Deploy Manufacturing data solutions using Azure portal
Important
Some or all of this functionality is available as part of a preview release. The content and the functionality are subject to change.
This section shows you how to deploy Manufacturing data solutions in the designated tenant. Before you start, make sure you complete the prerequisites for deployment.
Create a new resource
To create a new Manufacturing data solutions resource, follow these steps:
Open the Manufacturing data solutions deployment wizard from the Azure portal using one of the following two ways:
Select Create a resource and search for Factory Operations Agent in Azure AI.
Select the Manufacturing Data Solutions.
Select Create to create a new Manufacturing data solutions resource.
Configure the basics
On the Basics tab, enter the following information and select Next:
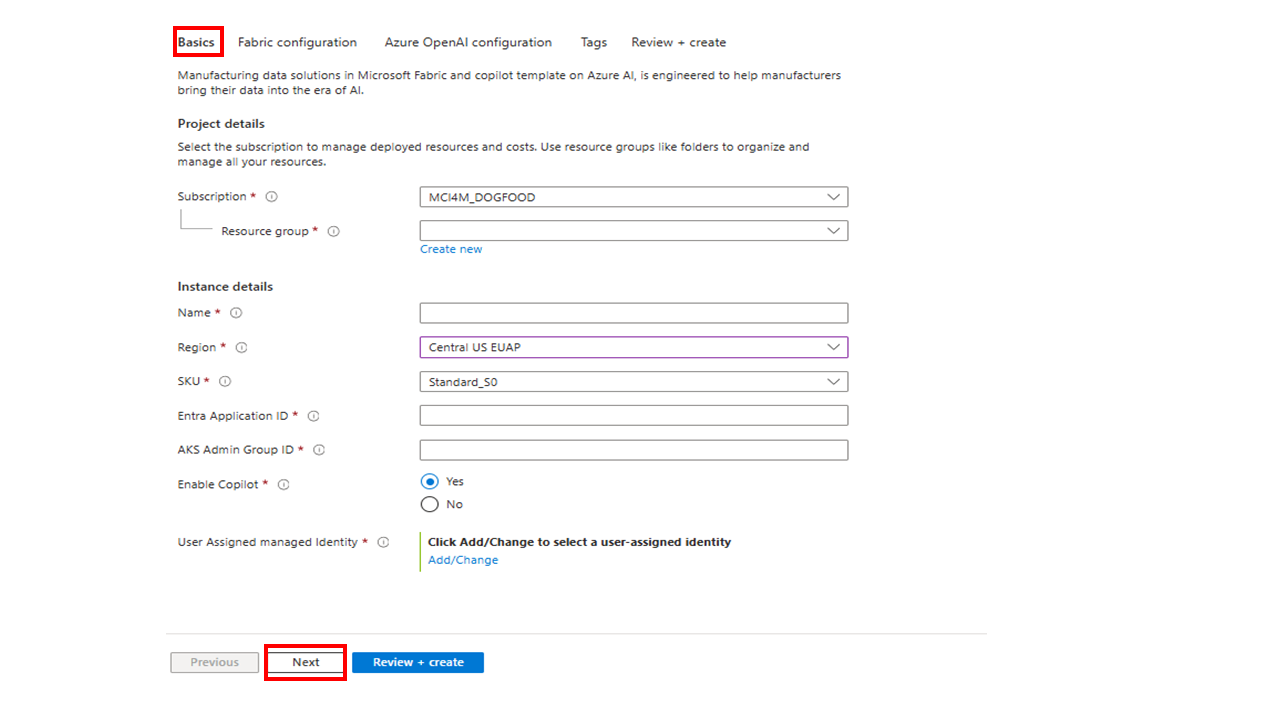
Setting Description Subscription Choose the subscription to deploy the Manufacturing data solutions resource in. Resource group Create or choose the resource group where you want to create the Manufacturing data solutions resource. Name Enter a name for the Manufacturing data solutions resource. The name shouldn't exceed 21 characters Region Choose the region where you want to deploy the resource. SKU Select Basic SKU for a Dev/Test release, or Standard for a Production release. For more information, see SKU. Microsoft Entra Application ID Enter the Application ID that you created the Manufacturing data solutions App Registration. AKS Admin Group ID Enter the Microsoft Entra ID group ID that you created with a list of owners and members. Enable Resource Telemetry Choose whether to collect and view logs and metrics for your resources. Enable Agent Choose whether to deploy the resources needed for Factory Operations Agent in Azure AI Foundry.

Note
If you try to deploy with the same name in the same resource group (RG) and subscription within seven days, purge the previous instance of App-configuration and then start the deployment.
Configure the fabric
On the Fabric Configuration tab, enter the following information and select Next. Select Add/Change to choose a managed identity.
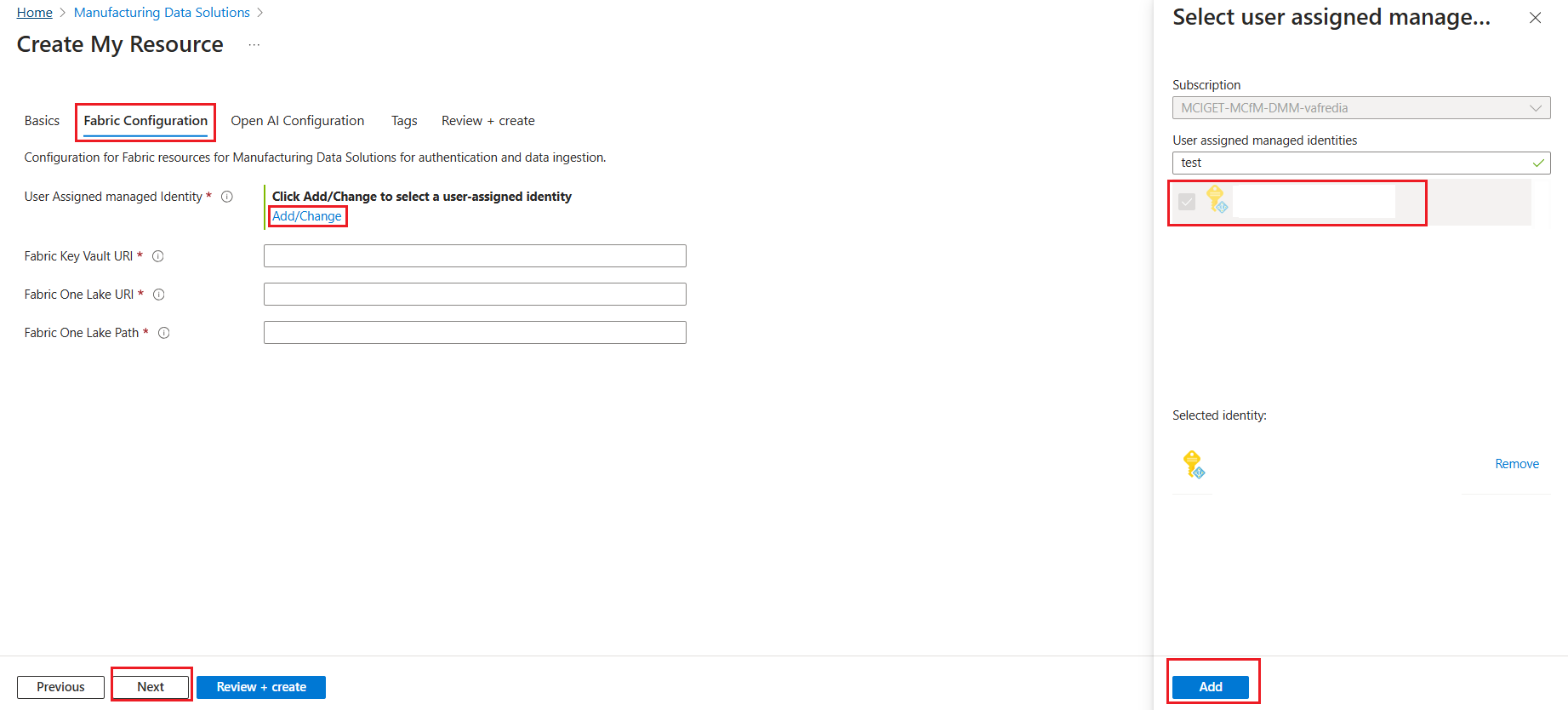
Setting Description User Assigned managed identity Enter the User Assigned Identity that is configured to read the secrets in Key Vault.
This value is required and is used for provisioning resources in your subscription. This value is also required if you want to onboard the Azure OpenAI resource to fetch necessary details.Fabric Key Vault URI Enter the URI of the Azure Key Vault, for example: https://<Key Vault Name>.vault.azure.netFabric One Lake URI Enter the URI of One Lake, for example: https://onelake.dfs.fabric.<Organization Name>.comFabric One Lake Path Enter the path of the Lakehouse, for example: <Workspace Name>/<Lakehouse Name>.lakehouse/files

Configure Azure OpenAI
If you enabled the agent on the Basics tab, you can configure Azure OpenAI on this tab. You can choose to onboard your own Azure OpenAI resource or use a Manufacturing data solutions managed Azure OpenAI deployment. Enter the details on the Azure OpenAI Configuration screen and then select Review and Create.
Agent configuration - Default
Choose Default if no configuration is required. This service tries to deploy a model in the following preference order based on availability: a) name:gpt-4o,version:2024-08-06 b) name:gpt-4 ,version:turbo-2024-04-09 c) name:gpt-4-32k ,version:0613.
Agent configuration - Bring your own Azure OpenAI resource
You can switch during update from user-managed Azure OpenAI resource to Manufacturing data solutions managed Azure OpenAI deployment.

| Bring your own Azure OpenAI resource | Description |
|---|---|
| Resource ID | Enter the Azure OpenAI resource ID from your deployment. |
| GPT Model Deployment Name | Enter the name of your Azure OpenAI GPT model deployment. |
| Embedding Model Deployment Name | Enter the name of your embedding model deployment. |
The Azure OpenAI resource should be present in the same tenant but can be present in any subscription, resource group, or region. Also, the User Managed Identity (provided in Basics) should have Cognitive Services Data Contributor role for data plane service to access the models and either Contributor or Owner role for control plane service to access the resource.
Agent configuration - Configure model

| Model Configuration | Description |
|---|---|
| GPT Model Name | Choose the large language model to use Capacity value between 5 and 90 |
| GPT Model Version | Choose the version of the large language model to use. |
| GPT Model Capacity | Choose the capacity (tokens in thousands per minute) for the large language model. |
| Embedding Model Capacity | Choose the capacity (tokens in thousands per minute) for the embeddings model to use. Capacity value between 100 and 240 |
The models available differ per region. You can also change the model after deployment.
The deployment takes around 40 to 50 minutes to complete. Open the Azure portal and select Deployments in the newly created resource group to check the status of the deployment.
SKU
You can choose from multiple SKU options for your resource.The SKU determines the capacity of underlying resources like Cosmos DB, Azure Data Explorer (ADX), and so on.
| SKU Type | SKU Name | Azure Data Explorer SKU | Function App SKU |
|---|---|---|---|
| Basic | Basic_B0 | Dev(No SLA)_Standard_E2a_v4 (Manual scale - instance count 1) | EP1 |
| Standard | Standard_S0 | Standard_E4ads_v5 (Manual Scale - instance count 2) | EP1 |
| Standard | Standard_S1 | Standard_E4ads_v5 (Optimized Autoscale - instance count 4 to 6) | EP1 |
| Standard | Standard_S2 | Standard_E4ads_v5 (Optimized Autoscale - instance count 6 to 10) | EP2 |
| Standard | Standard_S3 | Standard_E8ads_v5 (Optimized Autoscale - instance count 5) | EP3 |
| Standard | Standard_S4 | Standard_E8ads_v5 (Optimized Autoscale - instance count 5 to 10) | EP3 |
| Standard | Standard_S5 | Standard_E8d_v5 (Optimized Autoscale - instance count 6 to 20) | EP2 |
Note
Higher SKUs also offer the capability of running more queries simultaneously for improved performance and can be considered as implementation details, so they aren't highlighted in the provided table. The Azure Data Explorer (ADX) settings for the shuffle partitions, maximum concurrent requests, are set to an optimized value. The Event Hub throughput units are optimized, and the Function App workers have different limits to optimize the ingestion and consumption performance.
When you create a Manufacturing data solutions instance:
- If you select Basic, the system defaults to Basic_B0.
After the daily/weekly ingestion load is reduced, you can trigger an update on the Manufacturing data solutions instance and reduce to a lower SKU, which reduces the capacity for Azure Cosmos DB and Azure Data Explorer (ADX).
- You can't switch from Basic to Standard SKUs and vice versa.
- You can switch between Standard SKUs (S0 to S5).
Note
For Basic SKU, infrastructure resources are not deployed with zone redundancy. There's no SLA for this SKU. For Standard SKU, infrastructure resources are deployed with zone redundancy. They have standard SLAs.
Note
Switching from any Standard SKU to Basic SKU is not supported. You can update the SKU after deployment.
Configure Azure OpenAI model
If you enabled the agent during deployment, two models are deployed: an Azure OpenAI GPT model and embeddings model.
You can select from the following GPT models:
- GPT Model name
- GPT Model version
- GPT Model capacity
You can change the Embeddings Model Capacity for the embeddings model. However, you can't change the embeddings model name and version. They're set to text-embeddings-ada-002 version 2.
Deployment results
After deployment is finished, a new Manufacturing data solutions resource is created with supported Azure resources. The Azure resources associated for Manufacturing data solutions are hosted in two new resources groups.
