Opcje ciągłości działania i odzyskiwania po awarii dla produktu FSLogix
Uwaga
Wszystkie diagramy są przykładami opartymi na usłudze Azure Virtual Desktop i mają zastosowanie do innych platform pulpitów wirtualnych.
Skuteczny plan ciągłości działania i odzyskiwania po awarii (BCDR) koncentruje się na procesach i zasobach niezbędnych dla organizacji do działania w przypadku awarii lub innej znaczącej awarii. Profile użytkowników mobilnych nie są często opisywane jako składnik biznesowy lub krytyczny dla strategii BCDR . W środowisku pulpitu wirtualnego użytkownik nie wie, że ma profil mobilny. Profil jest przenoszone w celu zapewnienia użytkownikom spójnego środowiska niezależnie od maszyny wirtualnej. Dane biznesowe lub o znaczeniu krytycznym nie powinny być przechowywane w profilu użytkownika, jeśli w ogóle jest to możliwe. Korzystanie z usługi OneDrive, programu SharePoint lub innych rozwiązań jest skutecznym sposobem ochrony danych podczas zdarzenia BCDR , a jednocześnie nie polega na roamingu danych z użytkownikiem w ramach profilu. Ten proces jest najlepiej opisany w ćwiczeniu celu czasu odzyskiwania (RTO) i celu punktu odzyskiwania (RPO), w którym można rozważyć korzyść kosztową i analizę ryzyka na podstawie celów organizacyjnych i biznesowych.
Opcja 1. Brak odzyskiwania profilu
Chociaż ta opcja nie wygląda jak projekt BCDR , koncentruje się na zapewnieniu, że dane biznesowe i krytyczne dla misji nie są w profilu użytkownika. Podczas awarii użytkownicy będą tworzyć nowe profile w nowej lokalizacji lub na nowym dostawcy magazynu (oba mogą być prawdziwe). Ta opcja jest najbardziej opłacalna w zakresie kosztów infrastruktury, chociaż ma karę ze względu na wpływ, jaki może mieć na środowisko użytkownika.
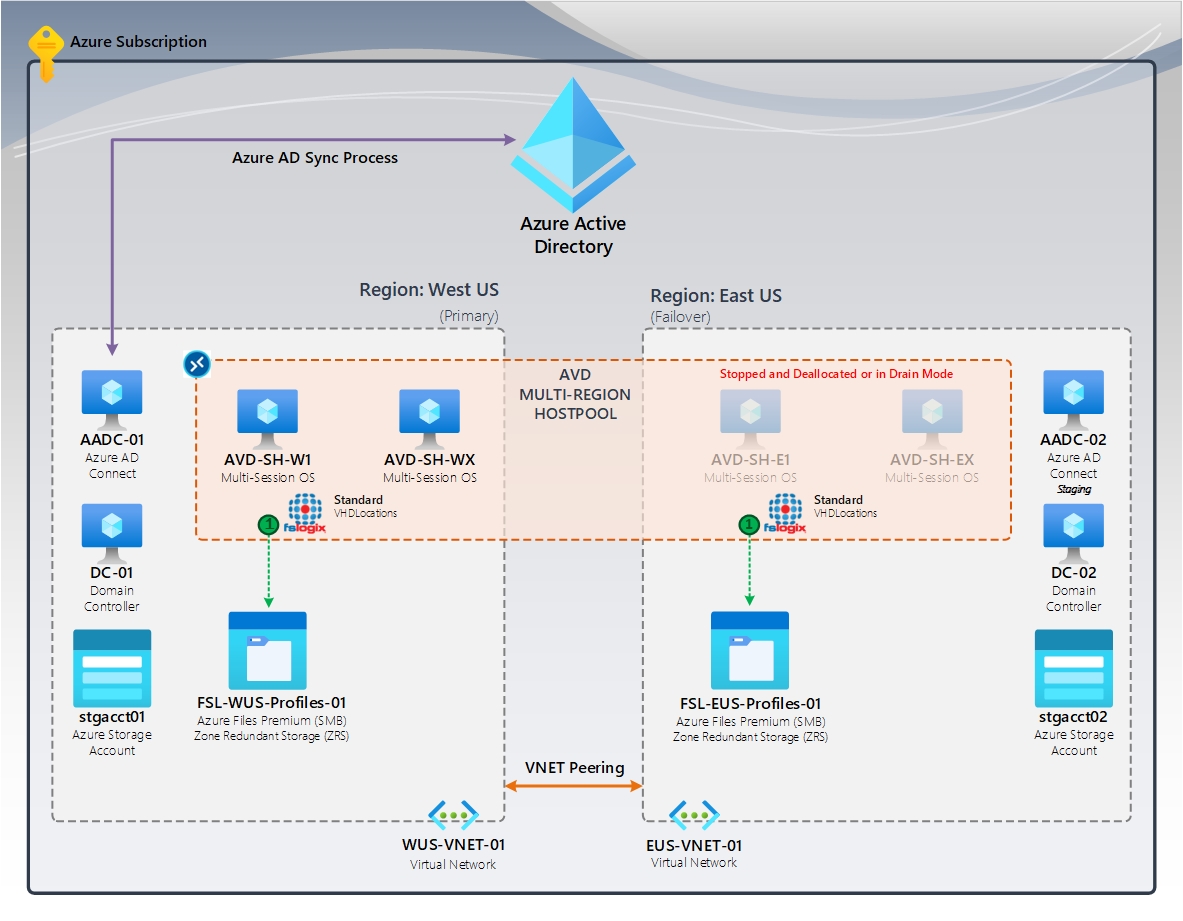
Rysunek 1. Brak odzyskiwania profilu | Kontenery standardowe FSLogix (VHDLocations)
Na diagramie znajduje się pula hostów z wieloma regionami przy użyciu usługi Azure Virtual Desktop. Oba regiony podstawowe i failover mają dedykowany udział usługi Azure Files przy użyciu magazynu strefowo nadmiarowego (ZRS), który zapewnia wysoką dostępność w regionie. Region trybu failover ma hosty sesji, które są zatrzymane lub cofnięto przydział. W przypadku awarii region trybu failover stanie się regionem podstawowym, a użytkownicy będą logować się do tych hostów sesji i tworzyć nowe profile w udziale usługi Azure Files w tym regionie.
Opcja 2. Pamięć podręczna w chmurze (podstawowa/tryb failover)
Projekt trybu failover to wspólna strategia zapewniająca dostępność i niezawodność infrastruktury w przypadku awarii lub awarii. Usługa Cloud Cache umożliwia korzystanie z biblioteki FSLogix przy użyciu tego typu projektu trybu failover. Za pomocą usługi Cloud Cache można skonfigurować urządzenia tak, aby używały dwóch (2) dostawców magazynu, którzy przechowują dane profilu w różnych lokalizacjach. Usługa Cloud Cache synchronizuje dane profilu z każdym z dwóch dostawców magazynu asynchronicznie, dzięki czemu zawsze masz najnowszą wersję danych. Niektóre urządzenia znajdują się w lokalizacji podstawowej, a inne urządzenia znajdują się w lokalizacji trybu failover. Usługa Cloud Cache określa priorytet pierwszego dostawcy magazynu (najbliżej urządzenia) i używa innego dostawcy magazynu jako kopii zapasowej. Jeśli na przykład twoje urządzenie podstawowe znajduje się w regionie Zachodnie stany USA, a urządzenie trybu failover znajduje się w regionie Wschodnie stany USA, możesz skonfigurować pamięć podręczną w chmurze w następujący sposób:
- Urządzenie podstawowe używa dostawcy magazynu w regionie Zachodnie stany USA jako pierwszej opcji i dostawcy magazynu w regionie Wschodnie stany USA jako drugą opcję.
- Urządzenie trybu failover używa dostawcy magazynu w regionie Wschodnie stany USA jako pierwszej opcji i dostawcy magazynu w regionie Zachodnie stany USA jako drugiej opcji.
- Jeśli urządzenie podstawowe lub najbliższy dostawca magazynu ulegnie awarii, możesz przełączyć się na urządzenie trybu failover lub dostawcę magazynu kopii zapasowych i kontynuować pracę bez utraty danych profilu.
Istnieją jednak pewne wady używania projektu trybu failover z usługą Cloud Cache. Najpierw musisz płacić za przechowywanie danych profilu w dwóch (2) lokalizacjach. Po drugie, należy ręcznie zainicjować proces trybu failover, który może wymagać zatwierdzenia osób biorących udział w projekcie biznesowym. Po trzecie, może wystąpić pewne opóźnienie lub niespójność danych profilu z powodu synchronizacji asynchronicznej z dwoma dostawcami magazynu.
Napiwek
- Przed zezwoleniem użytkownikom na powrót po awarii do profilów w lokalizacji podstawowej upewnij się, że wszyscy użytkownicy pomyślnie wylogowali się z lokalizacji trybu failover, aby upewnić się, że lokalizacja podstawowa ma aktualną replikę danych profilu użytkownika.
- Usługa Cloud Cache jest systemem intensywnie korzystającym z operacji we/wy i może łatwo powodować wąskie gardła sieci i/lub magazynu w przywróconej lokalizacji.
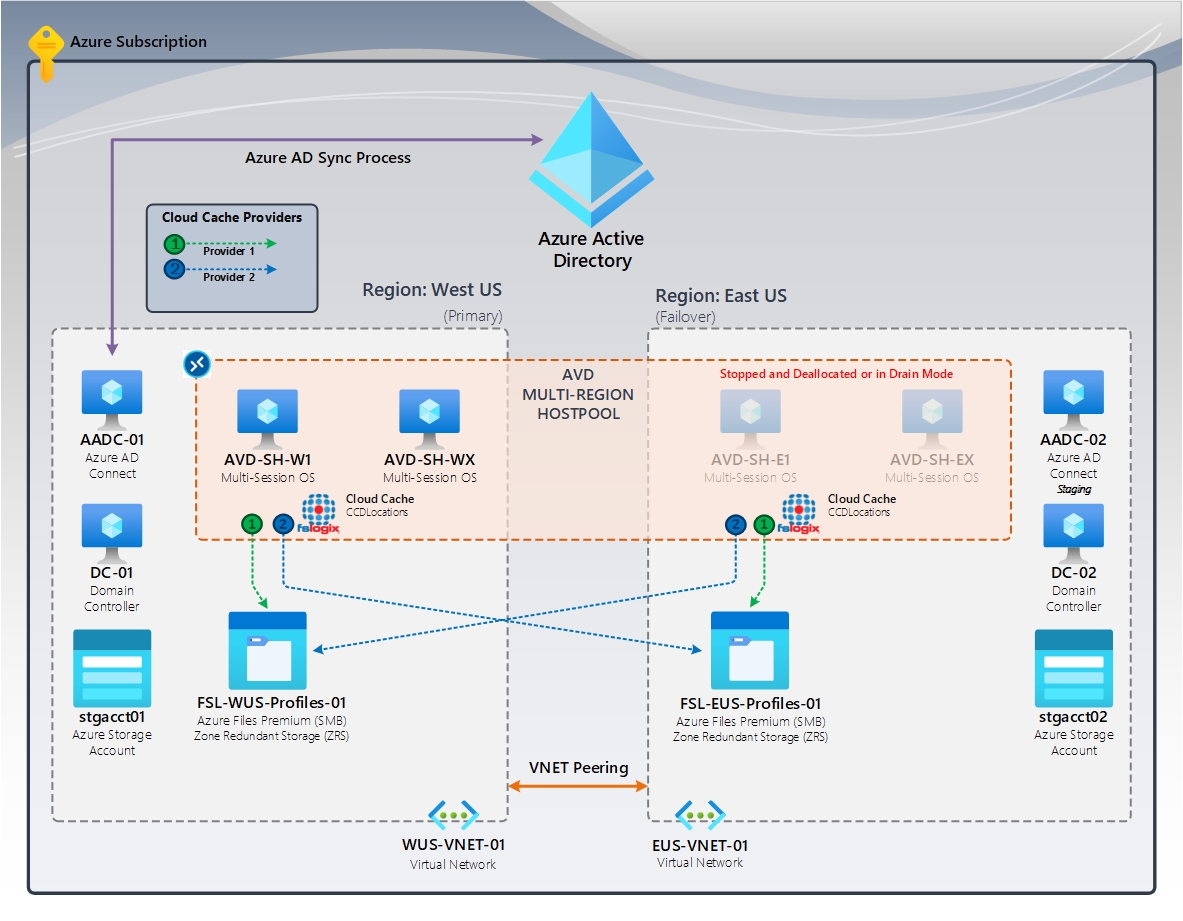
Rysunek 2. Pamięć podręczna w chmurze (podstawowa/tryb failover) | FSLogix Cloud Cache (CCDLocations)
Na diagramie mamy pulę hostów z wieloma regionami korzystającą z usługi Azure Virtual Desktop. Zarówno regiony podstawowe, jak i w trybie failover są częścią tej konfiguracji. Każdy z nich ma dedykowany udział usługi Azure Files przy użyciu magazynu strefowo nadmiarowego (ZRS), zapewniając wysoką dostępność w regionie. Region trybu failover zawiera hosty sesji, które są zatrzymane lub cofnięto przydział. W przypadku awarii region trybu failover stanie się regionem podstawowym. Użytkownicy będą logować się do tych hostów sesji i ładować ich zreplikowany profil z regionu trybu failover.
Należy jednak wziąć pod uwagę następujące kwestie:
- Zdarzenia BCDR (ciągłość działania i odzyskiwanie po awarii) są rzadko łaskawe. W zależności od okoliczności dane profilu użytkownika mogą nie być nienaruszone.
- Użytkownicy logujący się do hostów sesji w regionie trybu failover mogą doświadczyć utraty danych lub, w najgorszych przypadkach, uszkodzenia kontenera.
Biorąc pod uwagę tę sytuację, kluczowe znaczenie ma użycie platform magazynowania, takich jak OneDrive lub SharePoint, w przypadku danych krytycznych. Te platformy zapewniają dodatkową nadmiarowość i ochronę przed utratą danych. Należy pamiętać, że planowanie odzyskiwania po awarii jest niezbędne, a posiadanie odpowiedniej strategii magazynowania może ograniczyć ryzyko i zapewnić ciągłość działalności biznesowej.
Opcja 3. Pamięć podręczna w chmurze (aktywna/aktywna)
Podczas omawiania infrastruktury często używa się projektów aktywnych/aktywnych, które można również stosować do rozwiązania profilu FSLogix. Dzięki tej opcji usługa Cloud Cache jest skonfigurowana z dwoma dostawcami magazynu, którzy są aktualizowani asynchronicznie w celu odzwierciedlenia wszystkich zmian wprowadzonych w lokalnej pamięci podręcznej. Dostawca magazynu najbliżej aktywnej lokalizacji jest wymieniony jako pierwszy, podczas gdy dostawca najdalej znajduje się na liście drugiego. W drugiej lokalizacji kolejność jest odwrócona. Ta opcja wiąże się z dodatkowymi kosztami przechowywania danych dostawcy w dwóch lokalizacjach i wymaga ręcznej decyzji osób biorących udział w projekcie biznesowym przed zainicjowaniem trybu failover.
Napiwek
- Gdy region, w którym wystąpił błąd, może upłynąć dużo czasu na pełne replikowanie danych profilu.
- Usługa Cloud Cache jest systemem intensywnie korzystającym z operacji we/wy i może łatwo powodować wąskie gardła sieci i/lub magazynu w przywróconej lokalizacji.
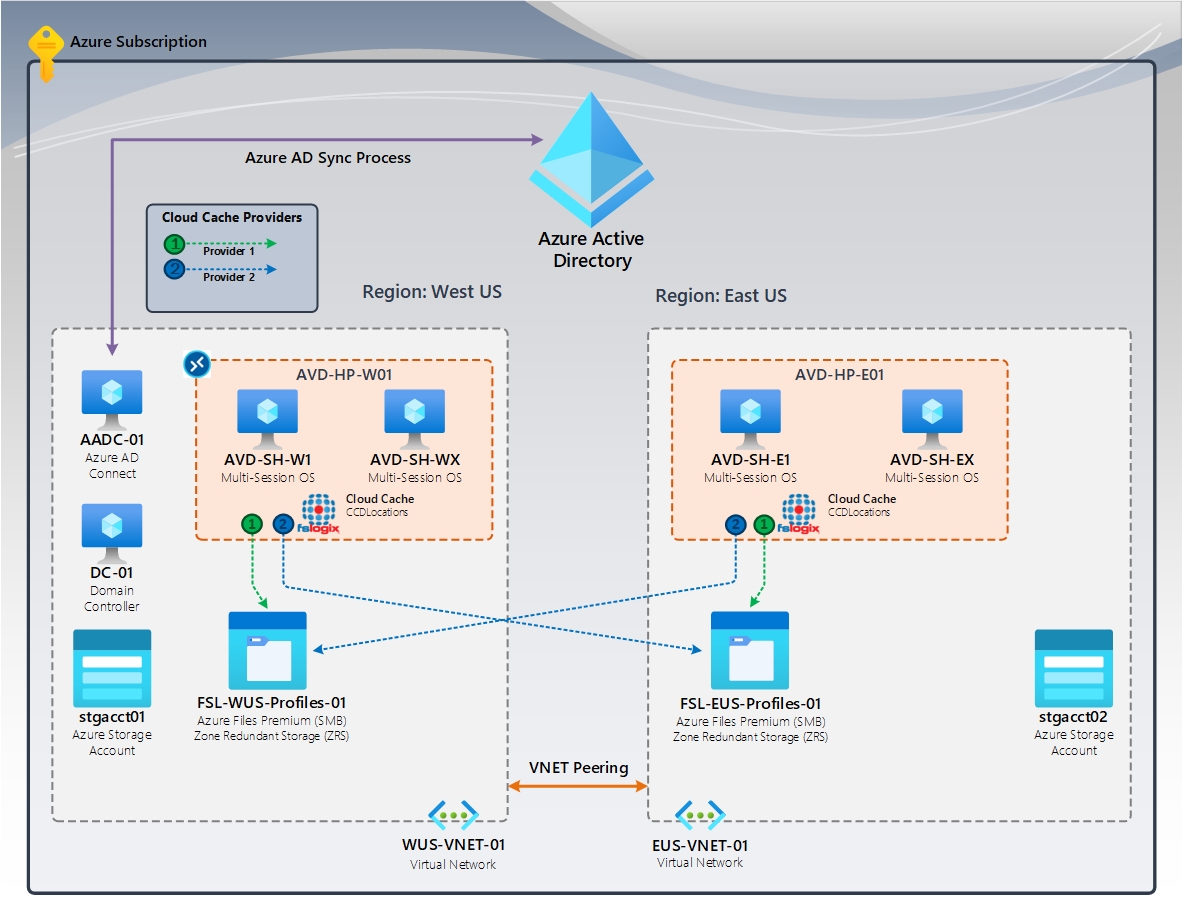
Rysunek 3. Pamięć podręczna w chmurze (aktywna/aktywna) | FSLogix Cloud Cache (CCDLocations)
Na diagramie znajdują się dwie (2) pule hostów AVD i hosty sesji znajdujące się w określonych regionach świadczenia usługi Azure. Użytkownicy przypisani do regionu Zachodnie stany USA uzyskują dostęp do tych maszyn wirtualnych. Użytkownicy w regionie Wschodnie stany USA mają dostęp tylko do tych maszyn wirtualnych i są przypisani do nich. Podczas awarii region ocalały musi mieć wystarczającą pojemność, aby obsługiwać wszystkich użytkowników. Ponadto użytkownicy z regionu, w którym wystąpił błąd, potrzebują dostępu przyznanego maszynom wirtualnym w regionie ocalałym.
Zdarzenia BCDR nigdy nie są bezpieczne i w zależności od okoliczności zdarzenia dane profilu użytkownika nie mają gwarancji, że będą nienaruszone. Użytkownicy logujący się do hostów sesji w ocalałym regionie mogą utracić dane lub gorzej uszkodzić kontener. Ta sytuacja wzmacnia potrzebę korzystania z platform magazynowania, takich jak OneDrive lub SharePoint, w przypadku krytycznych danych użytkownika.