series_fit_2lines()
Dotyczy: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Stosuje dwie segmenty regresji liniowej w serii, zwracając wiele kolumn.
Przyjmuje wyrażenie zawierające dynamiczną tablicę liczbową jako dane wejściowe i stosuje regresję liniową z dwoma segmentami w celu zidentyfikowania i oszacowania zmiany trendu w serii. Funkcja iteruje indeksy serii. W każdej iteracji funkcja dzieli serię na dwie części, pasuje do oddzielnej linii (przy użyciu series_fit_line()) do każdej części i oblicza łączną liczbę r-kwadrat. Najlepszym podziałem jest ten, który zmaksymalizował r-kwadrat; funkcja zwraca parametry:
| Parametr | Opis |
|---|---|
rsquare |
R-square jest standardową miarą jakości dopasowania. Jest to liczba w zakresie [0–1], gdzie 1 — jest najlepszym możliwym dopasowaniem, a 0 oznacza, że dane są nieurządkowane i nie pasują do żadnej linii. |
split_idx |
Indeks punktu przerwania do dwóch segmentów (opartych na zerach). |
variance |
Wariancja danych wejściowych. |
rvariance |
Wariancja reszt, która jest wariancją między wartościami danych wejściowych przybliżonymi wartościami (według dwóch segmentów linii). |
line_fit |
Tablica liczbowa zawierająca serię wartości najlepiej dopasowanej linii. Długość serii jest równa długości tablicy wejściowej. Jest ona używana głównie do tworzenia wykresów. |
right_rsquare |
R kwadrat linii po prawej stronie podziału, zobacz series_fit_line(). |
right_slope |
Nachylenie prawej przybliżonej linii (formularza y=ax+b). |
right_interception |
Przechwycenie przybliżonej lewej linii (b z y=ax+b). |
right_variance |
Wariancja danych wejściowych po prawej stronie podziału. |
right_rvariance |
Odchylenie reszt danych wejściowych po prawej stronie podziału. |
left_rsquare |
R kwadrat linii po lewej stronie podziału, zobacz series_fit_line(). |
left_slope |
Nachylenie lewej przybliżonej linii (formularza y=ax+b). |
left_interception |
Przechwycenie przybliżonej lewej linii (formularza y=ax+b). |
left_variance |
Wariancja danych wejściowych po lewej stronie podziału. |
left_rvariance |
Odchylenie reszt danych wejściowych po lewej stronie podziału. |
Uwaga
Ta funkcja zwraca wiele kolumn, więc nie można jej użyć jako argumentu dla innej funkcji.
Składnia
seria projektów series_fit_2lines()
Dowiedz się więcej na temat konwencji składni.
- Zwróci wszystkie wymienione powyżej kolumny o następujących nazwach: series_fit_2lines_x_rsquare, series_fit_2lines_x_split_idx itp.
project (rs, si, v)=series_fit_2lines(series)
- Zwróci następujące kolumny: rs (r-square), si (indeks podzielony), v (wariancja) i pozostałe będą wyglądać jak series_fit_2lines_x_rvariance, series_fit_2lines_x_line_fit itd.
extend (rs, si, v)=series_fit_2lines(series)
- Zwróci tylko: rs (r-square), si (indeks podzielony) i v (wariancja).
Parametry
| Nazwisko | Type | Wymagania | opis |
|---|---|---|---|
| seria | dynamic |
✔️ | Tablica wartości liczbowych. |
Napiwek
Najwygodniejszym sposobem korzystania z tej funkcji jest zastosowanie jej do wyników operatora serii make-series .
Przykłady
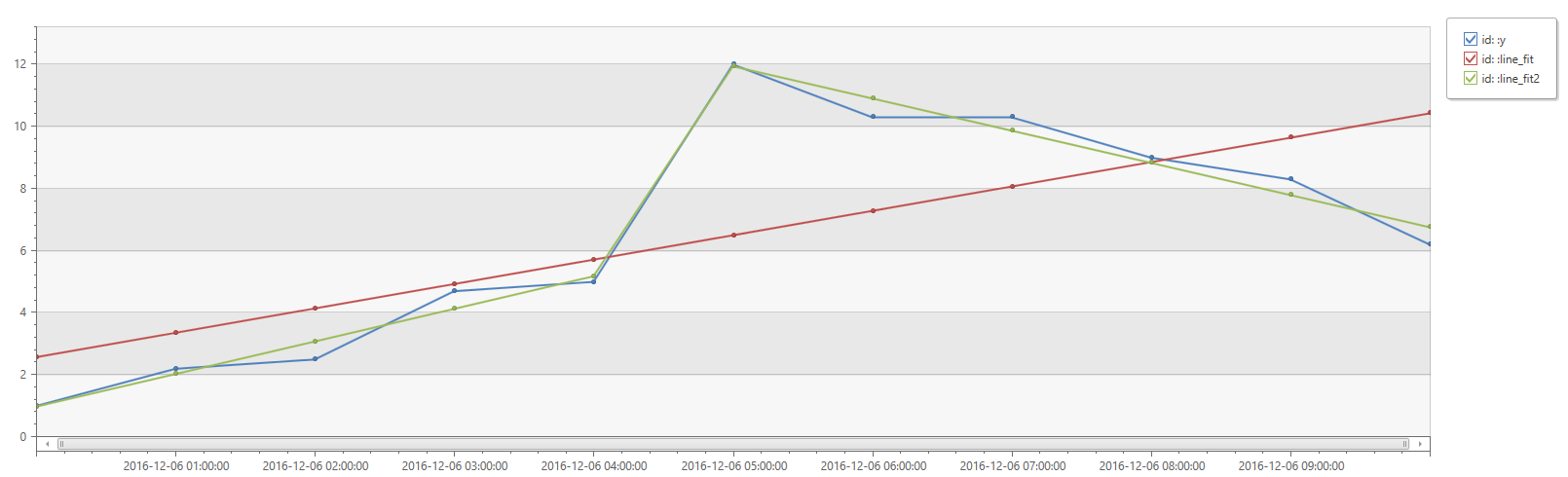
print
id=' ',
x=range(bin(now(), 1h) - 11h, bin(now(), 1h), 1h),
y=dynamic([1, 2.2, 2.5, 4.7, 5.0, 12, 10.3, 10.3, 9, 8.3, 6.2])
| extend
(Slope, Interception, RSquare, Variance, RVariance, LineFit)=series_fit_line(y),
(RSquare2, SplitIdx, Variance2, RVariance2, LineFit2)=series_fit_2lines(y)
| project id, x, y, LineFit, LineFit2
| render timechart