Dodawanie źródła platformy Apache Kafka do strumienia zdarzeń (wersja zapoznawcza)
W tym artykule pokazano, jak dodać źródło platformy Apache Kafka do strumienia zdarzeń.
Apache Kafka to rozproszona platforma typu open source do tworzenia skalowalnych systemów danych w czasie rzeczywistym. Dzięki zintegrowaniu platformy Apache Kafka jako źródła w strumieniu zdarzeń można bezproblemowo przenieść zdarzenia w czasie rzeczywistym z platformy Apache Kafka i przetworzyć je przed routingiem do wielu miejsc docelowych w usłudze Fabric.
Uwaga
To źródło nie jest obsługiwane w następujących regionach pojemności obszaru roboczego: Zachodnie stany USA3, Szwajcaria Zachodnia.
Wymagania wstępne
- Dostęp do obszaru roboczego Sieć szkieletowa z uprawnieniami współautora lub wyższymi uprawnieniami.
- Uruchomiony klaster platformy Apache Kafka.
- Platforma Apache Kafka musi być publicznie dostępna i nie znajdować się za zaporą lub być zabezpieczona w sieci wirtualnej.
Uwaga
Maksymalna liczba źródeł i miejsc docelowych dla jednego strumienia zdarzeń wynosi 11.
Dodawanie platformy Apache Kafka jako źródła
W obszarze Analiza w czasie rzeczywistym w sieci szkieletowej wybierz pozycję Eventstream , aby utworzyć nowy strumień zdarzeń.
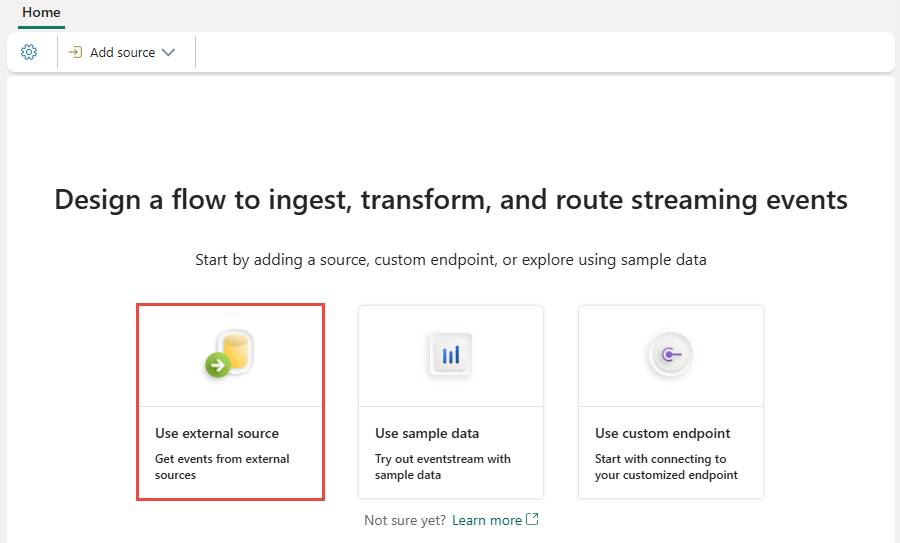
Na następnym ekranie wybierz pozycję Dodaj źródło zewnętrzne.
Konfigurowanie platformy Apache Kafka i nawiązywanie z nią połączenia
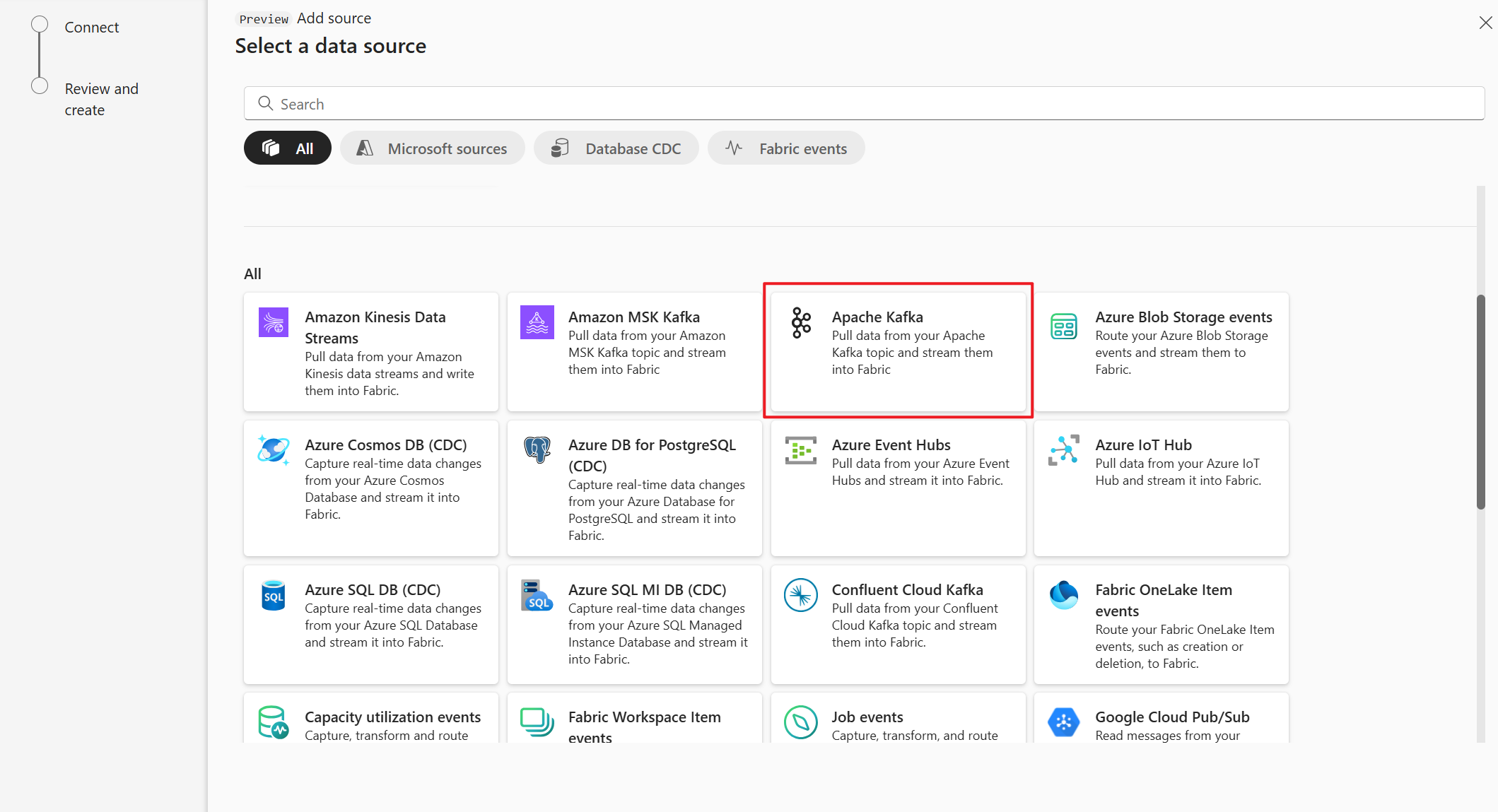
Na stronie Wybieranie źródła danych wybierz pozycję Apache Kafka.
Na stronie Łączenie wybierz pozycję Nowe połączenie.
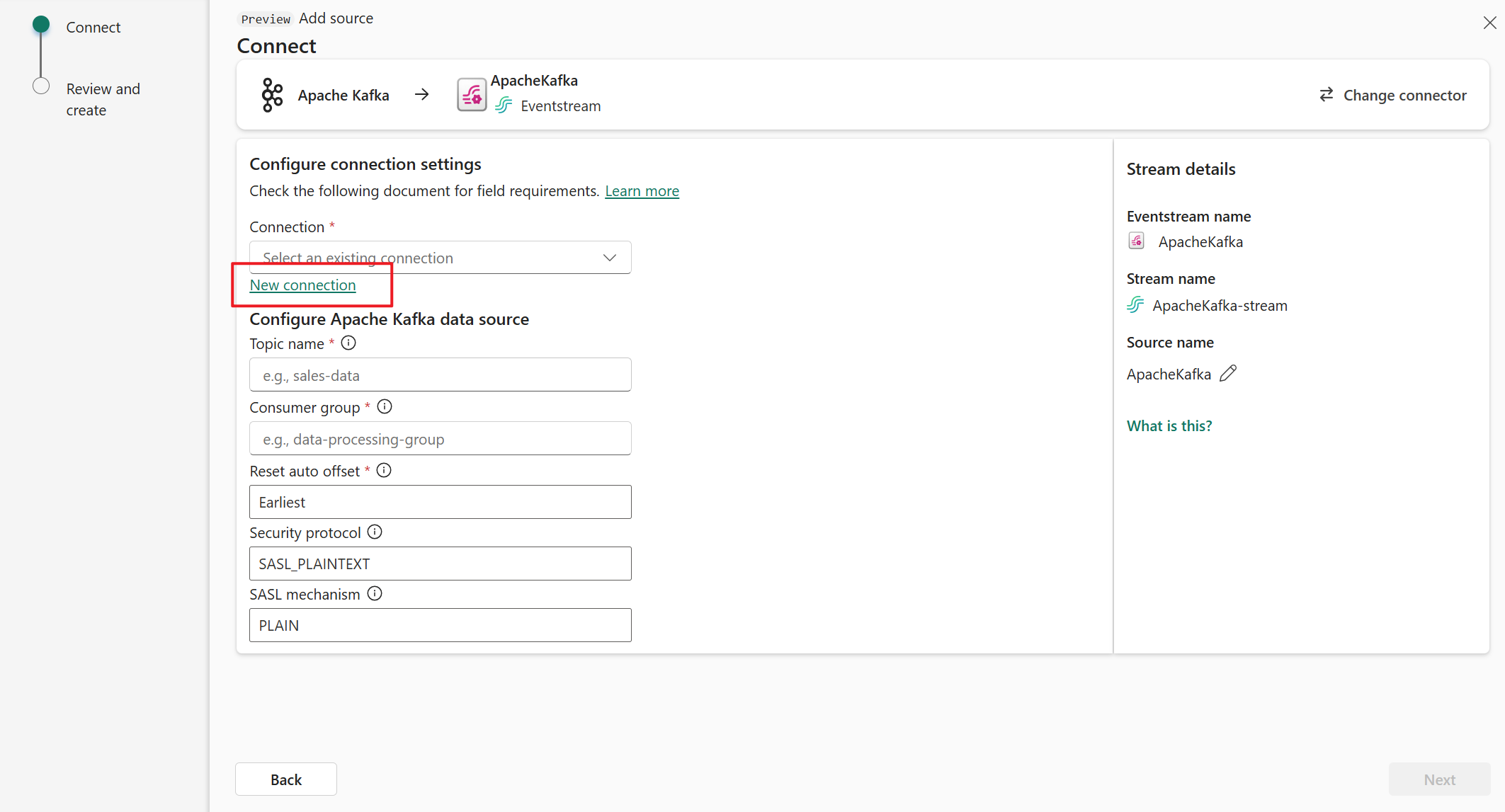
W sekcji Ustawienia połączenia w polu Bootstrap Server wprowadź adres serwera Apache Kafka.
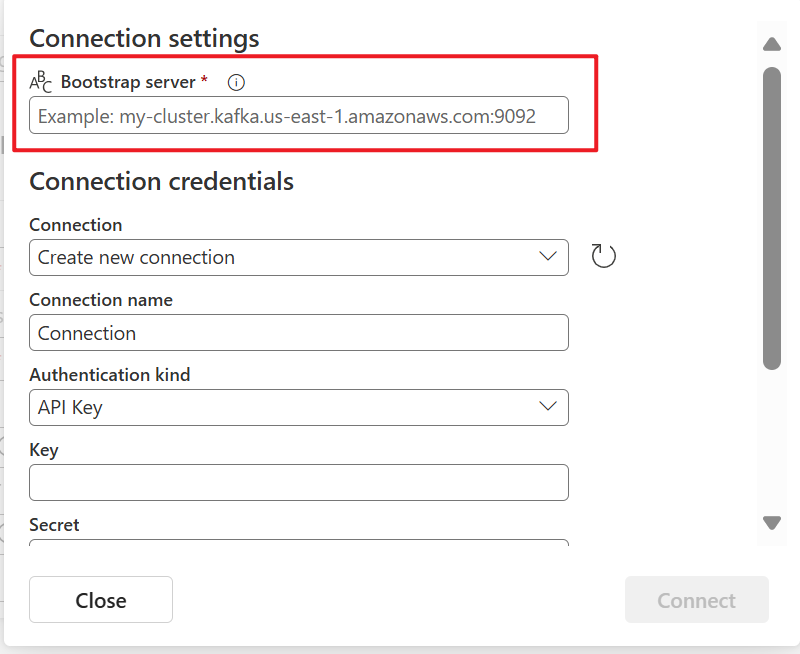
W sekcji Poświadczenia połączenia jeśli masz istniejące połączenie z klastrem Apache Kafka, wybierz je z listy rozwijanej Połączenie. W przeciwnym razie wykonaj następujące kroki:
- W polu Nazwa połączenia wprowadź nazwę połączenia.
- W polu Rodzaj uwierzytelniania upewnij się, że wybrano pozycję Klucz interfejsu API.
- W polu Klucz i Wpis tajny wprowadź klucz interfejsu API i klucz tajny.
Wybierz pozycję Połącz.
Teraz na stronie Łączenie wykonaj następujące kroki.
W polu Temat wprowadź temat platformy Kafka.
W polu Grupa odbiorców wprowadź grupę odbiorców klastra platformy Apache Kafka. To pole zawiera dedykowaną grupę odbiorców na potrzeby pobierania zdarzeń.
Wybierz pozycję Resetuj automatyczne przesunięcie , aby określić, gdzie rozpocząć odczytywanie przesunięć, jeśli nie ma zatwierdzenia.
W polu Protokół zabezpieczeń wartość domyślna to SASL_PLAINTEXT.
Uwaga
Źródło platformy Apache Kafka obsługuje obecnie tylko nieszyfrowaną transmisję danych (SASL_PLAINTEXT i PLAINTEXT) między klastrem Platformy Apache Kafka i strumieniem zdarzeń. Obsługa szyfrowanej transmisji danych za pośrednictwem protokołu SSL będzie dostępna wkrótce.
Domyślny mechanizm SASL jest zwykle zwykły, chyba że skonfigurowano inaczej. Można wybrać mechanizm SCRAM-SHA-256 lub SCRAM-SHA-512 , który odpowiada wymaganiom w zakresie zabezpieczeń.
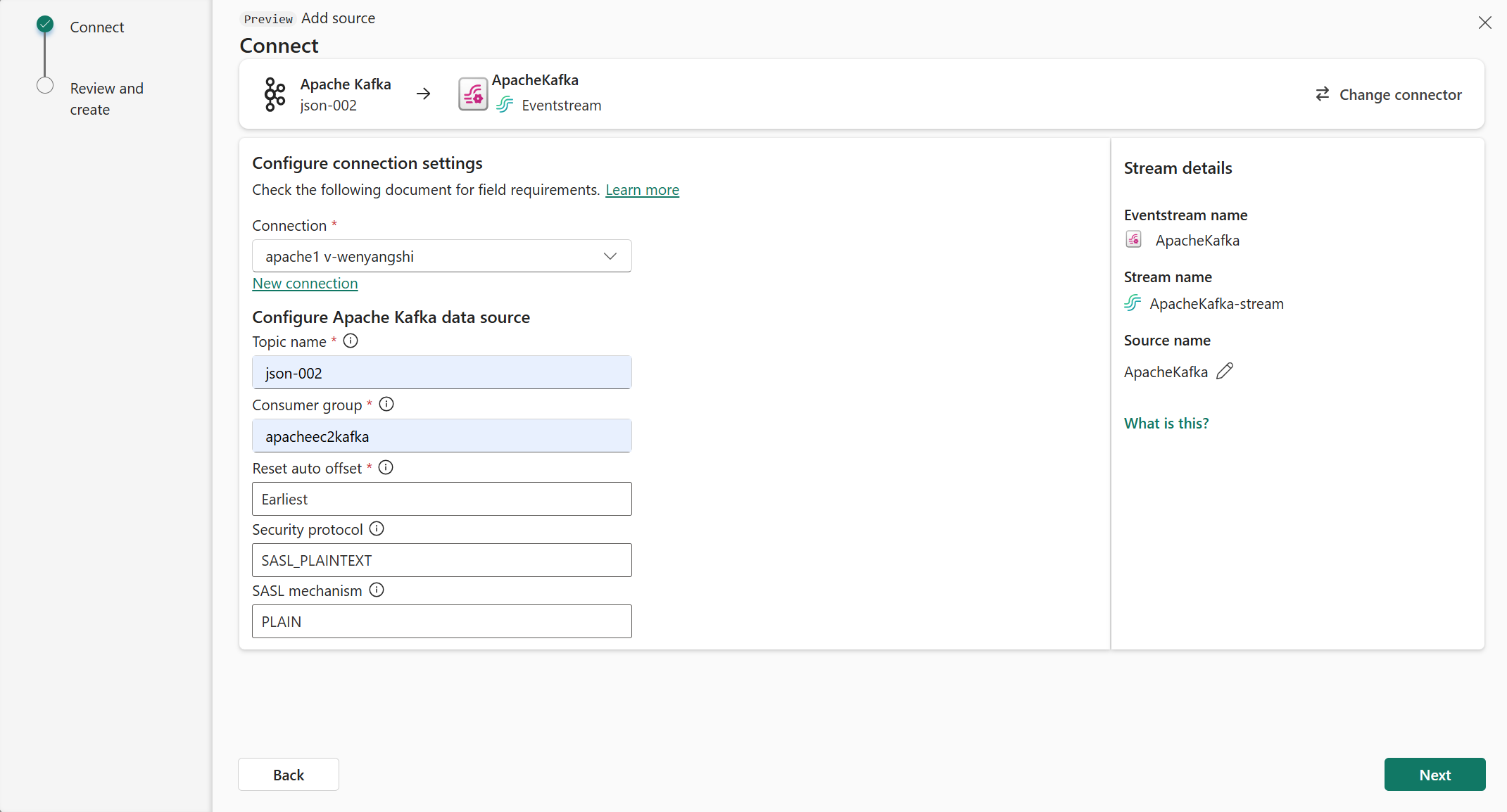
Wybierz Dalej. Na ekranie Przeglądanie i tworzenie przejrzyj podsumowanie, a następnie wybierz pozycję Dodaj.

Wyświetlanie zaktualizowanego strumienia zdarzeń
Źródło platformy Apache Kafka dodane do strumienia zdarzeń jest widoczne w trybie edycji.

Po wykonaniu tych kroków źródło platformy Apache Kafka jest dostępne do wizualizacji w widoku na żywo.

Powiązana zawartość
Inne łączniki:
- Strumienie danych Amazon Kinesis
- Azure Cosmos DB
- Azure Event Hubs
- Azure IoT Hub
- Przechwytywanie zmian danych w usłudze Azure SQL Database (CDC)
- Niestandardowy punkt końcowy
- Google Cloud Pub/Sub
- Usługa CDC bazy danych MySQL
- CdC bazy danych PostgreSQL
- Dane przykładowe
- Zdarzenia usługi Azure Blob Storage
- Zdarzenie obszaru roboczego sieci szkieletowej