Dodaj platformę Apache Kafka jako źródło w usłudze Fabric Real-Time Hub (wersja zapoznawcza)
W tym artykule opisano sposób dodawania platformy Apache Kafka jako źródła zdarzeń w centrum sieci szkieletowej w czasie rzeczywistym.
Wymagania wstępne
- Dostęp do obszaru roboczego w trybie licencji pojemności sieci szkieletowej (lub) w trybie licencji próbnej z uprawnieniami współautora lub wyższymi uprawnieniami.
- Uruchomiony klaster platformy Apache Kafka.
- Platforma Apache Kafka musi być publicznie dostępna i nie znajdować się za zaporą lub być zabezpieczona w sieci wirtualnej.
Strona źródeł danych
Zaloguj się do usługi Microsoft Fabric.
Jeśli w lewym dolnym rogu strony zobaczysz Power BI, przejdź do obciążenia Fabric, wybierając Power BI, a następnie wybierając Fabric.
Wybierz pozycję Czas rzeczywisty na lewym pasku nawigacyjnym.

Na stronie Centrum czasu rzeczywistego wybierz pozycję + Źródła danych w obszarze Połącz z w menu nawigacji po lewej stronie.
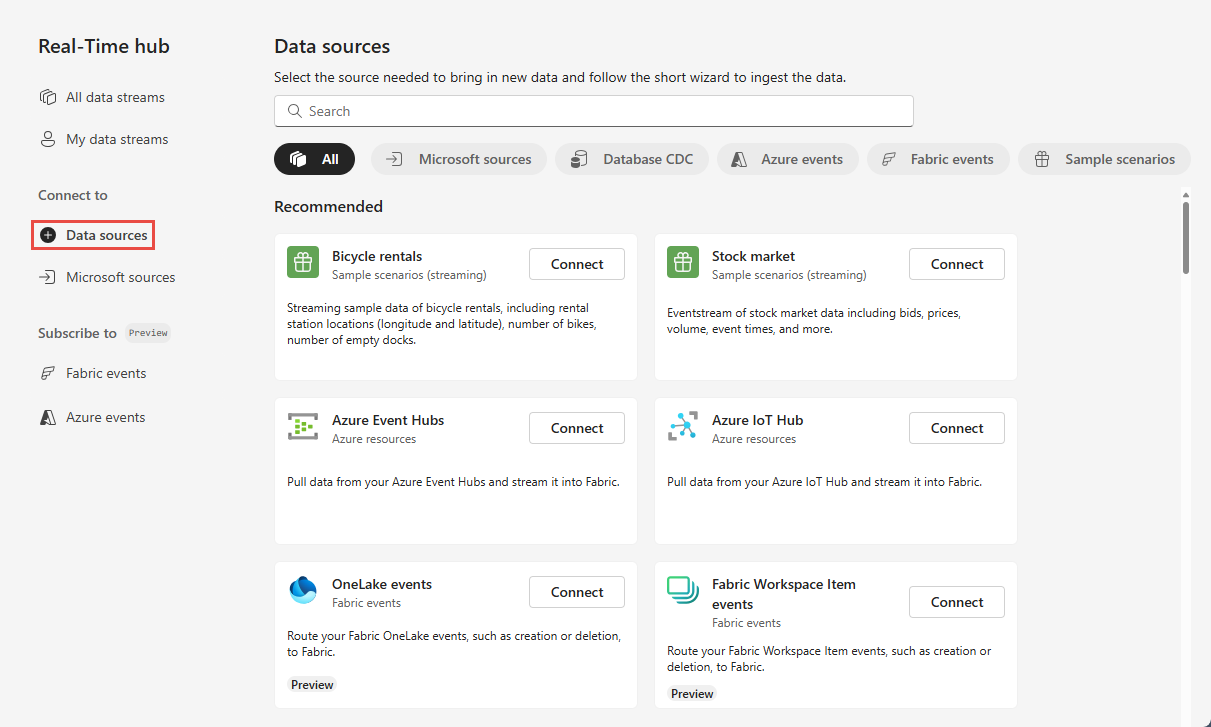
Możesz również przejść do strony Źródła danych na stronie Wszystkie strumienie danych lub Strony Moje strumienie danych, wybierając przycisk + Połącz źródło danych w prawym górnym rogu.
Dodawanie platformy Apache Kafka jako źródła
Poniżej przedstawiono kroki dodawania tematu platformy Apache Kafka jako źródła w usłudze Fabric Real-Time hub.
Na stronie Wybieranie źródła danych wybierz pozycję Apache Kafka.
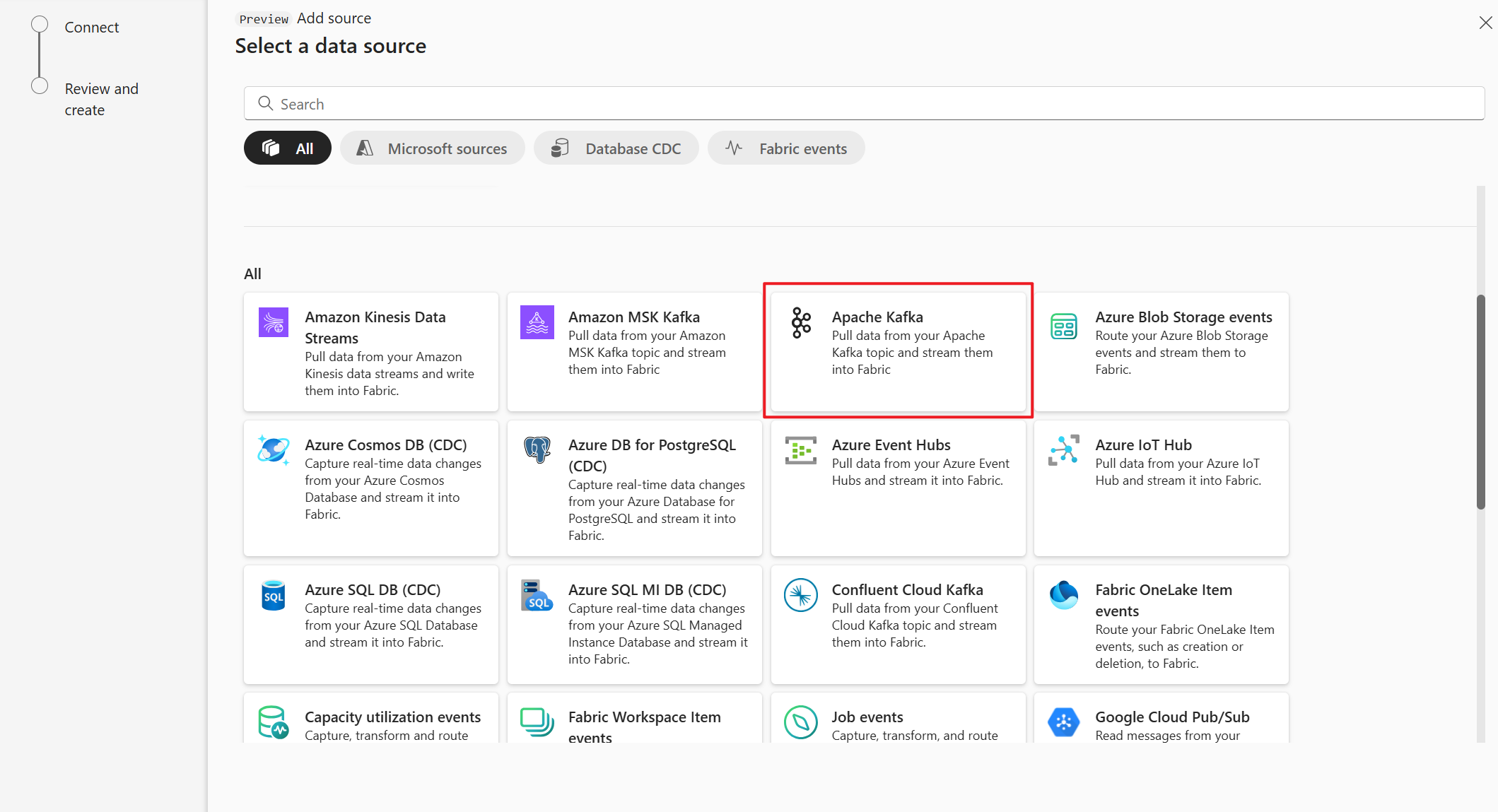
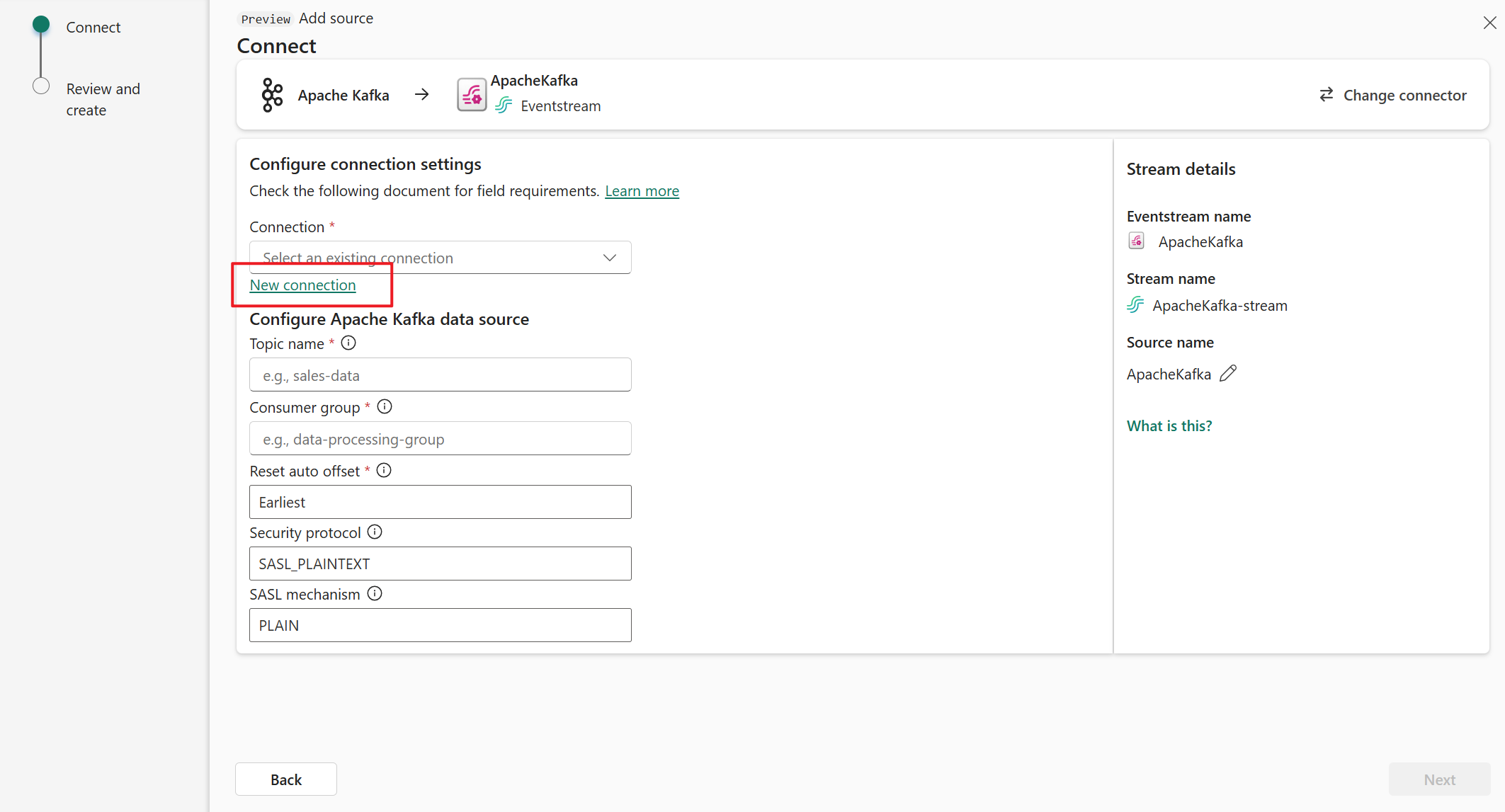
Na stronie Łączenie wybierz pozycję Nowe połączenie.
W sekcji Ustawienia połączenia w polu Bootstrap Server wprowadź adres serwera Apache Kafka.
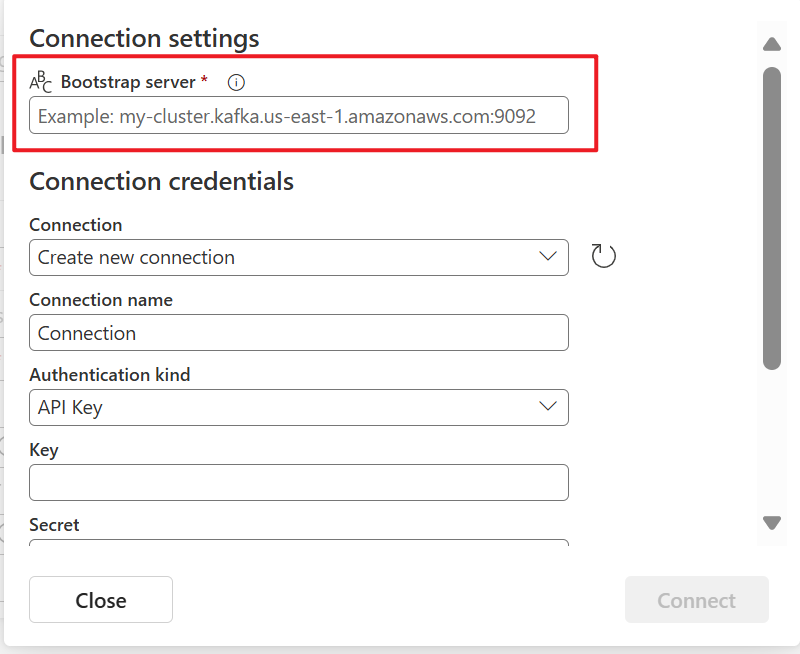
W sekcji Poświadczenia połączenia jeśli masz istniejące połączenie z klastrem Apache Kafka, wybierz je z listy rozwijanej Połączenie. W przeciwnym razie wykonaj następujące kroki:
- W polu Nazwa połączenia wprowadź nazwę połączenia.
- W polu Rodzaj uwierzytelniania upewnij się, że wybrano pozycję Klucz interfejsu API.
- W polu Klucz i Wpis tajny wprowadź klucz interfejsu API i klucz tajny.
Wybierz pozycję Połącz.
Teraz na stronie Łączenie wykonaj następujące kroki.
W polu Temat wprowadź temat platformy Kafka.
W polu Grupa odbiorców wprowadź grupę odbiorców klastra platformy Apache Kafka. To pole zawiera dedykowaną grupę odbiorców na potrzeby pobierania zdarzeń.
Wybierz pozycję Resetuj automatyczne przesunięcie , aby określić, gdzie rozpocząć odczytywanie przesunięć, jeśli nie ma zatwierdzenia.
W polu Protokół zabezpieczeń wartość domyślna to SASL_PLAINTEXT.
Uwaga
Źródło platformy Apache Kafka obsługuje obecnie tylko nieszyfrowaną transmisję danych (SASL_PLAINTEXT i PLAINTEXT) między klastrem Platformy Apache Kafka i strumieniem zdarzeń. Obsługa szyfrowanej transmisji danych za pośrednictwem protokołu SSL będzie dostępna wkrótce.
Domyślny mechanizm SASL jest zwykle zwykły, chyba że skonfigurowano inaczej. Można wybrać mechanizm SCRAM-SHA-256 lub SCRAM-SHA-512 , który odpowiada wymaganiom w zakresie zabezpieczeń.
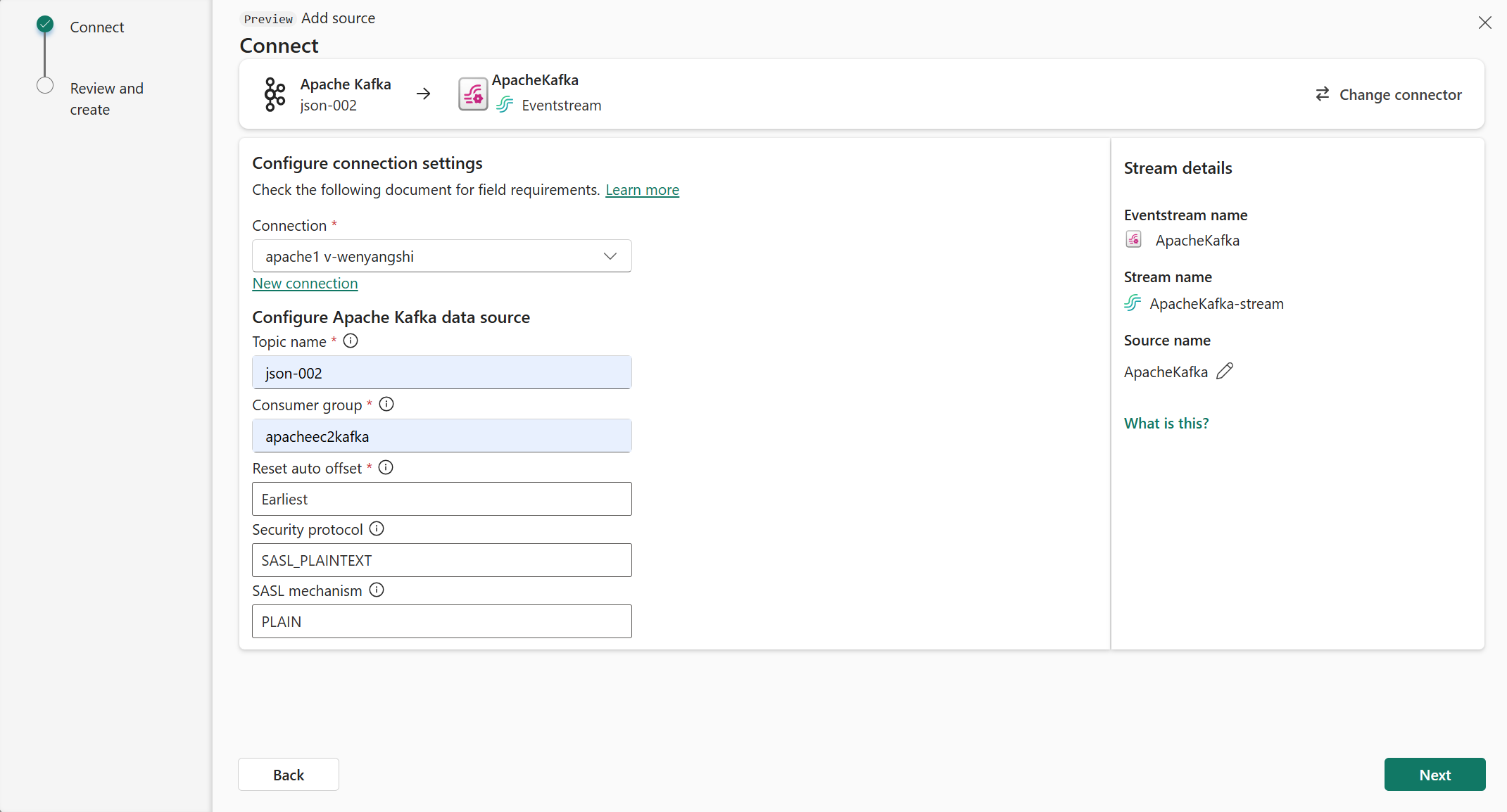
Wybierz Dalej. Na ekranie Przeglądanie i tworzenie przejrzyj podsumowanie, a następnie wybierz pozycję Dodaj.

Wyświetlanie szczegółów strumienia danych
Na stronie Przeglądanie i łączenie, jeśli wybierzesz pozycję Otwórz strumień zdarzeń, kreator otworzy strumień zdarzeń utworzony dla Ciebie przy użyciu wybranego źródła platformy Apache Kafka. Aby zamknąć kreatora, wybierz pozycję Zamknij w dolnej części strony.
W centrum czasu rzeczywistego przejdź do karty Strumienie danych centrum czasu rzeczywistego. Odśwież stronę. Powinien zostać wyświetlony utworzony strumień danych.
Aby uzyskać szczegółowe instrukcje, zobacz Wyświetlanie szczegółów strumieni danych w centrum sieci szkieletowej w czasie rzeczywistym.
Powiązana zawartość
Aby dowiedzieć się więcej o używaniu strumieni danych, zobacz następujące artykuły: