Używanie Delta Lake w Azure HDInsight na AKS z klastrem Apache Spark™ (wersja zapoznawcza)
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej w tym ogłoszeniu.
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki użytkowania dla wersji zapoznawczych Microsoft Azure zawierają więcej warunków prawnych, które dotyczą funkcji Azure w wersji beta, zapoznawczej lub w inny sposób jeszcze nie zostały wydane w wersji ogólnodostępnej. Aby uzyskać informacje na temat tej konkretnej wersji zapoznawczej, zobacz Azure HDInsight w usłudze AKS w wersji zapoznawczej informacji. W przypadku pytań lub sugestii dotyczących funkcji prosimy przesłać zgłoszenie na AskHDInsight z odpowiednimi szczegółami i śledzić nas, aby uzyskać więcej aktualizacji na Azure HDInsight Community.
Azure HDInsight w usłudze AKS to zarządzana usługa oparta na chmurze do analizy dużych zbiorów danych, która pomaga organizacjom przetwarzać duże ilości danych. W tym samouczku pokazano, jak używać Delta Lake w Azure HDInsight na AKS z klastrem Apache Spark™.
Warunek wstępny
Utwórz klaster Apache Spark™ w usłudze Azure HDInsight na AKS
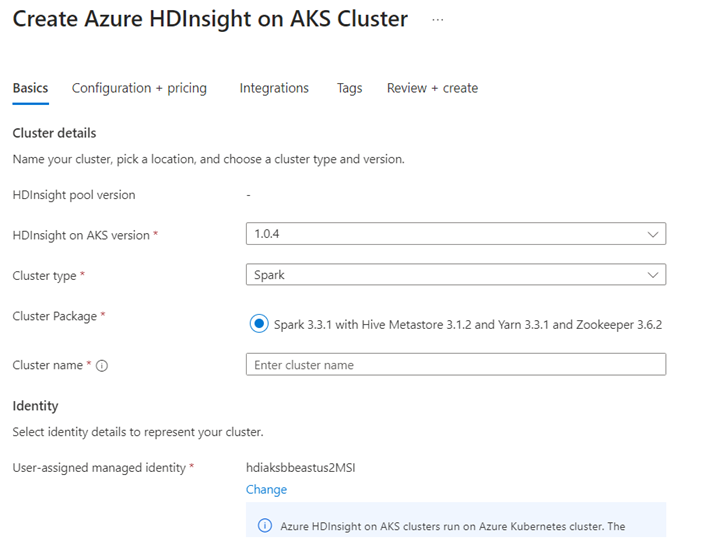
Uruchom scenariusz Delta Lake w notesie Jupyter. Utwórz notatnik Jupyter i podczas jego tworzenia wybierz opcję "Spark", ponieważ poniższy przykład jest w języku Scala.
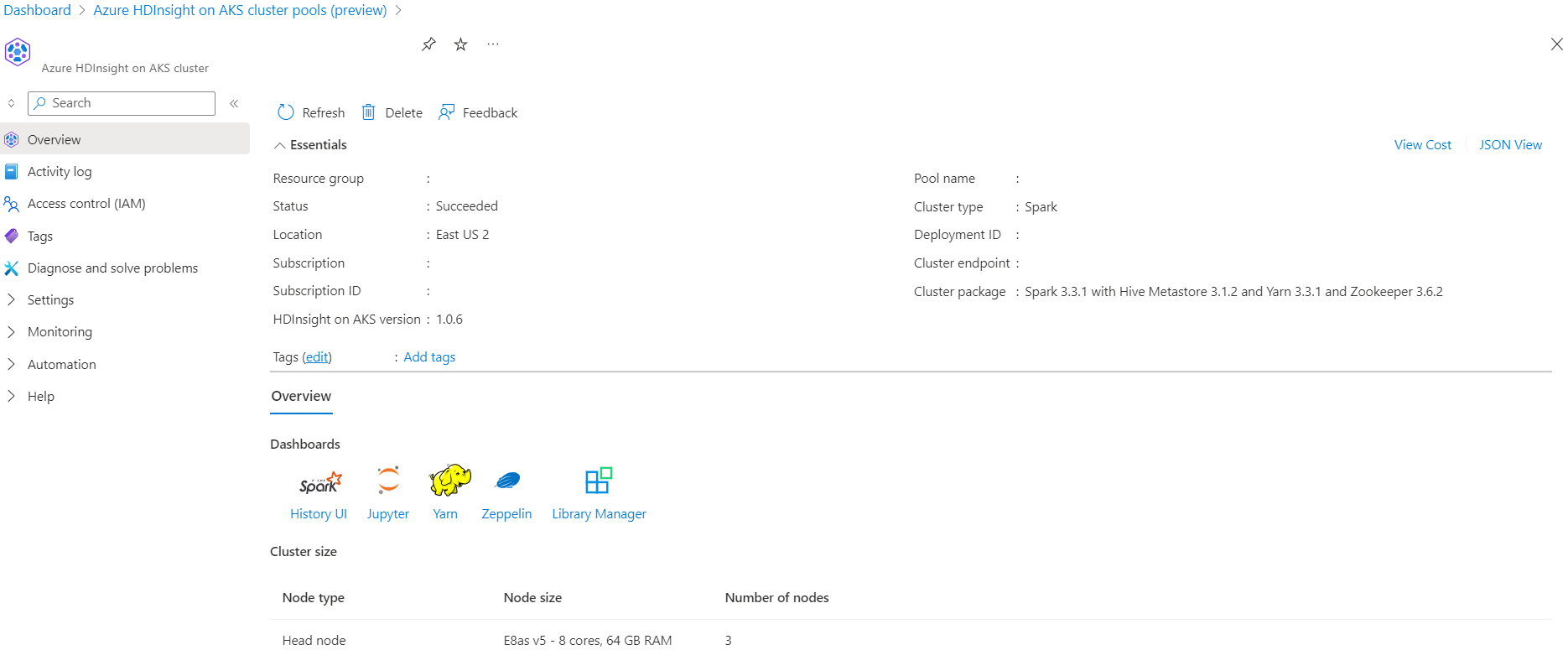


Scenariusz
- Przeczytaj format danych NYC Taxi Parquet — lista adresów URL plików Parquet jest dostępna z NYC Taxi & Limousine Commission.
- Dla każdego adresu URL (pliku) wykonaj pewne przekształcenia i zapisz je w formacie delta.
- Oblicz średnią odległość, średni koszt na milę i średni koszt z tabeli delty przy użyciu obciążenia przyrostowego.
- Zapisz obliczoną wartość z kroku 3 w formacie delty do folderu wyjściowego kluczowego wskaźnika wydajności.
- Utwórz tabelę Delta w folderze wyjściowym w formacie Delta (automatyczne odświeżanie).
- Folder wyjściowy KPI zawiera wiele wersji średniej odległości oraz średniego kosztu na milę dla podróży.
Podaj wymagane konfiguracje dla Delta Lake
Macierz zgodności Delta Lake z Apache Spark — Delta Lake, zmień wersję Delta Lake na podstawie wersji Apache Spark.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Wyświetlanie listy plików danych
Notatka
Te adresy URL plików pochodzą z NYC Taxi & Limousine Commission.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Tworzenie katalogu wyjściowego
Lokalizacja, w której chcesz utworzyć dane wyjściowe w formacie różnicowym; jeśli to konieczne, zmień zmienne transformDeltaOutputPath i avgDeltaOutputKPIPath.
-
avgDeltaOutputKPIPath— przechowywanie średniego wskaźnika KPI w formacie różnicowym -
transformDeltaOutputPath— przechowywanie przekształconych danych wyjściowych w formacie delta
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Tworzenie danych w formacie Delta na podstawie formatu Parquet
Dane wejściowe pochodzą z
listOfDataFile, gdzie dane zostały pobrane z https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.pageAby zademonstrować przemieszczanie w czasie i wersjonowanie, załaduj dane indywidualnie.
Wykonaj transformację i oblicz następujące wskaźniki KPI biznesowe na przyrostowym obciążeniu:
- Średnia odległość
- Średni koszt na milę
- Średni koszt
Zapisz przekształcone dane i wskaźniki KPI w formacie różnicowym
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Odczyt formatu delta za pomocą Delta Table
- odczytywanie przekształconych danych
- odczytywanie danych KPI
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Drukuj schemat
- Drukuj schemat tabeli delty dla przekształconych i średnich danych kluczowych wskaźników wydajności1.
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema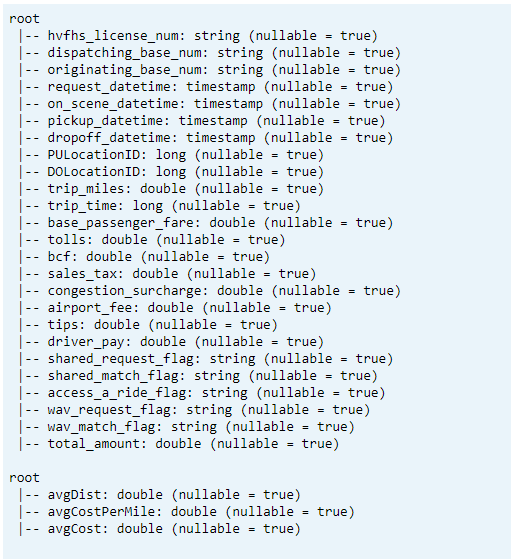
Wyświetlanie ostatniego obliczonego wskaźnika KPI z tabeli danych
dtAvgKpi.toDF.show(false)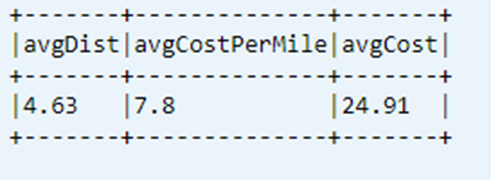


Wyświetlanie obliczonej historii kluczowego wskaźnika wydajności
W tym kroku jest wyświetlana historia tabeli transakcji kluczowego wskaźnika wydajności z _delta_log
dtAvgKpi.history().show(false)

Wyświetlanie danych kluczowych wskaźników wydajności po każdym załadowaniu danych
- Korzystając z podróży w czasie, można wyświetlić zmiany wskaźników KPI po każdym obciążeniu
- Wszystkie zmiany wersji można przechowywać w formacie CSV w
avgMoMKPIChangePath, aby usługa Power BI mogła odczytać te zmiany
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Odniesienie
- Nazwy projektów typu open source, Apache, Apache Spark i powiązane z nimi nazwy są znakami towarowymiFundacji Apache Software (ASF).