Omówienie mapowania widoku danych w wizualizacjach usługi Power BI
W tym artykule omówiono mapowanie widoku danych i opisano sposób użycia ról danych do tworzenia różnych typów wizualizacji. Wyjaśniono w nim, jak określić wymagania warunkowe dotyczące ról danych i różnych dataMappings typów.
Każde prawidłowe mapowanie tworzy widok danych. Możesz podać wiele mapowań danych w określonych warunkach. Obsługiwane opcje mapowania to:
"dataViewMappings": [
{
"conditions": [ ... ],
"categorical": { ... },
"single": { ... },
"table": { ... },
"matrix": { ... }
}
]
Usługa Power BI tworzy mapowanie do widoku danych tylko wtedy, gdy prawidłowe mapowanie jest również zdefiniowane w programie dataViewMappings.
Innymi słowy, można zdefiniować w parametrze , categorical ale inne mapowania, takie jak table lub single, mogą nie być.dataViewMappings W takim przypadku usługa Power BI tworzy widok danych z pojedynczym categorical mapowaniem, a table inne mapowania pozostają niezdefiniowane. Na przykład:
"dataViewMappings": [
{
"categorical": {
"categories": [ ... ],
"values": [ ... ]
},
"metadata": { ... }
}
]
Warunki
Sekcja conditions ustanawia reguły dla określonego mapowania danych. Jeśli dane są zgodne z jednym z opisanych zestawów warunków, wizualizacja akceptuje dane jako prawidłowe.
Dla każdego pola można określić minimalną i maksymalną wartość. Wartość reprezentuje liczbę pól, które mogą być powiązane z rolą danych.
Uwaga
Jeśli rola danych zostanie pominięta w warunku, może mieć dowolną liczbę pól.
W poniższym przykładzie parametr category jest ograniczony do jednego pola danych i measure jest ograniczony do dwóch pól danych.
"conditions": [
{ "category": { "max": 1 }, "measure": { "max": 2 } },
]
Można również ustawić wiele warunków dla roli danych. W takim przypadku dane są prawidłowe, jeśli zostanie spełniony jeden z warunków.
"conditions": [
{ "category": { "min": 1, "max": 1 }, "measure": { "min": 2, "max": 2 } },
{ "category": { "min": 2, "max": 2 }, "measure": { "min": 1, "max": 1 } }
]
W poprzednim przykładzie wymagany jest jeden z następujących dwóch warunków:
- Dokładnie jedno pole kategorii i dokładnie dwie miary
- Dokładnie dwie kategorie i dokładnie jedna miara
Pojedyncze mapowanie danych
Pojedyncze mapowanie danych jest najprostszą formą mapowania danych. Akceptuje pojedyncze pole miary i zwraca sumę. Jeśli pole jest liczbowe, zwraca sumę. W przeciwnym razie zwraca liczbę unikatowych wartości.
Aby użyć pojedynczego mapowania danych, zdefiniuj nazwę roli danych, którą chcesz mapować. To mapowanie działa tylko z pojedynczym polem miary. Jeśli przypisano drugie pole, nie jest generowany widok danych, dlatego dobrym rozwiązaniem jest uwzględnienie warunku ograniczającego dane do pojedynczego pola.
Uwaga
Tego mapowania danych nie można używać w połączeniu z żadnym innym mapowaniem danych. Ma to na celu zmniejszenie danych do pojedynczej wartości liczbowej.
Na przykład:
{
"dataRoles": [
{
"displayName": "Y",
"name": "Y",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"conditions": [
{
"Y": {
"max": 1
}
}
],
"single": {
"role": "Y"
}
}
]
}
Wynikowy widok danych może nadal zawierać inne typy mapowania, takie jak tabela lub kategorialne, ale każde mapowanie zawiera tylko jedną wartość. Najlepszym rozwiązaniem jest uzyskanie dostępu do wartości tylko w pojedynczym mapowaniu.
{
"dataView": [
{
"metadata": null,
"categorical": null,
"matrix": null,
"table": null,
"tree": null,
"single": {
"value": 94163140.3560001
}
}
]
}
Poniższy przykładowy kod przetwarza proste mapowanie widoków danych:
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewSingle = powerbi.DataViewSingle;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private valueText: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.valueText = document.createElement("p");
this.target.appendChild(this.valueText);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const singleDataView: DataViewSingle = dataView.single;
if (!singleDataView ||
!singleDataView.value ) {
return
}
this.valueText.innerText = singleDataView.value.toString();
}
}
Poprzedni przykładowy kod powoduje wyświetlenie pojedynczej wartości z usługi Power BI:
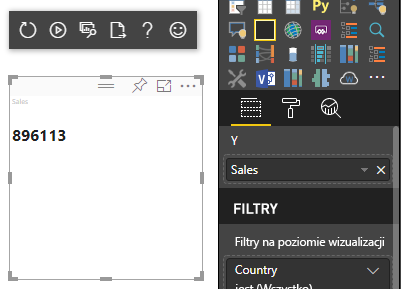
Mapowanie danych kategorii
Mapowanie danych kategorii służy do uzyskiwania niezależnych grup lub kategorii danych. Kategorie można również grupować przy użyciu opcji "grupuj według" w mapowaniu danych.
Podstawowe mapowanie danych kategorii
Rozważ następujące role danych i mapowania:
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
}
],
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" }
},
"values": {
"select": [
{ "bind": { "to": "measure" } }
]
}
}
}
W poprzednim przykładzie czytamy "Mapuj category moją rolę danych tak, aby dla każdego pola przeciągniętego do categoryelementu jego dane były mapowane na categorical.categories. Ponadto zamapuj moją measure rolę danych na categorical.values."
- dla... in: zawiera wszystkie elementy w tej roli danych w zapytaniu danych.
- wiązać... to: Daje taki sam wynik jak w przypadku... w programie , ale oczekuje, że rola danych będzie miała warunek ograniczający go do pojedynczego pola.
Grupowanie danych kategorii
W następnym przykładzie użyto tych samych dwóch ról danych co w poprzednim przykładzie i dodano dwie kolejne role danych o nazwach grouping i measure2.
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Grouping with",
"name": "grouping",
"kind": "Grouping"
},
{
"displayName": "X Axis",
"name": "measure2",
"kind": "Grouping"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "grouping",
"select": [{
"bind": {
"to": "measure"
}
},
{
"bind": {
"to": "measure2"
}
}
]
}
}
}
}
]
Różnica między tym mapowaniem a mapowaniem podstawowym polega na tym, jak categorical.values jest mapowane. Podczas mapowania measure ról i measure2 danych na rolę groupingdanych można odpowiednio skalować oś x i oś y.
Grupowanie danych hierarchicznych
W następnym przykładzie dane podzielone na kategorie służą do tworzenia hierarchii, która może służyć do obsługi akcji przechodzenia do szczegółów .
W poniższym przykładzie przedstawiono role danych i mapowania:
"dataRoles": [
{
"displayName": "Categories",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Measures",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Series",
"name": "series",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
]
}
}
}
}
]
Rozważ następujące dane podzielone na kategorie:
| Kraj/region | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|
| USA | x | x | 650 | 350 |
| Kanada | x | 630 | 490 | x |
| Meksyk | 645 | x | x | x |
| Zjednoczone Królestwo | x | x | 831 | x |
Usługa Power BI tworzy widok danych kategorii z następującym zestawem kategorii.
{
"categorical": {
"categories": [
{
"source": {...},
"values": [
"Canada",
"USA",
"UK",
"Mexico"
],
"identity": [...],
"identityFields": [...],
}
]
}
}
Każda category mapuje na zestaw values. Każda z nich values jest grupowana według serieswartości , która jest wyrażona jako lata.
Na przykład każda tablica values reprezentuje jeden rok.
Ponadto każda tablica values ma cztery wartości: Kanada, USA, Wielka Brytania i Meksyk.
{
"values": [
// Values for year 2013
{
"source": {...},
"values": [
null, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
645 // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2014
{
"source": {...},
"values": [
630, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2015
{
"source": {...},
"values": [
490, // Value for `Canada` category
650, // Value for `USA` category
831, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2016
{
"source": {...},
"values": [
null, // Value for `Canada` category
350, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
}
]
}
Poniższy przykład kodu służy do przetwarzania mapowania widoku danych kategorii. Ten przykład tworzy hierarchiczną strukturę Country/Region > Year > Value.
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewCategorical = powerbi.DataViewCategorical;
import DataViewValueColumnGroup = powerbi.DataViewValueColumnGroup;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private categories: HTMLElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.categories = document.createElement("pre");
this.target.appendChild(this.categories);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const categoricalDataView: DataViewCategorical = dataView.categorical;
if (!categoricalDataView ||
!categoricalDataView.categories ||
!categoricalDataView.categories[0] ||
!categoricalDataView.values) {
return;
}
// Categories have only one column in data buckets
// To support several columns of categories data bucket, iterate categoricalDataView.categories array.
const categoryFieldIndex = 0;
// Measure has only one column in data buckets.
// To support several columns on data bucket, iterate years.values array in map function
const measureFieldIndex = 0;
let categories: PrimitiveValue[] = categoricalDataView.categories[categoryFieldIndex].values;
let values: DataViewValueColumnGroup[] = categoricalDataView.values.grouped();
let data = {};
// iterate categories/countries-regions
categories.map((category: PrimitiveValue, categoryIndex: number) => {
data[category.toString()] = {};
// iterate series/years
values.map((years: DataViewValueColumnGroup) => {
if (!data[category.toString()][years.name] && years.values[measureFieldIndex].values[categoryIndex]) {
data[category.toString()][years.name] = []
}
if (years.values[0].values[categoryIndex]) {
data[category.toString()][years.name].push(years.values[measureFieldIndex].values[categoryIndex]);
}
});
});
this.categories.innerText = JSON.stringify(data, null, 6);
console.log(data);
}
}
Oto wynikowa wizualizacja:
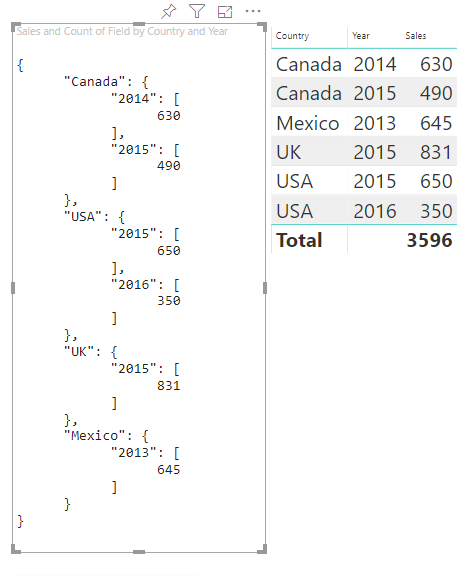
Tabele mapowania
Widok danych tabeli jest zasadniczo listą punktów danych, w których można agregować punkty danych liczbowych.
Na przykład użyj tych samych danych w poprzedniej sekcji, ale z następującymi możliwościami:
"dataRoles": [
{
"displayName": "Column",
"name": "column",
"kind": "Grouping"
},
{
"displayName": "Value",
"name": "value",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"table": {
"rows": {
"select": [
{
"for": {
"in": "column"
}
},
{
"for": {
"in": "value"
}
}
]
}
}
}
]
Wizualizuj widok danych tabeli w następujący przykład:
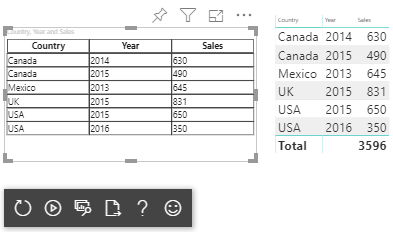
| Kraj/region | Year (Rok) | Sales |
|---|---|---|
| USA | 2016 | 100 |
| USA | 2015 | 50 |
| Kanada | 2015 | 200 |
| Kanada | 2015 | 50 |
| Meksyk | 2013 | 300 |
| Zjednoczone Królestwo | 2014 | 150 |
| USA | 2015 | 75 |
Powiązanie danych:
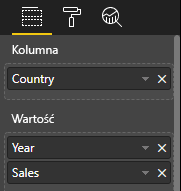
Usługa Power BI wyświetla dane jako widok danych tabeli. Nie zakładaj, że dane są uporządkowane.
{
"table" : {
"columns": [...],
"rows": [
[
"Canada",
2014,
630
],
[
"Canada",
2015,
490
],
[
"Mexico",
2013,
645
],
[
"UK",
2014,
831
],
[
"USA",
2015,
650
],
[
"USA",
2016,
350
]
]
}
}
Aby zagregować dane, wybierz odpowiednie pole, a następnie wybierz pozycję Suma.
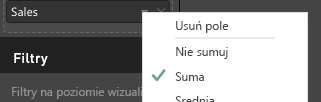
Przykładowy kod do przetwarzania mapowania widoku danych tabeli.
"use strict";
import "./../style/visual.less";
import powerbi from "powerbi-visuals-api";
// ...
import DataViewMetadataColumn = powerbi.DataViewMetadataColumn;
import DataViewTable = powerbi.DataViewTable;
import DataViewTableRow = powerbi.DataViewTableRow;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private table: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.table = document.createElement("table");
this.target.appendChild(this.table);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const tableDataView: DataViewTable = dataView.table;
if (!tableDataView) {
return
}
while(this.table.firstChild) {
this.table.removeChild(this.table.firstChild);
}
//draw header
const tableHeader = document.createElement("th");
tableDataView.columns.forEach((column: DataViewMetadataColumn) => {
const tableHeaderColumn = document.createElement("td");
tableHeaderColumn.innerText = column.displayName
tableHeader.appendChild(tableHeaderColumn);
});
this.table.appendChild(tableHeader);
//draw rows
tableDataView.rows.forEach((row: DataViewTableRow) => {
const tableRow = document.createElement("tr");
row.forEach((columnValue: PrimitiveValue) => {
const cell = document.createElement("td");
cell.innerText = columnValue.toString();
tableRow.appendChild(cell);
})
this.table.appendChild(tableRow);
});
}
}
Plik style/visual.less stylów wizualizacji zawiera układ tabeli:
table {
display: flex;
flex-direction: column;
}
tr, th {
display: flex;
flex: 1;
}
td {
flex: 1;
border: 1px solid black;
}
Wynikowa wizualizacja wygląda następująco:
Mapowanie danych macierzy
Mapowanie danych macierzy jest podobne do mapowania danych tabeli, ale wiersze są prezentowane hierarchicznie. Dowolnego z wartości roli danych można użyć jako wartości nagłówka kolumny.
{
"dataRoles": [
{
"name": "Category",
"displayName": "Category",
"displayNameKey": "Visual_Category",
"kind": "Grouping"
},
{
"name": "Column",
"displayName": "Column",
"displayNameKey": "Visual_Column",
"kind": "Grouping"
},
{
"name": "Measure",
"displayName": "Measure",
"displayNameKey": "Visual_Values",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"matrix": {
"rows": {
"for": {
"in": "Category"
}
},
"columns": {
"for": {
"in": "Column"
}
},
"values": {
"select": [
{
"for": {
"in": "Measure"
}
}
]
}
}
}
]
}
Hierarchiczna struktura danych macierzy
Usługa Power BI tworzy hierarchiczną strukturę danych. Katalog główny hierarchii drzewa zawiera dane z kolumny Category Rodzice roli danych z elementami podrzędnymi z kolumny Podrzędne tabeli roli danych.
Model semantyczny:
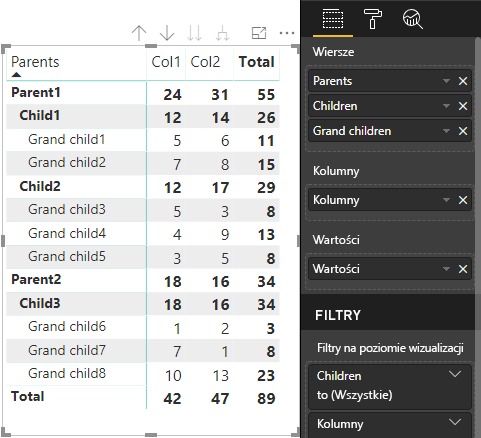
| Elementy nadrzędne | Children | Wnuki | Kolumny | Wartości |
|---|---|---|---|---|
| Element nadrzędny1 | Element podrzędny1 | Grand child1 | Kolumna 1 | 5 |
| Element nadrzędny1 | Element podrzędny1 | Grand child1 | Kolumna 2 | 6 |
| Element nadrzędny1 | Element podrzędny1 | Grand child2 | Kolumna 1 | 7 |
| Element nadrzędny1 | Element podrzędny1 | Grand child2 | Kolumna 2 | 8 |
| Element nadrzędny1 | Element podrzędny 2 | Wielkie dziecko3 | Kolumna 1 | 5 |
| Element nadrzędny1 | Element podrzędny 2 | Wielkie dziecko3 | Kolumna 2 | 3 |
| Element nadrzędny1 | Element podrzędny 2 | Wielkie dziecko4 | Kolumna 1 | 100 |
| Element nadrzędny1 | Element podrzędny 2 | Wielkie dziecko4 | Kolumna 2 | 9 |
| Element nadrzędny1 | Element podrzędny 2 | Grand child5 | Kolumna 1 | 3 |
| Element nadrzędny1 | Element podrzędny 2 | Grand child5 | Kolumna 2 | 5 |
| Element nadrzędny 2 | Podrzędne 3 | Grand child6 | Kolumna 1 | 1 |
| Element nadrzędny 2 | Podrzędne 3 | Grand child6 | Kolumna 2 | 2 |
| Element nadrzędny 2 | Podrzędne 3 | Grand child7 | Kolumna 1 | 7 |
| Element nadrzędny 2 | Podrzędne 3 | Grand child7 | Kolumna 2 | 1 |
| Element nadrzędny 2 | Podrzędne 3 | Grand child8 | Kolumna 1 | 10 |
| Element nadrzędny 2 | Podrzędne 3 | Grand child8 | Kolumna 2 | 13 |
Podstawowa wizualizacja macierzy usługi Power BI renderuje dane jako tabelę.
Wizualizacja pobiera strukturę danych zgodnie z opisem w poniższym kodzie (pokazano tutaj tylko dwa pierwsze wiersze tabeli):
{
"metadata": {...},
"matrix": {
"rows": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Parent1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 1,
"levelValues": [...],
"value": "Child1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 2,
"levelValues": [...],
"value": "Grand child1",
"identity": {...},
"values": {
"0": {
"value": 5 // value for Col1
},
"1": {
"value": 6 // value for Col2
}
}
},
...
]
},
...
]
},
...
]
}
},
"columns": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Col1",
"identity": {...}
},
{
"level": 0,
"levelValues": [...],
"value": "Col2",
"identity": {...}
},
...
]
}
},
"valueSources": [...]
}
}
Rozwiń i zwiń nagłówki wierszy
W przypadku interfejsu API 4.1.0 lub nowszego dane macierzy obsługują rozszerzanie i zwijanie nagłówków wierszy. Z poziomu interfejsu API 4.2 można programowo rozwinąć/zwinąć cały poziom. Funkcja rozwijania i zwijania optymalizuje pobieranie danych do widoku dataView, umożliwiając użytkownikowi rozwinięcie lub zwinięcie wiersza bez pobierania wszystkich danych na następny poziom. Pobiera tylko dane dla wybranego wiersza. Stan rozszerzenia nagłówka wiersza pozostaje spójny w zakładkach, a nawet w zapisanych raportach. Nie jest ona specyficzna dla każdej wizualizacji.
Polecenia rozwijania i zwijania można dodać do menu kontekstowego, podając dataRoles parametr do showContextMenu metody .
Aby rozwinąć dużą liczbę punktów danych, użyj interfejsu API pobierania większej ilości danych za pomocą interfejsu API rozwijania/zwijania.
Funkcje interfejsu API
Następujące elementy zostały dodane do interfejsu API w wersji 4.1.0, aby umożliwić rozwijanie i zwijanie nagłówków wierszy:
Flaga
isCollapsedw elemecieDataViewTreeNode:interface DataViewTreeNode { //... /** * TRUE if the node is Collapsed * FALSE if it is Expanded * Undefined if it cannot be Expanded (e.g. subtotal) */ isCollapsed?: boolean; }Metoda
toggleExpandCollapsew interfejsieISelectionManger:interface ISelectionManager { //... showContextMenu(selectionId: ISelectionId, position: IPoint, dataRoles?: string): IPromise<{}>; // dataRoles is the name of the role of the selected data point toggleExpandCollapse(selectionId: ISelectionId, entireLevel?: boolean): IPromise<{}>; // Expand/Collapse an entire level will be available from API 4.2.0 //... }Flaga
canBeExpandedw elemecie DataViewHierarchyLevel:interface DataViewHierarchyLevel { //... /** If TRUE, this level can be expanded/collapsed */ canBeExpanded?: boolean; }
Wymagania wizualne
Aby włączyć funkcję zwijania rozwijania w wizualizacji przy użyciu widoku danych macierzy:
Dodaj następujący kod do pliku capabilities.json:
"expandCollapse": { "roles": ["Rows"], //”Rows” is the name of rows data role "addDataViewFlags": { "defaultValue": true //indicates if the DataViewTreeNode will get the isCollapsed flag by default } },Upewnij się, że role można przechodzić do szczegółów:
"drilldown": { "roles": ["Rows"] },Dla każdego węzła utwórz wystąpienie konstruktora wyboru, wywołując
withMatrixNodemetodę na wybranym poziomie hierarchii węzłów i tworząc elementselectionId. Na przykład:let nodeSelectionBuilder: ISelectionIdBuilder = visualHost.createSelectionIdBuilder(); // parantNodes is a list of the parents of the selected node. // node is the current node which the selectionId is created for. parentNodes.push(node); for (let i = 0; i < parentNodes.length; i++) { nodeSelectionBuilder = nodeSelectionBuilder.withMatrixNode(parentNodes[i], levels); } const nodeSelectionId: ISelectionId = nodeSelectionBuilder.createSelectionId();Utwórz wystąpienie menedżera wyboru i użyj
selectionManager.toggleExpandCollapse()metody z parametremselectionId, który został utworzony dla wybranego węzła. Na przykład:// handle click events to apply expand\collapse action for the selected node button.addEventListener("click", () => { this.selectionManager.toggleExpandCollapse(nodeSelectionId); });
Uwaga
- Jeśli wybrany węzeł nie jest węzłem wiersza, usługa Power BI zignoruje wywołania rozwijania i zwijania, a polecenia rozwijania i zwijania zostaną usunięte z menu kontekstowego.
- Parametr jest wymagany dla
showContextMenumetody tylko wtedy, gdy wizualizacjadataRolesobsługujedrilldownlubexpandCollapsefunkcje. Jeśli wizualizacja obsługuje te funkcje, ale dane dataRole nie zostały dostarczone, podczas korzystania z wizualizacji dewelopera lub debugowania publicznej wizualizacji z włączonym trybem debugowania wystąpi błąd.
Rozważania i ograniczenia
- Po rozwinięciu węzła do widoku DataView zostaną zastosowane nowe limity danych. Nowy element DataView może nie zawierać niektórych węzłów przedstawionych w poprzednim widoku danych.
- W przypadku używania rozszerzenia lub zwijania sumy są dodawane nawet wtedy, gdy wizualizacja nie zażądała ich.
- Rozszerzanie i zwijanie kolumn nie jest obsługiwane.
Zachowaj wszystkie kolumny metadanych
W przypadku interfejsu API 5.1.0 lub nowszego obsługiwana jest obsługa wszystkich kolumn metadanych. Ta funkcja umożliwia wizualizacji odbieranie metadanych dla wszystkich kolumn niezależnie od tego, jakie są ich aktywne projekcje.
Dodaj następujące wiersze do pliku capabilities.json :
"keepAllMetadataColumns": {
"type": "boolean",
"description": "Indicates that visual is going to receive all metadata columns, no matter what the active projections are"
}
Ustawienie tej właściwości spowoduje true otrzymanie wszystkich metadanych, w tym z zwiniętych kolumn. Ustawienie go na false wartość lub pozostawienie niezdefiniowanej spowoduje odbieranie metadanych tylko w kolumnach z aktywnymi projekcjami (na przykład rozwiniętymi).
Algorytm redukcji danych
Algorytm redukcji danych określa, które dane i ile danych są odbierane w widoku danych.
Liczba jest ustawiona na maksymalną liczbę wartości, które można zaakceptować w widoku danych. Jeśli istnieje więcej niż liczba wartości, algorytm redukcji danych określa, które wartości powinny zostać odebrane.
Typy algorytmów redukcji danych
Istnieją cztery typy ustawień algorytmu redukcji danych:
top: pierwsze wartości liczbowe są pobierane z modelu semantycznego.bottom: ostatnie wartości liczbowe pochodzą z modelu semantycznego.sample: Uwzględniane są pierwsze i ostatnie elementy oraz liczba elementów z równymi interwałami między nimi. Na przykład jeśli masz model semantyczny [0, 1, 2, ... 100] i liczba 9, otrzymujesz wartości [0, 10, 20 ... 100].window: Ładuje jedno okno punktów danych w czasie zawierającym elementy liczbowe .topObecnie iwindowsą równoważne. W przyszłości ustawienie okna będzie w pełni obsługiwane.
Domyślnie wszystkie wizualizacje usługi Power BI mają zastosowany algorytm redukcji danych z liczbą ustawioną na 1000 punktów danych. To ustawienie domyślne jest równoważne ustawieniu następujących właściwości w pliku capabilities.json :
"dataReductionAlgorithm": {
"top": {
"count": 1000
}
}
Można zmodyfikować wartość zliczaną na dowolną wartość całkowitą do 30000. Wizualizacje usługi Power BI oparte na języku R mogą obsługiwać maksymalnie 150000 wierszy.
Użycie algorytmu redukcji danych
Algorytm redukcji danych może być używany w mapowaniu widoku danych kategorii, tabeli lub macierzy.
W mapowaniu danych kategorii można dodać algorytm do sekcji values "kategorie" i/lub "grup" dla mapowania danych kategorii.
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" },
"dataReductionAlgorithm": {
"window": {
"count": 300
}
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
],
"dataReductionAlgorithm": {
"top": {
"count": 100
}
}
}
}
}
}
W mapowaniu widoku danych tabeli zastosuj algorytm redukcji danych do rows sekcji tabeli mapowania widoku danych.
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"top": {
"count": 2000
}
}
}
}
}
]
Algorytm redukcji danych można zastosować do rows sekcji i columns macierzy mapowania widoku danych.