Zagadnienia dotyczące mapowania pól dla standardowych przepływów danych
Podczas ładowania danych do tabel usługi Dataverse można mapować kolumny zapytania źródłowego w środowisku edycji przepływu danych na docelowe kolumny tabeli Dataverse. Poza mapowaniem danych należy wziąć pod uwagę inne zagadnienia i najlepsze rozwiązania. W tym artykule omówiono różne ustawienia przepływu danych, które kontrolują zachowanie odświeżania przepływu danych i w związku z tym dane w tabeli docelowej.
Kontrolowanie, czy przepływy danych tworzą, czy upsert rejestrują każde odświeżanie
Za każdym razem, gdy odświeżysz przepływ danych, pobiera rekordy ze źródła i ładuje je do usługi Dataverse. Jeśli przepływ danych jest uruchamiany więcej niż raz — w zależności od sposobu konfigurowania przepływu danych — możesz:
- Utwórz nowe rekordy dla każdego odświeżania przepływu danych, nawet jeśli takie rekordy już istnieją w tabeli docelowej.
- Utwórz nowe rekordy, jeśli jeszcze nie istnieją w tabeli, lub zaktualizuj istniejące rekordy, jeśli już istnieją w tabeli. To zachowanie jest nazywane upsert.
Użycie kolumny klucza wskazuje przepływ danych na rekordy upsert do tabeli docelowej, nie wybierając klucza wskazującego przepływ danych w celu utworzenia nowych rekordów w tabeli docelowej.
Kolumna klucza to kolumna unikatowa i deterministyczna wiersza danych w tabeli. Na przykład w tabeli Orders (Zamówienia), jeśli identyfikator zamówienia jest kolumną klucza, nie powinno być dwóch wierszy z tym samym identyfikatorem zamówienia. Ponadto jeden identyfikator zamówienia — załóżmy, że zamówienie o identyfikatorze 345 — powinno reprezentować tylko jeden wiersz w tabeli. Aby wybrać kolumnę klucza dla tabeli w usłudze Dataverse z przepływu danych, należy ustawić pole klucza w środowisku Tabele mapy.
Wybieranie nazwy podstawowej i pola klucza podczas tworzenia nowej tabeli
Na poniższej ilustracji przedstawiono sposób wybierania kolumny klucza do wypełnienia ze źródła podczas tworzenia nowej tabeli w przepływie danych.
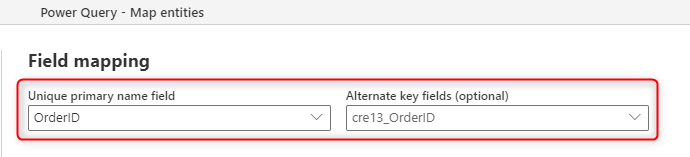
Pole nazwy podstawowej widoczne w mapowaniu pól dotyczy pola etykiety; to pole nie musi być unikatowe. Pole używane w tabeli do sprawdzania duplikacji to pole ustawione w polu Klucz alternatywny.
Posiadanie klucza podstawowego w tabeli gwarantuje, że nawet jeśli masz zduplikowane dane w polu zamapowanym na klucz podstawowy, zduplikowane wpisy nie zostaną załadowane do tabeli. To zachowanie zapewnia wysoką jakość danych w tabeli. Wysokiej jakości dane są niezbędne w tworzeniu rozwiązań do raportowania na podstawie tabeli.
Pole nazwy podstawowej
Pole nazwy podstawowej jest polem wyświetlania używanym w usłudze Dataverse. To pole jest używane w widokach domyślnych do wyświetlania zawartości tabeli w innych aplikacjach. To pole nie jest polem klucza podstawowego i nie powinno być traktowane jako to. To pole może mieć zduplikowane wartości, ponieważ jest to pole wyświetlane. Najlepszym rozwiązaniem jest jednak użycie pola łączonego do mapowania na pole nazwy podstawowej, więc nazwa jest w pełni objaśniona.
Pole klucza alternatywnego jest używane jako klucz podstawowy.
Wybieranie pola klucza podczas ładowania do istniejącej tabeli
Podczas mapowania zapytania przepływu danych na istniejącą tabelę Dataverse możesz wybrać, czy i który klucz ma być używany podczas ładowania danych do tabeli docelowej.
Na poniższej ilustracji przedstawiono sposób wybierania kolumny klucza, która ma być używana podczas upserting rekordów do istniejącej tabeli Dataverse:

Ustawianie kolumny Unikatowy identyfikator tabeli i używanie jej jako pola klucza na potrzeby rozbudowy rekordów w istniejących tabelach usługi Dataverse
Wszystkie wiersze tabeli Microsoft Dataverse mają unikatowe identyfikatory zdefiniowane jako identyfikatory GUID. Te identyfikatory GUID są kluczem podstawowym dla każdej tabeli. Domyślnie klucz podstawowy tabeli nie może być ustawiany przez przepływy danych i jest automatycznie generowany przez usługę Dataverse podczas tworzenia rekordu. Istnieją zaawansowane przypadki użycia, w których wykorzystanie klucza podstawowego tabeli jest pożądane, na przykład integrowanie danych ze źródłami zewnętrznymi przy zachowaniu tych samych wartości klucza podstawowego zarówno w tabeli zewnętrznej, jak i w tabeli Dataverse.
Uwaga
- Ta funkcja jest dostępna tylko podczas ładowania danych do istniejących tabel.
- Pole unikatowego identyfikatora akceptuje tylko ciąg zawierający wartości identyfikatora GUID, dowolny inny typ danych lub wartość powoduje niepowodzenie tworzenia rekordu.
Aby skorzystać z unikatowego pola identyfikatora tabeli, wybierz pozycję Załaduj do istniejącej tabeli na stronie Tabele mapy podczas tworzenia przepływu danych. W przykładzie pokazanym na kolejnym obrazie dane są ładowane do tabeli CustomerTransactions i używa kolumny TransactionID ze źródła danych jako unikatowego identyfikatora tabeli.
Zwróć uwagę, że na liście rozwijanej Wybierz klucz można wybrać unikatowy identyfikator , który zawsze nosi nazwę "nazwa tabeli + identyfikator". Ponieważ nazwa tabeli to "CustomerTransactions", unikatowe pole identyfikatora nosi nazwę "CustomerTransactionId".

Po wybraniu sekcji mapowania kolumn zostanie zaktualizowana tak, aby zawierała unikatowy identyfikator jako kolumnę docelową. Następnie możesz mapować kolumnę źródłową reprezentującą unikatowy identyfikator dla każdego rekordu.

Co to są dobrzy kandydaci do pola kluczowego
Pole klucza jest unikatową wartością reprezentującą unikatowy wiersz w tabeli. Ważne jest, aby mieć to pole, ponieważ pomaga uniknąć zduplikowanych rekordów w tabeli. To pole może pochodzić z trzech źródeł:
Klucz podstawowy w systemie źródłowym (taki jak OrderID w poprzednim przykładzie). łączenie pola utworzonego za pomocą przekształceń dodatku Power Query w przepływie danych.
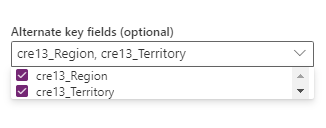
Kombinacja pól do wybrania w opcji Klucz alternatywny. Kombinacja pól używanych jako pole klucza jest również nazywana kluczem złożonym.
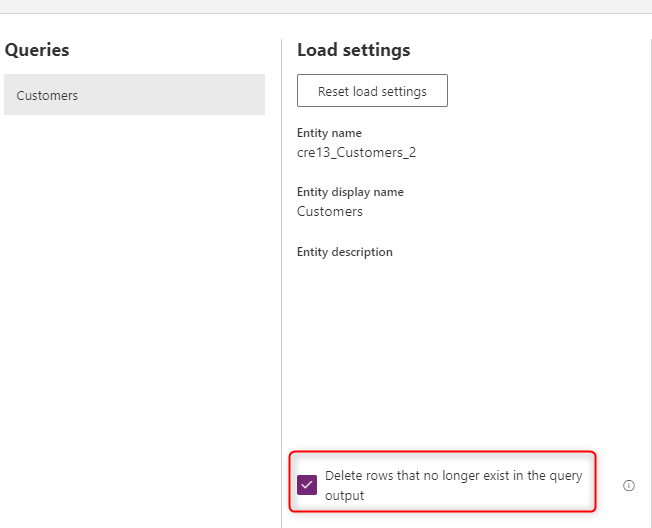
Usuwanie wierszy, które już nie istnieją
Jeśli chcesz mieć dane w tabeli zawsze synchronizowane z danymi z systemu źródłowego, wybierz opcję Usuń wiersze, które już nie istnieją w danych wyjściowych zapytania. Jednak ta opcja spowalnia przepływ danych, ponieważ istnieje potrzeba porównania wierszy na podstawie klucza podstawowego (alternatywnego klucza w mapowaniu pola przepływu danych) dla tej akcji.
Opcja oznacza, że jeśli w tabeli znajduje się wiersz danych, który nie istnieje w danych wyjściowych zapytania następnego odświeżania przepływu danych, ten wiersz zostanie usunięty z tabeli.
Uwaga
Standardowe przepływy danych w wersji 2 opierają się na createdon polach i modifiedon , aby usunąć wiersze, które nie istnieją w danych wyjściowych przepływów danych, z tabeli docelowej. Jeśli te kolumny nie istnieją w tabeli docelowej, rekordy nie zostaną usunięte.
Znane ograniczenia
- Mapowanie na pola odnośników polimorficznych nie jest obecnie obsługiwane.
- Mapowanie na pole odnośnika wielo poziomowego, odnośnik wskazujący pole odnośnika innej tabeli, nie jest obecnie obsługiwane.
- Mapowanie na pola Stan i Przyczyna stanu nie jest obecnie obsługiwane.
- Mapowanie danych na tekst wielowierszowy zawierający znaki podziału wiersza nie jest obsługiwane, a podziały wierszy zostaną usunięte. Zamiast tego można użyć tagu
<br>podziału wiersza, aby załadować i zachować tekst wielowierszowy. - Mapowanie na pola wyboru skonfigurowane z włączoną opcją wyboru wielokrotnego jest obsługiwane tylko w określonych warunkach. Przepływ danych ładuje tylko dane do pól Wybór z włączoną opcją wyboru wielokrotnego, a jest używana lista wartości rozdzielonych przecinkami (liczb całkowitych) etykiet. Jeśli na przykład etykiety to "Choice1, Choice2, Choice3" z odpowiednimi wartościami całkowitymi "1, 2, 3", wartości kolumn powinny mieć wartość "1,3", aby wybrać pierwszą i ostatnią opcję.
- Standardowe przepływy danych w wersji 2 opierają się na
createdonpolach imodifiedon, aby usunąć wiersze, które nie istnieją w danych wyjściowych przepływów danych, z tabeli docelowej. Jeśli te kolumny nie istnieją w tabeli docelowej, rekordy nie zostaną usunięte. - Mapowanie na pola, których właściwość IsValidForCreate jest ustawiona na
falsejest nieobsługiwana (na przykład pole Konto jednostki Kontakt).