniki usługi Apache Spark
usługa Zookeeper: Klaster Zookeeper składający się z trzech węzłów, służy jako rozproszony koordynator lub magazyn o wysokiej dostępności dla innych usług.
Usługa Yarn: W klastrze Hadoop Yarn zadania Spark będą zaplanowane jako aplikacje Yarn.
Interfejsy Klienta: Klastry Apache Spark w HDInsight na AKS udostępniają różne interfejsy klientów. Livy Server, Jupyter Notebook, Spark History Server, świadczy usługi Spark użytkownikom HDInsight w AKS.
Odniesienie
- Nazwy projektów typu open source Apache, Apache Spark i z nimi związane są znakami towarowymiFundacji Apache Software Foundation (ASF).