Integrowanie usługi OneLake z usługą Azure HDInsight
Azure HDInsight to zarządzana usługa oparta na chmurze do analizy danych big data, która pomaga organizacjom przetwarzać duże ilości danych. W tym samouczku pokazano, jak nawiązać połączenie z usługą OneLake przy użyciu notesu Jupyter z klastra usługi Azure HDInsight.
Korzystanie z usługi Azure HDInsight
Aby nawiązać połączenie z usługą OneLake przy użyciu notesu Jupyter z klastra usługi HDInsight:
Utwórz klaster Apache Spark usługi HDInsight (HDI). Postępuj zgodnie z następującymi instrukcjami: Konfigurowanie klastrów w usłudze HDInsight.
Podając informacje o klastrze, pamiętaj nazwę użytkownika i hasło logowania klastra, ponieważ będą one potrzebne do uzyskania dostępu do klastra później.
Utwórz tożsamość zarządzaną przypisaną przez użytkownika (UAMI): utwórz dla usługi Azure HDInsight — UAMI i wybierz ją jako tożsamość na ekranie Magazynu .
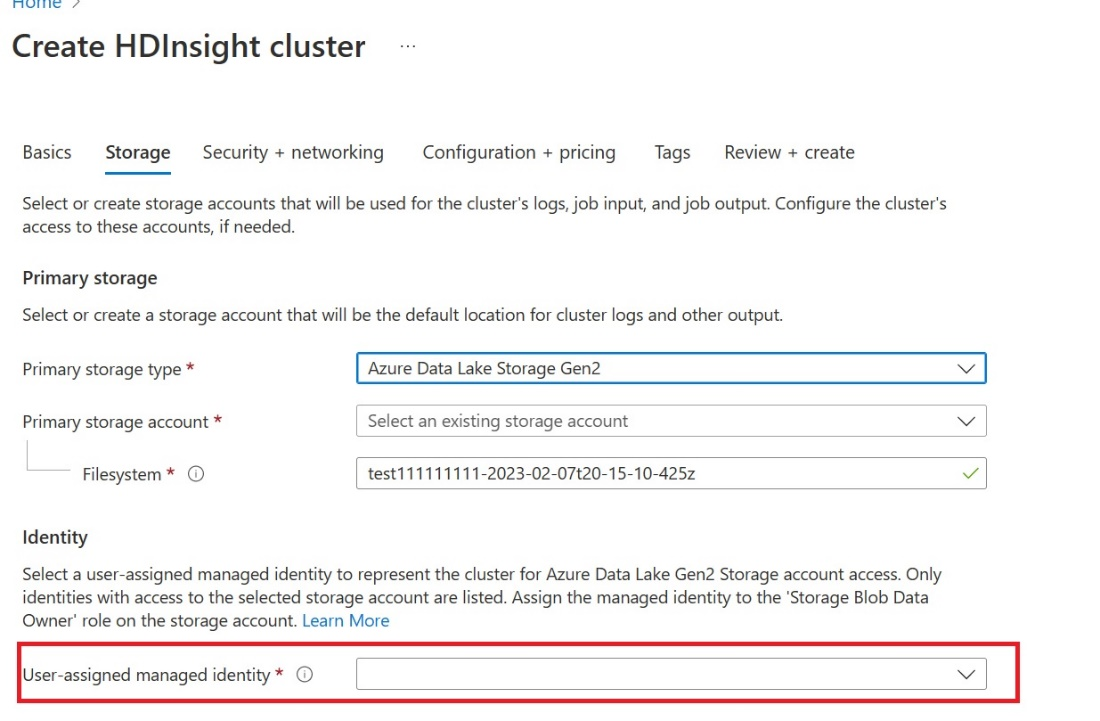
Nadaj temu interfejsowi użytkownika dostęp do obszaru roboczego Sieć szkieletowa, który zawiera elementy. Aby uzyskać pomoc przy podejmowaniu decyzji o tym, jaka rola jest najlepsza, zobacz Role obszaru roboczego.
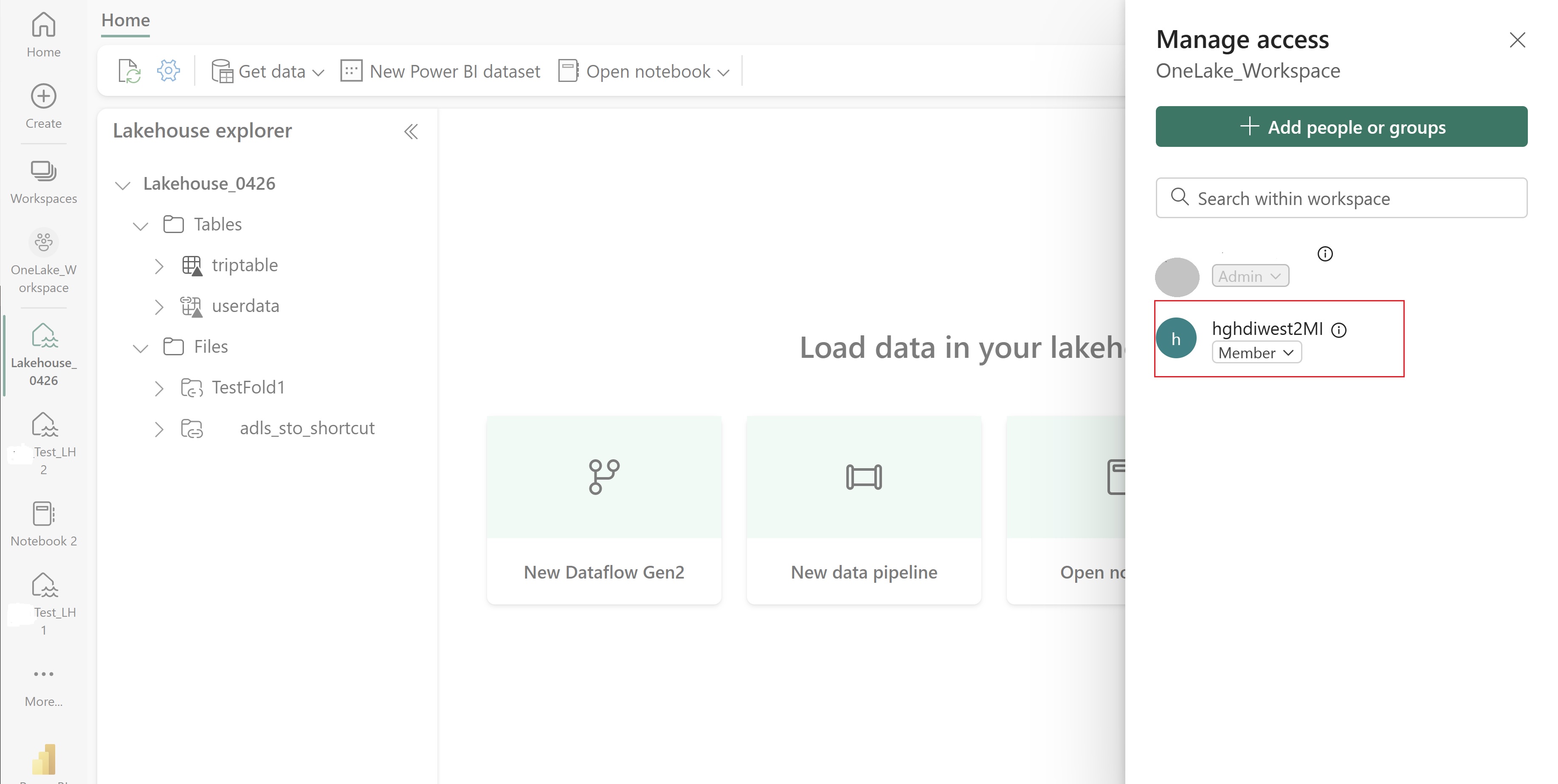
Przejdź do lakehouse i znajdź nazwę obszaru roboczego i lakehouse. Można je znaleźć w adresie URL usługi Lakehouse lub okienku Właściwości dla pliku.
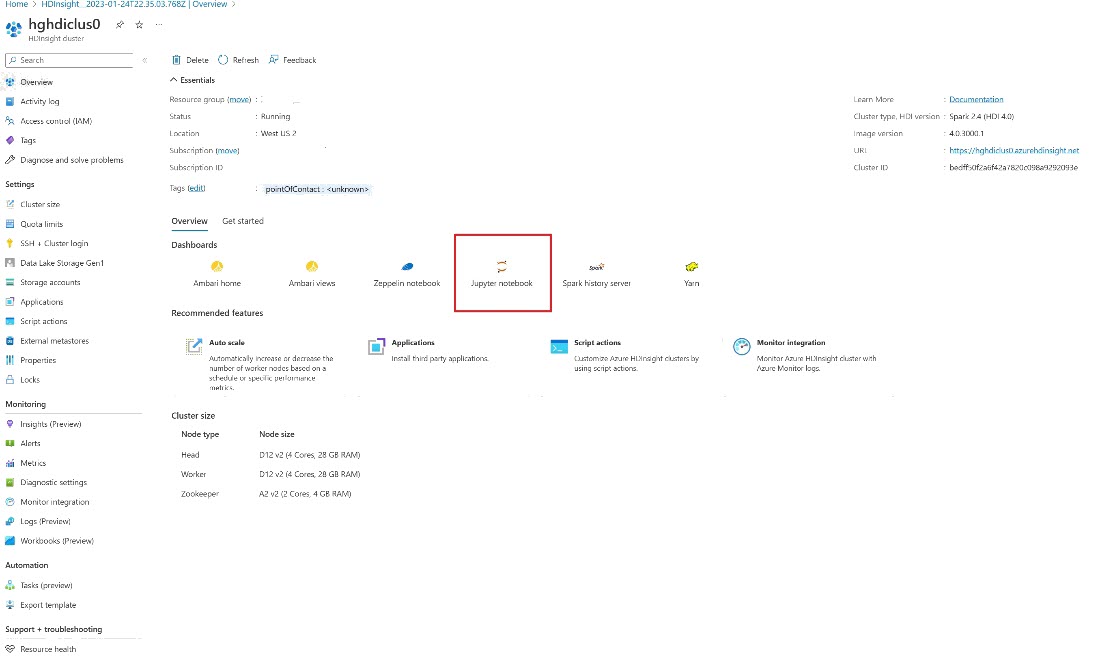
W witrynie Azure Portal wyszukaj klaster i wybierz notes.
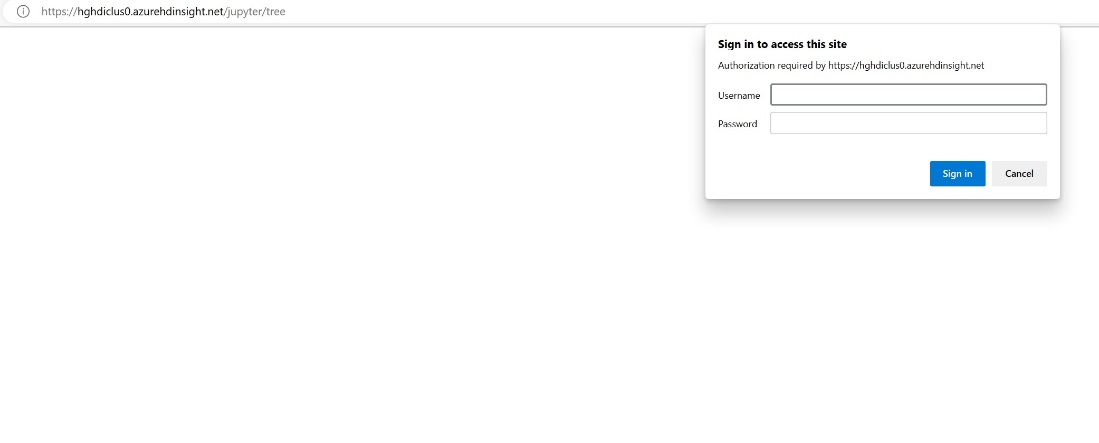
Wprowadź informacje o poświadczeniach podane podczas tworzenia klastra.
Utwórz nowy notes platformy Apache Spark.
Skopiuj nazwy obszaru roboczego i lakehouse do notesu i skompiluj adres URL usługi OneLake dla usługi Lakehouse. Teraz możesz odczytać dowolny plik z tej ścieżki pliku.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Spróbuj zapisać dane w lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Przetestuj, czy dane zostały pomyślnie zapisane, sprawdzając magazyn lakehouse lub odczytując nowo załadowany plik.




Teraz możesz odczytywać i zapisywać dane w usłudze OneLake przy użyciu notesu Jupyter w klastrze spark usługi HDI.