Dostępność usługi Eventhouse OneLake
Kopię logiczną danych bazy KQL można utworzyć w centrum zdarzeń, włączając dostępność usługi OneLake. Włączenie dostępności OneLake oznacza, że możesz wykonywać zapytania dotyczące danych w bazie danych KQL w formacie Delta Lake za pośrednictwem innych silników Fabric, takich jak tryb Direct Lake w Power BI, Warehouse, Lakehouse, Notebooks oraz inne.
Delta Lake to ujednolicony format tabeli data lake, który zapewnia bezproblemowy dostęp do danych we wszystkich silnikach obliczeniowych w usłudze Microsoft Fabric. Aby uzyskać więcej informacji na temat usługi Delta Lake, zobacz Co to jest usługa Delta Lake?.
Z tego artykułu dowiesz się, jak włączyć dostępność danych bazy danych KQL w usłudze OneLake.
Jak to działa
Możesz włączyć dostępność OneLake na poziomie bazy danych lub tabeli. Po włączeniu na poziomie bazy danych wszystkie nowe tabele i ich dane są udostępniane w usłudze OneLake. Po włączeniu funkcji możesz również zastosować tę opcję do istniejących tabel, wybierając opcję Zastosuj do istniejących tabel, aby uwzględnić historyczne wypełnienie. Włączenie na poziomie tabeli sprawia, że tylko ta tabela i jej dane są dostępne w usłudze OneLake. Zasady przechowywania danych bazy danych KQL są również stosowane do danych w usłudze OneLake. Dane usunięte z bazy danych KQL na koniec okresu przechowywania są również usuwane z usługi OneLake. Jeśli wyłączysz dostępność OneLake, dane zostaną tymczasowo usunięte z OneLake.
Gdy dostępność OneLake jest włączone, nie można wykonać następujących zadań:
- Zmienianie nazw tabel
- Zmienianie schematów tabel
- Stosowanie zabezpieczeń na poziomie wiersza do tabel
- Nie można usunąć, skrócić ani wyczyścić danych
Jeśli musisz wykonać dowolne z tych zadań, wykonaj następujące czynności:
Ważne
Wyłączenie dostępności OneLake miękko usuwa dane z usługi OneLake. Po włączeniu dostępności wszystkie dane zostają udostępnione w usłudze OneLake, w tym uzupełnienie historyczne.
Wyłącz dostępność OneLake .
Wykonaj żądane zadanie.
Włącz dostępność OneLake .
Ważne
Aby uzyskać więcej informacji na temat czasu wyświetlania danych w usłudze OneLake, zobacz zachowanie adaptacyjne.
Nie ma dodatkowych kosztów magazynowania, aby włączyć dostępności oneLake. Aby uzyskać więcej informacji, zobacz Zużycie zasobów.
Wymagania wstępne
- Obszar roboczy z pojemnością z włączoną usługą Microsoft Fabric
- Baza danych KQL z uprawnieniami do edycji i danymi
Włączanie dostępności usługi OneLake
Możesz włączyć dostępność OneLake dla bazy danych lub tabeli KQL.
Aby włączyć dostępność OneLake (), wybierz bazę danych lub tabelę.
W sekcji OneLake okienka szczegółów ustaw dostępność na Włączony.
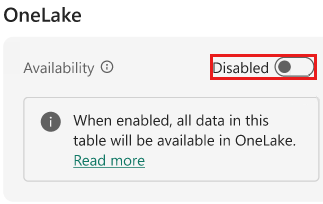
W oknie Włącz dostępność usługi Onelake wybierz Włącz.

Szczegóły bazy danych lub tabeli są odświeżane automatycznie.
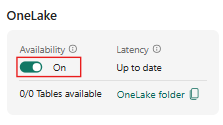
Po włączeniu dostępności OneLake w bazie danych lub tabeli KQL, można teraz uzyskać dostęp do wszystkich danych w danej ścieżce OneLake w formacie Delta Lake. Możesz również utworzyć skrót OneLake z usługi Lakehouse, Data Warehouse lub wykonać zapytanie o dane bezpośrednio za pośrednictwem trybu usługi Power BI Direct Lake.
Zachowanie adaptacyjne
Eventhouse oferuje niezawodny mechanizm, który inteligentnie grupuje przychodzące strumienie danych w jeden lub więcej plików Parquet, strukturowane do analizy. Przetwarzanie wsadowe strumieni danych jest ważne podczas radzenia sobie z cieknącymi danymi. Zapisywanie wielu małych plików Parquet do jeziora może być nieefektywne, co skutkuje wyższymi kosztami i niską wydajnością.
Mechanizm adaptacyjny usługi Eventhouse może opóźnić operacje zapisu, jeśli nie ma wystarczającej ilości danych, aby utworzyć optymalne pliki Parquet. Dzięki temu pliki Parquet są optymalne pod względem rozmiaru i są zgodne z najlepszymi praktykami Delta Lake. Mechanizm adaptacyjny Eventhouse zapewnia, że pliki Parquet są odpowiednio przygotowane do analizy, a także równoważy potrzebę szybkiej dostępności danych, z uwzględnieniem kosztów i wydajności.
Uwaga
- Domyślnie operacja zapisu może potrwać do 3 godzin lub do momentu utworzenia plików o wystarczającym rozmiarze (zazwyczaj 200–256 MB).
- Opóźnienie można dostosować do wartości z zakresu od 5 minut do 3 godzin.
Na przykład użyj następującego polecenia, aby ustawić opóźnienie na 5 minut:
.alter-merge table <TableName> policy mirroring dataformat=parquet with (IsEnabled=true, TargetLatencyInMinutes=5);
Ostrożność
Dostosowanie opóźnienia do krótszego okresu może spowodować nieoptymalną tabelę różnicową z dużą liczbą małych plików, co może prowadzić do nieefektywnej wydajności zapytań. Wynikowa tabela w usłudze OneLake jest tylko do odczytu i nie można jej zoptymalizować po utworzeniu.
Możesz monitorować, jak dawno temu nowe dane zostały dodane w jeziorze, sprawdzając opóźnienie danych przy użyciu polecenia .show table mirroring operations.
Wyniki są mierzone z czasu ostatniego dodania danych. Gdy opóźnienie powoduje wyświetlenie wartości 00:00:00, wszystkie dane w bazie danych KQL są dostępne w usłudze OneLake.
Wyświetlanie plików
Po włączeniu dostępności OneLake w tabeli zostanie utworzony folder dziennika delta wraz z odpowiednimi plikami JSON i Parquet. Możesz wyświetlić pliki, które zostały udostępnione w usłudze OneLake i ich właściwości, pozostając w obrębie Inteligencji w Czasie Rzeczywistym.
Aby wyświetlić pliki, umieść kursor nad tabelą w okienku Eksplorator , a następnie wybierz menu Więcej [...]>Wyświetlanie plików.
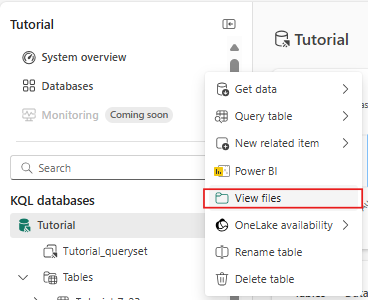
Aby wyświetlić właściwości folderu dziennika delty lub poszczególnych plików, umieść kursor nad folderem lub plikiem, a następnie wybierz menu Więcej [...]>Właściwości.
Aby wyświetlić pliki w folderze dziennika różnicowego:
- Wybierz folder _delta_log.
- Wybierz plik, aby wyświetlić metadane i schemat tabeli. Otwierany edytor jest w formacie tylko do odczytu.
Zasady dublowania dostępu
Domyślnie, gdy dostępnośćusługi OneLake jest włączona, polityka mirroringu jest aktywowana. Za pomocą zasad można monitorować opóźnienie danych lub zmieniać je w tabelach różnicowych partycji.
Uwaga
Jeśli wyłączysz dostępność usługi OneLake, właściwość zasad IsEnabled dublowania jest ustawiona na wartość false (IsEnabled=false).
Podział tabel delta
Możesz podzielić swoje tablice delta na partycje, aby zwiększyć szybkość zapytań. Aby uzyskać informacje o tym, kiedy partycjonować pliki OneLake, zobacz Kiedy partycjonować tabele. Każda partycja jest reprezentowana jako oddzielna kolumna przy użyciu nazwy partycji wymienionej na liście Partycje. Oznacza to, że kopia oneLake ma więcej kolumn niż tabela źródłowa.
Aby podzielić tabele różnicowe, użyj polecenia .alter-merge table policy mirroring.
Zapytania do tabel różnicowych
Notatnik Fabric umożliwia odczytywanie danych w OneLake przy użyciu poniższego fragmentu kodu.
W fragmencie kodu zastąp
<workspaceGuid>,<workspaceGuid>i<tableName>własnymi wartościami.
delta_table_path = 'abfss://`<workspaceGuid>`@onelake.dfs.fabric.microsoft.com/`<eventhouseGuid>`/Tables/`<tableName>`'
df = spark.read.format("delta").load(delta_table_path)
df.show()
Uwaga
W przypadku bazy danych usługi Azure Data Explorer użyj następującego kodu:
delta_table_path = 'abfss://`<workspaceName>`@onelake.dfs.fabric.microsoft.com/`<itemName>`.KustoDatabase/Tables/`<tableName>`'
Powiązana zawartość
- Aby uwidocznić dane w usłudze OneLake, zobacz Tworzenie skrótu w usłudze OneLake
- Aby utworzyć skrót OneLake w Lakehouse, zobacz Co to są skróty w Lakehouse?
- Aby zapytać o dane z usługi OneLake w bazie danych lub tabeli KQL, zobacz Utwórz skrót OneLake w bazie danych KQL