Optymalizowanie dodatku Power Query podczas rozwijania kolumn tabeli
Prostota i łatwość użycia, która umożliwia użytkownikom usługi Power BI szybkie zbieranie danych i generowanie interesujących i zaawansowanych raportów w celu podejmowania inteligentnych decyzji biznesowych umożliwia również użytkownikom łatwe generowanie zapytań o niskiej wydajności. Dzieje się tak często, gdy istnieją dwie tabele, które są powiązane w sposób, w jaki klucz obcy jest powiązany z tabelami SQL lub listami programu SharePoint. (W przypadku rekordu ten problem nie jest specyficzny dla języka SQL lub programu SharePoint i występuje w wielu scenariuszach wyodrębniania danych zaplecza, szczególnie w przypadku, gdy schemat jest płynny i możliwy do dostosowania). Nie ma też z natury nic złego w przechowywaniu danych w osobnych tabelach, które mają wspólny klucz — w rzeczywistości jest to podstawowy zestaw zasad projektowania i normalizacji bazy danych. Ale oznacza to lepszy sposób na rozszerzenie relacji.
Rozważmy poniższy przykład listy klientów programu SharePoint.
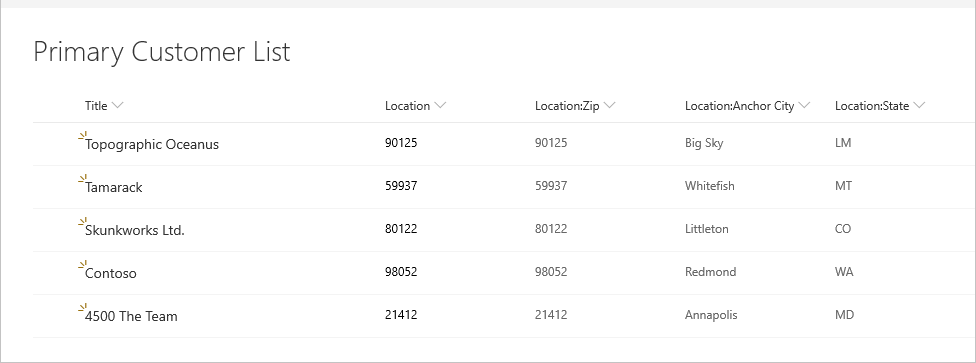
A poniższa lista lokalizacji odnosi się do niej.
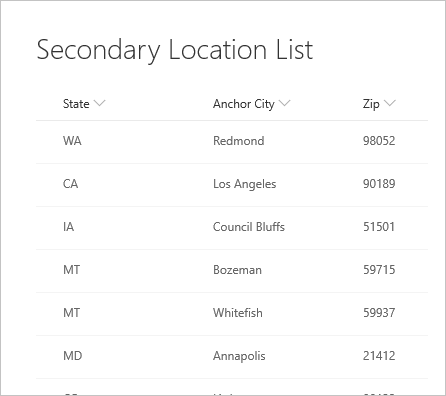
Podczas pierwszego nawiązywania połączenia z listą lokalizacja jest wyświetlana jako rekord.
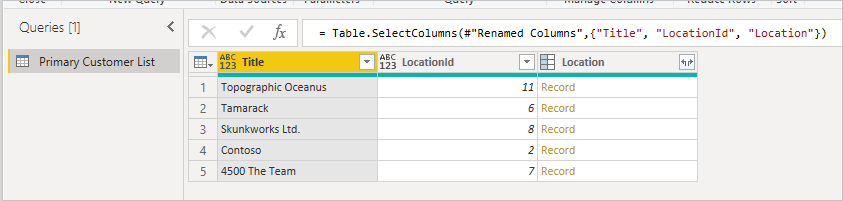
Te dane najwyższego poziomu są zbierane za pośrednictwem pojedynczego wywołania HTTP do interfejsu API programu SharePoint (ignorując wywołanie metadanych), które można zobaczyć w dowolnym debugerze internetowym.

Po rozwinięciu rekordu zobaczysz pola sprzężone z tabeli pomocniczej.
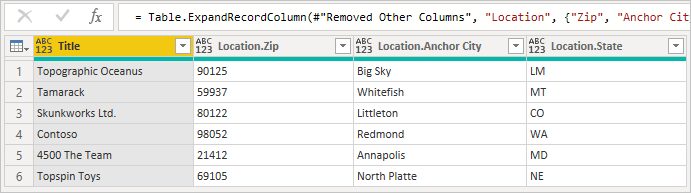
Podczas rozwijania powiązanych wierszy z jednej tabeli do innej domyślne zachowanie usługi Power BI polega na wygenerowaniu wywołania metody Table.ExpandTableColumn. Można to zobaczyć w polu wygenerowanej formuły. Niestety ta metoda generuje pojedyncze wywołanie drugiej tabeli dla każdego wiersza w pierwszej tabeli.
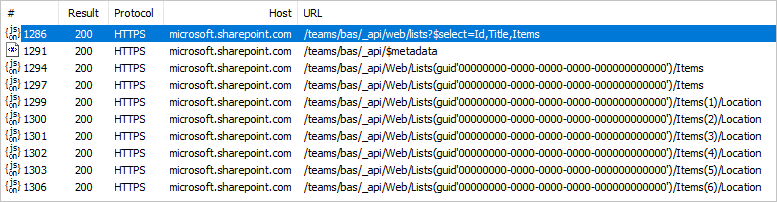
Zwiększa to liczbę wywołań HTTP o jeden dla każdego wiersza na liście podstawowej. Może to nie wydawać się dużo w powyższym przykładzie pięciu lub sześciu wierszy, ale w systemach produkcyjnych, w których listy programu SharePoint docierają do setek tysięcy wierszy, może to spowodować znaczne pogorszenie środowiska.
Gdy zapytania osiągną to wąskie gardło, najlepszym ograniczeniem jest uniknięcie zachowania wywołań na wiersz przy użyciu klasycznego sprzężenia tabeli. Gwarantuje to, że będzie tylko jedno wywołanie w celu pobrania drugiej tabeli, a pozostała część rozszerzenia może wystąpić w pamięci przy użyciu klucza wspólnego między dwiema tabelami. Różnica wydajności może być ogromna w niektórych przypadkach.
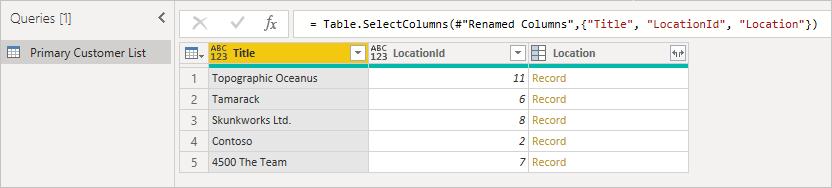
Najpierw zacznij od oryginalnej tabeli, zwracając uwagi na kolumnę, którą chcesz rozwinąć, i upewnij się, że masz identyfikator elementu, aby można było go dopasować. Zazwyczaj klucz obcy ma nazwę podobną do nazwy wyświetlanej kolumny z dołączonym identyfikatorem. W tym przykładzie jest to LocationId.
Po drugie załaduj tabelę pomocniczą, upewniając się, że identyfikator jest kluczem obcym. Kliknij prawym przyciskiem myszy panel Zapytania, aby utworzyć nowe zapytanie.
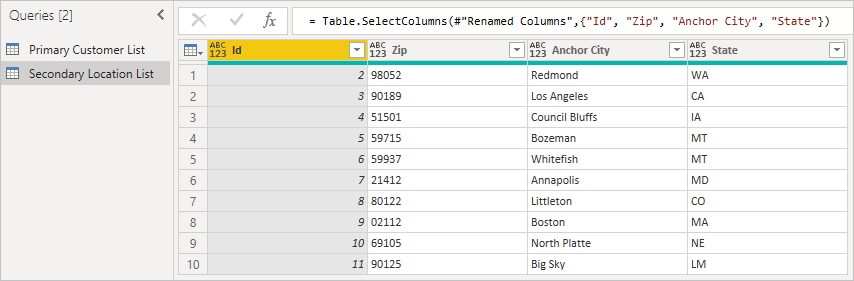
Na koniec połącz dwie tabele przy użyciu odpowiednich nazw kolumn, które są zgodne. Zazwyczaj to pole można znaleźć, rozwijając najpierw kolumnę, a następnie wyszukując pasujące kolumny w wersji zapoznawczej.

W tym przykładzie można zobaczyć, że identyfikator LocationId na liście podstawowej jest zgodny z identyfikatorem na liście pomocniczej. Interfejs użytkownika zmienia nazwę na Location.Id , aby nazwa kolumny została unikatowa. Teraz użyjemy tych informacji, aby scalić tabele.
Klikając prawym przyciskiem myszy panel zapytania i wybierając pozycję Nowe zapytanie>połącz>zapytania scalane jako nowe, zobaczysz przyjazny interfejs użytkownika, aby ułatwić łączenie tych dwóch zapytań.
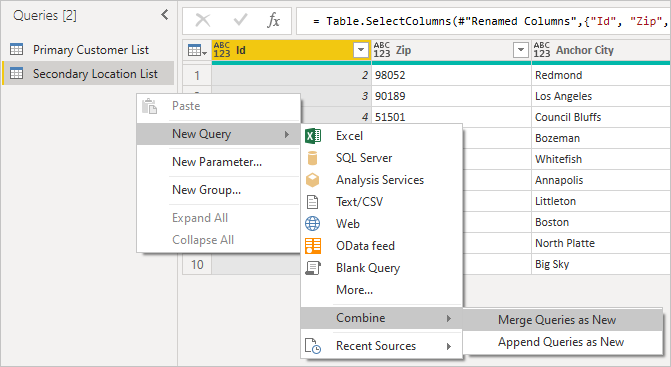
Wybierz każdą tabelę z listy rozwijanej, aby wyświetlić podgląd zapytania.
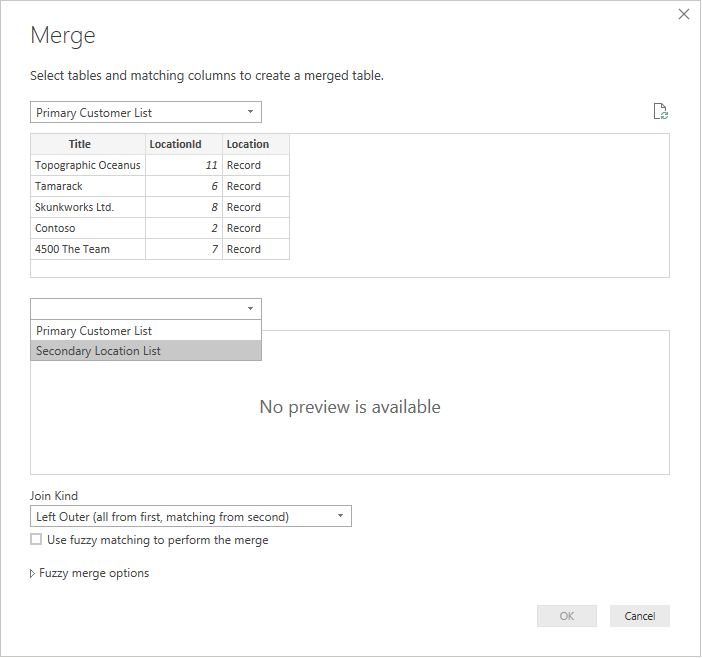
Po wybraniu obu tabel wybierz kolumnę, która łączy tabele logicznie (w tym przykładzie jest to LocationId z tabeli podstawowej i identyfikator z tabeli pomocniczej). W oknie dialogowym zostanie wyświetlonych instrukcje, ile wierszy jest dopasowanych przy użyciu tego klucza obcego. Prawdopodobnie użyjesz domyślnego rodzaju sprzężenia (lewego zewnętrznego) dla tego rodzaju danych.
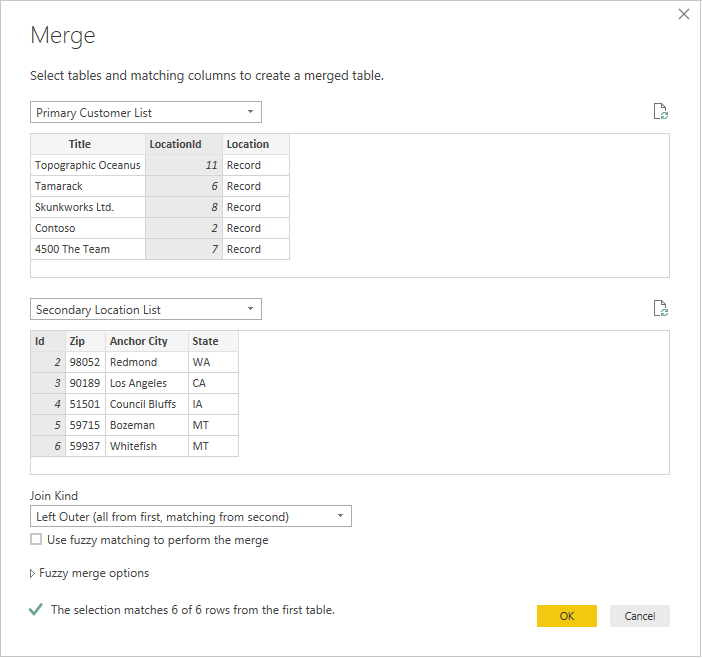
Wybierz przycisk OK i zobaczysz nowe zapytanie, które jest wynikiem sprzężenia. Rozszerzenie rekordu nie oznacza teraz dodatkowych wywołań zaplecza.

Odświeżanie tych danych spowoduje tylko dwa wywołania programu SharePoint — jedno dla listy podstawowej i jedno dla listy pomocniczej. Sprzężenie zostanie wykonane w pamięci, co znacznie zmniejsza liczbę wywołań programu SharePoint.
Tego podejścia można użyć w przypadku dwóch tabel w usłudze PowerQuery, które mają pasujący klucz obcy.
Uwaga
Listy użytkowników programu SharePoint i taksonomia są również dostępne jako tabele i można je połączyć dokładnie w sposób opisany powyżej, pod warunkiem, że użytkownik ma odpowiednie uprawnienia dostępu do tych list.