Zrozumienie różnic między typami przepływów danych
Przepływy danych służą do wyodrębniania, przekształcania i ładowania danych do miejsca docelowego magazynu, gdzie mogą być używane w różnych scenariuszach. Ponieważ nie wszystkie miejsca docelowe magazynu mają te same cechy, niektóre funkcje i zachowania przepływu danych różnią się w zależności od miejsca docelowego magazynu, do którego przepływ danych ładuje dane. Przed utworzeniem przepływu danych ważne jest, aby zrozumieć, jak będą używane dane, i wybrać miejsce docelowe magazynu zgodnie z wymaganiami rozwiązania.
Wybranie miejsca docelowego magazynu przepływu danych określa typ przepływu danych. Przepływ danych, który ładuje dane do tabel usługi Dataverse, jest klasyfikowany jako standardowy przepływ danych. Przepływy danych, które ładują dane do tabel analitycznych, są klasyfikowane jako przepływ danych analitycznych.
Przepływy danych utworzone w usłudze Power BI są zawsze analitycznymi przepływami danych. Przepływy danych utworzone w usłudze Power Apps mogą być standardowe lub analityczne, w zależności od wyboru podczas tworzenia przepływu danych.
Standardowe przepływy danych
Standardowy przepływ danych ładuje dane do tabel Usługi Dataverse. Standardowe przepływy danych można tworzyć tylko w usłudze Power Apps. Jedną z zalet tworzenia tego typu przepływu danych jest to, że każda aplikacja, która zależy od danych w usłudze Dataverse, może współpracować z danymi utworzonymi przez standardowe przepływy danych. Typowe aplikacje korzystające z tabel Dataverse to Power Apps, Power Automate, AI Builder i Power Virtual Agents.
Aby utworzyć przepływ danych w usłudze Power Apps:
Na kartach usługi Power Apps wybierz pozycję Więcej.
Wybierz pozycję Przepływy danych.
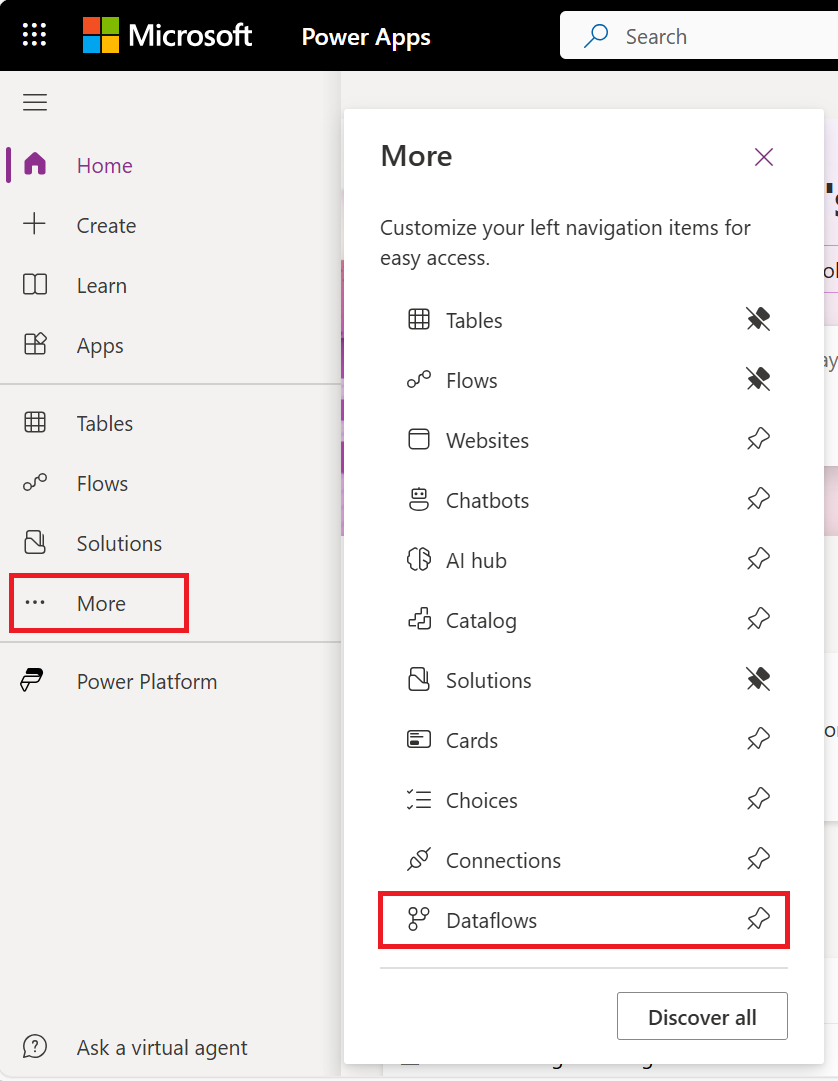
Wybierz pozycję Nowy przepływ danych.
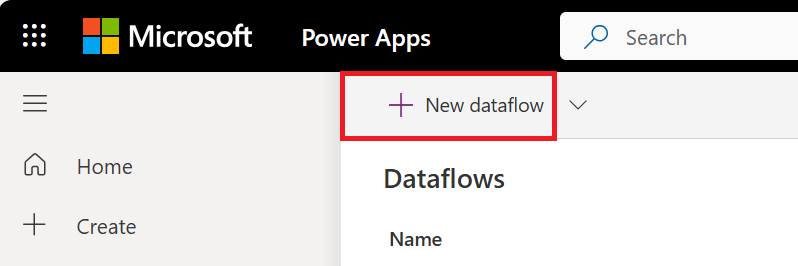
Jeśli tworzysz pierwszy przepływ danych, możesz również wybrać przycisk Utwórz przepływ danych.
Wersje standardowych przepływów danych
Uwaga
Zachęcamy użytkowników przepływu danych platformy Power Platform do migrowania ze standardowych przepływów danych w wersji 1 do standardowych przepływów danych w wersji 2. Przepływy danych w wersji 1 w warstwie Standardowa są w najbliższej przyszłości nieobsługiwane. Aby uzyskać więcej informacji na temat migracji do standardowych przepływów danych w wersji 2, zobacz Migrowanie standardowego przepływu danych w wersji 1 do standardowego przepływu danych w wersji 2.
Pracujemy nad znaczącymi aktualizacjami standardowych przepływów danych w celu zwiększenia ich wydajności i niezawodności. Te ulepszenia będą ostatecznie dostępne dla wszystkich standardowych przepływów danych. Jednak w międzyczasie rozróżniamy istniejące standardowe przepływy danych (wersja 1) i nowe standardowe przepływy danych (wersja 2), dodając wskaźnik wersji w usłudze Power Apps.

Porównanie funkcji standardowych wersji przepływu danych
W poniższej tabeli wymieniono główne różnice funkcji między standardowymi przepływami danych w wersji 1 i w wersji 2 oraz przedstawiono informacje o zachowaniu poszczególnych funkcji w każdej wersji.
| Funkcja | Standardowa V1 | Standardowa V2 |
|---|---|---|
| Maksymalna liczba przepływów danych, które można zapisywać z automatycznym harmonogramem dla dzierżawy klienta | 50 | Nieograniczony |
| Maksymalna liczba rekordów pozyskanych na kwerendę/tabelę | 500,000 | Bezgraniczny. Maksymalna liczba rekordów, które można pozyskać na zapytanie lub tabelę, zależy teraz od limitów ochrony usługi Dataverse w czasie pozyskiwania. |
| Szybkość pozyskiwania danych w usłudze Dataverse | Wydajność wg planu bazowego | Zwiększona wydajność o kilka czynników. Rzeczywiste wyniki mogą się różnić i zależeć od cech pozyskanych danych oraz obciążenia usługi Dataverse w momencie pozyskiwania. |
| Zasady odświeżania przyrostowego | Nieobsługiwane | Obsługiwane |
| Odporność | W przypadku napotkania limitów ochrony usługi Dataverse rekord jest ponawiany do trzech razy. | W przypadku napotkania limitów ochrony usługi Dataverse rekord jest ponawiany do trzech razy. |
| Integracja z usługą Power Automate | Nieobsługiwane | Obsługiwane |
Analityczne przepływy danych
Analityczny przepływ danych ładuje dane do typów magazynu zoptymalizowanych pod kątem analizy — Azure Data Lake Storage. Środowiska platformy Microsoft Power Platform i obszary robocze usługi Power BI zapewniają klientom zarządzaną lokalizację magazynu analitycznego powiązaną z tymi licencjami produktów. Ponadto klienci mogą łączyć konto magazynu usługi Azure Data Lake w organizacji jako miejsce docelowe dla przepływów danych.
Analityczne przepływy danych są w stanie obsługiwać dodatkowe funkcje analityczne. Na przykład integracja z funkcjami sztucznej inteligencji usługi Power BI lub korzystaniem z tabel obliczeniowych, które zostały omówione w dalszej części.
Przepływy danych analitycznych można tworzyć w usłudze Power BI. Domyślnie ładują dane do zarządzanego magazynu usługi Power BI. Można jednak również skonfigurować usługę Power BI do przechowywania danych w usłudze Azure Data Lake Storage organizacji.
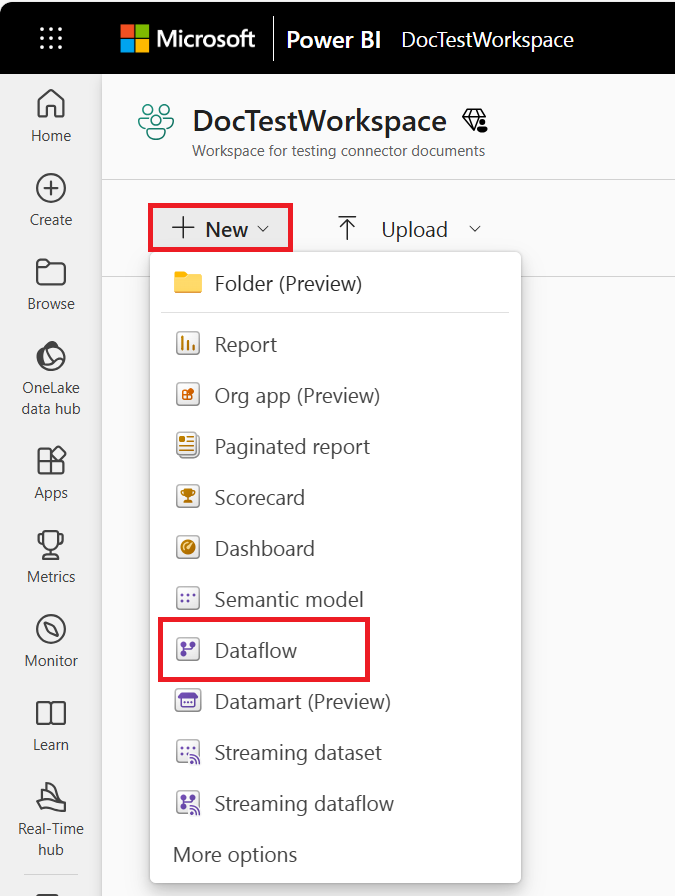
Możesz również tworzyć analityczne przepływy danych w portalach usługi Power Apps i Dynamics 365 Customer Insights. Podczas tworzenia przepływu danych w portalu usługi Power Apps możesz wybrać między magazynem analitycznym zarządzanym przez usługę Dataverse lub kontem usługi Azure Data Lake Storage w organizacji.
Integracja sztucznej inteligencji
Czasami w zależności od wymagania może być konieczne zastosowanie niektórych funkcji sztucznej inteligencji i uczenia maszynowego na danych za pośrednictwem przepływu danych. Te funkcje są dostępne w przepływach danych usługi Power BI i wymagają obszaru roboczego Premium.

W poniższych artykułach omówiono sposób używania funkcji sztucznej inteligencji w przepływie danych:
- Integracja usługi Azure Machine Learning w usłudze Power BI
- Usługi Cognitive Services w usłudze Power BI
- Zautomatyzowane uczenie maszynowe w usłudze Power BI
Funkcje wymienione w dwóch poprzednich sekcjach są specyficzne dla usługi Power BI i nie są dostępne podczas tworzenia przepływu danych w portalach usługi Power Apps lub Dynamics 365 Customer Insights.
Obliczone tabele
Jednym z powodów używania obliczonej tabeli jest możliwość przetwarzania dużych ilości danych. Tabela obliczeniowa pomaga w tych scenariuszach. Jeśli masz tabelę w przepływie danych, a inna tabela w tym samym przepływie danych używa danych wyjściowych pierwszej tabeli, ta akcja tworzy obliczoną tabelę.
Obliczona tabela pomaga w wydajności przekształceń danych. Zamiast ponownie wykonywać przekształcenia wymagane w pierwszej tabeli wielokrotnie, transformacja jest wykonywana tylko raz w obliczonej tabeli. Następnie wynik jest używany wiele razy w innych tabelach.
Aby dowiedzieć się więcej na temat tabel obliczeniowych, zobacz Tworzenie tabel obliczeniowych w przepływach danych.
Obliczone tabele są dostępne tylko w przepływie danych analitycznych.
Standardowe i analityczne przepływy danych
W poniższej tabeli wymieniono pewne różnice między tabelą standardową a tabelą analityczną.
| Operacja | Standardowa | Analityczny |
|---|---|---|
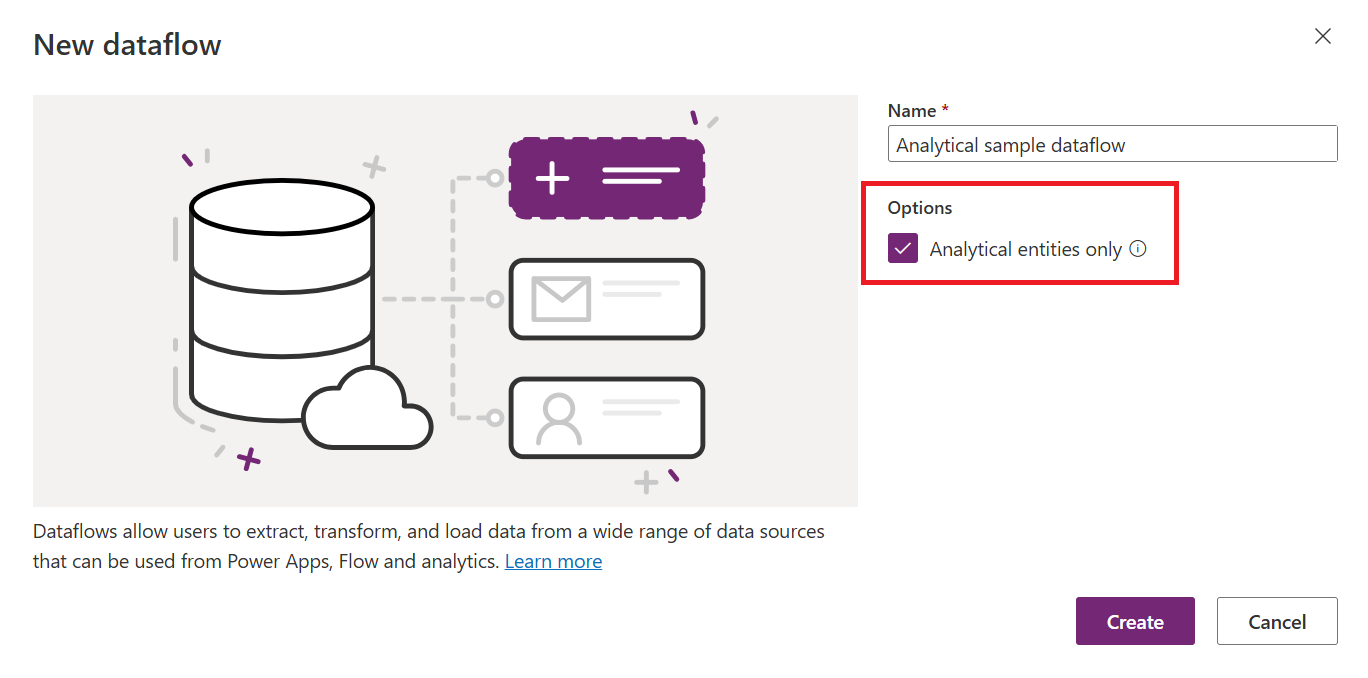
| Jak utworzyć | Przepływy danych platformy Power Platform | Przepływy danych usługi Power BI Przepływy danych platformy Power Platform, zaznaczając pole wyboru Jednostki analityczne tylko podczas tworzenia przepływu danych |
| Opcje magazynu | Dataverse | Usługa Power BI udostępniała magazyn usługi Azure Data Lake dla przepływów danych usługi Power BI, usługa Dataverse dostarczała magazyn usługi Azure Data Lake dla przepływów danych platformy Power Platform lub dostarczała magazyn usługi Azure Data Lake |
| Przekształcenia dodatku Power Query | Tak | Tak |
| Funkcje sztucznej inteligencji | Nie. | Tak |
| Tabela obliczana | Nie. | Tak |
| Może być używany w innych aplikacjach | Tak, za pośrednictwem usługi Dataverse | Przepływy danych usługi Power BI: tylko w usłudze Power BI Przepływy danych platformy Power Platform lub zewnętrzne przepływy danych usługi Power BI: Tak, za pośrednictwem usługi Azure Data Lake Storage |
| Mapowanie na tabelę standardową | Tak | Tak |
| Ładowanie przyrostowe | Domyślne ładowanie przyrostowe Możliwe jest zmianę przy użyciu pola wyboru Usuń wiersze, które już nie istnieją w danych wyjściowych zapytania przy ustawieniach ładowania |
Domyślne pełne ładowanie Możliwe skonfigurowanie odświeżania przyrostowego przez skonfigurowanie odświeżania przyrostowego w ustawieniach przepływu danych |
| Zaplanowane odświeżanie | Tak | Tak, możliwość powiadamiania właścicieli przepływu danych o niepowodzeniu |
Scenariusze użycia każdego typu przepływu danych
Poniżej przedstawiono przykładowe scenariusze i zalecenia dotyczące najlepszych rozwiązań dla każdego typu przepływu danych.
Użycie międzyplatformowe — standardowy przepływ danych
Jeśli twoim planem tworzenia przepływów danych jest użycie przechowywanych danych na wielu platformach (nie tylko usługi Power BI, ale także innych usług platformy Microsoft Power Platform, Dynamics 365 itd.), standardowy przepływ danych jest doskonałym wyborem. Standardowe przepływy danych przechowują dane w usłudze Dataverse, do których można uzyskać dostęp za pośrednictwem wielu innych platform i usług.
Duże przekształcenia danych w dużych tabelach danych — analityczny przepływ danych
Analityczne przepływy danych to doskonała opcja przetwarzania dużych ilości danych. Analityczne przepływy danych zwiększają również moc obliczeniową za transformacją. Przechowywanie danych w usłudze Azure Data Lake Storage zwiększa szybkość zapisu w miejscu docelowym. W porównaniu z usługą Dataverse (która może mieć wiele reguł do sprawdzenia w czasie przechowywania danych), usługa Azure Data Lake Storage jest szybsza w przypadku transakcji odczytu/zapisu na dużej ilości danych.
Funkcje sztucznej inteligencji — analityczny przepływ danych
Jeśli planujesz używać dowolnej funkcji sztucznej inteligencji za pośrednictwem etapu przekształcania danych, warto użyć analitycznego przepływu danych, ponieważ możesz użyć wszystkich obsługiwanych funkcji sztucznej inteligencji z tego typu przepływem danych.