Jak używać łącznika Flink/Delta
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej dzięki temu ogłoszeniu .
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki użytkowania platformy Microsoft Azure zawierają dodatkowe postanowienia prawne dotyczące funkcji Azure, które są w wersji beta, zapoznawczej lub w inny sposób nie zostały jeszcze wydane jako ogólnodostępne. Aby uzyskać informacje na temat tej konkretnej wersji zapoznawczej, zobacz informacje na temat wersji zapoznawczej usługi Azure HDInsight na AKS. W przypadku pytań lub sugestii dotyczących funkcji, prześlij żądanie w AskHDInsight z podaniem szczegółów i śledź nas, aby uzyskać więcej informacji na temat aktualizacji dotyczących społeczności Azure HDInsight.
Korzystając ze sobą usług Apache Flink i Delta Lake, można utworzyć niezawodną i skalowalną architekturę usługi Data Lakehouse. Łącznik Flink/Delta umożliwia zapisywanie danych w tabelach Delta przy użyciu transakcji ACID i dokładnie raz przetwarzanie. Oznacza to, że strumienie danych są spójne i wolne od błędów, nawet jeśli ponownie uruchomisz potok Flink z punktu kontrolnego. Łącznik Flink/Delta zapewnia, że dane nie zostaną utracone ani zduplikowane oraz że są zgodne z semantykami Flink.
Z tego artykułu dowiesz się, jak używać łącznika Flink-Delta.
- Przeczytaj dane z tabeli delty.
- Zapisz dane do tabeli delty.
- Wykonaj zapytanie w usłudze Power BI.
Co to jest łącznik Flink/Delta
Flink/Delta Connector to biblioteka JVM do odczytywania i zapisywania danych z aplikacji Apache Flink do tabel delty korzystających z biblioteki Delta Standalone JVM. Łącznik zapewnia dokładnie jednokrotne gwarancje dostarczania.
Łącznik Flink/Delta obejmuje następujące elementy:
DeltaSink, do zapisywania danych z platformy Apache Flink do tabeli Delta. Usługa DeltaSource do odczytywania tabel delty przy użyciu narzędzia Apache Flink.
Łącznik apache Flink-Delta obejmuje:
W zależności od wersji łącznika można go używać z następującymi wersjami narzędzia Apache Flink:
Connector's version Flink's version
0.4.x (Sink Only) 1.12.0 <= X <= 1.14.5
0.5.0 1.13.0 <= X <= 1.13.6
0.6.0 X >= 1.15.3
0.7.0 X >= 1.16.1 --- We use this in Flink 1.17.0
Warunki wstępne
- Klaster usługi HDInsight Flink 1.17.0 w usłudze AKS
- Flink-Delta Connector 0.7.0
- Aby uzyskać dostęp do ADLS Gen2, użyj tożsamości usługi zarządzanej MSI.
- IntelliJ na potrzeby programowania
Odczytywanie danych z tabeli delty
Delta Source może działać w jednym z dwóch trybów, opisanych w następujący sposób.
Tryb ograniczony jest odpowiedni dla zadań wsadowych, gdy chcemy odczytywać zawartość tabeli delty tylko dla określonej wersji tabeli. Utwórz źródło dla tego trybu przy użyciu interfejsu API DeltaSource.forBoundedRowData.
Tryb ciągły odpowiedni dla zadań przesyłania strumieniowego, w którym chcemy stale sprawdzać tabelę delty pod kątem nowych zmian i wersji. Utwórz dla tego trybu źródło za pomocą API DeltaSource.forContinuousRowData.
Przykład: Tworzenie źródła dla tabeli delty w celu odczytania wszystkich kolumn w trybie ograniczonym. Odpowiednie do zadań wsadowych. W tym przykładzie ładuje najnowszą wersję tabeli.
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
Zapisywanie do zasobnika delty
Delta Sink obecnie udostępnia następujące metryki Flink:

Tworzenie ujścia dla tabel niepartycyjnych
W tym przykładzie pokazano, jak utworzyć obiekt DeltaSink i podłączyć go do istniejącego org.apache.flink.streaming.api.datastream.DataStream.
import io.delta.flink.sink.DeltaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
Pełny kod
Odczytywanie danych z tabeli delty i ujście do innej tabeli różnicowej.
package contoso.example;
import io.delta.flink.sink.DeltaSink;
import io.delta.flink.source.DeltaSource;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
public class DeltaSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
// Execute the Flink job
env.execute("Delta datasource and sink Example");
}
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
}
Pom.xml Maven
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>contoso.example</groupId>
<artifactId>FlinkDeltaDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<hadoop-version>3.3.4</hadoop-version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-standalone_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-flink</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Spakuj plik jar i prześlij go do klastra Flink w celu uruchomienia
Przekaż plik jar do systemu ABFS.

Przekaż informacje o job jar w klastrze AppMode.
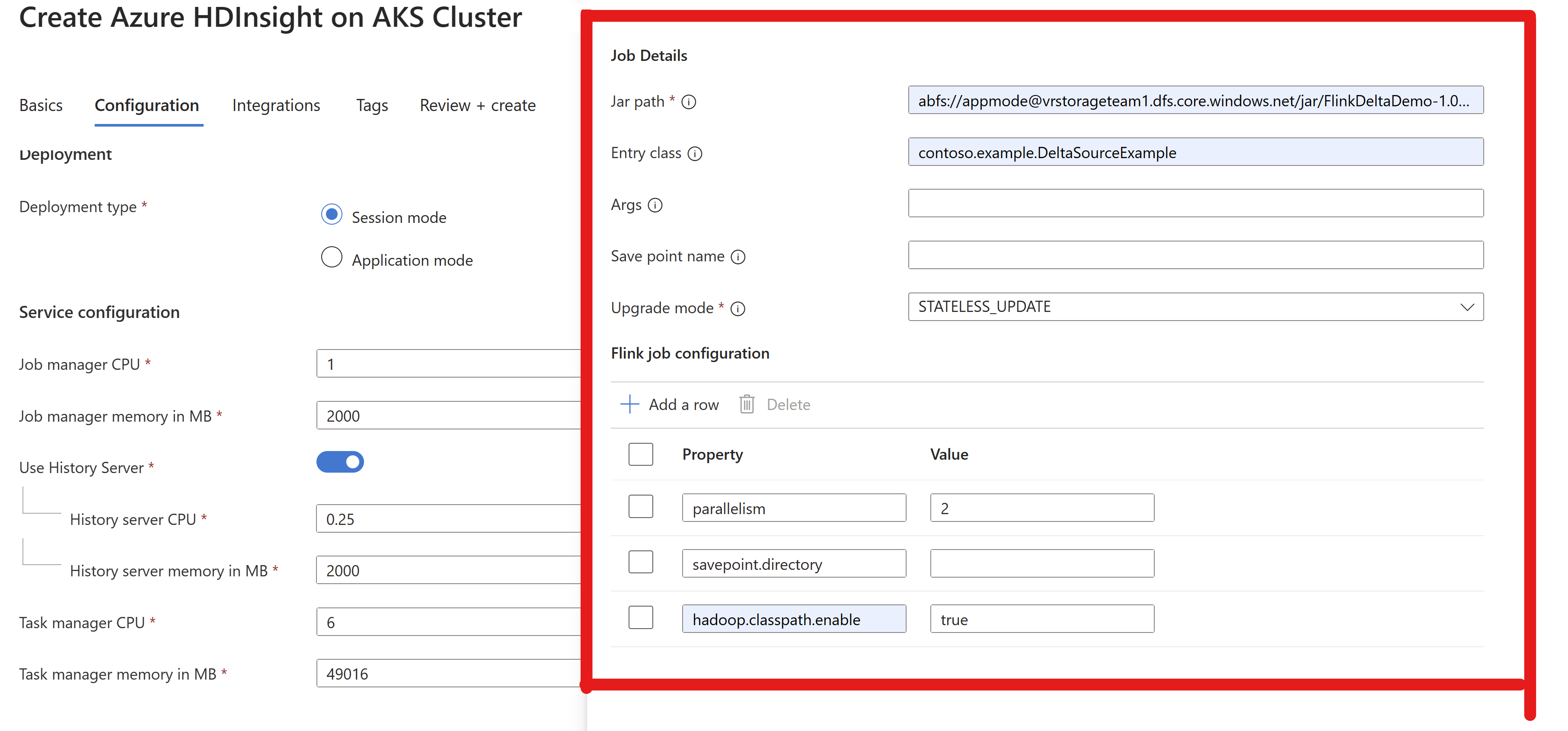
Notatka
Zawsze włączaj
hadoop.classpath.enablepodczas odczytywania/zapisywania w usłudze ADLS.Prześlij klaster. Powinno być możliwe wyświetlenie zadania w interfejsie użytkownika Flink.

Znajdź wyniki w usłudze ADLS.





Integracja z usługą Power BI
Gdy dane są w ujściu różnicowym, możesz uruchomić zapytanie w programie Power BI Desktop i utworzyć raport.
Otwórz program Power BI Desktop, aby pobrać dane przy użyciu łącznika ADLS Gen2.
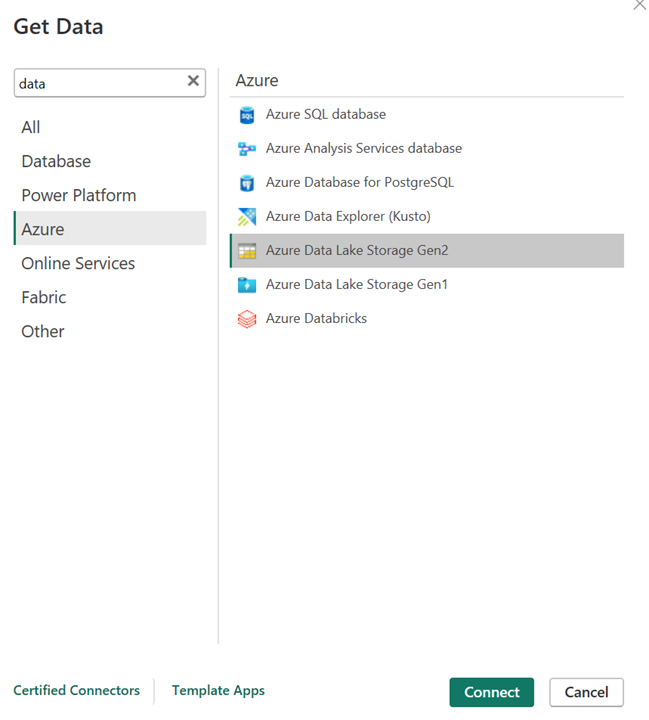
Adres URL konta magazynu.

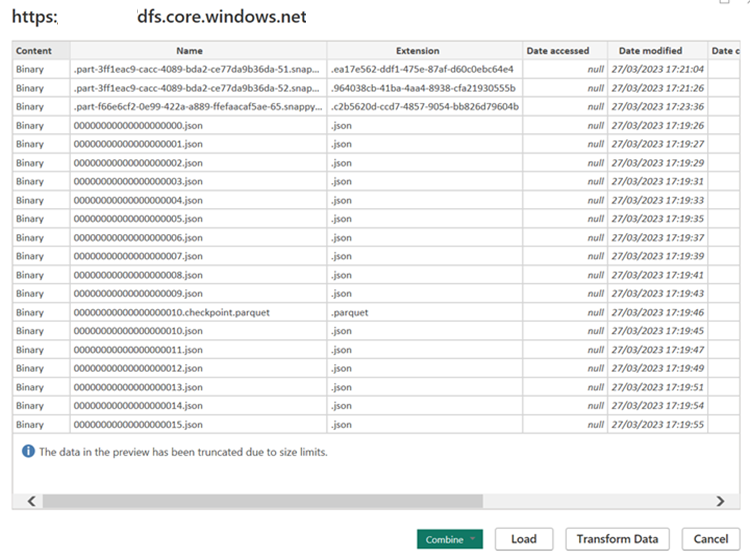
Utwórz zapytanie M dla źródła i wywołaj funkcję, która pobiera dane z konta magazynowego.
Gdy dane będą łatwo dostępne, możesz tworzyć raporty.
Bibliografia
- Nazwy projektów typu open source Apache, Apache Flink, Flink i skojarzone są znakami towarowymiApache Software Foundation (ASF).