Używanie wstępnie utworzonego modelu do wyodrębniania informacji z prostych dokumentów w Microsoft Syntex
Prosty model przetwarzania dokumentów oferuje elastyczne, wstępnie wytrenowane rozwiązanie do wyodrębniania informacji z podstawowych dokumentów strukturalnych, w tym informacje takie jak:
Pary klucz-wartość — pomyśl o nich jak o etykietach i odpowiadających im informacjach, takich jak "Name: Adele Vance".
Znaczniki wyboru — są to pola wyboru lub inne znaczniki wskazujące opcje lub zaznaczenia w dokumencie.
Nazwane jednostki — są to określone elementy, takie jak nazwy osób, miejsc lub organizacji wymienionych w tekście dokumentu.
Kody kreskowe — są to czytelne dla komputera reprezentacje danych, których można użyć do śledzenia lub identyfikacji w dokumencie.
W przeciwieństwie do innych wstępnie utworzonych modeli ze stałymi schematami, ten model może identyfikować klucze, których inni mogą przegapić, zapewniając cenną alternatywę dla niestandardowego etykietowania i trenowania modelu. Ten model obsługuje również kody kreskowe i wykrywanie języka.
Typy dokumentów
Proste przetwarzanie dokumentów najlepiej sprawdza się w przypadku typów dokumentów zawierających informacje ustrukturyzowane, takie jak:
Forms — często mają jasne pola i etykiety, co ułatwia wyodrębnianie par klucz-wartość.
Faktury — zazwyczaj obejmują spójne układy z tabelami i parami klucz-wartość.
Paragony — podobnie jak faktury, mają ustrukturyzowane dane, które można łatwo wyodrębnić.
Kontrakty — zawierają dobrze zdefiniowane sekcje i klauzule, które można efektywnie przeanalizować.
Wyciągi bankowe — uwzględnij tabele i dane ustrukturyzowane, które są idealne do wyodrębniania.
Te dokumenty korzystają z możliwości optycznego rozpoznawania znaków (OCR) i procesów uczenia głębokiego używanych do wyodrębniania par klucz-wartość, znaczników wyboru, tabel i nazwanych jednostek.
Uwaga
Obecnie ten model jest dostępny dla typów plików .pdf i obrazów oraz w ponad 100 językach. Więcej obsługiwanych typów plików zostanie dodanych w przyszłych wersjach.
Aby użyć prostego modelu przetwarzania dokumentów, wykonaj następujące kroki:
- Krok 1. Tworzenie modelu
- Krok 2. Przekazywanie przykładu pliku do analizy
- Krok 3. Wybieranie wyodrębniaczy dla modelu
- Krok 4. Stosowanie modelu
Krok 1. Tworzenie modelu
Postępuj zgodnie z instrukcjami w temacie Tworzenie modelu w aplikacji Syntex , aby utworzyć prosty model przetwarzania dokumentów. Następnie wykonaj następujące kroki, aby ukończyć model.
Krok 2. Przekazywanie przykładu pliku do analizy
Na stronie Modele w sekcji Dodawanie pliku do analizy wybierz pozycję Dodaj plik.
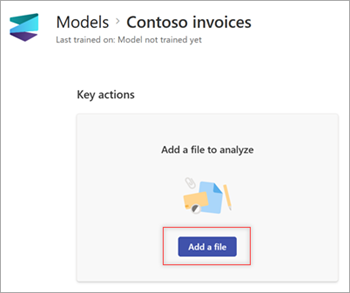
Na stronie Pliki do analizowania modelu wybierz pozycję Dodaj , aby znaleźć plik, którego chcesz użyć.
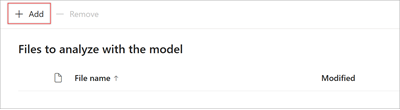
Na stronie Dodawanie pliku z biblioteki plików szkoleniowych wybierz plik, a następnie wybierz pozycję Dodaj.
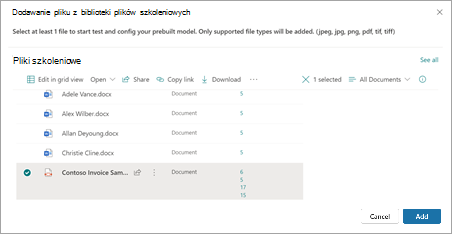
Na stronie Pliki do analizy modelu wybierz pozycję Dalej.
Krok 3. Wybieranie wyodrębniaczy dla modelu
Na stronie szczegółów wyodrębniacza widoczny jest obszar dokumentu po prawej stronie i panel Extractors po lewej stronie. Na panelu Extractors jest wyświetlana lista wyodrębniaczy, które zostały zidentyfikowane w dokumencie.
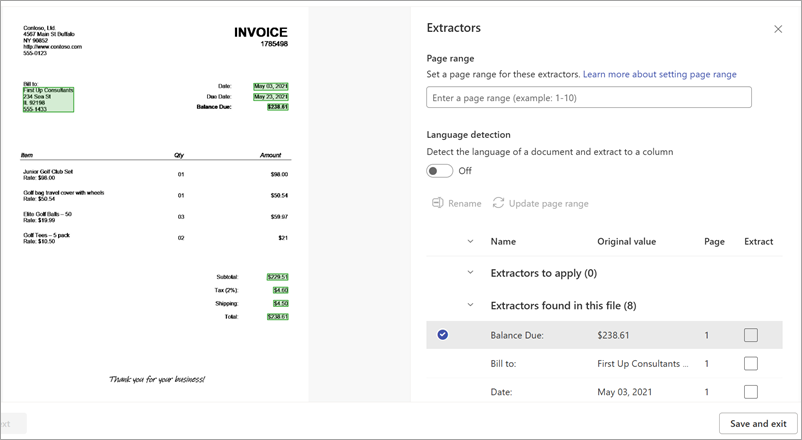
Pola jednostek wyróżnione na zielono w obszarze dokumentu to elementy, które zostały wykryte przez model podczas analizowania pliku. Po wybraniu jednostki do wyodrębnienia wyróżnione pole zmieni kolor na niebieski. Jeśli później zdecydujesz się nie uwzględniać jednostki, wyróżnione pole zmieni się na szare. Wyróżnienia ułatwiają wyświetlanie bieżącego stanu wybranych wyodrębniaczy.
Porada
Aby powiększać lub pomniejszać pola jednostki, użyj kółka przewijania myszy lub kontrolek powiększenia w dolnej części obszaru dokumentu.
Wybieranie jednostki wyodrębniacza
W zależności od preferencji możesz wybrać wyodrębniacz z obszaru dokumentu lub z panelu Wyodrębniacze .
- Aby wybrać wyodrębniacz z obszaru dokumentu, wybierz pole jednostki.
- Aby wybrać wyodrębniacz z panelu Extractors , w kolumnie Wyodrębnij zaznacz odpowiednie pole wyboru po prawej stronie nazwy jednostki.
Po wybraniu ekstraktora w obszarze dokumentu zostanie wyświetlone pole Wybierz wyodrębniacz? Pole zawiera nazwę klucza (nazwę wygenerowaną dla wyodrębniacza), wykrytą wartość (wartość tego pola w dokumencie), typ kolumny i opcję wybrania jednostki jako wyodrębniacza.
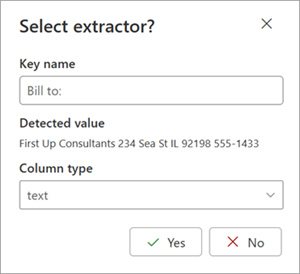
Nazwa klucza jest używana jako nazwa kolumny, gdy model jest stosowany do biblioteki programu SharePoint. Jeśli chcesz, możesz zmienić nazwę klucza na bardziej opisową. Typ kolumny przedstawia sposób wyświetlania informacji w bibliotece. Możesz zmienić typ kolumny, aby pokazać, jak mają być wyświetlane informacje. Gdy model jest stosowany do biblioteki, możesz użyć formatowania kolumn, aby określić, jak ma wyglądać w dokumencie.
Kontynuuj wybieranie innych wyodrębniaczy, których chcesz użyć. Możesz również dodać inne pliki do analizy pod kątem tej konfiguracji modelu.
Zmień nazwę ekstraktora
Istnieją trzy sposoby zmiany nazwy wyodrębniacza:
W obszarze dokumentu na stronie szczegółów ekstraktora wybierz pole jednostki. W polu Wybierz wyodrębniacz? w polu Nazwa klucza wprowadź nową nazwę dla wyodrębniacza.
Na panelu Wyodrębniacze na stronie szczegółów ekstraktora wybierz wyodrębniacz, który chcesz zmienić nazwę, a następnie wybierz pozycję Zmień nazwę.
Na stronie głównej modelu w sekcji Extractors (Wyodrębniacze ) wybierz wyodrębniacz, który chcesz zmienić nazwę, a następnie wybierz pozycję Zmień nazwę.
Ustawianie zakresu stron na potrzeby przetwarzania
Dla tego modelu można określić, aby przetworzyć zakres stron dla pliku, a nie całego pliku. Na panelu Wyodrębniacze w sekcji Zakres stron wybierz stronę, którą chcesz przetworzyć. Domyślnie ustawienie Zakres stron jest puste. Jeśli nie podano zakresu stron, cały dokument jest przetwarzany. Aby uzyskać więcej informacji, zobacz Ustawianie zakresu stron w celu wyodrębnienia informacji z określonych stron.
Wykrywanie języka dokumentu
W przypadku tego modelu można wykryć język dokumentu i wyodrębnić go do kolumny. Na panelu Wyodrębniacze w sekcji Wykrywanie języka przełącz, aby włączyć wykrywanie języka. Pokazuje kod ISO wykrytego języka.

Wykrywanie języka można również włączyć lub wyłączyć z panelu Ustawienia modelu dla modelu.
Krok 4. Stosowanie modelu
Aby zapisać zmiany i wrócić do strony głównej modelu, na panelu Extractors wybierz pozycję Zapisz i zakończ.
Jeśli wszystko jest gotowe do zastosowania modelu do biblioteki, w obszarze dokumentu wybierz pozycję Dalej. Na panelu Dodaj do biblioteki wybierz bibliotekę, do której chcesz dodać model, a następnie wybierz pozycję Dodaj.