Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano ogólny łącznik SQL. Artykuł dotyczy następujących produktów:
- Microsoft Identity Manager 2016 (MIM2016)
- Microsoft Entra ID
Dla MIM2016 łącznik jest dostępny do pobrania z Centrum pobierania Microsoft.
Aby zobaczyć, jak działa ten łącznik, sprawdź artykuł Krok po kroku dotyczący Ogólnego Łącznika SQL.
Uwaga
Microsoft Entra ID teraz udostępnia uproszczone rozwiązanie oparte na agencie do inicjacji użytkowników w bazie danych SQL, bez konieczności wdrażania synchronizacji programu MIM. Zalecamy użycie go na potrzeby aprowizacji użytkowników wychodzących. Dowiedz się więcej.
Omówienie ogólnego łącznika SQL
Ogólny łącznik SQL umożliwia integrację usługi synchronizacji z systemem bazy danych, który oferuje łączność ODBC.
Z perspektywy wysokiego poziomu następujące funkcje są obsługiwane przez bieżącą wersję łącznika:
| Funkcja | Wsparcie |
|---|---|
| Połączone źródło danych | Łącznik jest obsługiwany ze wszystkimi 64-bitowymi sterownikami ODBC*. Został przetestowany z następującymi elementami: |
| Scenariusze | |
| Operacje | |
| Schemat |
Wymagania wstępne
Przed użyciem łącznika upewnij się, że na serwerze synchronizacji są następujące elementy:
- Microsoft .NET 4.6.2 Framework lub nowszy
- 64-bitowe sterowniki klienta ODBC
- Jeśli używasz łącznika do komunikowania się z programem Oracle 12c, wymaga to programu Oracle Instant Client 12.2.0.1 lub nowszego z pakietem ODBC.
- Jeśli używasz łącznika do komunikowania się z programem Oracle 18c-23c, wymaga to programu Oracle Instant Client 18-23 lub nowszego z pakietem ODBC, a zmienna systemowa NLS_LANG ma być ustawiona na obsługę znaków UTF8, np. NLS_LANG=AMERICAN_AMERICA. AL32UTF8.
- Ten konektor używa instrukcji przygotowanych SQL oraz wielu instrukcji na transakcję. Niektóre systemy RDBM mogą mieć problemy w sterownikach ODBC związane z obsługą transakcji, przygotowywaniem instrukcji SQL po stronie serwera oraz wykonywaniem wielu instrukcji w ramach tej samej transakcji. Skonfiguruj odpowiednio opcje połączenia DSN, aby upewnić się, że te instrukcje są poprawnie wysyłane do bazy danych. Na przykład sterownik OdBC MySQL w wersji 8.0.32 wymaga opcji NO_SSPS=1 i MULTI_STATEMENTS=1. Inne opcje, takie jak "automatyczne zatwierdzanie" lub "zatwierdzanie tylko operacji zakończonych powodzeniem", mogą mieć wpływ na sposób obsługi eksportów wsadowych; aby uzyskać szczegółowe informacje, skontaktuj się z administratorem bazy danych. Aby rozwiązać problemy podczas eksportowania, ustaw rozmiar partii eksportu na 1 i włącz szczegółowe rejestrowanie łącznika.
Wdrożenie tego łącznika może wymagać zmian w konfiguracji bazy danych, a także zmian konfiguracji w programie MIM. W przypadku wdrożeń obejmujących integrację programu MIM z serwerem bazy danych innej firmy w środowisku produkcyjnym zalecamy klientom pracę z dostawcą bazy danych lub partnerem wdrażania, aby uzyskać pomoc, wskazówki i obsługę tej integracji.
Uprawnienia w połączonym źródle danych
Aby utworzyć lub wykonać dowolne z obsługiwanych zadań w łączniku Generic SQL, musisz mieć następujące elementy:
- db_datareader
- db_datawriter
Porty i protokoły
Aby porty wymagane do działania sterownika ODBC działały, zapoznaj się z dokumentacją dostawcy bazy danych.
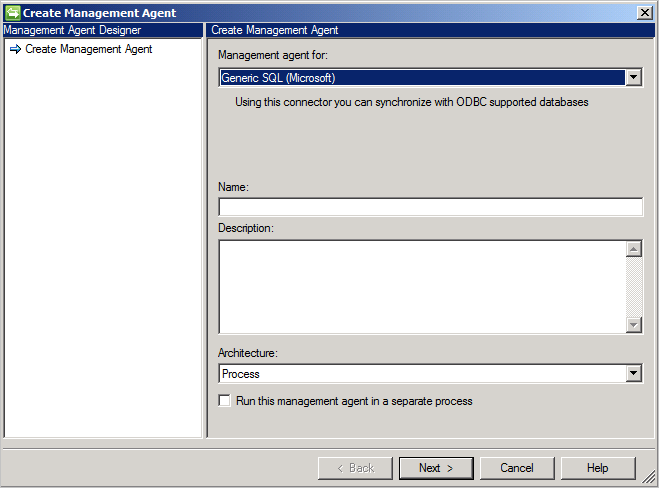
Tworzenie nowego łącznika
Aby utworzyć uniwersalny łącznik SQL, w Usłudze synchronizacji wybierz Agent zarządzania i Utwórz. Wybierz łącznik Generic SQL (Microsoft).
Łączność
Łącznik używa pliku DSN ODBC do łączności. Utwórz plik DSN przy użyciu źródeł danych ODBC znajdujących się w menu Start w obszarze Narzędzia administracyjne. W narzędziu administracyjnym utwórz File DSN, aby mógł być przekazany do łącznika.
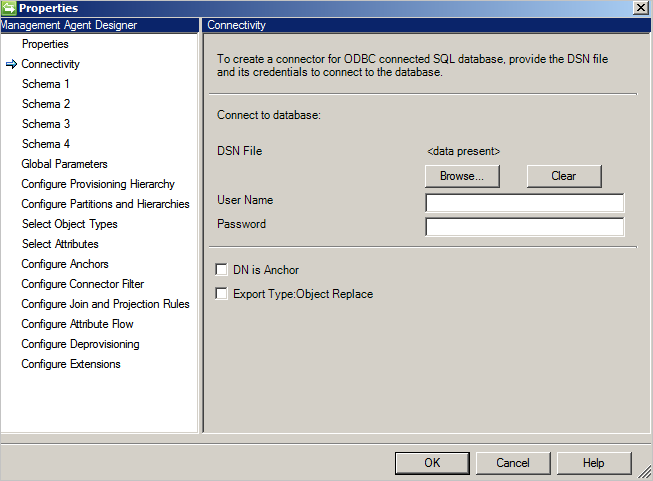
Ekran Łączność jest pierwszym elementem podczas tworzenia nowego ogólnego łącznika SQL. Najpierw należy podać następujące informacje:
- Ścieżka pliku DSN
- Uwierzytelnianie
- Nazwa użytkownika
- Hasło
Baza danych powinna obsługiwać jedną z następujących metod uwierzytelniania:
- Uwierzytelnianie systemu Windows: uwierzytelniająca baza danych używa poświadczeń systemu Windows do zweryfikowania użytkownika. Określona nazwa użytkownika/hasło służy do uwierzytelniania w bazie danych. To konto musi mieć uprawnienia do bazy danych.
- Uwierzytelnianie SQL: uwierzytelniająca baza danych używa nazwy użytkownika/hasła zdefiniowanego na ekranie Łączność w celu nawiązania połączenia z bazą danych. Jeśli przechowujesz nazwę użytkownika/pasword w pliku DSN, poświadczenia podane na ekranie Łączność mają pierwszeństwo.
- Uwierzytelnianie usługi Azure SQL Database: aby uzyskać więcej informacji, zobacz Nawiązywanie połączenia z bazą danych SQL Database za pośrednictwem uwierzytelniania usługi Microsoft Entra.
DN jest kotwicą: jeśli wybierzesz tę opcję, DN jest również używana jako atrybut kotwicy. Można go użyć do prostej implementacji, ale także ma następujące ograniczenie:
- Łącznik obsługuje tylko jeden typ obiektu. W związku z tym wszystkie atrybuty odwołania mogą odwoływać się tylko do tego samego typu obiektu.
Typ eksportu: Zamiana obiektu: podczas eksportu, gdy zmieniają się tylko niektóre atrybuty, cały obiekt ze wszystkimi atrybutami jest eksportowany i zastępuje istniejący obiekt.
Schemat 1 (Wykrywanie typów obiektów)
Na tej stronie skonfigurujesz sposób znajdowania różnych typów obiektów w bazie danych przez łącznik.
Każdy typ obiektu jest przedstawiany jako partycja i konfigurowany dalej w obszarze Konfigurowanie partycji i hierarchii.
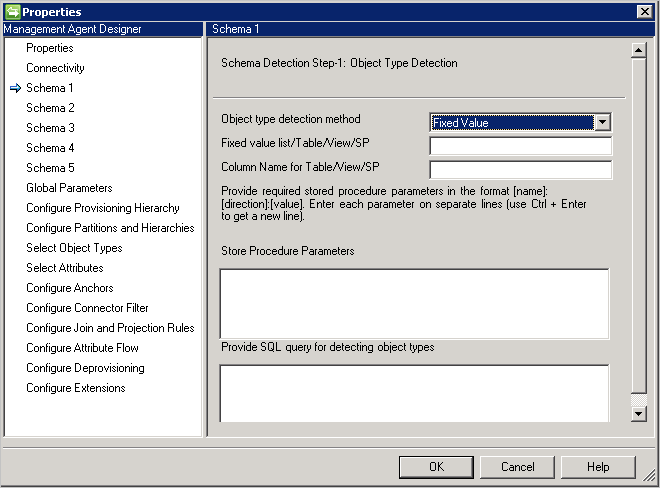
Metoda wykrywania typu obiektu: Łącznik obsługuje te metody wykrywania typów obiektów.
-
Stała wartość: Należy podać listę typów obiektów z listą rozdzielaną przecinkami. Na przykład:
User,Group,Department.
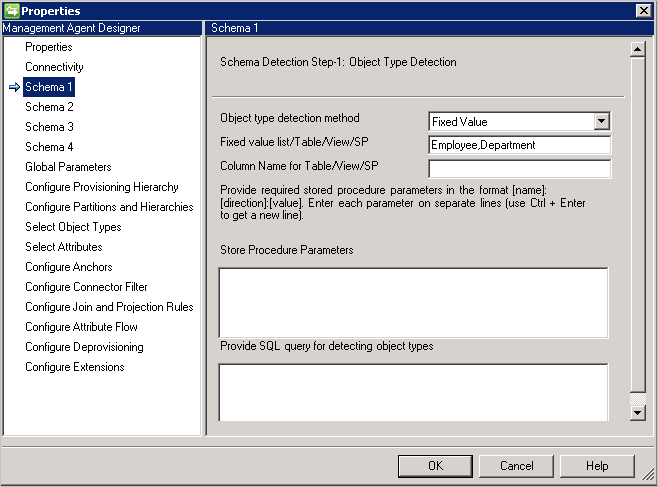
-
Tabela/Widok/Procedura składowana: podaj nazwę tabeli/widoku/procedury składowanej, a następnie nazwę kolumny, która zawiera listę typów obiektów. Jeśli używasz procedury składowanej, podaj również parametry dla niego w formacie [Name]:[Direction]:[Value]. Podaj każdy parametr w osobnym wierszu (użyj Ctrl+Enter, aby uzyskać nowy wiersz).
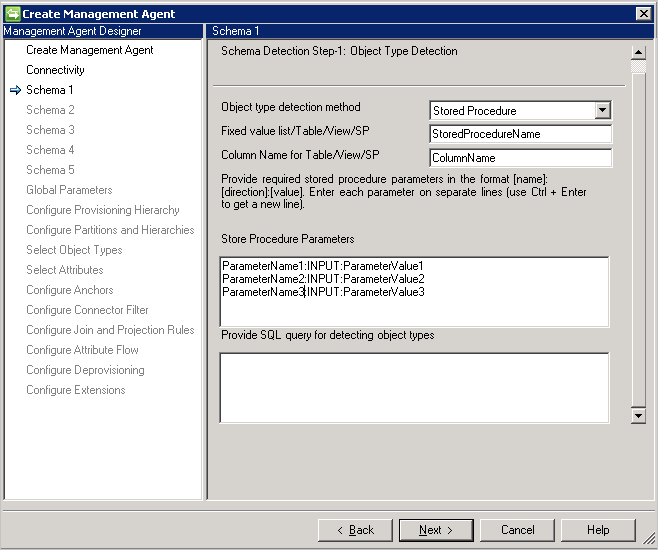
-
Zapytanie SQL: ta opcja umożliwia podanie zapytania SQL zwracającego pojedynczą kolumnę z typami obiektów, na przykład
SELECT [Column Name] FROM TABLENAME. Zwracana kolumna musi być ciągiem typu (varchar).
Schemat 2 (Wykrywanie typów atrybutów)
Na tej stronie skonfigurujesz sposób wykrywania nazw atrybutów i typów. Opcje konfiguracji są wyświetlane dla każdego typu obiektu wykrytego na poprzedniej stronie.
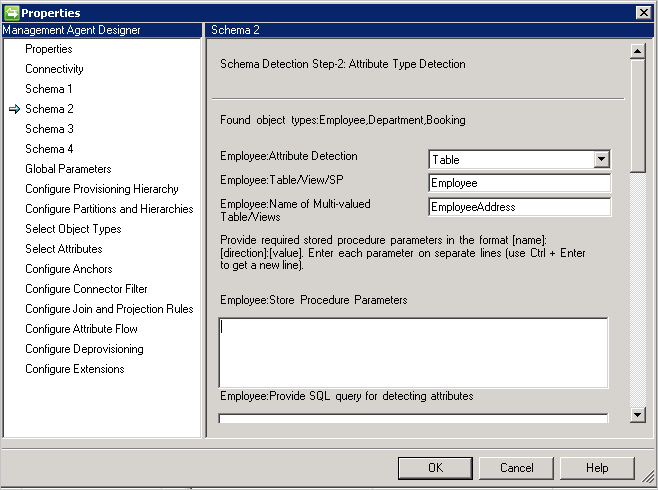
Metoda wykrywania typu atrybutu: Łącznik obsługuje te metody wykrywania typów atrybutów z każdym wykrytym typem obiektu na ekranie Schemat 1.
- Tabela/Widok/Procedura składowana: podaj nazwę tabeli/widoku/procedury składowanej, która powinna być używana do znajdowania nazw atrybutów. Jeśli używasz procedury składowanej, podaj również parametry dla niego w formacie [Name]:[Direction]:[Value]. Podaj każdy parametr w osobnym wierszu (użyj Ctrl+Enter, aby uzyskać nowy wiersz). Aby wykryć nazwy atrybutów w atrybucie wielowartościowym, podaj rozdzielaną przecinkami listę tabel lub widoków. Scenariusze z wieloma wartościami nie są obsługiwane, gdy tabela nadrzędna i podrzędna mają takie same nazwy kolumn.
-
Zapytanie SQL: ta opcja umożliwia podanie zapytania SQL zwracającego jedną kolumnę z nazwami atrybutów, na przykład
SELECT [Column Name] FROM TABLENAME. Zwracana kolumna musi być ciągiem typu (varchar).
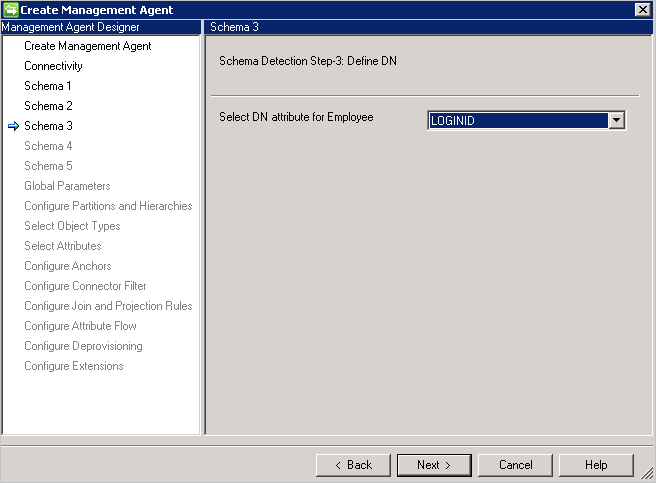
Schemat 3 (Definiowanie kotwicy i DN)
Ta strona umożliwia konfigurację atrybutu kotwicy oraz DN dla każdego wykrytego typu obiektu. Możesz wybrać wiele atrybutów, aby ustawić unikatowość kotwicy.
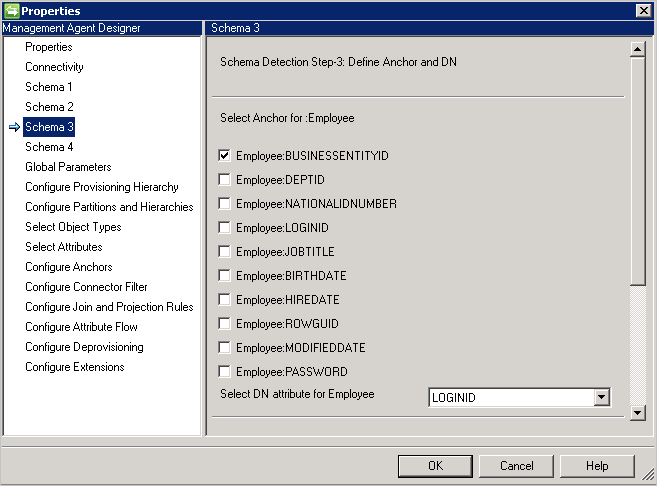
Atrybuty wielowartościowe i logiczne nie są wyświetlane.
Ten sam atrybut nie może być używany dla DN i kotwicy, chyba że opcja DN jest kotwicą jest zaznaczona na stronie Łączność.
Jeśli na stronie Łączność jest wybrana opcja Kotwica , ta strona wymaga tylko atrybutu DN. Ten atrybut będzie również używany jako atrybut kotwicy.
Schemat 4 (Definiowanie typu atrybutu, odwołania i kierunku)
Ta strona umożliwia skonfigurowanie typu atrybutu, takiego jak liczba całkowita, binarna lub wartość logiczna oraz kierunek dla każdego atrybutu. Wszystkie atrybuty z schematu 2 strony są wymienione, w tym atrybuty wielowartościowe.
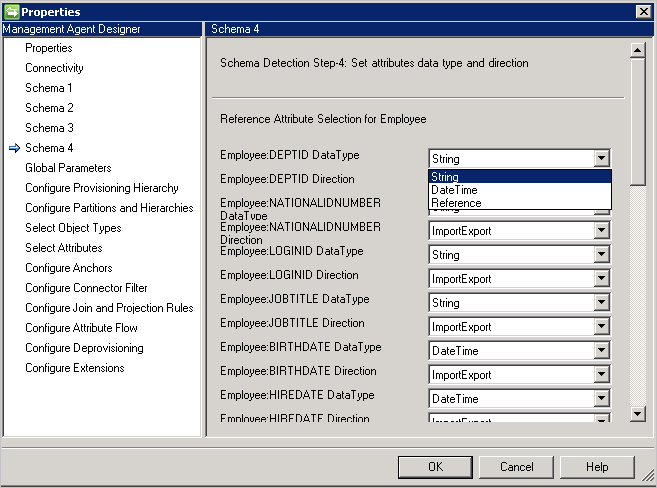
- DataType: służy do mapowania typu atrybutu na typy znane przez aparat synchronizacji. Wartością domyślną jest użycie tego samego typu co wykryte w schemacie SQL, ale funkcja DateTime i Reference nie jest łatwo wykrywalna. W przypadku tych opcji należy określić DateTime lub Referencja.
- Kierunek: możesz ustawić kierunek atrybutu na Import, Export lub ImportExport. ImportExport jest domyślny.
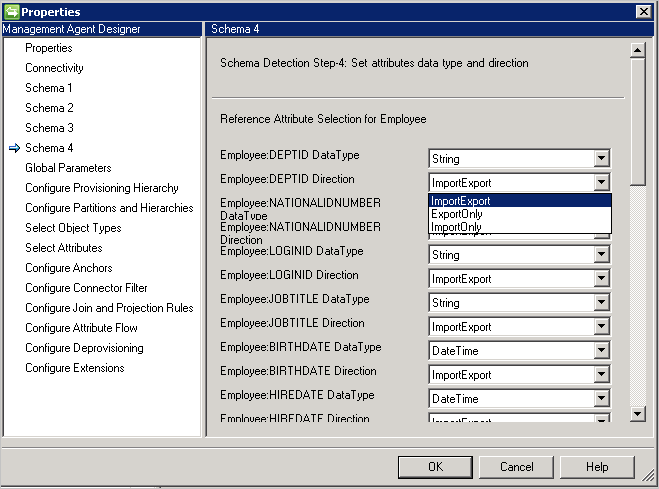
Uwagi:
- Jeśli typ atrybutu nie jest wykrywalny przez Łącznik, używa typu danych String.
- Zagnieżdżone tabele można uważać za tabele bazy danych z jedną kolumną. Oracle przechowuje wiersze zagnieżdżonej tabeli w nieokreślonej kolejności. Jednak podczas pobierania zagnieżdżonej tabeli do zmiennej PL/SQL wiersze otrzymują kolejne indeksy podrzędne rozpoczynające się od 1. Zapewnia to dostęp przypominający tablicę do poszczególnych wierszy.
- Funkcja VARRYS nie jest obsługiwana w łączniku.
Schemat 5 (Definiowanie partycji dla atrybutów referencyjnych)
Na tej stronie skonfigurujesz wszystkie atrybuty referencyjne, do których odwołuje się partycja (typ obiektu).
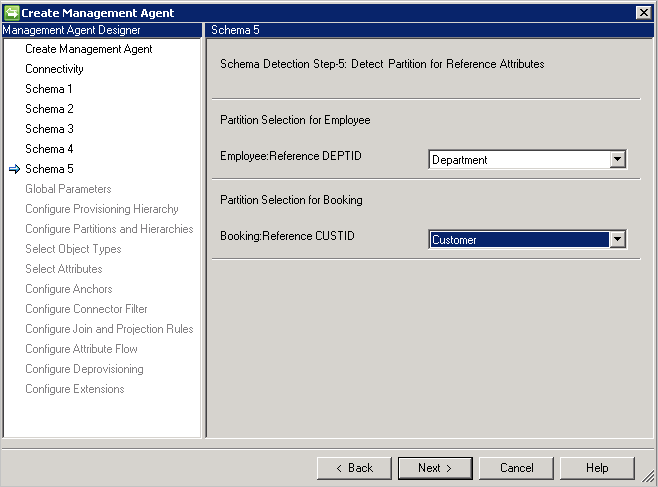
Jeśli używasz DN is anchor, musisz użyć tego samego typu obiektu, z którego się korzysta jako punktu odniesienia. Nie można odwołać się do innego typu obiektu.
Uwaga
Począwszy od aktualizacji z marca 2017 r. jest teraz dostępna opcja "*" Po wybraniu tej opcji wszystkie możliwe typy elementów członkowskich zostaną zaimportowane.
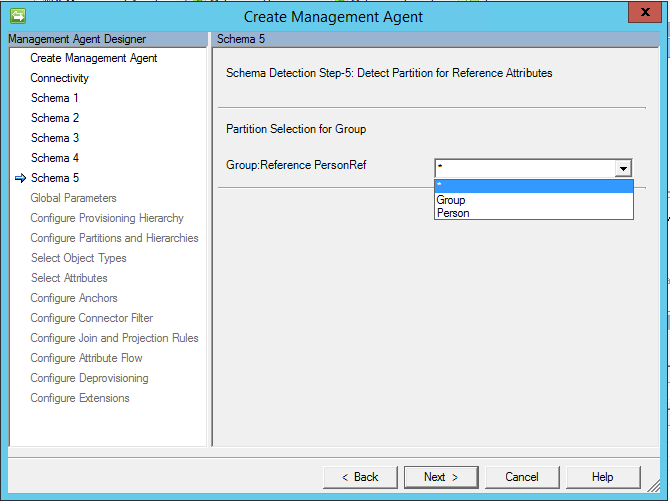
Ważne
Od maja 2017 roku opcja "*", znana także jako dowolna opcja, została zmieniona, aby obsługiwać przepływ importu i eksportu. Jeśli chcesz użyć tej opcji, tabela/widok wielowartych powinien mieć atrybut zawierający typ obiektu.

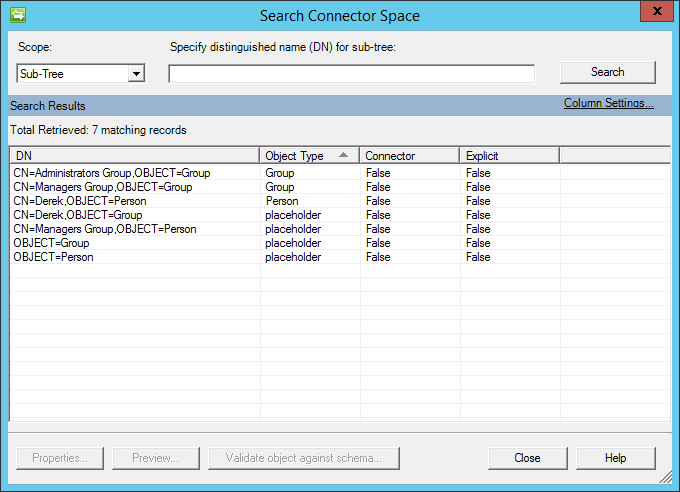
Jeśli wybrano "*", należy również określić nazwę kolumny z typem obiektu.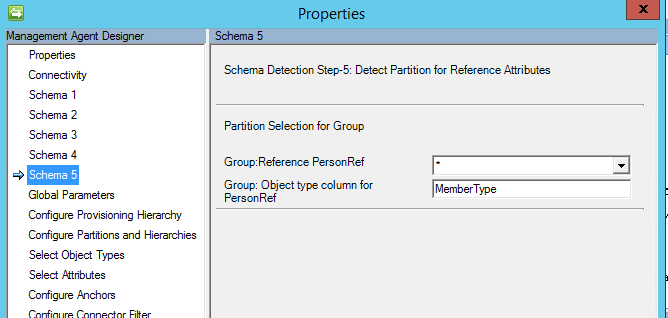
Po zaimportowaniu zobaczysz coś podobnego do poniższego obrazu:
Parametry globalne
Strona Parametry globalne służy do konfigurowania Import delta, formatu daty/godziny oraz metody hasła.
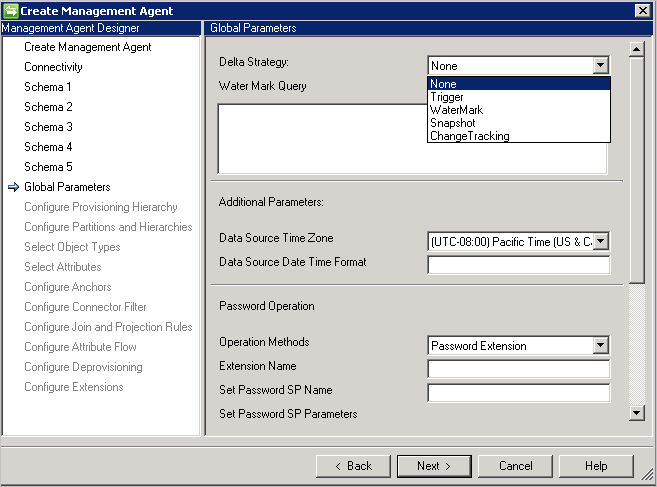
Łącznik Generic SQL Connector obsługuje następujące metody dla Delta Import:
- Wyzwalacz: zobacz Generowanie widoków różnicowych przy użyciu wyzwalaczy.
-
Znak wodny: uniwersalne podejście, które może być używane z dowolną bazą danych. Zapytanie znaku wodnego jest wstępnie wypełniane na podstawie dostawcy bazy danych. Kolumna znaku wodnego musi być obecna w każdej stosowanej tabeli/widoku. Ta kolumna musi śledzić wstawienia i aktualizacje tabel oraz ich zależnych (wielowartościowych lub podrzędnych) tabel. Zegary między usługą synchronizacji a serwerem bazy danych muszą być zsynchronizowane. Jeśli nie, niektóre wpisy w imporcie różnicowym mogą zostać pominięte.
Ograniczenie:- Strategia znaku wodnego nie obsługuje usuniętych obiektów.
- Migawka: (działa tylko z Microsoft SQL Server) Tworzenie widoków delta za pomocą migawek
-
Śledzenie zmian: (działa tylko z programem Microsoft SQL Server) Informacje o śledzeniu zmian
Ograniczenia:- Atrybut Anchor & DN musi być częścią klucza podstawowego dla wybranego obiektu w tabeli.
- Zapytanie SQL nie jest obsługiwane podczas importowania i eksportowania za pomocą funkcji Change Tracking.
Dodatkowe parametry: określ strefę czasową serwera bazy danych wskazującą, gdzie znajduje się serwer bazy danych. Ta wartość służy do obsługi różnych formatów atrybutów daty i godziny.
Łącznik zawsze przechowuje datę i godzinę w formacie UTC. Aby można było poprawnie przekonwertować datę i godziny, należy określić strefę czasową serwera bazy danych i używany format. Format powinien być wyrażony w formacie .NET.
Podczas eksportowania każdego atrybutu daty/godziny należy podać łącznikowi w formacie czasu UTC.
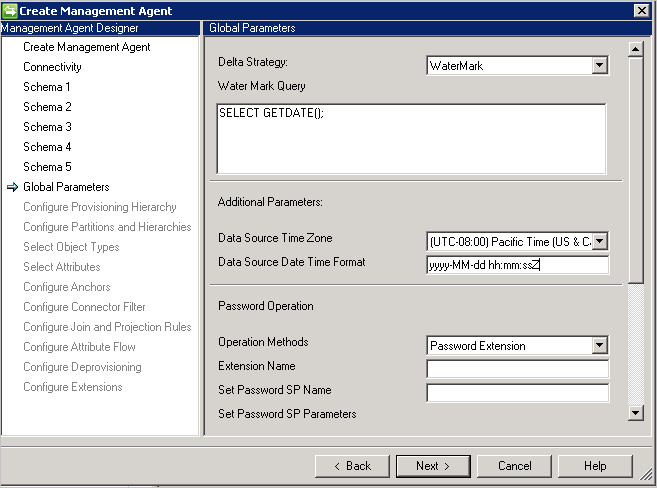
Konfiguracja hasła: łącznik zapewnia funkcje synchronizacji haseł i obsługuje ustawianie i zmienianie hasła.
Łącznik udostępnia dwie metody obsługi synchronizacji haseł:
-
Procedura składowana: ta metoda wymaga dwóch procedur składowanych do obsługi ustawiania i zmieniania hasła. Wpisz wszystkie parametry dla operacji dodawania i zmiany hasła w Set Password SP i Change Password SP odpowiednio, zgodnie z poniższym przykładem.
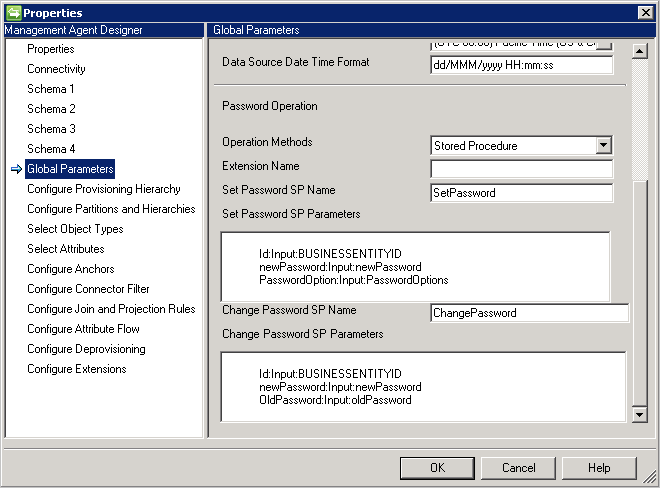
-
Rozszerzenie hasła: ta metoda wymaga biblioteki DLL rozszerzenia hasła (należy podać nazwę biblioteki DLL rozszerzenia, która implementuje interfejs IMAExtensible2Password). Zestaw rozszerzenia haseł należy umieścić w folderze rozszerzenia, aby łącznik mógł załadować bibliotekę DLL podczas działania.
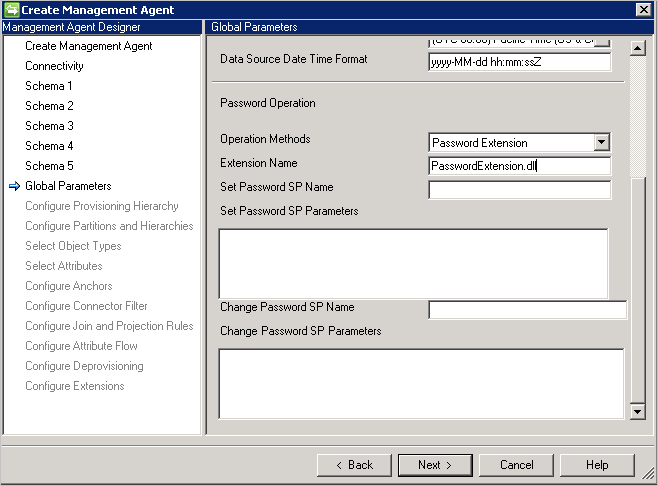
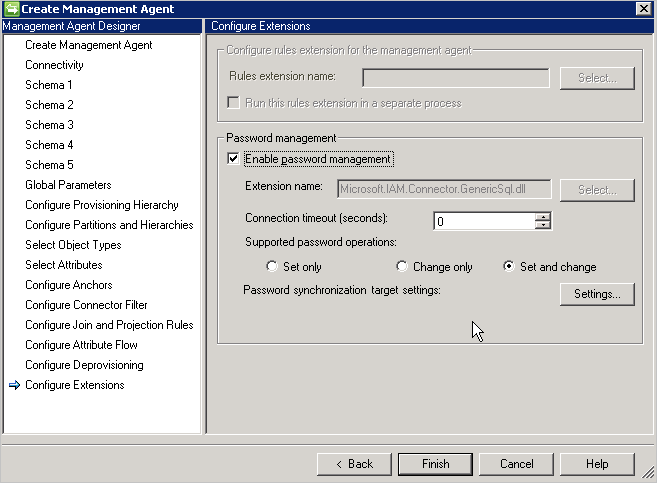
Należy również włączyć zarządzanie hasłami na stronie Konfigurowanie rozszerzenia .
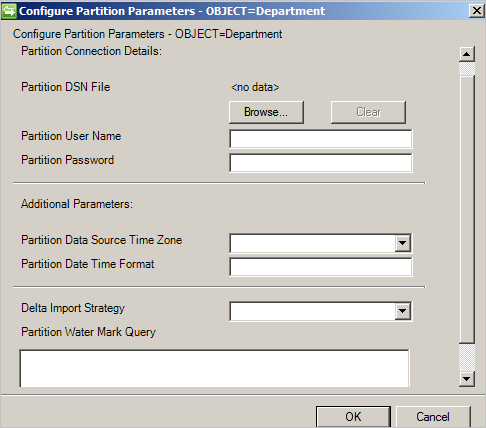
Konfiguruj partycje i hierarchie
Na stronie Partycje i hierarchie wybierz wszystkie typy obiektów. Każdy typ obiektu jest własną partycją.
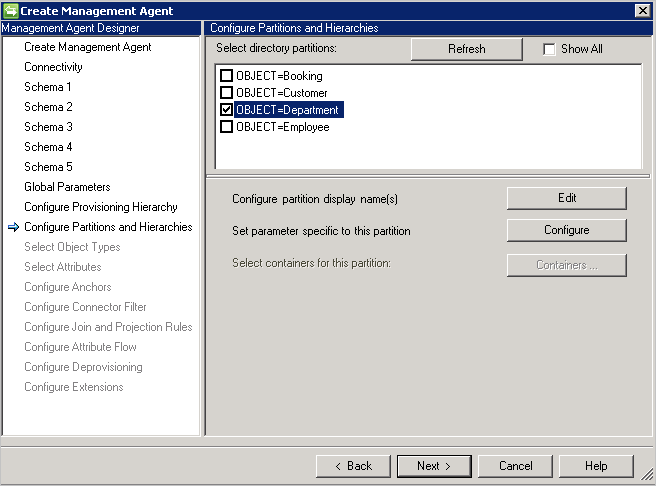
Można również nadpisać wartości zdefiniowane na stronie Łączność lub Parametry globalne.
Konfiguruj zakotwiczenia
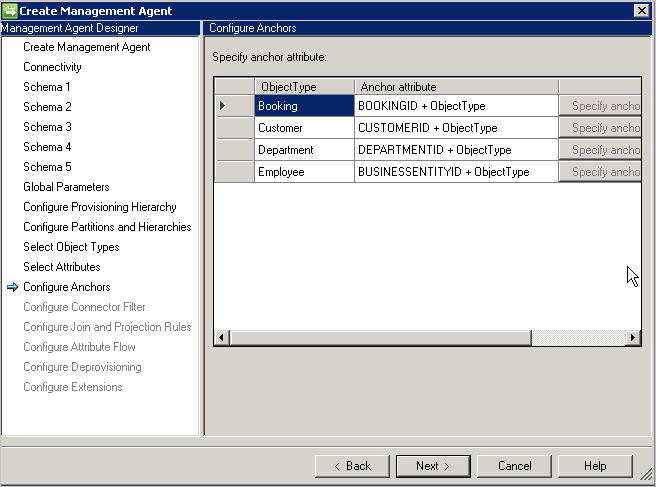
Ta strona jest tylko do odczytu, ponieważ kotwica została już zdefiniowana. Wybrany atrybut kotwicy jest zawsze dołączany z typem obiektu, aby upewnić się, że pozostaje unikatowy w różnych typach obiektów.
Konfigurowanie parametru kroku uruchamiania
Te kroki są konfigurowane w profilach uruchamiania w łączniku. Te konfiguracje wykonują rzeczywistą pracę podczas importowania i eksportowania danych.
Importowanie pełne i różnicowe
Ogólne łączniki SQL obsługują importowanie pełne i różnicowe przy użyciu następujących metod:
- Stół
- Widok
- Procedura składowana
- Zapytanie SQL
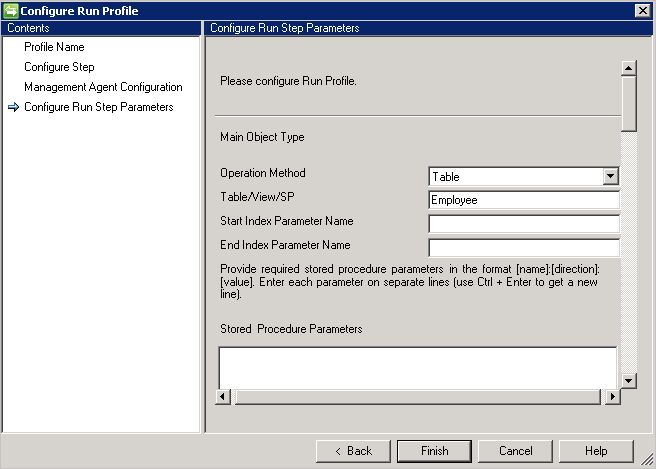
Tabela/widok
Aby zaimportować atrybuty wielowartościowe dla obiektu, należy podać nazwę tabeli/widoków w polu Nazwa tabeli/widoków wielowartościowych i odpowiednie warunki sprzężenia w warunku sprzężenia z tabelą nadrzędną. Jeśli w źródle danych znajduje się więcej niż jedna tabela z wieloma wartościami, możesz użyć operacji łączenia (union), aby stworzyć jeden widok.
Ważne
Ogólny agent zarządzania SQL może pracować tylko z jedną tabelą wielowartej. Nie umieszczaj więcej niż jednej nazwy tabeli w nazwie tabeli lub widoków wielowartościowych. Jest to ograniczenie ogólnego języka SQL.
Przykład: chcesz zaimportować obiekt Employee i wszystkie jego atrybuty wielowartościowe. Istnieją dwie tabele o nazwach Pracownik (tabela główna) i Działy (tabela wielowartościowa). Należy wykonać następujące czynności:
- Wpisz Employee in Table/View/SP (Pracownik w tabeli/widoku/sp).
- Wpisz Dział w polu Nazwa tabeli/widoków wielowartościowych.
- Wprowadź warunek połączenia między pracownikiem a działem w polu Warunek sprzężenia, na przykład
Employee.DEPTID=Department.DepartmentID.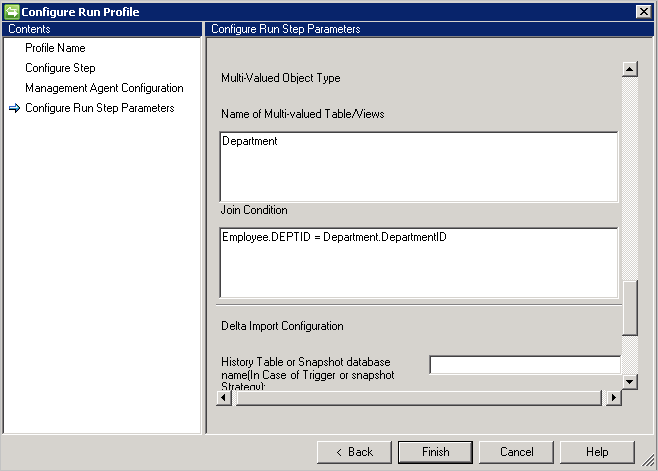
Procedury składowane
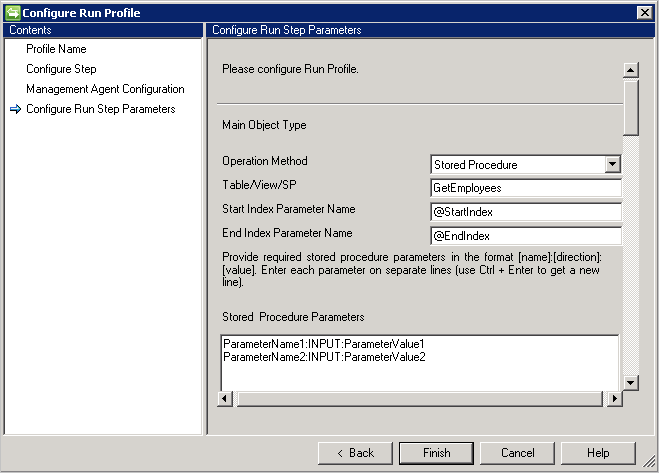
- Jeśli masz dużo danych, zaleca się zaimplementowanie stronicowania przy użyciu procedur składowanych.
- Aby procedura składowana obsługiwała stronicowanie, należy podać indeks początkowy i indeks końcowy. Zobacz: Efektywne przeglądanie dużych ilości danych.
- @StartIndex i @EndIndex są zastępowane w czasie wykonywania odpowiednimi wartościami rozmiaru strony skonfigurowanymi na stronie Konfigurowanie kroku . Na przykład gdy łącznik pobiera pierwszą stronę i rozmiar strony jest ustawiony na 500, w takiej sytuacji @StartIndex będzie to 1 i @EndIndex 500. Te wartości zwiększają się, gdy połączenie pobiera kolejne strony i zmienia wartości @StartIndex oraz @EndIndex.
- Aby wykonać sparametryzowaną procedurę składowaną, podaj parametry w formacie
[Name]:[Direction]:[Value]. Wprowadź każdy parametr w osobnym wierszu (użyj Ctrl + Enter, aby uzyskać nowy wiersz). - Ogólny łącznik SQL obsługuje również operację importowania z serwerów połączonych w programie Microsoft SQL Server. Jeśli informacje powinny zostać pobrane z tabeli na serwerze połączonym, tabela powinna być podana w formacie:
[ServerName].[Database].[Schema].[TableName] - Ogólny łącznik SQL Obsługuje tylko te obiekty, które mają podobną strukturę (zarówno nazwę aliasu, jak i typ danych) między informacjami o krokach uruchamiania i wykrywaniem schematu. Jeśli wybrany obiekt ze schematu i podane informacje w kroku uruchamiania są inne, łącznik SQL nie może obsługiwać tego typu scenariuszy.
Zapytanie SQL
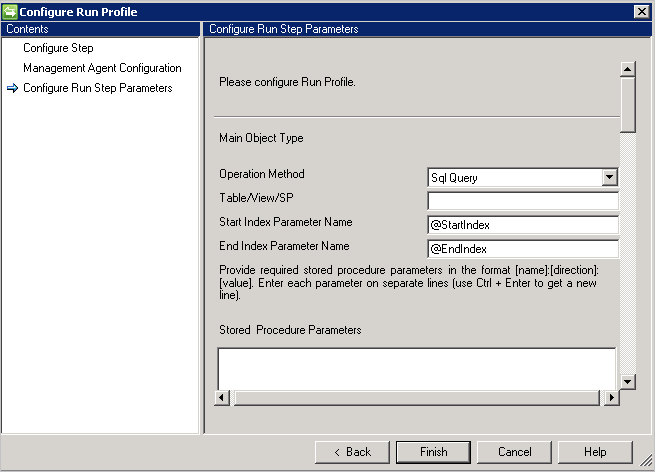
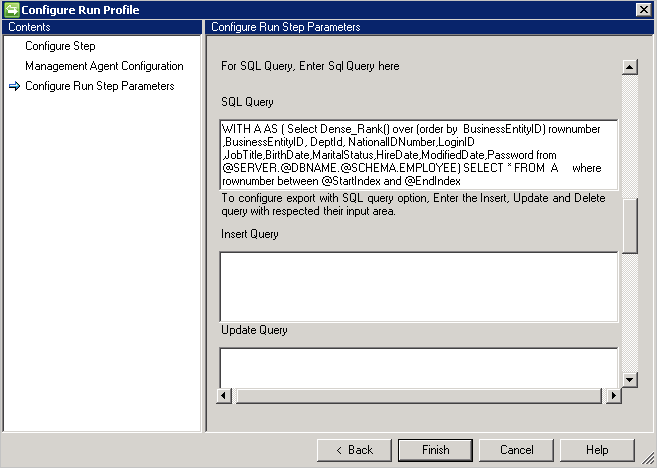
Ważne
Znak CRLF lub znak nowej linii służy jako separator między wieloma oświadczeniami.
Przykładowe zapytanie SQL z paginacją — nieprawidłowe zapytanie nie będzie działać, ponieważ używany jest znak nowej linii:
WITH A AS
(select dense_rank() over (order by BusinessEntityID)
rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password
from Employees
) select * from A where rownumber between @StartIndex and @EndIndex
Przykładowe zapytanie SQL z podziałem na strony — poprawne zapytanie:
WITH A AS (select dense_rank() over (order by BusinessEntityID) rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password from Employees) select * from A where rownumber between @StartIndex and @EndIndex
- Zapytania zwracające wiele zestawów wyników nie są obsługiwane.
- Zapytanie SQL obsługuje stronicowanie i udostępnia indeks początkowy i indeks końcowy jako zmienną do obsługi stronicowania.
Import zmian
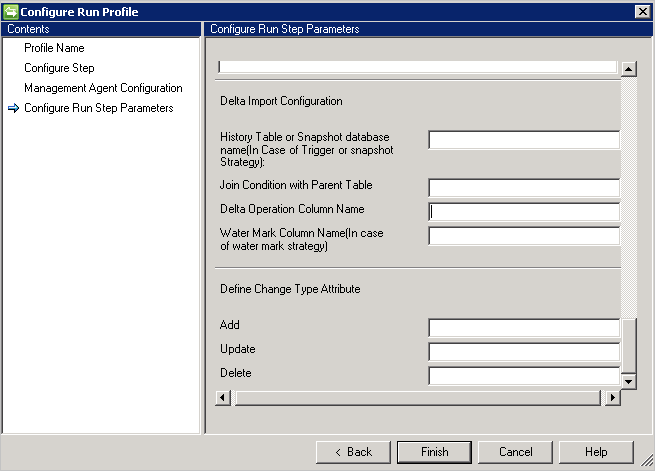
Konfiguracja importu różnicowego wymaga dodatkowej konfiguracji w porównaniu z importem całkowitym.
- Jeśli wybierzesz metodę Wyzwalacz lub Migawka w celu śledzenia zmian różnicowych, podaj tabelę historii lub bazę danych migawek w polu Historia tabeli lub nazwy bazy danych migawki.
- Należy również podać warunek sprzężenia między tabelą Historia i tabelą nadrzędną, na przykład
Employee.ID=History.EmployeeID - Aby śledzić transakcję w tabeli nadrzędnej z tabeli historii, należy podać nazwę kolumny zawierającą informacje o operacji (Add/Update/Delete).
- Jeśli wybierzesz opcję Znak wodny do śledzenia zmian różnicowych, podaj nazwę kolumny zawierającą informacje o operacji w Nazwa kolumny znaku wodnego.
- Kolumna atrybutu typu zmiany jest wymagana dla typu zmiany. Ta kolumna odwzorowuje zmianę, która zachodzi w tabeli podstawowej lub tabeli wielowartościowej, na typ zmiany w widoku różnicowym. Ta kolumna może zawierać typ zmiany Modify_Attribute, dotyczący zmian na poziomie atrybutu, lub typ zmiany na poziomie obiektu, taki jak Dodaj, Modyfikuj lub Usuń. Jeśli jest to coś innego niż wartość domyślna Dodaj, Modyfikuj lub Usuń, możesz zdefiniować te wartości przy użyciu tej opcji.
Export
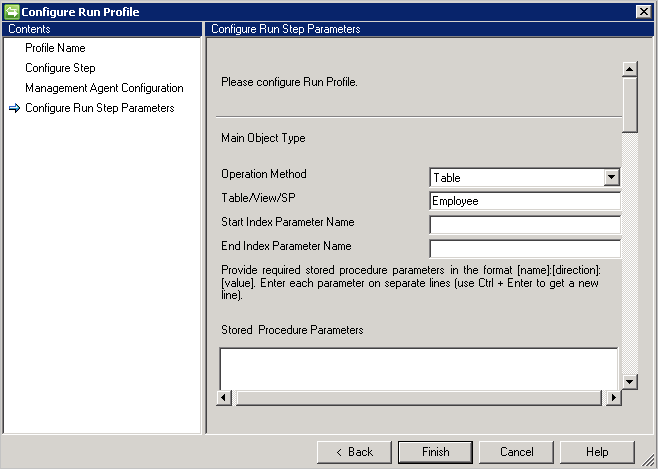
Ogólny łącznik SQL obsługuje eksportowanie przy użyciu czterech obsługiwanych metod, takich jak:
- Table
- Widok
- Procedura składowana
- Zapytanie SQL
Tabela/widok
Jeśli wybierzesz opcję Tabela/Widok, łącznik wygeneruje odpowiednie zapytania, aby wykonać eksportowanie.
Procedury składowane
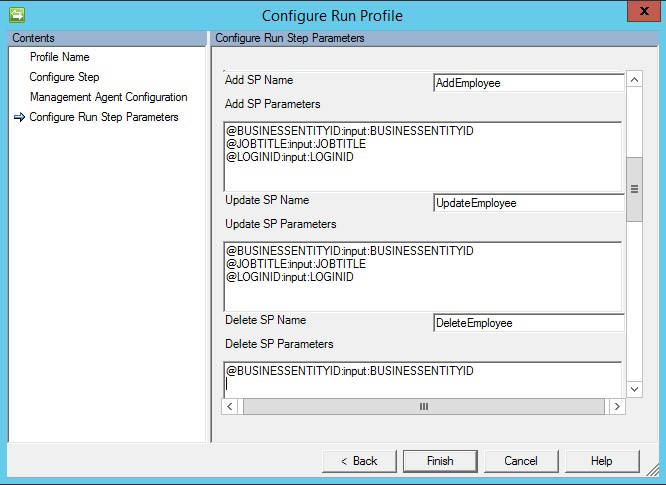
W przypadku wybrania opcji Procedura składowana eksport wymaga wykonania trzech różnych procedur składowanych w celu wykonania operacji wstawiania/aktualizowania/usuwania.
- Dodaj nazwę SP: ten SP działa, jeśli jakikolwiek obiekt jest przekazywany do łącznika w celu dodania do odpowiedniej tabeli.
- Aktualizacja nazwy procedury składowanej: Ta procedura składowana działa, jeśli jakikolwiek obiekt jest przesyłany do łącznika w celu aktualizacji w odpowiedniej tabeli.
- Usuń nazwę SP: Ten SP działa, jeśli jakikolwiek obiekt zostanie przekazany do połączenia w celu usunięcia w odpowiedniej tabeli.
- Atrybut wybrany ze schematu używany jako wartość parametru do procedury składowanej. Na przykład
@EmployeeName: INPUT: EmployeeName(EmployeeName jest zaznaczone w schemacie łącznika, a łącznik zastępuje tą wartość podczas eksportowania) - Aby uruchomić sparametryzowaną procedurę składowaną, podaj parametry w formacie
[Name]:[Direction]:[Value]. Wprowadź każdy parametr w osobnym wierszu (użyj Ctrl + Enter, aby uzyskać nowy wiersz).
Zapytanie SQL
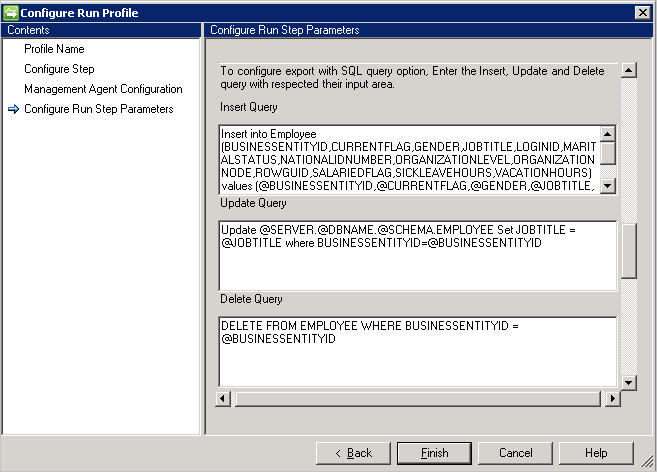
Jeśli wybierzesz opcję zapytania SQL, funkcja Eksportuj wymaga wykonania trzech różnych zapytań w celu wykonania operacji wstawiania/aktualizowania/usuwania.
- Wstaw zapytanie: to zapytanie jest uruchamiane, jeśli jakikolwiek obiekt przychodzi do łącznika w celu wstawiania w odpowiedniej tabeli.
- Zapytanie aktualizacji: To zapytanie jest uruchamiane, jeśli jakikolwiek obiekt przychodzi do łącznika do aktualizacji w właściwej tabeli.
- Usuń zapytanie: to zapytanie jest uruchamiane, jeśli jakikolwiek obiekt zostanie przesłany do łącznika w celu usunięcia w odpowiadającej tabeli.
- Atrybut wybrany ze schematu używany jako wartość parametru do zapytania, na przykład
Insert into Employee (ID, Name) Values (@ID, @EmployeeName)
Ważne
Znak CRLF lub znak nowego wiersza służy jako separator między wieloma instrukcjami.
Przykładowe zapytanie SQL z aktualizacją wieloetapową — znak nowego wiersza używany do oddzielania instrukcji SQL:
update Employee set jobTitle=@JOBTITLE where BusinessEntityID=@BUSINESSENTITYID
insert into ChangeLog VALUES (@BUSINESSENTITYID)
Rozwiązywanie problemów
- Aby uzyskać informacje na temat włączania rejestrowania w celu rozwiązywania problemów z łącznikiem, zobacz How to Enable ETW Tracing for Connectors (Jak włączyć śledzenie ETW dla łączników).