Przepis: Usługi azure AI — wykrywanie anomalii wielowariancyjnej
Ten przepis pokazuje, jak można używać usług SynapseML i Azure AI na platformie Apache Spark na potrzeby wykrywania anomalii wielowariancyjnych. Wykrywanie anomalii wielowariancyjnych umożliwia wykrywanie anomalii między wieloma zmiennymi lub szeregami czasowymi, biorąc pod uwagę wszystkie korelacje i zależności między różnymi zmiennymi. W tym scenariuszu używamy usługi SynapseML do trenowania modelu na potrzeby wykrywania anomalii wielowariancyjnych przy użyciu usług Azure AI, a następnie używamy modelu do wnioskowania anomalii wielowariancyjnych w zestawie danych zawierającym syntetyczne pomiary z trzech czujników IoT.
Ważne
Od 20 września 2023 r. nie będzie można tworzyć nowych zasobów Narzędzie do wykrywania anomalii. Usługa Narzędzie do wykrywania anomalii jest wycofywana 1 października 2026 r.
Aby dowiedzieć się więcej na temat Narzędzie do wykrywania anomalii usługi Azure AI, zapoznaj się z tą stroną dokumentacji.
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- Dołącz notes do magazynu lakehouse. Po lewej stronie wybierz pozycję Dodaj , aby dodać istniejący obiekt lakehouse lub utworzyć jezioro.
Ustawienia
Postępuj zgodnie z instrukcjami, aby utworzyć Anomaly Detector zasób przy użyciu witryny Azure Portal lub alternatywnie, możesz również użyć interfejsu wiersza polecenia platformy Azure do utworzenia tego zasobu.
Po skonfigurowaniu elementu Anomaly Detectormożna eksplorować metody obsługi danych różnych formularzy. Katalog usług w usłudze Azure AI oferuje kilka opcji: Vision, Speech, Language, Web search, Decision, Translation i Document Intelligence.
Tworzenie zasobu Narzędzie do wykrywania anomalii
- W witrynie Azure Portal wybierz pozycję Utwórz w grupie zasobów, a następnie wpisz Narzędzie do wykrywania anomalii. Wybierz zasób Narzędzie do wykrywania anomalii.
- Nadaj zasobowi nazwę i najlepiej użyć tego samego regionu co pozostała część grupy zasobów. Użyj domyślnych opcji pozostałych, a następnie wybierz pozycję Przejrzyj i utwórz , a następnie pozycję Utwórz.
- Po utworzeniu zasobu Narzędzie do wykrywania anomalii otwórz go i wybierz
Keys and Endpointspanel w lewym okienku nawigacyjnym. Skopiuj klucz zasobu Narzędzie do wykrywania anomalii doANOMALY_API_KEYzmiennej środowiskowej lub zapisz go w zmiennejanomalyKey.
Tworzenie zasobu konta magazynu
Aby zapisać dane pośrednie, należy utworzyć konto usługi Azure Blob Storage. Na tym koncie magazynu utwórz kontener do przechowywania danych pośrednich. Zanotuj nazwę kontenera i skopiuj parametry połączenia do tego kontenera. Będzie ona potrzebna później, aby wypełnić zmienną containerName i zmienną środowiskową BLOB_CONNECTION_STRING .
Wprowadź klucze usługi
Zacznijmy od skonfigurowania zmiennych środowiskowych dla kluczy usługi. Następna komórka ustawia ANOMALY_API_KEY zmienne środowiskowe i BLOB_CONNECTION_STRING na podstawie wartości przechowywanych w usłudze Azure Key Vault. Jeśli korzystasz z tego samouczka we własnym środowisku, przed kontynuowaniem upewnij się, że te zmienne środowiskowe zostały ustawione.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Teraz odczytaj ANOMALY_API_KEY zmienne środowiskowe i BLOB_CONNECTION_STRING i ustaw containerName zmienne i location .
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Najpierw nawiążmy połączenie z naszym kontem magazynu, aby wykrywacz anomalii mógł zapisywać wyniki pośrednie w tym miejscu:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Zaimportujmy wszystkie niezbędne moduły.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Teraz przeczytajmy nasze przykładowe dane w ramce danych platformy Spark.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Teraz możemy utworzyć estimator obiekt, który jest używany do trenowania naszego modelu. Określamy czas rozpoczęcia i zakończenia danych treningowych. Określamy również kolumny wejściowe do użycia oraz nazwę kolumny zawierającej znaczniki czasu. Na koniec określamy liczbę punktów danych do użycia w oknie przewijania wykrywania anomalii i ustawiamy parametry połączenia na konto usługi Azure Blob Storage.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Teraz, gdy utworzyliśmy element estimator, dopasujmy go do danych:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Po wywołaniu .show(5) w poprzedniej komórce pokazaliśmy nam pięć pierwszych wierszy w ramce danych. Wszystkie wyniki były null spowodowane tym, że nie znajdowały się w oknie wnioskowania.
Aby wyświetlić wyniki tylko dla wnioskowanych danych, umożliwia wybranie potrzebnych kolumn. Następnie możemy uporządkować wiersze w ramce danych według kolejności rosnącej i przefiltrować wynik, aby wyświetlić tylko wiersze, które znajdują się w zakresie okna wnioskowania. W naszym przypadku inferenceEndTime jest to samo, co ostatni wiersz w ramce danych, więc może to zignorować.
Na koniec, aby móc lepiej wykreślić wyniki, umożliwia przekonwertowanie ramki danych Spark na ramkę danych biblioteki Pandas.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Sformatuj kolumnę contributors , która przechowuje wynik udziału z każdego czujnika do wykrytych anomalii. Następna komórka formatuje te dane i dzieli wynik udziału każdego czujnika na własną kolumnę.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Świetnie! Teraz mamy wyniki udziału czujników 1, 2 i 3 odpowiednio w series_0kolumnach , series_1i series_2 .
Uruchom następną komórkę, aby wykreślić wyniki. Parametr minSeverity określa minimalną ważność anomalii do wykreślenia.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
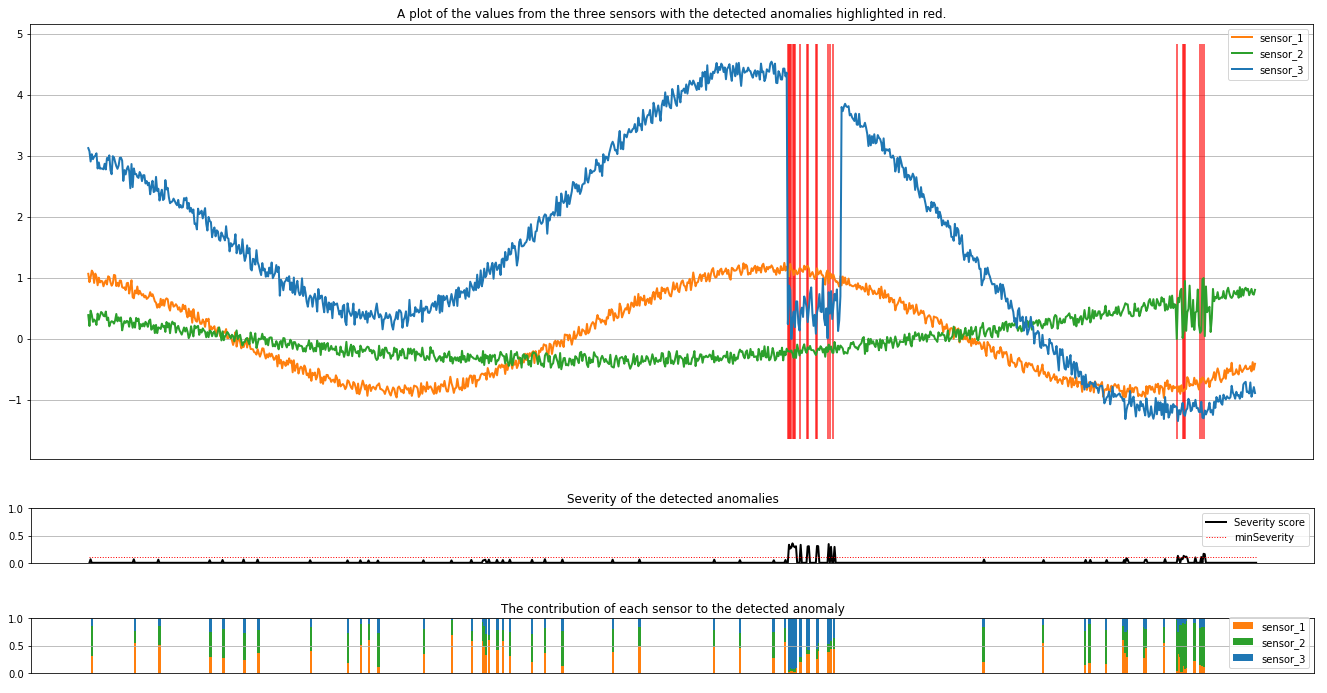
Wykresy pokazują nieprzetworzone dane z czujników (wewnątrz okna wnioskowania) w kolorze pomarańczowym, zielonym i niebieskim. Czerwone linie pionowe na pierwszej ilustracji pokazują wykryte anomalie o ważności większej lub równej minSeverity.
Drugi wykres przedstawia wynik ważności wszystkich wykrytych anomalii z minSeverity progiem pokazanym w kropkowanej czerwonej linii.
Na koniec ostatni wykres przedstawia wkład danych z każdego czujnika do wykrytych anomalii. Pomaga nam to zdiagnozować i zrozumieć najbardziej prawdopodobną przyczynę każdej anomalii.