Przewodnik konfigurowania wdrażania
Aplikacja ALM Accelerator for Power Platform używa plików konfiguracji w formacie JSON do automatyzowania wdrażania rozwiązań. Ustawiają one odwołania do połączeń, zmienne środowiskowe i uprawnienia, udostępniają aplikacje kanwy i aktualizują własność składników rozwiązania, takich jak przepływy Power Automate, gdy rozwiązania są wdrażane w środowiskach podrzędnych.
Pliki konfiguracji określone w tym artykule umożliwiają skonfigurowanie elementów specyficznych dla środowiska, w którym wdrażane jest rozwiązanie. Potrzebne pliki konfiguracji, a więc czynności, które należy wykonać w tym artykule, zależą od składników wdrożonych przez potoki rozwiązania. Na przykład jeśli rozwiązanie zawiera tylko tabele Dataverse i aplikacje oparte na modelach, a konfiguracja ani dane na środowisko nie są wymagane, można pominąć niektóre z tych kroków.
Przykładowe pliki konfiguracji zostały określone w ustawieniach wdrożenia i niestandardowych ustawieniach wdrożenia dla rozwiązania ALMAcceleratorSampleSolution.
Przed rozpoczęciem
Ten artykuł zawiera przewodnik krok po kroku dotyczący ręcznego konfigurowania plików konfiguracji wdrożenia. Zawiera on szczegółowe informacje i kontekst dla akcji wykonywanych przez potoki i aplikację ALM Accelerator jako dokumentację dla administratorów, którzy chcą poznać szczegóły poszczególnych kroków procesu.
Zalecamy jednak skonfigurowanie ustawień wdrażania w aplikacji ALM Accelerator.
Utwórz plik JSON ustawień wdrażania
Jeśli plik customDeploymentSettings.json jest przechowywany w katalogu głównym katalogu config, ta sama konfiguracja dotyczy wszystkich środowisk. Jeśli korzystasz z przekształcenia pliku lub zadań potoków zastępczych tokenów w celu określenia informacji dotyczących określonych środowisk, możesz określić wartości dla poszczególnych środowisk w zmiennych potoku.
Można jednak utworzyć specyficzne dla środowiska pliki customDeploymentSettings.json. Przechowuj je w podkatalogach katalogu config nazwanego dla środowisk użytkownika. Nazwa katalogu musi być odpowiadać zmiennej EnvironmentName utworzonej podczas tworzenia potoku dla środowisk sprawdzania poprawności, testowania i środowiska produkcyjnego. Jeśli nie istnieją żadne ustawienia wdrożenia specyficzne dla środowiska JSON i katalog, potoki powrócą do konfiguracji w katalogu głównym katalogu config.
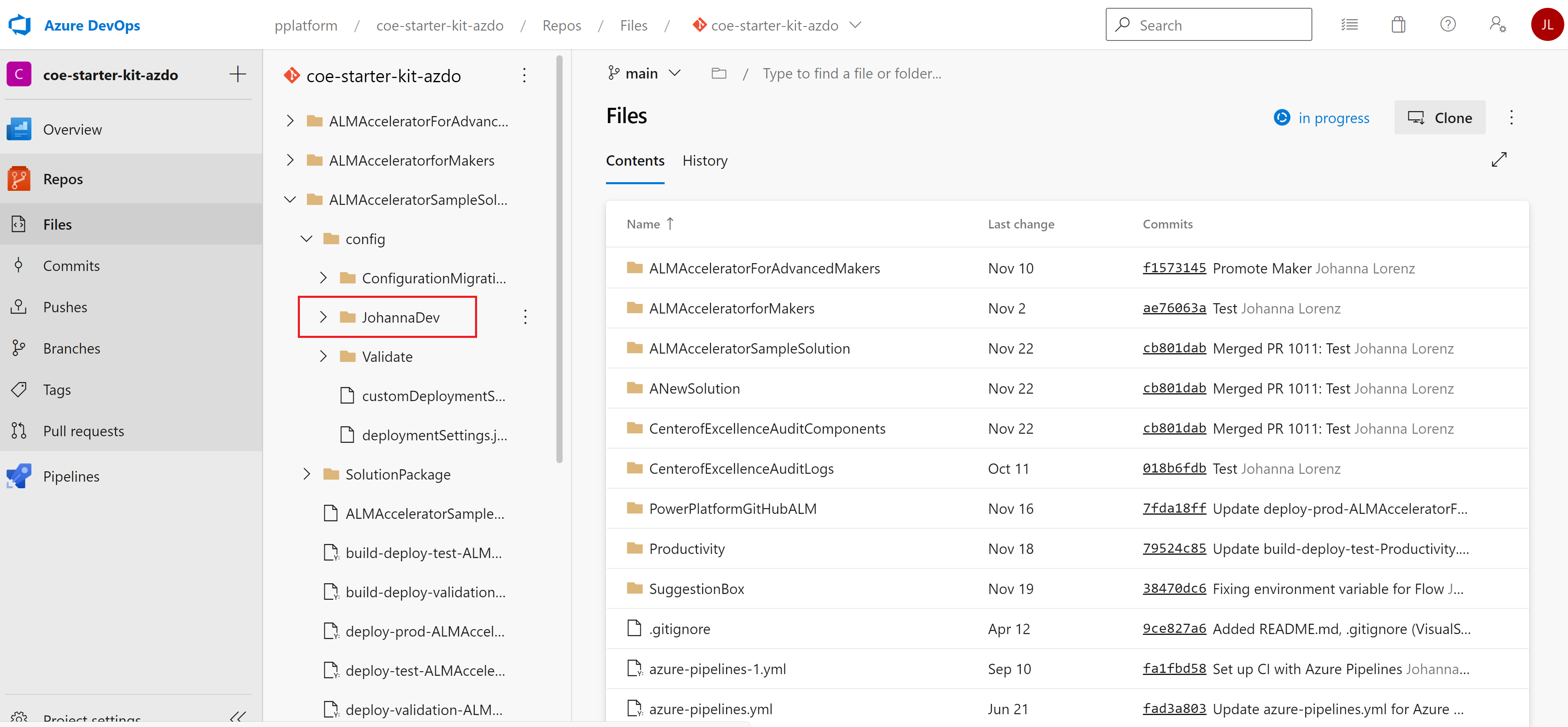
Można także utworzyć pliki konfiguracji specyficzne dla użytkownika, takie jak katalog JohannaDev na powyższej ilustracji. Deweloperzy mogą używać ich do wybrania określonej konfiguracji, gdy importują rozwiązania niezarządzane z kontroli źródła.
Plik JSON z ustawieniami wdrażania konfiguruje odwołania do połączeń i zmienne środowiskowe.
{
"EnvironmentVariables": [
{
"SchemaName": "cat_shared_sharepointonline_97456712308a4e65aae18bafcd84c81f",
"Value": "#{environmentvariable.cat_shared_sharepointonline_97456712308a4e65aae18bafcd84c81f}#"
},
{
"SchemaName": "cat_shared_sharepointonline_21f63b2d26f043fb85a5c32fc0c65924",
"Value": "#{environmentvariable.cat_shared_sharepointonline_21f63b2d26f043fb85a5c32fc0c65924}#"
},
{
"SchemaName": "cat_TextEnvironmentVariable",
"Value": "#{environmentvariable.cat_TextEnvironmentVariable}#"
},
{
"SchemaName": "cat_ConnectorBaseUrl",
"Value": "#{environmentvariable.cat_ConnectorBaseUrl}#"
},
{
"SchemaName": "cat_DecimalEnvironmentVariable",
"Value": "#{environmentvariable.cat_DecimalEnvironmentVariable}#"
},
{
"SchemaName": "cat_JsonEnvironmentVariable",
"Value": "#{environmentvariable.cat_JsonEnvironmentVariable}#"
},
{
"SchemaName": "cat_ConnectorHostUrl",
"Value": "#{environmentvariable.cat_ConnectorHostUrl}#"
}
],
"ConnectionReferences": [
{
"LogicalName": "new_sharedsharepointonline_b49bb",
"ConnectionId": "#{connectionreference.new_sharedsharepointonline_b49bb}#",
"ConnectorId": "/providers/Microsoft.PowerApps/apis/shared_sharepointonline"
},
{
"LogicalName": "cat_CDS_Current",
"ConnectionId": "#{connectionreference.cat_CDS_Current}#",
"ConnectorId": "/providers/Microsoft.PowerApps/apis/shared_commondataserviceforapps"
}
]
}
Skopiuj powyższy przykładowy kod JSON do nowego pliku o nazwie deploymentSettings.json.
Zapisz plik w folderze config w usłudze Git.
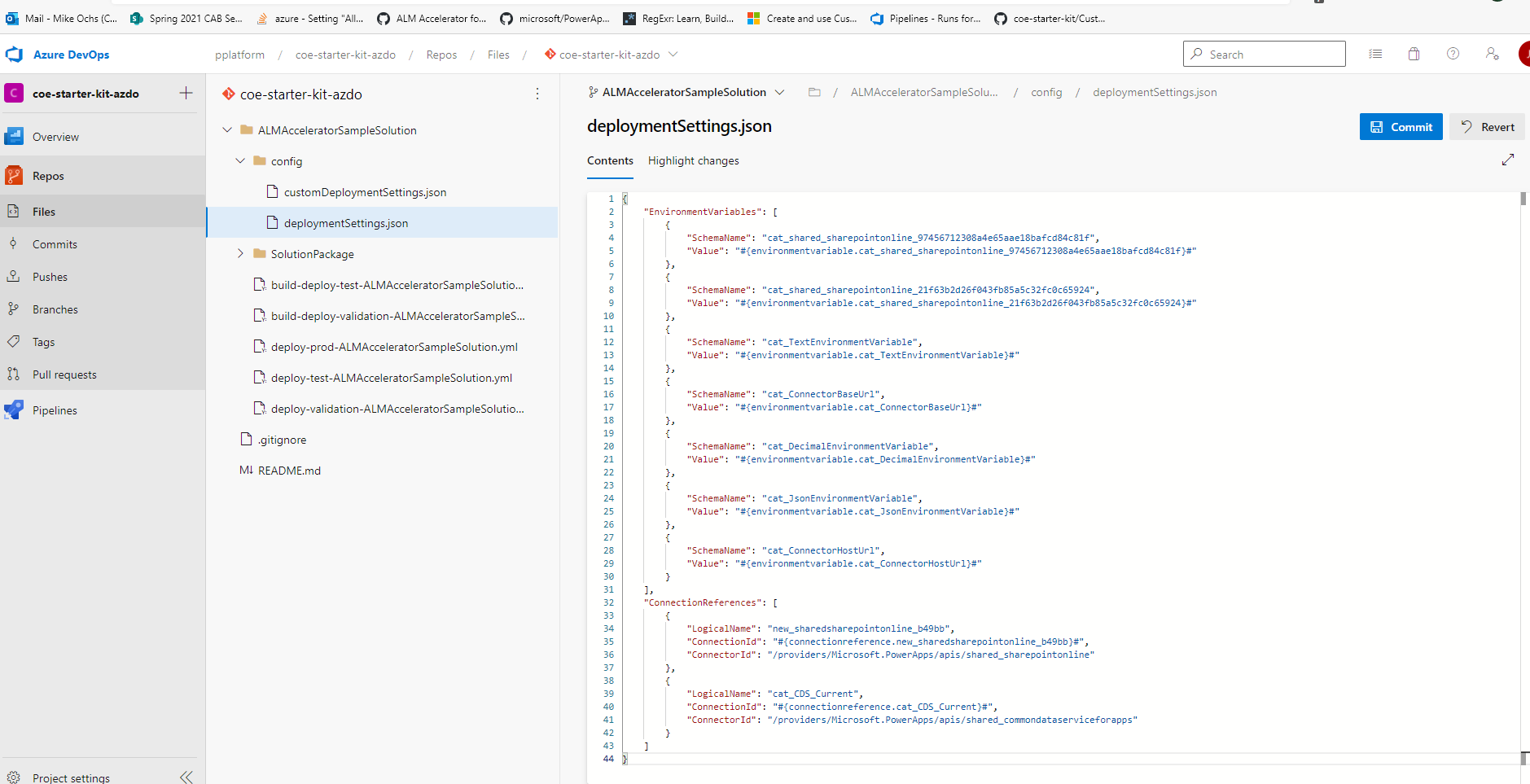
Tworzenie odwołania do połączenia JSON
Właściwość ConnectionReferences w pliku customDeploymentConfiguration.json ustawia odwołania do połączeń w rozwiązaniu po zaimportowaniu rozwiązania do środowiska.
ConnectionReferences Włącz również przepływy po zaimportowaniu rozwiązania na podstawie właściciela połączenia określonego w zmiennej.
Ręczne tworzenie połączeń w środowiskach docelowych.
Skopiuj identyfikatory połączeń.
Pobierz nazwę logiczną odwołania do połączenia ze składnika odwołania do połączenia w rozwiązaniu.
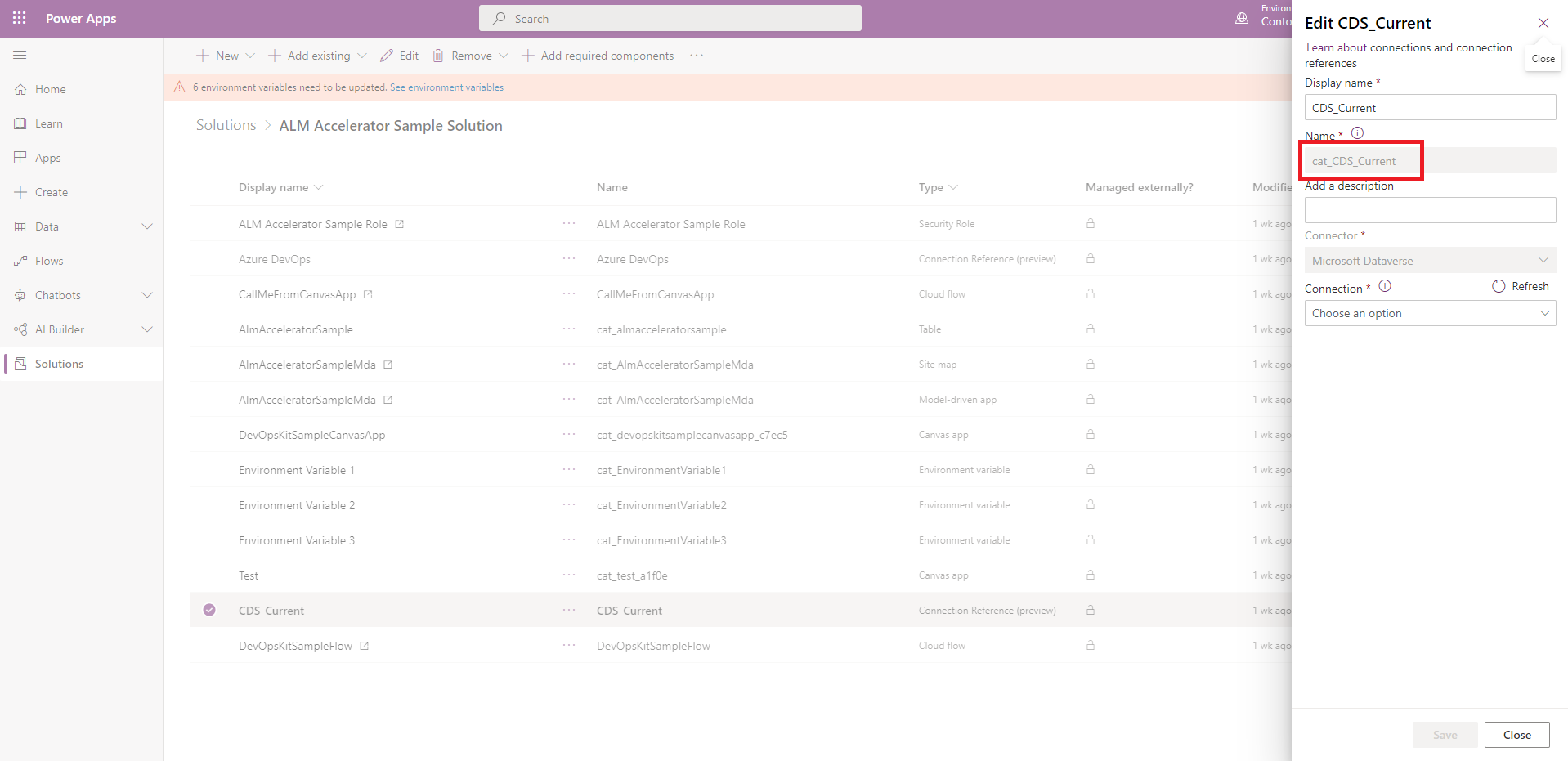
Po utworzeniu połączenia pobierz identyfikator połączenia z adresu URL połączenia. Jeśli na przykład adres URL to „https://.../connections/shared_commondataservice/9f66d1d455f3474ebf24e4fa2c04cea2/details”, identyfikator połączenia to f66d1d455f3474ebf24e4fa2c04cea2.
Edytuj plik customDeploymentSettings.json i wklej identyfikatory we właściwości
ConnectionReferences, tak jak w poniższym przykładowym kodzie:"ConnectionReferences": [ { "LogicalName": "new_sharedsharepointonline_b49bb", "ConnectionId": "#{connectionreference.new_sharedsharepointonline_b49bb}#", "ConnectorId": "/providers/Microsoft.PowerApps/apis/shared_sharepointonline" }, { "LogicalName": "cat_CDS_Current", "ConnectionId": "#{connectionreference.cat_CDS_Current}#", "ConnectorId": "/providers/Microsoft.PowerApps/apis/shared_commondataserviceforapps" } ]Jeśli używasz rozszerzenia Zamień tokeny i dodasz tokeny w konfiguracji, tak jak w poprzednim przykładzie, otwórz potok dla rozwiązania, a następnie wybierz opcję Edytuj>Zmienne.
Na ekranie Zmienne potoku utwórz połączenie <connection_reference_logicalname>. W tym przykładzie zmienna potoku ma nazwę
connection.cat_CDS_Current.Ustaw wartość identyfikatora połączenia, który został wcześniej znaleziony.
Aby upewnić się, że wartość nie jest zapisywana jako zwykły tekst, zaznacz opcję Zachowaj tę wartość jako wpis tajny.
Jeśli ma to zastosowanie, powtórz powyższe kroki dla każdego utworzyć rozwiązania i potoku.
Tworzenie kodu JSON zmiennej środowiskowej w pliku konfiguracji wdrożenia
Właściwość EnvironmentVariables w pliku customDeploymentConfiguration.json ustawia zmiennej środowiskowe Dataverse w rozwiązaniu po zaimportowaniu rozwiązania do środowiska.
Ważne
Gdy są eksportowane rozwiązania kontrolowane przez źródło, wraz z rozwiązaniem są eksportowane zmienne środowiskowe. Może to stanowić zagrożenie dla bezpieczeństwa, jeśli zmienne środowiskowe zawierają informacje poufne. Zaleca się, aby nie przechowywać informacji poufnych w zmiennych środowiskowych. Jednym ze sposobów, aby upewnić się, że wartości zmiennych w środowisku nie są kontrolowane przez źródło, jest utworzenie rozwiązania przeznaczonego specjalnie dla wartości zmiennych środowiskowych w środowiskach projektowych i ustawienie ich wartości w tym rozwiązaniu. Uniemożliwia to wyeksportowanie wartości wraz z rozwiązaniem i ich przechowywanie w ramach kontroli źródła.
Skopiuj nazwę schematu dla zmiennej środowiskowej ze składnika zmiennej środowiska w rozwiązaniu.
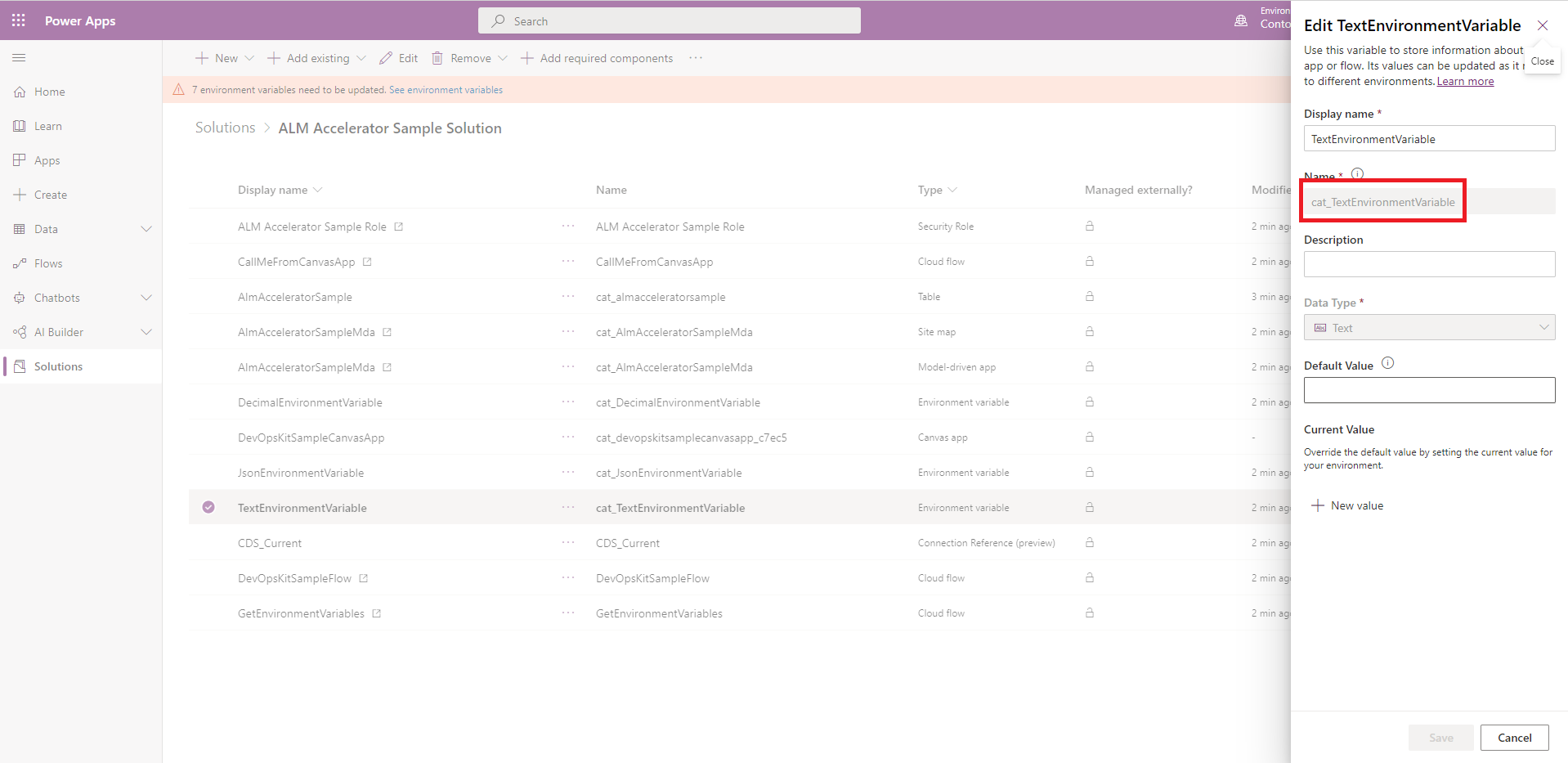
Edytuj plik customDeploymentSettings.json i wklej nazwę we właściwości
EnvironmentVariables, tak jak w poniższym przykładowym kodzie:{ "EnvironmentVariables": [ { "SchemaName": "cat_TextEnvironmentVariable", "Value": "#{variable.cat_TextEnvironmentVariable}#" }, { "SchemaName": "cat_DecimalEnvironmentVariable", "Value": "#{variable.cat_DecimalEnvironmentVariable}#" }, { "SchemaName": "cat_JsonEnvironmentVariable", "Value": "{\"name\":\"#{variable.cat_JsonEnvironmentVariable.name}#\"}" } ] }Jeśli używasz rozszerzenia Zamień tokeny i dodasz tokeny w konfiguracji, tak jak w poprzednim przykładzie, otwórz potok dla rozwiązania, a następnie wybierz opcję Edytuj>Zmienne.
Na ekranie Zmienne potoku utwórz zmienną potoku dla każdego tokenu w konfiguracji, na przykład: variable.cat_TextEnvironmentVariable.
Ustaw wartość na wartość zmiennej środowiskowej dla danego środowiska.
Aby upewnić się, że wartość nie jest zapisywana jako zwykły tekst, zaznacz opcję Zachowaj tę wartość jako wpis tajny.
Jeśli ma to zastosowanie, powtórz powyższe kroki dla każdego utworzyć rozwiązania i potoku.
Tworzenie pliku JSON niestandardowych ustawień wdrożenia
Plik JSON niestandardowych ustawień wdrożenia zawiera ustawienia aktywujące przepływy w imieniu użytkownika, określające własność przepływów, udostępniające aplikacje kanwy grupom Microsoft Entra i tworzące zespoły grup Dataverse po wdrożeniu.
{
"ActivateFlowConfiguration": [
{
"solutionComponentName": "DevOpsKitSampleFlow",
"solutionComponentUniqueName": "0a43b549-50ed-ea11-a815-000d3af3a7c4",
"activateAsUser": "#{activateflow.activateas.DevOpsKitSampleFlow}#"
},
{
"solutionComponentName": "CallMeFromCanvasApp",
"solutionComponentUniqueName": "71cc728c-2487-eb11-a812-000d3a8fe6a3",
"activateAsUser": "#{activateflow.activateas.CallMeFromCanvasApp}#"
},
{
"solutionComponentName": "GetEnvironmentVariables",
"solutionComponentUniqueName": "d2f7f0e2-a1a9-eb11-b1ac-000d3a53c3c2",
"activateAsUser": "#{activateflow.activateas.GetEnvironmentVariables}#"
}
],
"SolutionComponentOwnershipConfiguration": [
{
"solutionComponentType": 29,
"solutionComponentName": "DevOpsKitSampleFlow",
"solutionComponentUniqueName": "0a43b549-50ed-ea11-a815-000d3af3a7c4",
"ownerEmail": "#{owner.ownerEmail.DevOpsKitSampleFlow}#"
},
{
"solutionComponentType": 29,
"solutionComponentName": "CallMeFromCanvasApp",
"solutionComponentUniqueName": "71cc728c-2487-eb11-a812-000d3a8fe6a3",
"ownerEmail": "#{owner.ownerEmail.CallMeFromCanvasApp}#"
},
{
"solutionComponentType": 29,
"solutionComponentName": "GetEnvironmentVariables",
"solutionComponentUniqueName": "d2f7f0e2-a1a9-eb11-b1ac-000d3a53c3c2",
"ownerEmail": "#{owner.ownerEmail.GetEnvironmentVariables}#"
}
],
"AadGroupCanvasConfiguration": [
{
"aadGroupId": "#{canvasshare.aadGroupId.DevOpsKitSampleCanvasApp}#",
"canvasNameInSolution": "cat_devopskitsamplecanvasapp_c7ec5",
"canvasDisplayName": "DevOpsKitSampleCanvasApp",
"roleName": "#{canvasshare.roleName.DevOpsKitSampleCanvasApp}#"
}
],
"AadGroupTeamConfiguration": [
{
"aadGroupTeamName": "Sample Group Team Name",
"aadSecurityGroupId": "#{team.samplegroupteamname.aadSecurityGroupId}#",
"dataverseSecurityRoleNames": [
"#{team.samplegroupteamname.role}#"
]
}
]
}
Skopiuj poprzedni przykładowy kod JSON do nowego pliku o nazwie customDeploymentSettings.json.
Zapisz plik w folderze config w usłudze Git.
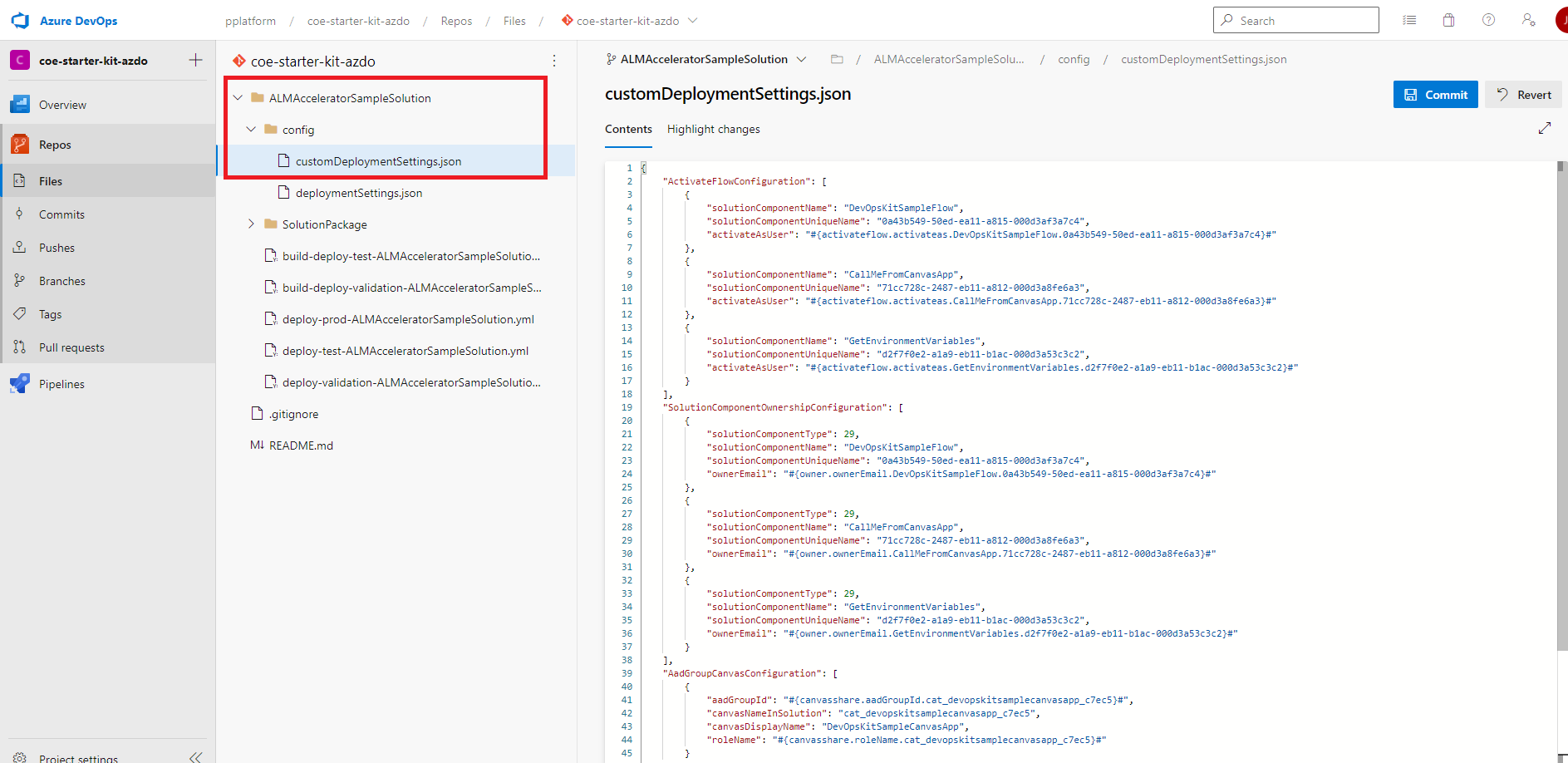
Tworzenie kodu JSON domyślnej zmiennej środowiskowej w pliku niestandardowej konfiguracji wdrożenia
Właściwość DefaultEnvironmentVariables w pliku customDeploymentConfiguration.json jest używana w potoku eksportu w celu ustawienia domyślnych zmiennych środowiska Dataverse w rozwiązaniu podczas eksportowania i przechowywania rozwiązania w kontroli źródła.
Uwaga
Domyślne ustawienia zmiennych środowiskowych mają zastosowanie tylko wtedy, gdy potok eksportu jest skonfigurowany ze zmienną potoku VerifyDefaultEnvironmentVariableValues = True.
Skopiuj nazwę schematu dla zmiennej środowiskowej ze składnika zmiennej środowiska w rozwiązaniu.
Edytuj plik customDeploymentSettings.json i wklej nazwę we właściwości
DefaultEnvironmentVariables, tak jak w poniższym przykładowym kodzie:{ "DefaultEnvironmentVariables": [ [ "cat_TextEnvironmentVariable", "#{defaultvariable.cat_TextEnvironmentVariable}#" ], [ "cat_DecimalEnvironmentVariable", "#{defaultvariable.cat_DecimalEnvironmentVariable}#" ], [ "cat_jsonEnvironmentVariable", "{\"name\":\"#{defaultvariable.cat_jsonEnvironmentVariable.name}#\"}" ] ] }Jeśli używasz rozszerzenia Zamień tokeny i dodasz tokeny w konfiguracji, tak jak w poprzednim przykładzie, otwórz potok dla rozwiązania, a następnie wybierz opcję Edytuj>Zmienne.
Na ekranie Zmienne potoku utwórz zmienną potoku dla każdego tokenu w konfiguracji, na przykład: defaultvariable.cat_TextEnvironmentVariable.
Jeśli ma to zastosowanie, powtórz powyższe kroki dla każdego utworzyć rozwiązania i potoku.
Tworzenie kodu JSON konfiguracji kanwy grupy Microsoft Entra
Właściwość AadGroupCanvasConfiguration w pliku customDeploymentConfiguration.json udostępnia aplikacje kanwy w rozwiązaniu określonym grupom Microsoft Entra po zaimportowaniu rozwiązania do środowiska.
Skopiuj identyfikatory dla aplikacji kanwy i grupy usługi Microsoft Entra.
Pobierz nazwę schematu dla aplikacji kanwy ze składnika aplikacji kanwy w rozwiązaniu.
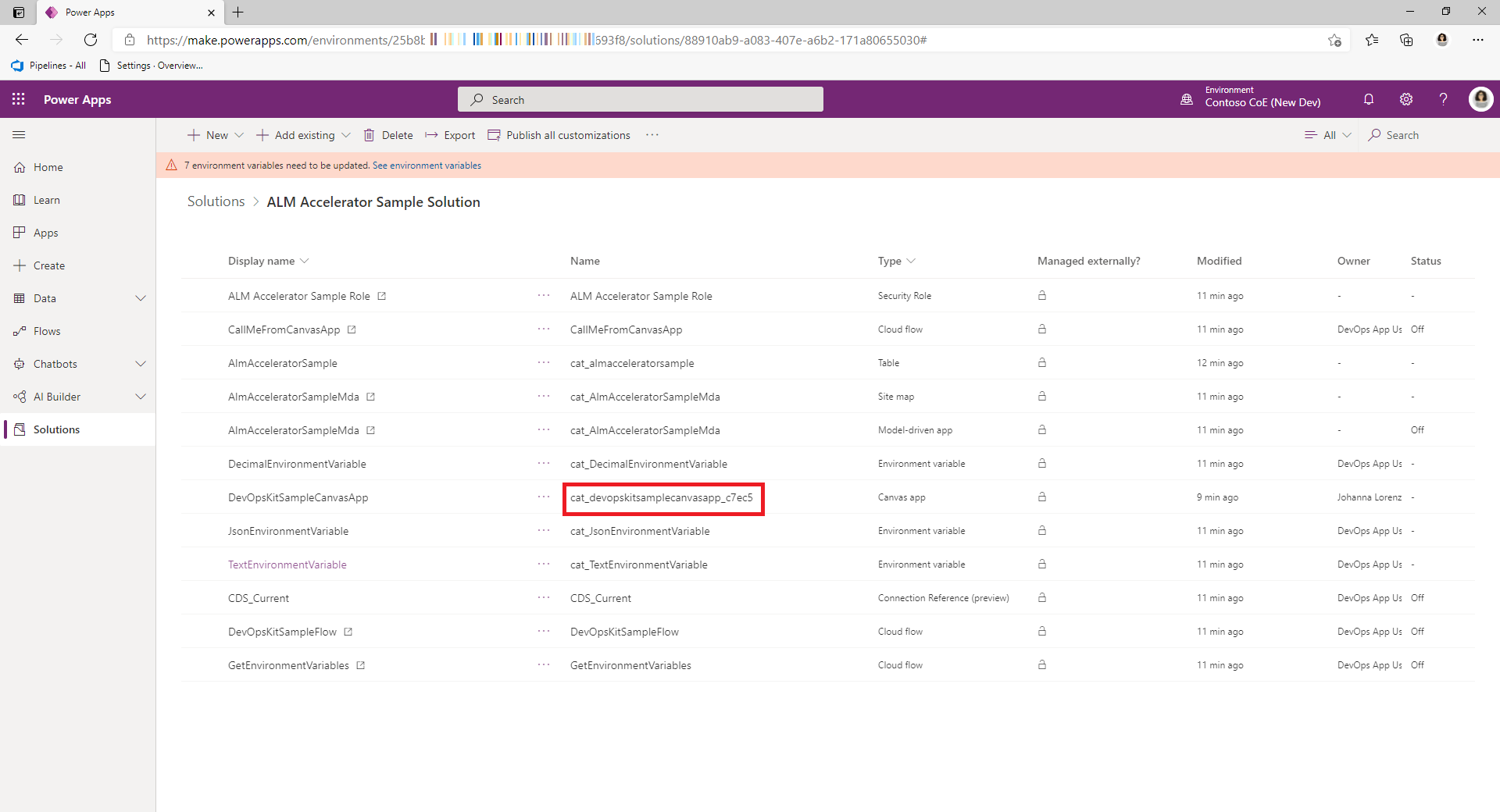
Pobierz identyfikator grupy Microsoft Entra ze strony Grupa w witrynie Azure Portal.
Edytuj plik customDeploymentSettings.json i wklej identyfikatory we właściwości
AadGroupCanvasConfiguration, tak jak w poniższym przykładowym kodzie:{ "AadGroupCanvasConfiguration": [ { "aadGroupId": "#{canvasshare.aadGroupId}#", "canvasNameInSolution": "cat_devopskitsamplecanvasapp_c7ec5", "roleName": "#{canvasshare.roleName}#" } ] }Nazwa
roleNamemoże mieć wartośćCanView,CanViewWithShareiCanEdit.Jeśli używasz rozszerzenia Zamień tokeny i dodasz tokeny w konfiguracji, tak jak w poprzednim przykładzie, otwórz potok dla rozwiązania, a następnie wybierz opcję Edytuj>Zmienne.
Na ekranie Zmienne potoku utwórz zmienną potoku dla każdego tokenu w konfiguracji, na przykład:
canvasshare.aadGroupId.Ustaw wartość identyfikatora grupy Microsoft Entra, dla którego aplikacja musi być udostępniona dla tego określonego środowiska.
Aby upewnić się, że wartość nie jest zapisywana jako zwykły tekst, zaznacz opcję Zachowaj tę wartość jako wpis tajny.
Jeśli ma to zastosowanie, powtórz powyższe kroki dla każdego utworzyć rozwiązania i potoku.
Utwórz grupę i konfigurację zespołu Microsoft Entra w formacie JSON
Właściwość AadGroupTeamConfiguration w pliku customDeploymentConfiguration.json mapuje zespoły i role Dataverse na grupy Microsoft Entra w rozwiązaniu po zaimportowaniu rozwiązania do środowiska.
Role zabezpieczeń należy dodać do rozwiązania, jeśli nie są one tworzone ręcznie w środowisku docelowym. Do zespołu można zastosować jedną lub więcej ról. Role te zapewniają uprawnienia do składników rozwiązania wymaganych przez użytkowników w grupie.
Nazwa zespołu Dataverse może być nazwą istniejącego zespołu lub nowego zespołu, który ma zostać utworzony w Dataverse i zmapowany na grupę Microsoft Entra po zaimportowaniu rozwiązania.
Role Dataverse mogą być dowolną rolą zabezpieczeń w Dataverse, która zostanie zastosowana do zespołu po zaimportowaniu rozwiązania. Role muszą mieć uprawnienia do zasobów, których wymaga rozwiązanie, takich jak tabele i procesy.
Pobierz identyfikator grupy Microsoft Entra ze strony Grupa w witrynie Azure Portal, jak opisano w poprzedniej sekcji.
Edytuj plik customDeploymentSettings.json i wklej kod JSON we właściwości
AadGroupTeamConfiguration, tak jak w poniższym przykładowym kodzie:{ "AadGroupTeamConfiguration": [ { "aadGroupTeamName": "alm-accelerator-sample-solution", "aadSecurityGroupId": "#{team.aadSecurityGroupId}#", "dataverseSecurityRoleNames": [ "ALM Accelerator Sample Role" ] } ] }Jeśli używasz rozszerzenia Zamień tokeny i dodasz tokeny w konfiguracji, tak jak w poprzednim przykładzie, otwórz potok dla rozwiązania, a następnie wybierz opcję Edytuj>Zmienne.
Na ekranie Zmienne potoku utwórz zmienną potoku dla każdego tokenu w konfiguracji, na przykład:
team.aadSecurityGroupId.Ustaw wartość identyfikatora grupy Microsoft Entra do skojarzenia z zespołem w usłudze Dataverse.
Aby upewnić się, że wartość nie jest zapisywana jako zwykły tekst, zaznacz opcję Zachowaj tę wartość jako wpis tajny.
Jeśli ma to zastosowanie, powtórz powyższe kroki dla każdego utworzyć rozwiązania i potoku.
Utwórz własność komponentu rozwiązania JSON
Właściwość SolutionComponentOwnershipConfiguration w pliku customDeploymentConfiguration.json przypisuje własność składników rozwiązania do użytkowników Dataverse po zaimportowaniu rozwiązania do środowiska. Przypisywanie własności jest przydatne w przypadku składników, takich jak przepływy, które domyślnie są własnością głównego użytkownika usługi po zaimportowaniu rozwiązania przez potok, a organizacje chcą zmienić ich przypisanie po zaimportowaniu.
Właściwość SolutionComponentOwnershipConfiguration włącza również przepływy, które nie mają żadnych odwołań do połączeń. Przepływ jest włączony przez określonego użytkownika, gdy nie istnieją odwołania do połączenia, aby włączyć przepływ.
Uwaga
Bieżąca potok umożliwia jedynie ustawienie własności przepływów.
Kod typu składnika rozwiązania jest oparty na typach składników określonych w odniesieniu do interfejsu API solutioncomponent EntityType sieci Web. Na przykład przepływ Power Automate to typ składnika 29. Typ składnika powinien być określony jako wartość całkowita bez cudzysłowu.
Pobierz unikatową nazwę składnika przepływu Power Automate z rozwiązania niezapakowanego.
Przepływy nie wymagają unikatowych nazw po utworzeniu. Jedynym unikatowym identyfikatorem przepływu jest wewnętrzny identyfikator, który przypisuje w rozwiązaniu.
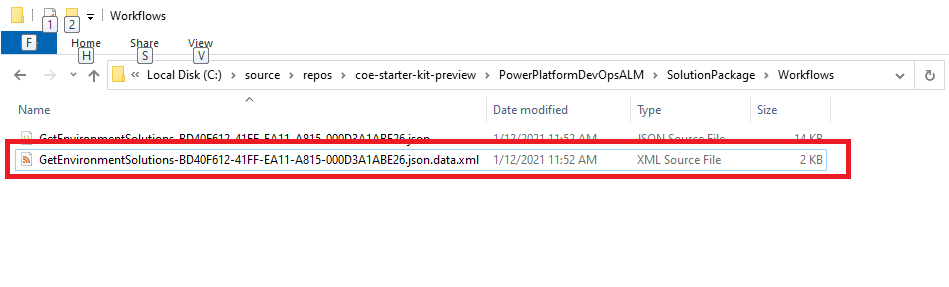
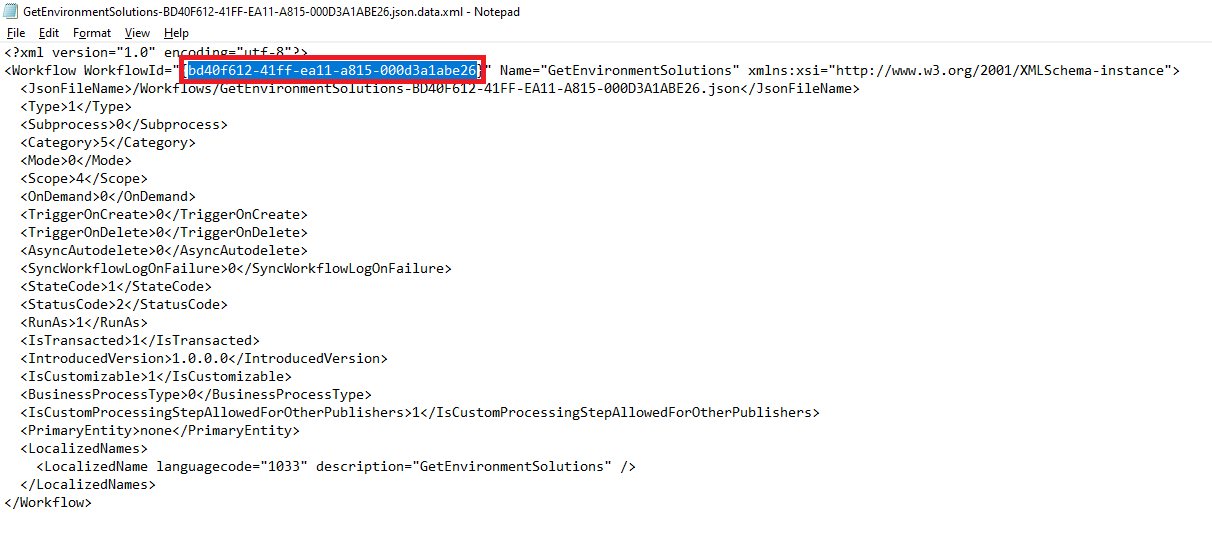
Pobierz adres e-mail właściciela z rekordu użytkownika w Dataverse lub Microsoft 365.
Edytuj plik customDeploymentSettings.json i wklej kod JSON we właściwości
AadGroupTeamConfiguration, tak jak w poniższym przykładowym kodzie:{ "SolutionComponentOwnershipConfiguration": [ { "solutionComponentType": 29, "solutionComponentUniqueName": "00000000-0000-0000-0000-00000000000", "ownerEmail": "#{owner.ownerEmail}#" }, { "solutionComponentType": 29, "solutionComponentUniqueName": "00000000-0000-0000-0000-00000000000", "ownerEmail": "#{owner.ownerEmail}#" } ] }Jeśli używasz rozszerzenia Zamień tokeny i dodasz tokeny w konfiguracji, tak jak w poprzednim przykładzie, otwórz potok dla rozwiązania, a następnie wybierz opcję Edytuj>Zmienne.
Na ekranie Zmienne potoku utwórz zmienną potoku dla każdego tokenu w konfiguracji, na przykład:
owner.ownerEmail.Ustaw wartość na adres e-mail właściciela składnika.
Aby upewnić się, że wartość nie jest zapisywana jako zwykły tekst, zaznacz opcję Zachowaj tę wartość jako wpis tajny.
Jeśli ma to zastosowanie, powtórz powyższe kroki dla każdego utworzyć rozwiązania i potoku.
Importowanie danych z potoku
Po wdrożeniu rozwiązania w środowisku docelowym można zaimportować dane konfiguracji lub źródłowe do środowiska Dataverse. Potoki są skonfigurowane do importowania danych przy użyciu narzędzia do konfiguracji migracji, dostępnego za pośrednictwem NuGet. Dowiedz się więcej o zarządzaniu danymi konfiguracji.
Jeśli dane konfiguracji są przechowywane w katalogu głównym katalogu config, te same dane konfiguracji są wdrażane do wszystkich środowisk. Użytkownik może tworzyć pliki danych konfiguracji dla określonego środowiska. Przechowuj je w podkatalogach katalogu config nazwanego dla środowisk użytkownika. Nazwa katalogu musi być odpowiadać zmiennej EnvironmentName utworzonej podczas tworzenia potoku dla środowisk sprawdzania poprawności, testowania i środowiska produkcyjnego. Jeśli nie istnieje katalog i dane konfiguracji specyficzne dla środowiska, potoki powrócą do danych konfiguracji w katalogu głównym katalogu config.
Sklonuj repozytorium Azure DevOps, w którym rozwiązanie ma być kontrolowane przez źródło i w którym utworzono potok rozwiązania YAML na maszynie lokalnej.
Jeśli jeszcze tego nie zrobiono, utwórz katalog o nazwie config w folderze config w folderze rozwiązań.

Zainstaluj narzędzie do migracji konfiguracji. Postępuj zgodnie z instrukcjami z tematu Pobieranie narzędzi z NuGet.
Otwórz narzędzie Konfiguracja migracji, wybierz opcję Utwórz schemat, a następnie wybierz opcję Kontynuuj.
Zaloguj się do dzierżawcy, z której chcesz wyeksportować dane konfiguracji.
Wybierz środowisko.
Wybierz tabele i kolumny do wyeksportowania.
Wybierz pozycję Zapisz i eksportuj. Zapisz dane w ścieżce katalogu config\ConfigurationMigrationData w lokalnym repozytorium Azure DevOps, w folderze rozwiązania, dla którego mają zostać zaimportowane dane.
Uwaga
Potok wyszukuje ten konkretny folder do zaimportowania danych po zaimportowaniu rozwiązania. Należy się upewnić, że nazwa folderu i jego lokalizacja są dokładnie takie, jak w tym miejscu.
Po wyświetleniu monitu o wyeksportowanie danych wybierz opcję Tak.
Wybierz tę samą lokalizację dla wyeksportowanych danych, wybierz pozycję Zapisz, a następnie wybierz opcję Eksportuj dane.
Po zakończeniu eksportowania należy rozpakować pliki z pliku data.zip do katalogu ConfigurationMigrationData. Usuń pliki data.zip i SampleData.xml.
Zatwierdź zmiany swoimi danymi w Azure DevOps.