Rozwiązywanie problemów ze niesymetrycznością danych w usłudze Azure Data Lake Analytics przy użyciu Azure Data Lake Tools for Visual Studio
Ważne
Usługa Azure Data Lake Analytics została wycofana 29 lutego 2024 r. Dowiedz się więcej z tym ogłoszeniem.
W przypadku analizy danych organizacja może używać Azure Synapse Analytics lub Microsoft Fabric.
Co to jest niesymetryczność danych?
Krótko stwierdzono, że niesymetryczność danych jest wartością nadmiernie reprezentowaną. Załóżmy, że masz przypisanych 50 egzaminatorów podatkowych do inspekcji zeznań podatkowych, jeden egzaminator dla każdego stanu USA. Egzaminator Wyoming, ponieważ populacja jest mała, ma niewiele do zrobienia. W Kalifornii jednak egzaminator jest zajęty ze względu na dużą populację stanu.

W naszym scenariuszu dane są nierównomiernie rozłożone na wszystkich egzaminatorów podatkowych, co oznacza, że niektórzy egzaminatorzy muszą pracować więcej niż inne. W swojej własnej pracy często występują sytuacje, takie jak przykład analizy podatkowej tutaj. W bardziej technicznych kategoriach jeden wierzchołek dostaje znacznie więcej danych niż jego elementów równorzędnych, sytuacja, która sprawia, że wierzchołek działa więcej niż inne i że ostatecznie spowalnia całe zadanie. Co gorsza, zadanie może zakończyć się niepowodzeniem, ponieważ wierzchołki mogą mieć na przykład 5-godzinne ograniczenie czasu wykonywania i ograniczenie pamięci 6 GB.
Rozwiązywanie problemów ze niesymetrycznością danych
Azure Data Lake Tools for Visual Studio i Visual Studio Code mogą pomóc w wykrywaniu, czy zadanie ma problem z niesymetrycznością danych.
- Instalowanie narzędzi Azure Data Lake Tools for Visual Studio
- Instalowanie kodu Azure Data Lake Tools for Visual Studio
Jeśli problem istnieje, możesz go rozwiązać, próbując rozwiązać ten problem w tej sekcji.
Rozwiązanie 1. Ulepszanie partycjonowania tabel
Opcja 1. Przefiltruj niesymetryczną wartość klucza z wyprzedzeniem
Jeśli nie ma to wpływu na logikę biznesową, możesz filtrować wartości o wyższej częstotliwości z wyprzedzeniem. Jeśli na przykład istnieje wiele wartości 000-000-000 w identyfikatorze GUID kolumny, możesz nie chcieć agregować tej wartości. Przed zagregowaniem można napisać "WHERE GUID != "000-000-000", aby filtrować wartość o wysokiej częstotliwości.
Opcja 2. Wybierz inną partycję lub klucz dystrybucji
W poprzednim przykładzie, jeśli chcesz sprawdzić tylko obciążenie inspekcji podatkowej w całym kraju/regionie, możesz poprawić dystrybucję danych, wybierając numer identyfikatora jako klucz. Wybranie innego klucza partycji lub dystrybucji może czasami równomiernie dystrybuować dane, ale należy upewnić się, że ten wybór nie ma wpływu na logikę biznesową. Na przykład aby obliczyć sumę podatkową dla każdego stanu, możesz wyznaczyć stan jako klucz partycji. Jeśli nadal występuje ten problem, spróbuj użyć opcji 3.
Opcja 3. Dodawanie większej liczby partycji lub kluczy dystrybucji
Zamiast używać tylko stanu jako klucza partycji, można użyć więcej niż jednego klucza do partycjonowania. Rozważ na przykład dodanie kodu ZIP jako innego klucza partycji, aby zmniejszyć rozmiary partycji danych i równomiernie rozłożyć dane.
Opcja 4. Użyj dystrybucji działania okrężnego
Jeśli nie możesz znaleźć odpowiedniego klucza dla partycji i dystrybucji, możesz spróbować użyć dystrybucji działania okrężnego. Rozkład działania okrężnego traktuje wszystkie wiersze równie i losowo umieszcza je w odpowiednich zasobnikach. Dane są równomiernie dystrybuowane, ale tracą informacje o lokalizacji, wadę, która może również zmniejszyć wydajność zadań dla niektórych operacji. Ponadto jeśli mimo to wykonujesz agregację dla niesymetrycznego klucza, problem z niesymetrycznością danych będzie się powtarzać. Aby dowiedzieć się więcej na temat dystrybucji okrężnej, zobacz sekcję Rozkłady tabel U-SQL w temacie CREATE TABLE (U-SQL): Create a Table with Schema (Tworzenie tabeli przy użyciu schematu).
Rozwiązanie 2. Ulepszanie planu zapytania
Opcja 1. Użyj instrukcji CREATE STATISTICS
Język U-SQL udostępnia instrukcję CREATE STATISTICS w tabelach. Ta instrukcja zawiera więcej informacji do optymalizatora zapytań dotyczących cech danych (na przykład rozkładu wartości), które są przechowywane w tabeli. W przypadku większości zapytań optymalizator zapytań generuje już niezbędne statystyki dla planu zapytań wysokiej jakości. Czasami może być konieczne zwiększenie wydajności zapytań przez utworzenie większej liczby statystyk za pomocą polecenia CREATE STATISTICS lub zmodyfikowanie projektu zapytania. Aby uzyskać więcej informacji, zobacz stronę CREATE STATISTICS (U-SQL).
Przykład kodu:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Uwaga
Informacje o statystykach nie są aktualizowane automatycznie. Jeśli zaktualizujesz dane w tabeli bez ponownego utworzenia statystyk, wydajność zapytania może ulec pogorszeniu.
Opcja 2. Używanie narzędzia SKEWFACTOR
Jeśli chcesz zsumować podatek dla każdego stanu, musisz użyć stanu GROUP BY, czyli podejścia, które nie pozwala uniknąć problemu z niesymetrycznością danych. Jednak możesz podać wskazówkę dotyczącą danych w zapytaniu, aby zidentyfikować niesymetryczność danych w kluczach, aby optymalizator mógł przygotować plan wykonania.
Zazwyczaj można ustawić parametr jako 0,5 i 1, z wartością 0,5 co oznacza niesymetryczność i jedno oznacza duże niesymetryczność. Ponieważ wskazówka ma wpływ na optymalizację planu wykonywania dla bieżącej instrukcji i wszystkich instrukcji podrzędnych, pamiętaj, aby dodać wskazówkę przed potencjalną niesymetryczną agregacją klucza.
SKEWFACTOR (columns) = x
Zawiera wskazówkę, że podane kolumny mają niesymetryczny współczynnik x od 0 (bez niesymetryczności) do 1 (ciężkie niesymetryczność).
Przykład kodu:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
Opcja 3. Użyj funkcji ROWCOUNT
Oprócz skEWFACTOR, w przypadku określonych niesymetrycznych przypadków sprzężenia klucza, jeśli wiesz, że inny zestaw dołączonych wierszy jest mały, możesz powiedzieć optymalizator, dodając wskazówkę ROWCOUNT w instrukcji U-SQL przed JOIN. Dzięki temu optymalizator może wybrać strategię dołączenia do emisji, aby zwiększyć wydajność. Pamiętaj, że funkcja ROWCOUNT nie rozwiązuje problemu niesymetryczności danych, ale może zaoferować dodatkową pomoc.
OPTION(ROWCOUNT = n)
Zidentyfikuj mały zestaw wierszy przed dołączeniem, podając szacowaną liczbę wierszy całkowitych.
Przykład kodu:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
Rozwiązanie 3. Ulepszanie reduktora zdefiniowanego przez użytkownika i łączenia
Czasami można napisać operatora zdefiniowanego przez użytkownika, aby poradzić sobie ze skomplikowaną logiką procesu, a dobrze napisany reduktor i kombinator może w niektórych przypadkach wyeliminować problem niesymetryczności danych.
Opcja 1. Użyj rekursywnego reduktora, jeśli to możliwe
Domyślnie reduktor zdefiniowany przez użytkownika jest uruchamiany w trybie niecyklicznym, co oznacza, że praca redukcji klucza jest dystrybuowana do pojedynczego wierzchołka. Jeśli jednak dane są niesymetryczne, ogromne zestawy danych mogą być przetwarzane w jednym wierzchołku i działać przez długi czas.
Aby poprawić wydajność, możesz dodać atrybut w kodzie, aby zdefiniować reduktor do uruchamiania w trybie cyklicznym. Następnie ogromne zestawy danych można dystrybuować do wielu wierzchołków i uruchamiać równolegle, co przyspiesza zadanie.
Aby zmienić rekursywny rekursywny, należy upewnić się, że algorytm jest asocjacyjny. Na przykład suma jest asocjacyjna, a mediana nie jest. Należy również upewnić się, że dane wejściowe i wyjściowe reduktora zachowają ten sam schemat.
Atrybut rekursywnego reduktora:
[SqlUserDefinedReducer(IsRecursive = true)]
Przykład kodu:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
Opcja 2. Użyj trybu łączenia na poziomie wiersza, jeśli to możliwe
Podobnie jak wskazówka ROWCOUNT dla konkretnych przypadków sprzężenia klucza niesymetrycznego, tryb łączenia próbuje dystrybuować ogromne niesymetryczne zestawy wartości klucza do wielu wierzchołków, aby można było wykonać pracę współbieżnie. Tryb łączenia nie może rozwiązać problemów z niesymetrycznością danych, ale może zaoferować dodatkową pomoc dla ogromnych niesymetrycznych zestawów wartości klucza.
Domyślnie tryb łączenia jest pełny, co oznacza, że zestaw wierszy po lewej stronie i zestaw wierszy po prawej stronie nie może być oddzielony. Ustawienie trybu jako Lewa/Prawa/Wewnętrzna umożliwia sprzężenie na poziomie wiersza. System oddziela odpowiednie zestawy wierszy i dystrybuuje je do wielu wierzchołków uruchamianych równolegle. Jednak przed skonfigurowaniem trybu łączenia należy zachować ostrożność, aby upewnić się, że odpowiednie zestawy wierszy można oddzielić.
W poniższym przykładzie przedstawiono oddzielony zestaw wierszy po lewej stronie. Każdy wiersz wyjściowy zależy od pojedynczego wiersza wejściowego z lewej strony i potencjalnie zależy od wszystkich wierszy z prawej strony z tą samą wartością klucza. Jeśli ustawisz tryb łączenia w lewo, system oddziela ogromny lewy wiersz na małe i przypisuje je do wielu wierzchołków.
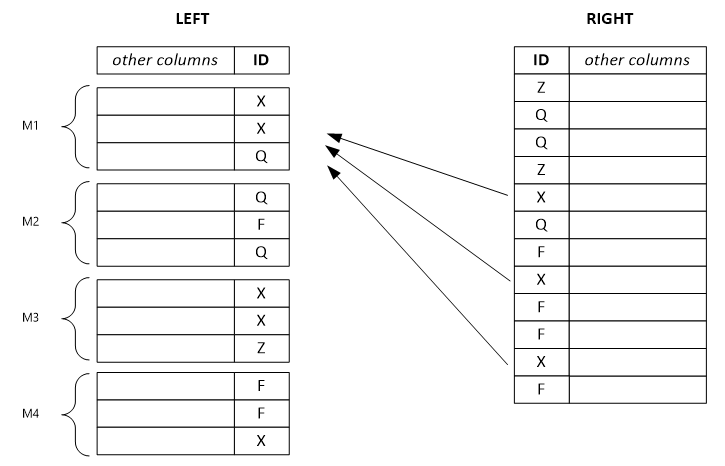
Uwaga
Jeśli ustawisz niewłaściwy tryb łączenia, kombinacja jest mniej wydajna, a wyniki mogą być nieprawidłowe.
Atrybuty trybu łączenia:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): każdy wiersz wyjściowy potencjalnie zależy od wszystkich wierszy wejściowych z lewej i prawej z tą samą wartością klucza.
SqlUserDefinedCombiner(Mode=CombinerMode.Left): każdy wiersz wyjściowy zależy od jednego wiersza wejściowego z lewej strony (i potencjalnie wszystkich wierszy z prawej strony z tą samą wartością klucza).
qlUserDefinedCombiner(Mode=CombinerMode.Right): Każdy wiersz danych wyjściowych zależy od jednego wiersza wejściowego z prawej strony (i potencjalnie wszystkich wierszy z lewej strony z tą samą wartością klucza).
SqlUserDefinedCombiner(Mode=CombinerMode.Inner): każdy wiersz danych wyjściowych zależy od jednego wiersza wejściowego z lewej strony i po prawej stronie o tej samej wartości.
Przykład kodu:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}