Semantyczny model usługi Power BI — skalowanie w poziomie
Semantyczny model skalowalny w poziomie pomaga usłudze Power BI zapewnić szybką wydajność, podczas gdy raporty i pulpity nawigacyjne są używane przez dużą grupę odbiorców. Skalowanie modelu semantycznego w poziomie używa pojemności Premium do hostowania co najmniej jednej repliki tylko do odczytu podstawowego modelu semantycznego. Zwiększając przepływność, repliki tylko do odczytu zapewniają, że wydajność nie spowalnia, gdy wielu użytkowników przesyła zapytania w tym samym czasie.
Gdy usługa Power BI tworzy repliki tylko do odczytu, oddziela je od podstawowego modelu semantycznego odczytu i zapisu. Repliki tylko do odczytu obsługują zapytania raportów i pulpitów nawigacyjnych usługi Power BI, a model semantyczny odczytu i zapisu jest używany podczas wykonywania operacji zapisu i odświeżania. Podczas operacji zapisu i odświeżania repliki tylko do odczytu nadal obsługują raporty i zapytania pulpitu nawigacyjnego bez zakłócania działania. Domyślnie modele semantyczne tylko do odczytu i odczytu są automatycznie synchronizowane, aby repliki tylko do odczytu były aktualne. Można jednak wyłączyć automatyczną synchronizację i wybrać synchronizację ręcznie w wierszu polecenia lub za pomocą skryptu.
W poniższej tabeli przedstawiono wymaganą synchronizację dla każdej metody odświeżania po włączeniu skalowania modelu semantycznego usługi Power BI w poziomie, a automatyczna synchronizacja jest wyłączona:
| Refresh, metoda | Synchronizuj |
|---|---|
| OnDemand UI | Zawsze synchronizuje |
| Zaplanowane odświeżanie | Zawsze synchronizuje |
| Podstawowy interfejs API REST | Wymagana ręczna synchronizacja 1 |
| Zaawansowany interfejs API REST | Wymagana ręczna synchronizacja 1 |
| XMLA | Wymagana ręczna synchronizacja 1 |
1 — z autoSyncReadOnlyReplicas w queryScaleOutSettings ustawieniu na wartość false.
Zarządzanie repliką
Skalowanie w poziomie tworzy jedną replikę modelu semantycznego odczytu i zapisu oraz dowolną liczbę replik tylko do odczytu. Wszystkie operacje zapisu są kierowane do repliki odczytu i zapisu. Obejmuje to zapytania dotyczące sesji przeznaczonych dla repliki odczytu i zapisu jawnie, czyli nie są używane ?readonly w parametry połączenia. Te zapytania mogą powodować wysokie interakcyjne użycie procesora CPU w repliki do odczytu i zapisu. W takich przypadkach nowa replika nie jest tworzona, ponieważ obciążenie zapytania przeznaczone dla repliki do odczytu i zapisu nie może być dystrybuowane do replik tylko do odczytu.
Liczba replik tylko do odczytu jest określana na podstawie liczby jednostek CU używanych przez zapytania. Jeśli zapotrzebowanie przekracza zasoby obliczeniowe obecnie dostępne w węźle, w którym jest ładowany model i pozostaje wysokie, dodatkowa replika tylko do odczytu może zostać utworzona w innym węźle w celu rozłożenia obciążenia. Łączna liczba jednostek SKU używanych przez wszystkie połączone repliki nie może jednak przekraczać maksymalnej liczby jednostek SKU, z których może korzystać pojedynczy model dla danej jednostki SKU pojemności.
Na przykład dany model semantyczny w pojemności F64 będzie miał wystarczającą ilość zasobów w jednym węźle, aby korzystać ze wszystkich dozwolonych jednostek SKU w tej jednostce SKU. W związku z tym pojemności F64 zwykle nie są skalowane w poziomie poza pojedynczą replikę tylko do odczytu. Z drugiej strony pojemności F256 i F1024+ są bardziej prawdopodobne, aby utworzyć drugą replikę tylko do odczytu, ponieważ pojedynczy węzeł może nie być wystarczający, aby zapewnić wszystkie jednostki CU, które mogą być używane w pojemności F256/F1024+.
Pakiet QSO jest przeznaczony do wykorzystania dostępnej mocy obliczeniowej danej jednostki SKU pojemności tak wydajnie i bezproblemowo, jak to możliwe z najmniejszą liczbą replik tylko do odczytu i bez nakładu pracy związanego z zarządzaniem dla właścicieli modeli semantycznych.
Jednak bieżące obciążenie pojemności może być wystarczająco wysokie, aby spowodować ograniczenie przepustowości w przypadku dodania większej liczby replik. Ograniczanie przepustowości uniemożliwia osiągnięcie trwałego wysokiego użycia procesora CPU przez dodatkowe repliki tylko do odczytu. W takich przypadkach nie jest tworzona nowa replika tylko do odczytu.
Replika jest usuwana, gdy użycie aktualizacji cu dla modelu zmniejsza się wystarczająco i stale pozostaje wystarczająco niskie.
Wymagania wstępne
Domyślnie skalowanie w poziomie jest włączone dla dzierżawy, ale nie jest włączone dla modeli semantycznych w dzierżawie. Aby włączyć skalowanie w poziomie dla modelu semantycznego, należy użyć interfejsów API REST usługi Power BI. Przed włączeniem należy spełnić następujące wymagania wstępne:
Ustawienie Skalowanie w poziomie zapytań dla dużych modeli semantycznych dla dzierżawy jest włączone (ustawienie domyślne).
Obszar roboczy znajduje się w pojemności usługi Power BI Premium:
- Premium na użytkownika (PPU)
- Jednostki SKU P usługi Power BI Premium
- Jednostki SKU usługi Power BI A dla usługi Power BI Embedded (znane również jako osadzanie dla klientów).
- Jednostki SKU F sieci szkieletowej
Ustawienie Format magazynu dużego modelu semantycznego jest włączone.
Aby zarządzać modelami semantycznymi przy użyciu interfejsu API REST, użyj poleceń cmdlet usługi Power BI Management. Zainstaluj, otwierając program PowerShell w trybie administratora i uruchamiając polecenie:
Install-Module -Name MicrosoftPowerBIMgmtNastępująca (lub nowsza) aplikacja, biblioteka i wersje usługi obsługują nawiązywanie połączenia z replikami tylko do odczytu:
Aplikacja, biblioteka lub usługa Wersja Dostawca OLE DB usług Microsoft Analysis Services dla programu Microsoft SQL Server (MSOLAP) 16.0.20.201 (marzec 2022 r.) Microsoft.AnalysisServices.AdomdClient (ADOMD.NET) 19.36.0 (marzec 2022 r.) Power BI Desktop Czerwiec 2022 SQL Server Management Studio (SSMS) 19,0 Tabelaryczny edytor 2 2.16.6 Tabelaryczny edytor 3 3.2.3 DAX Studio 3.0.0
Konfigurowanie skalowania w poziomie dla modelu semantycznego
Aby dowiedzieć się, jak włączyć lub wyłączyć skalowanie w poziomie dla modelu semantycznego lub uzyskać stan skalowania w poziomie przy użyciu programu PowerShell i interfejsów API REST, zobacz Konfigurowanie skalowania modelu semantycznego w poziomie.
Nawiązywanie połączenia z określonym typem modelu semantycznego
Po włączeniu skalowania w poziomie są zachowywane następujące połączenia:
Domyślnie program Power BI Desktop łączy się z repliką tylko do odczytu.
Raporty połączeń na żywo łączą się z repliką tylko do odczytu.
Aplikacje klienckie XMLA domyślnie łączą się z modelem semantycznym odczytu i zapisu.
Odświeża się w usługa Power BI i odświeża przy użyciu interfejsu API REST rozszerzonego odświeżania nawiąż połączenie z modelem semantycznym odczytu i zapisu.
Możesz nawiązać połączenie z repliką tylko do odczytu lub z semantycznym modelem odczytu i zapisu, dołączając jeden z następujących ciągów do adresu URL modelu semantycznego:
- Tylko odczyt -
?readonly - Odczyt i zapis -
?readwrite
Wyłączanie skalowania modelu semantycznego w poziomie dla dzierżawy
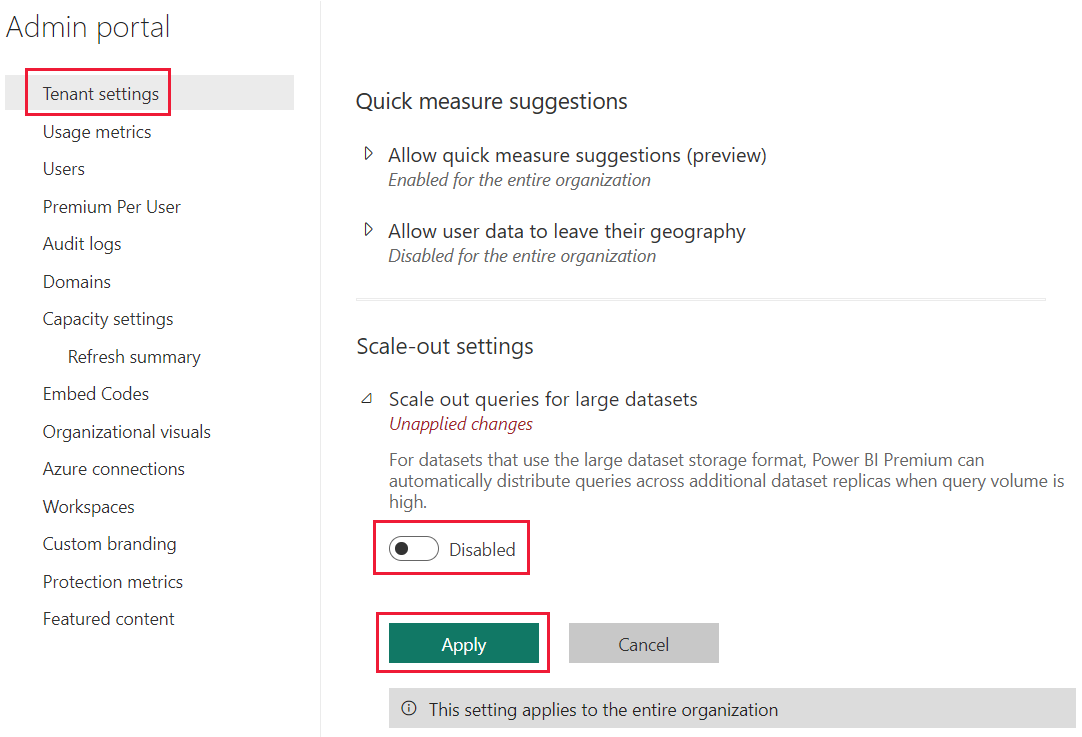
Skalowanie modelu semantycznego usługi Power BI w poziomie jest domyślnie włączone dla dzierżawy. Administratorzy dzierżawy usługi Power BI mogą wyłączyć to ustawienie. Aby wyłączyć skalowanie modelu semantycznego w poziomie dla dzierżawy, wykonaj następujące czynności:
Przejdź do ustawień dzierżawy.
W obszarze Ustawienia skalowania w poziomie rozwiń pozycję Zapytania skalowane w poziomie dla dużych modeli semantycznych.
Przełącz przełącznik na Wyłączone.
Wybierz Zastosuj.
Rozważania i ograniczenia
Aplikacje klienckie mogą łączyć się z repliką tylko do odczytu za pośrednictwem punktu końcowego XMLA, pod warunkiem, że obsługują tryb określony w parametry połączenia. Aplikacje klienckie mogą również łączyć się z wystąpieniem odczytu i zapisu przy użyciu punktu końcowego XMLA.
Odświeżanie ręczne i zaplanowane jest zawsze automatycznie synchronizowane z najnowszą wersją replik tylko do odczytu. Odświeżanie interfejsu API REST uwzględnia konfigurację automatycznej synchronizacji. Jeśli automatyczna synchronizacja jest wyłączona, model semantyczny musi być synchronizowany z replikami tylko do odczytu przy użyciu interfejsu API REST synchronizacji ręcznej.
Po wyłączeniu automatycznej synchronizacji aktualizacje i odświeżenia XMLA muszą być synchronizowane z kopiami modelu semantycznego tylko do odczytu przy użyciu interfejsu API REST synchronizacji.
Podczas usuwania modelu semantycznego skalowalnego w poziomie usługi Power BI i tworzenia innego modelu semantycznego o tej samej nazwie poczekaj pięć minut przed utworzeniem nowego modelu semantycznego. Usunięcie replik podstawowego modelu semantycznego może zająć trochę czasu w usłudze Power BI.
Gdy jest włączona funkcja skalowania modelu semantycznego usługi Power BI i
autoSyncReadOnlyReplicas=false, zmiany w następujących funkcjach nie są obsługiwane:- Dodawanie lub usuwanie ról
- Aktualizowanie zestawu członkostwa w rolach dla dowolnej roli
- Modyfikowanie źródła danych
- Usuwanie źródeł danych używanych przez zapytanie bezpośrednie lub tabelę podwójną
- Zmiany w wyrażeniach zabezpieczeń na poziomie obiektu (OLS) lub dynamicznych wyrażeń zabezpieczeń na poziomie wiersza
Aby wprowadzić zmiany w tych funkcjach, wyłącz skalowanie w poziomie i poczekaj kilka minut na zmianę przed ponownym opublikowaniem.
Odnajdywanie członkostwa w rolach przy użyciu dynamicznego widoku zarządzania (DMV) TMSCHEMA_ROLE_MEMBERSHIPS zestawu wierszy nie zwraca żadnych wyników podczas uruchamiania względem repliki tylko do odczytu.
Raporty korzystające z połączenia na żywo zawsze łączą się z repliką tylko do odczytu, nawet jeśli parametry połączenia używa metody
?readwrite. Jednak w programie Power BI Desktop raporty połączeń na żywo przy użyciu połączenia z?readwriterepliką do odczytu i zapisu.Zestawy wierszy widoku dynamicznego zarządzania (DMV) DBSCHEMA_CATALOGS i DISCOVER_XML_METADATA zwracają informacje o replice do odczytu i zapisu w przypadku użycia
?readonlyw parametry połączenia.Profiler programu SQL Server nie działa z
?readonlyparametry połączenia.Te operacje wyzwalają automatyczną synchronizację nawet wtedy, gdy automatyczna synchronizacja jest wyłączona (
AutoSync=Off).- Migrowanie obszaru roboczego z jednej pojemności do innej.
- Przełączanie (lub obracanie) wersji klucza używanego na potrzeby funkcji Bring your own encryption keys (BYOK).
- Przeniesienie obszaru roboczego modelu semantycznego z pojemności, która nie używa rozwiązania BYOK do pojemności korzystającej z funkcji BYOK.
- Przeniesienie obszaru roboczego modelu semantycznego z pojemności, która używa rozwiązania BYOK do pojemności, która nie korzysta z funkcji BYOK.
- Przywracanie modelu semantycznego przy użyciu publicznego punktu końcowego XMLA.
Wyłączenie dużego formatu magazynu modelu semantycznego powoduje wyłączenie skalowania w poziomie i utratę wszystkich informacji synchronizacji.