Dostrajanie Azure Data Lake Storage Gen1 pod kątem wydajności
Data Lake Storage Gen1 obsługuje wysoką przepływność na potrzeby intensywnej analizy operacji we/wy i przenoszenia danych. W Data Lake Storage Gen1 użycie całej dostępnej przepływności — ilości danych, które mogą być odczytywane lub zapisywane na sekundę — jest ważne, aby uzyskać najlepszą wydajność. Jest to osiągane przez wykonanie jak największej liczby operacji odczytu i zapisu równolegle.
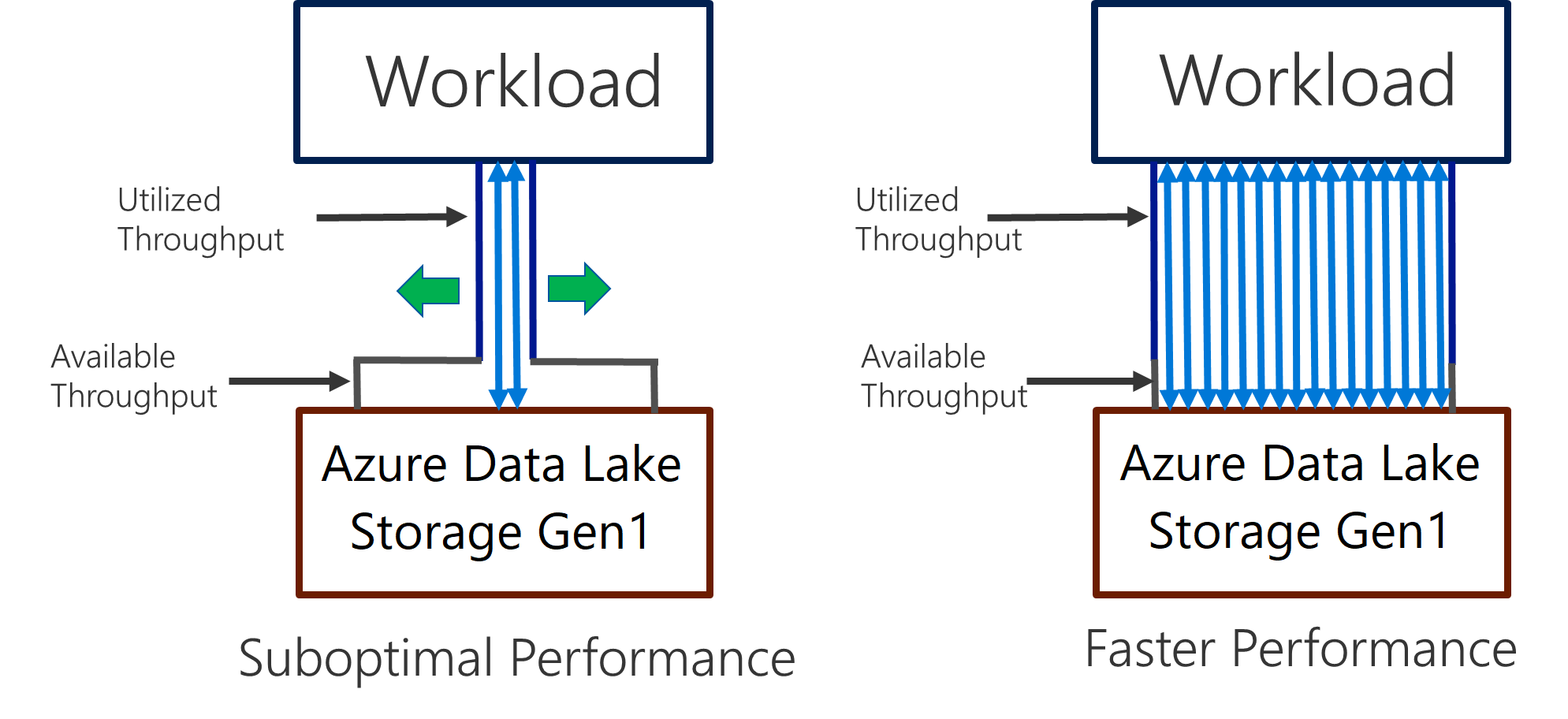
Data Lake Storage Gen1 można skalować w celu zapewnienia niezbędnej przepływności dla wszystkich scenariuszy analizy. Domyślnie konto Data Lake Storage Gen1 zapewnia automatycznie wystarczającą przepływność, aby zaspokoić potrzeby szerokiej kategorii przypadków użycia. W przypadku przypadków, w których klienci napotykają domyślny limit, można skonfigurować konto Data Lake Storage Gen1 w celu zapewnienia większej przepływności, kontaktując się z pomocą techniczną firmy Microsoft.
Wprowadzanie danych
Podczas pozyskiwania danych z systemu źródłowego do Data Lake Storage Gen1 należy wziąć pod uwagę, że źródłowy sprzęt, sprzęt sieci źródłowej i łączność sieciowa z Data Lake Storage Gen1 może być wąskim gardłem.
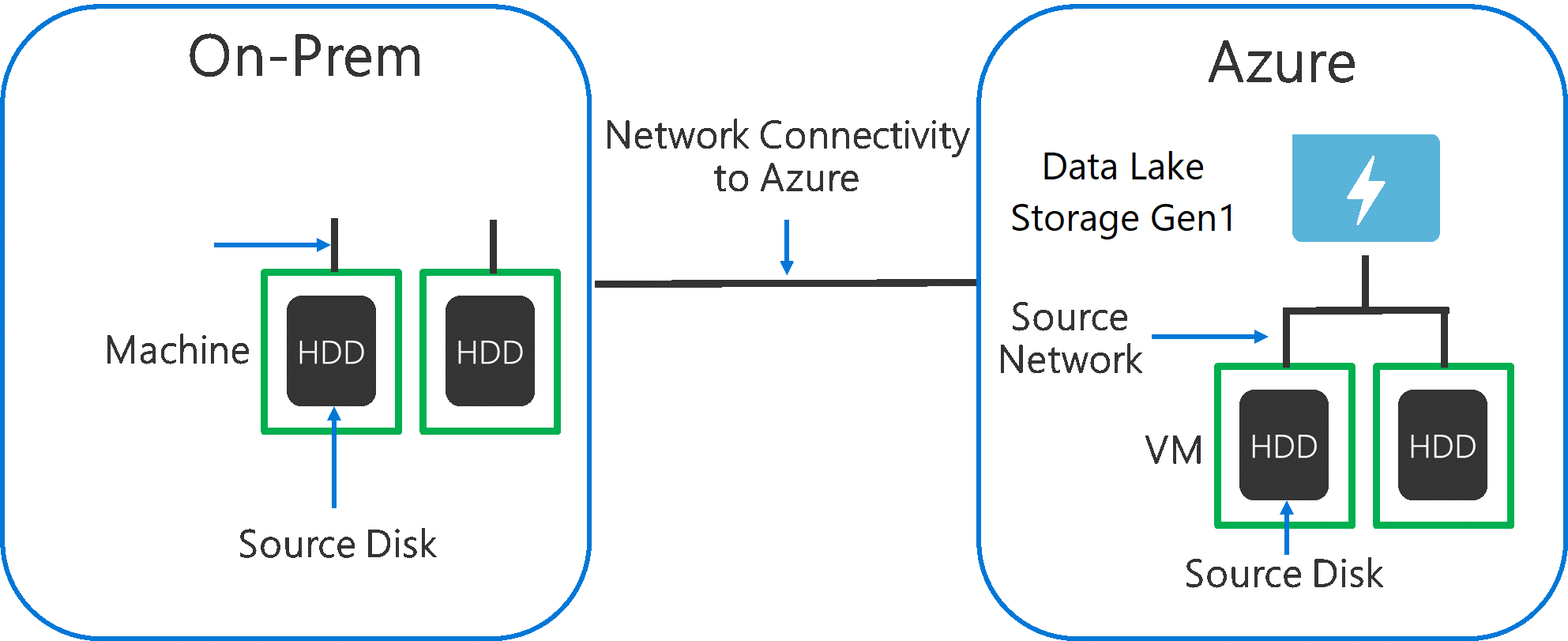
Ważne jest, aby upewnić się, że przenoszenie danych nie ma wpływu na te czynniki.
Sprzęt źródłowy
Niezależnie od tego, czy używasz maszyn lokalnych, czy maszyn wirtualnych na platformie Azure, należy starannie wybrać odpowiedni sprzęt. W przypadku sprzętu dysku źródłowego preferuj dyski SSD do dysków HDD i wybieraj sprzęt dysku z szybszymi wrzecionami. W przypadku sprzętu sieci źródłowej użyj najszybszych możliwych kart sieciowych. Na platformie Azure zalecamy maszyny wirtualne usługi Azure D14, które mają odpowiednio zaawansowany sprzęt dyskowy i sieciowy.
Łączność sieciowa z Data Lake Storage Gen1
Łączność sieciowa między danymi źródłowymi i Data Lake Storage Gen1 czasami może być wąskim gardłem. Jeśli dane źródłowe są lokalne, rozważ użycie dedykowanego linku z usługą Azure ExpressRoute . Jeśli dane źródłowe są na platformie Azure, wydajność będzie najlepsza, gdy dane są w tym samym regionie świadczenia usługi Azure co konto Data Lake Storage Gen1.
Konfigurowanie narzędzi do pozyskiwania danych na potrzeby maksymalnej równoległej
Po rozwiązaniu problemów ze źródłowym sprzętem i wąskimi gardłami łączności sieciowej możesz przystąpić do konfigurowania narzędzi do pozyskiwania. Poniższa tabela zawiera podsumowanie kluczowych ustawień kilku popularnych narzędzi do pozyskiwania i zawiera szczegółowe artykuły dotyczące dostrajania wydajności. Aby dowiedzieć się więcej na temat tego narzędzia do użycia w scenariuszu, odwiedź ten artykuł.
| Narzędzie | Ustawienia | Więcej szczegółów |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Link |
| AdlCopy | Jednostki usługi Azure Data Lake Analytics | Link |
| DistCp | -m (maper) | Link |
| Azure Data Factory | parallelCopies | Link |
| Sqoop | fs.azure.block.size, -m (maper) | Link |
Struktura zestawu danych
Gdy dane są przechowywane w Data Lake Storage Gen1, rozmiar pliku, liczba plików i struktura folderów wpływają na wydajność. W poniższej sekcji opisano najlepsze rozwiązania w tych obszarach.
Rozmiar pliku
Zazwyczaj aparaty analityczne, takie jak HDInsight i Azure Data Lake Analytics mają obciążenie na plik. Jeśli przechowujesz dane tak wiele małych plików, może to negatywnie wpłynąć na wydajność.
Ogólnie rzecz biorąc, porządkuj dane w większe pliki o większych rozmiarach, aby uzyskać lepszą wydajność. Zgodnie z zasadą organizowania zestawów danych w plikach o rozmiarze 256 MB lub większym. W niektórych przypadkach, takich jak obrazy i dane binarne, nie można ich przetworzyć równolegle. W takich przypadkach zaleca się przechowywanie pojedynczych plików poniżej 2 GB.
Czasami potoki danych mają ograniczoną kontrolę nad nieprzetworzonymi danymi, które mają wiele małych plików. Zaleca się posiadanie procesu "gotowania", który generuje większe pliki do użycia w aplikacjach podrzędnych.
Organizowanie danych szeregów czasowych w folderach
W przypadku obciążeń Hive i ADLA oczyszczanie partycji danych szeregów czasowych może pomóc niektórym zapytaniom w odczytywaniu tylko podzestawu danych, co zwiększa wydajność.
Te potoki, które pozyskiwają dane szeregów czasowych, często umieszczają pliki ze strukturą nazewnictwa plików i folderów. Poniżej przedstawiono typowy przykład danych, które są ustrukturyzowane według daty: \DataSet\RRRR\MM\DD\datafile_YYYY_MM_DD.tsv.
Zwróć uwagę, że informacje o dacie/dacie są wyświetlane zarówno jako foldery, jak i w nazwie pliku.
W przypadku daty i godziny jest to typowy wzorzec: \DataSet\RRRR\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv.
Ponownie wybór w organizacji folderów i plików powinien być zoptymalizowany pod kątem większych rozmiarów plików i rozsądnej liczby plików w każdym folderze.
Optymalizowanie zadań intensywnie korzystających z operacji we/wy na obciążeniach Platformy Hadoop i Spark w usłudze HDInsight
Zadania należą do jednej z następujących trzech kategorii:
- Intensywnie korzystających z procesora CPU. Te zadania mają długi czas obliczeń z minimalnymi czasami we/wy. Przykłady obejmują uczenie maszynowe i zadania przetwarzania języka naturalnego.
- Intensywnie korzystających z pamięci. Te zadania używają dużej ilości pamięci. Przykłady obejmują zadania analizy pageRank i analizy w czasie rzeczywistym.
- Intensywne we/wy. Te zadania spędzają większość czasu na wykonywaniu operacji we/wy. Typowym przykładem jest zadanie kopiowania, które wykonuje tylko operacje odczytu i zapisu. Inne przykłady obejmują zadania przygotowywania danych, które odczytują wiele danych, wykonują pewne przekształcenia danych, a następnie zapisują dane z powrotem do magazynu.
Poniższe wskazówki dotyczą tylko zadań intensywnie korzystających z operacji we/wy.
Ogólne zagadnienia dotyczące klastra usługi HDInsight
- Wersje usługi HDInsight. Aby uzyskać najlepszą wydajność, użyj najnowszej wersji usługi HDInsight.
- Regionów. Umieść konto Data Lake Storage Gen1 w tym samym regionie co klaster usługi HDInsight.
Klaster usługi HDInsight składa się z dwóch węzłów głównych i niektórych węzłów roboczych. Każdy węzeł roboczy zapewnia określoną liczbę rdzeni i pamięci, która jest określana przez typ maszyny wirtualnej. Podczas uruchamiania zadania usługa YARN jest negocjatorem zasobów, który przydziela dostępną pamięć i rdzenie do tworzenia kontenerów. Każdy kontener uruchamia zadania potrzebne do ukończenia zadania. Kontenery są uruchamiane równolegle w celu szybkiego przetwarzania zadań. W związku z tym wydajność jest większa, uruchamiając jak najwięcej kontenerów równoległych.
Istnieją trzy warstwy w klastrze usługi HDInsight, które można dostosować w celu zwiększenia liczby kontenerów i używania całej dostępnej przepływności.
- Warstwa fizyczna
- Warstwa usługi YARN
- Warstwa obciążenia
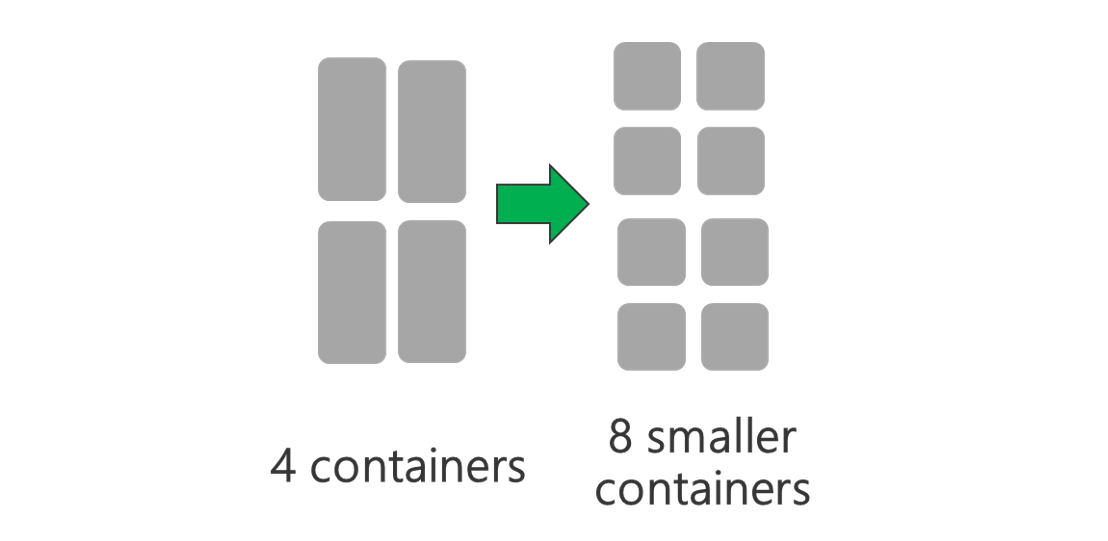
Warstwa fizyczna
Uruchom klaster z większą ilością węzłów i/lub większych maszyn wirtualnych. Większy klaster umożliwia uruchamianie większej liczby kontenerów usługi YARN, jak pokazano na poniższej ilustracji.

Używaj maszyn wirtualnych z większą przepustowością sieci. Przepustowość sieci może być wąskim gardłem, jeśli przepustowość sieci jest mniejsza niż Data Lake Storage Gen1 przepływności. Różne maszyny wirtualne będą miały różne rozmiary przepustowości sieci. Wybierz typ maszyny wirtualnej, który ma największą możliwą przepustowość sieci.
Warstwa usługi YARN
Użyj mniejszych kontenerów YARN. Zmniejsz rozmiar każdego kontenera usługi YARN, aby utworzyć więcej kontenerów o tej samej ilości zasobów.
W zależności od obciążenia zawsze wymagany będzie minimalny rozmiar kontenera usługi YARN. W przypadku wybrania zbyt małego kontenera zadania napotkają problemy z brakiem pamięci. Zazwyczaj kontenery YARN nie powinny być mniejsze niż 1 GB. Typowe jest wyświetlanie kontenerów YARN o pojemności 3 GB. W przypadku niektórych obciążeń może być konieczne większe kontenery usługi YARN.
Zwiększ liczbę rdzeni na kontener YARN. Zwiększ liczbę rdzeni przydzielonych do każdego kontenera, aby zwiększyć liczbę zadań równoległych uruchamianych w każdym kontenerze. Działa to w przypadku aplikacji takich jak Spark, które uruchamiają wiele zadań na kontener. W przypadku aplikacji takich jak Hive, które uruchamiają pojedynczy wątek w każdym kontenerze, lepiej jest mieć więcej kontenerów, a nie więcej rdzeni na kontener.
Warstwa obciążenia
Użyj wszystkich dostępnych kontenerów. Ustaw liczbę zadań, które mają być równe lub większe niż liczba dostępnych kontenerów, tak aby wszystkie zasoby były używane.
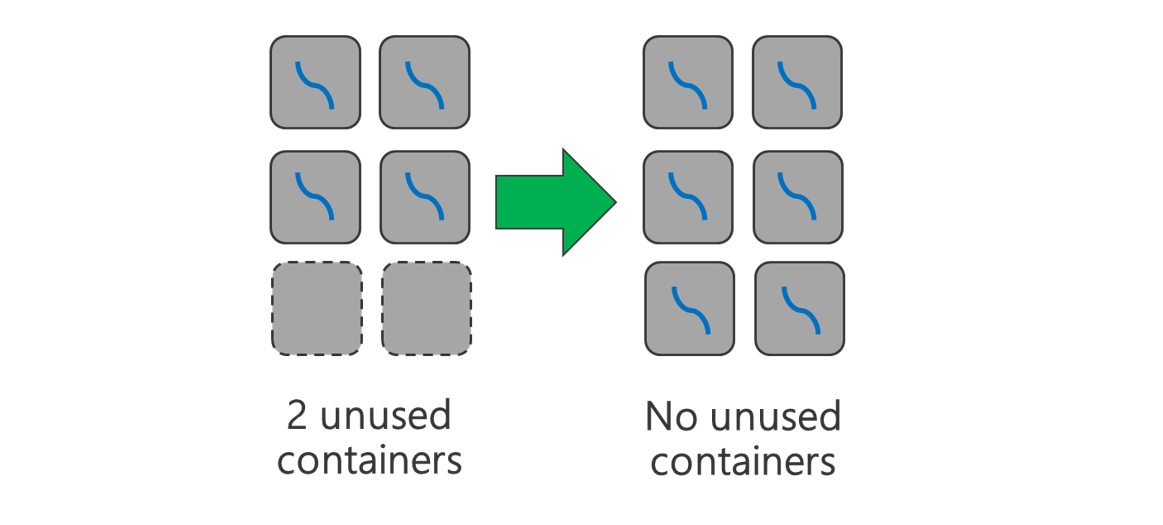
Zadania, które zakończyły się niepowodzeniem, są kosztowne. Jeśli każde zadanie ma dużą ilość danych do przetworzenia, wówczas niepowodzenie zadania powoduje kosztowne ponowienie próby. W związku z tym lepiej jest tworzyć więcej zadań, z których każdy przetwarza niewielką ilość danych.
Oprócz powyższych ogólnych wytycznych każda aplikacja ma różne parametry, które można dostosować dla tej konkretnej aplikacji. W poniższej tabeli wymieniono niektóre parametry i linki umożliwiające rozpoczęcie dostrajania wydajności dla każdej aplikacji.
| Obciążenie | Parametr do ustawiania zadań |
|---|---|
| Platforma Spark w usłudze HDInsight |
|
| Hive w usłudze HDInsight |
|
| Usługa MapReduce w usłudze HDInsight |
|
| Usługa Storm w usłudze HDInsight |
|