Opis faz wykonywania aplikacji kanwy, przepływu wywołań danych i monitorowania wydajności
Gdy użytkownik otwiera aplikację kanwy, przechodzi ona przez kilka faz wykonania, zanim zostanie wyświetlony interfejs użytkownika. Podczas ładowania aplikacji łączy się ona z różnymi źródłami danych — takimi jak SharePoint, Microsoft Dataverse, SQL Server (lokalne wystąpienia), Azure SQL Database (online), Excel i Oracle.
W tym artykule dowiesz się o różnych fazach wykonywania, o tym, jak aplikacja łączy się ze źródłami danych, a także o narzędziach, których możesz użyć do monitorowania wydajności.
Fazy wykonywania w aplikacjach kanwy
Aplikacja kanwy przechodzi przez następujące fazy wykonywania przed wyświetleniem interfejsu użytkownikowi:
Uwierzytelnianie użytkownika: wyświetla monit o zalogowanie się przy użyciu poświadczeń dla wszystkich połączeń, które są potrzebne aplikacji, przy pierwszym logowaniu. Jeśli ten sam użytkownik otworzy aplikację ponownie, monit może zostać wyświetlony ponownie w zależności od zasad zabezpieczeń organizacji.
Pobranie metadanych: Pobranie metadanych, takich jak wersja platformy Power Apps, na której jest uruchamiana aplikacja, i źródła, z których pobiera dane.
Inicjowanie aplikacji: wykonanie wszelkich zadań określonych za pomocą właściwości OnStart.
Renderowanie ekranów: renderowanie pierwszego ekranu za pomocą kontrolek wypełnionych danymi przez aplikację. Jeśli użytkownik otwiera inne ekrany, aplikacja renderuje je przy użyciu tego samego procesu.
Przepływ wywołań danych w aplikacjach kanwy
Wywołania danych z aplikacji kanwy wysyłają dane do tabelarycznych źródeł danych przy użyciu łączników za pośrednictwem protokołu OData. Żądania OData przepływają do warstw zaplecza, aby skontaktować się z docelowym źródło danych i pobrać dane dla klienta lub przekazać dane do źródło danych. Łączniki oparte na akcjach, które umożliwiają interfejsy API, działają w ten sam sposób.
Zrozumienie sposobu przesyłania żądań OData i API w aplikacjach kanwy może pomóc zoptymalizować wydajność aplikacji kanwy i źródeł danych zaplecza.
W tej sekcji dowiesz się, jak wywołania danych przepływają w aplikacjach kanwy dla różnych typów źródeł danych.
Przepływ wywołań danych dla źródeł danych online
Na poniższym diagramie pokazano, jak typowe żądanie danych w aplikacji kanwy (po lewej stronie) przechodzi przez warstwy po stronie serwera i dociera do docelowego źródła danych (po prawej stronie), a następnie zwraca dane klientowi.

Każda warstwa na poprzednim diagramie może działać szybko lub mieć pewne dodatkowe obciążenia występujące w trakcie przetwarzania żądania. W wielu aplikacjach znaczące obciążenia mogą występować w dwóch konkretnych miejscach:
Źródło danych na zapleczu podczas przetwarzania żądania.
Klient podczas wysyłania żądania — lub podczas wykonywania operacji na odebranych danych w pamięci sterty oraz wykonywania powiązanych funkcji JavaScript w celu przetwarzania danych na potrzeby ich wyświetlenia wewnątrz ekranów.
Przepływ wywołań danych dla lokalnej bramy danych
Jeśli aplikacja kanwy łączy się z lokalnym źródłem danych, takim jak SQL Server, musisz mieć dodatkową warstwę nazywaną lokalną bramą danych. Ta brama jest wymagana w celu dostępu do lokalnych źródeł danych. Przejmuje kontrolę nad procesem konwersji z żądań OData na instrukcje DML (Data Manipulation Language) języka SQL.
Na poniższym diagramie pokazano, gdzie i jak lokalna brama danych wchodzi do akcji i przetwarza żądania danych.

Jeśli aplikacja korzysta z lokalnego źródła danych, lokalizacja i specyfikacja bramy danych również wpłynie na wydajność wywołań danych.
Przepływ rozmów dotyczących danych przy użyciu Microsoft Dataverse
Gdy używasz Microsoft Dataverse jako źródła danych, żądania danych przechodzą bezpośrednio do wystąpienia środowiska—bez przechodzenia przez Azure API Management. Z tego powodu wydajność transmisji danych jest szybsza w porównaniu do pozostałych źródeł danych. Ta aplikacja jest domyślnie połączona do Microsoft Dataverse podczas tworzenia nowej aplikacji kanwy.

Dzięki zrozumieniu tej ogólnej koncepcji sposobu przemieszczania się wywołań danych można szczegółowo ustalić przyczyny określonej wydajności. Krótko mówiąc, obciążenia pogarszające wydajność mogą się zdarzyć w dowolnej warstwie — na kliencie, w usłudze APIM (API Management), łącznik, lokalnej bramie danych i źródłach danych na zapleczu.
Mierzenie wydajności
Narzędzie monitorowania Power Apps
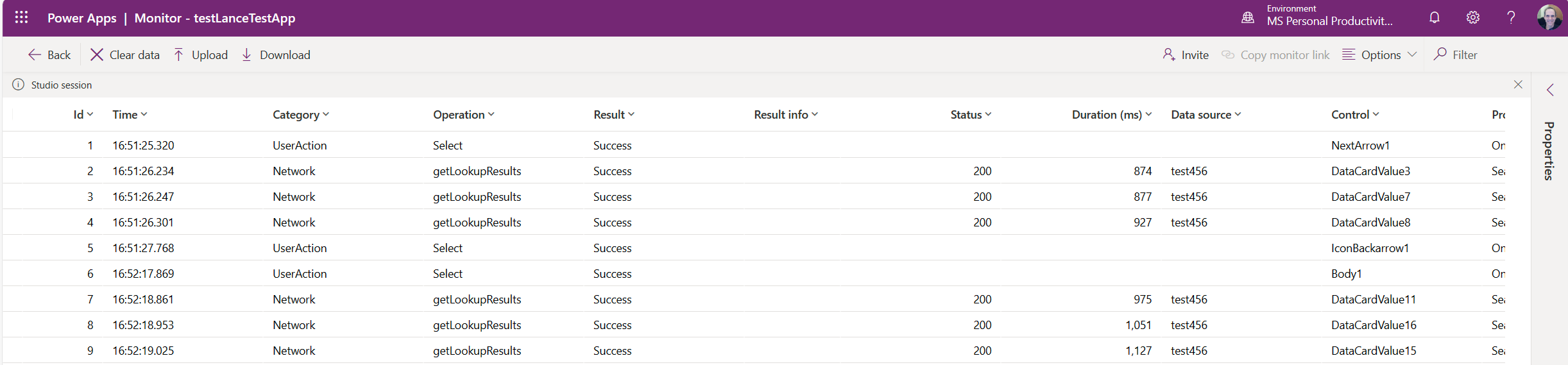
Chociaż możesz użyć narzędzi programistycznych przeglądarki, aby sprawdzić wydajność, Power Apps podgrupuje zestaw wywołań w narzędziu Monitorowanie tylko do tych, które są Power Apps.
Narzędzie monitorujące Power Apps może pomóc Ci śledzić, co faktycznie jest wysyłane do źródło danych, a także znaczniki czasu wysyłania żądań i otrzymywania odpowiedzi z serwera.
Więcej informacji o narzędziu do monitorowania znajdziesz w tym artykule: Debugowanie aplikacji kanwy za pomocą Monitora.
Pomiar obciążenia pamięci klienta
Aby graficznie zobaczyć zużycie pamięci, możesz użyć narzędzi programistycznych przeglądarki do profilowania pamięci. Profil wizualizuje rozmiar sterty, dokumenty, węzły i odbiorniki. Sprawdź profil wydajności aplikacji za pomocą przeglądarki, zgodnie z opisem w Przegląd narzędzi dewelopera Microsoft Edge (Chromium). Sprawdź scenariusze, które przekroczą wartość progową dla pamięci dla sterty JS. Więcej informacji: Rozwiązywanie problemów z pamięcią

Następne kroki
Zobacz też
Rozwiązywanie problemów z Power Apps
Uwaga
Czy możesz poinformować nas o preferencjach dotyczących języka dokumentacji? Wypełnij krótką ankietę. (zauważ, że ta ankieta jest po angielsku)
Ankieta zajmie około siedmiu minut. Nie są zbierane żadne dane osobowe (oświadczenie o ochronie prywatności).