Szybki start: przenoszenie i przekształcanie danych przy użyciu przepływów danych i potoków danych
W tym samouczku odkryjesz, jak doświadczenie związane z przepływem danych i potokiem danych może stworzyć potężne i kompleksowe rozwiązanie Data Factory.
Warunki wstępne
Aby rozpocząć pracę, musisz mieć następujące wymagania wstępne:
- Konto najemcy z aktywną subskrypcją. Utwórz bezpłatne konto .
- Upewnij się, że masz obszar roboczy z włączoną usługą Microsoft Fabric: Utwórz obszar roboczy, który nie jest domyślnym obszarem Mój obszar roboczy.
- Baza danych Azure SQL Database z danymi tabeli.
- konto usługi Blob Storage.
Przepływy danych w porównaniu z potokami
Przepływy danych Gen2 pozwalają na korzystanie z interfejsu niskokodowego oraz ponad 300 transformacji danych oparte na AI, co umożliwia łatwiejsze i bardziej elastyczne czyszczenie, przygotowywanie i przekształcanie danych niż jakiekolwiek inne narzędzie. Potoki danych umożliwiają rozbudowane możliwości orkiestracji danych gotowe do użycia w celu tworzenia elastycznych przepływów pracy danych spełniających potrzeby przedsiębiorstwa. W procesie przetwarzania można utworzyć logiczne grupowania działań realizujących zadanie, które mogą obejmować wywołanie Dataflow w celu oczyszczenia i przygotowania danych. Chociaż istnieją pewne funkcje nakładające się między nimi, wybór, który ma być używany dla określonego scenariusza, zależy od tego, czy potrzebujesz pełnego bogactwa potoków, czy można użyć prostszych, ale bardziej ograniczonych możliwości przepływów danych. Aby uzyskać więcej informacji, zobacz przewodnik decyzyjny Fabric
Przekształcanie danych za pomocą przepływów danych
Wykonaj następujące kroki, aby skonfigurować przepływ danych.
Krok 1. Tworzenie przepływu danych
Wybierz obszar roboczy z obsługą Fabric, a następnie wybierz pozycję Nowy. Następnie wybierz pozycję Przepływ danych Gen2.
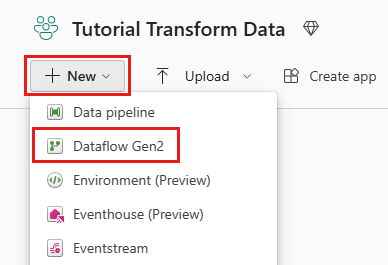
Zostanie wyświetlone okno edytora przepływów danych. Wybierz kartę Import from SQL Server (Importowanie z programu SQL Server).
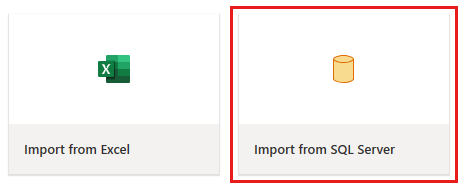


Krok 2. Pobieranie danych
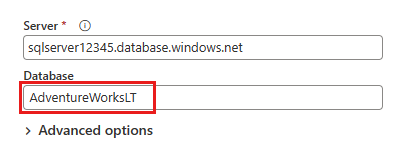
W wyświetlonym oknie dialogowym Połącz ze źródłem danych wprowadź dane do połączenia z bazą danych Azure SQL, a następnie wybierz Dalej. W tym przykładzie używasz przykładowej bazy danych AdventureWorksLT skonfigurowanej podczas ustawiania bazy danych Azure SQL w ramach wymagań wstępnych.
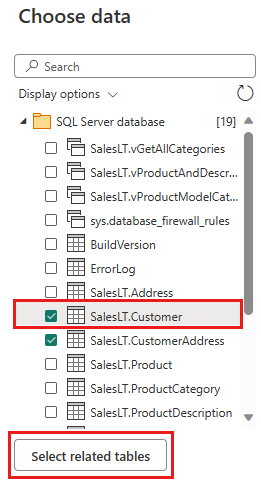
Wybierz dane, które chcesz przekształcić, a następnie wybierz pozycję Utwórz. Na potrzeby tego przewodnika Szybki start wybierz pozycję SalesLT.Customer z przykładowych danych AdventureWorksLT dostarczonych dla usługi Azure SQL DB, a następnie naciśnij przycisk Wybierz powiązane tabele, aby automatycznie dołączyć dwie inne powiązane tabele.


Krok 3. Przekształcanie danych
Jeśli nie jest zaznaczony, wybierz przycisk widok diagramu na pasku stanu u dołu strony lub wybierz widok diagramu z menu Widok u góry edytora Power Query. Jedną z tych opcji można przełączać widok diagramu.
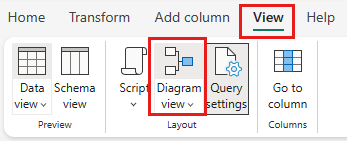
Kliknij prawym przyciskiem myszy zapytanie SalesLT Customer lub wybierz ikonę z trzema kropkami po prawej stronie okna zapytania, a następnie wybierz pozycję Scal zapytania.
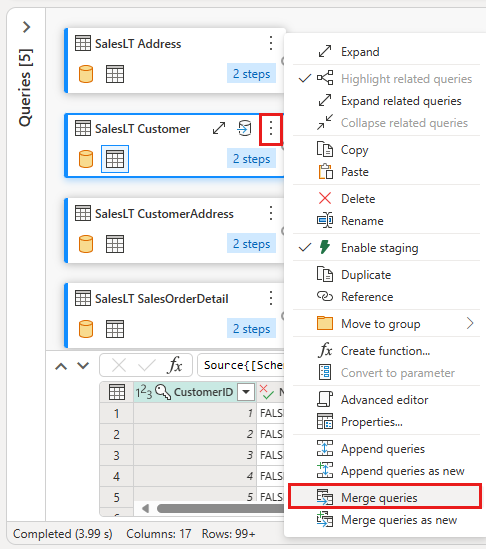
Skonfiguruj scalanie, wybierając tabelę SalesLTOrderHeader jako prawą tabelę dla scalania, kolumnę CustomerID z każdej tabeli jako kolumnę sprzężenia oraz Zewnętrzne lewe jako rodzaj sprzężenia. Następnie wybierz pozycję OK, aby dodać zapytanie scalania.
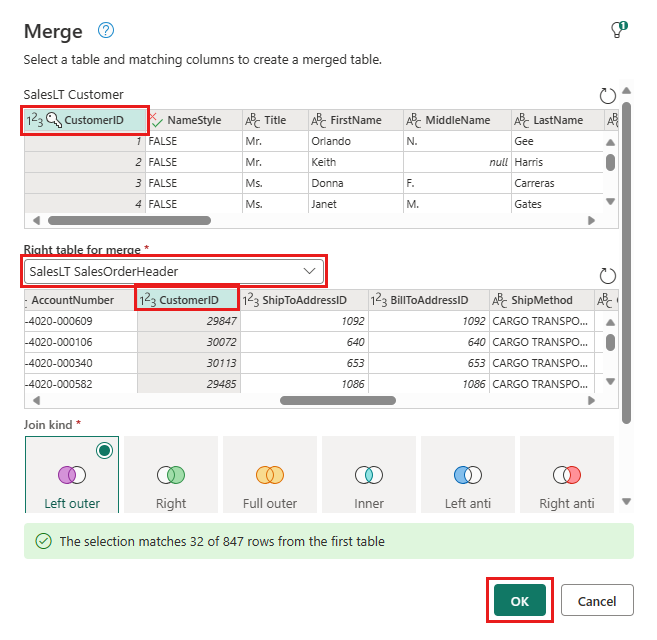
Wybierz przycisk Dodaj miejsce docelowe danych, który wygląda jak symbol bazy danych ze strzałką nad nią, z nowo utworzonego zapytania scalania. Następnie wybierz usługi Azure SQL Database jako typ docelowy.
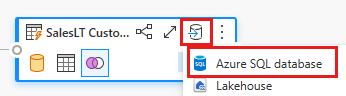
Podaj szczegóły połączenia usługi Azure SQL Database, w którym ma zostać opublikowane zapytanie scalania. W tym przykładzie można również użyć bazy danych AdventureWorksLT jako źródła danych dla miejsca docelowego.
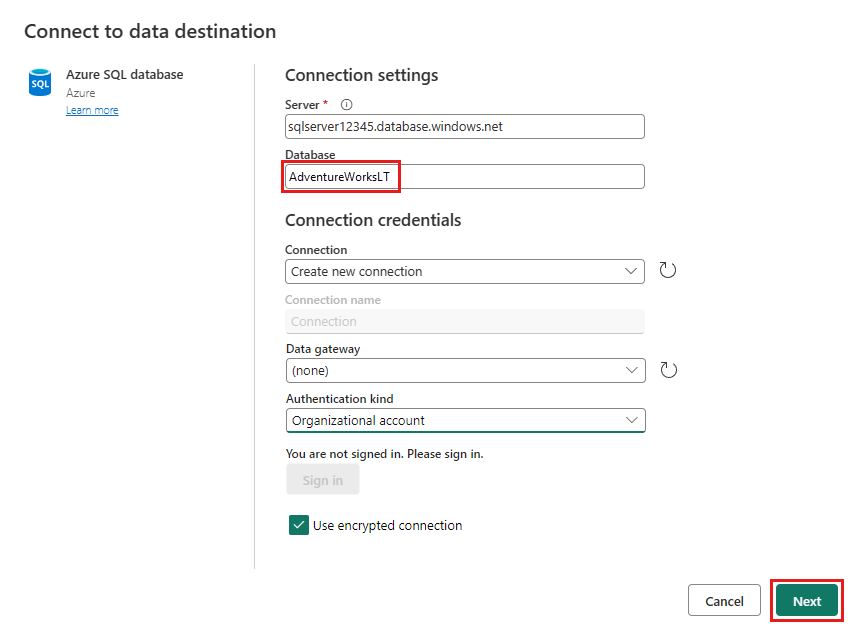
Wybierz bazę danych do przechowywania danych i podaj nazwę tabeli, a następnie wybierz pozycję Dalej.
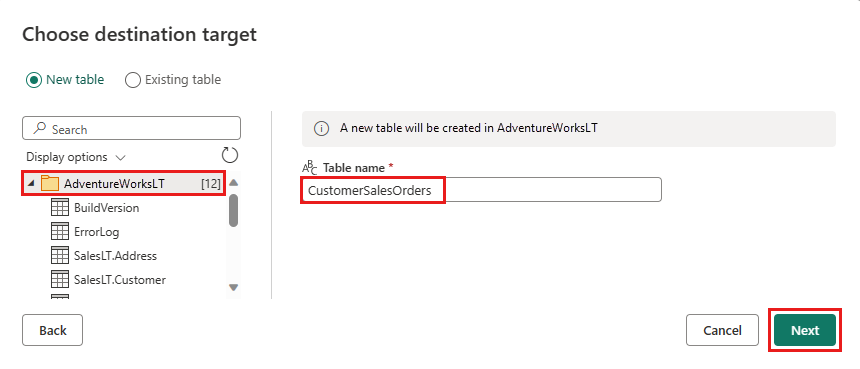
Możesz pozostawić ustawienia domyślne w oknie dialogowym Wybieranie ustawień docelowych, a następnie wybrać Zapisz ustawienia bez wprowadzania żadnych zmian w tym miejscu.
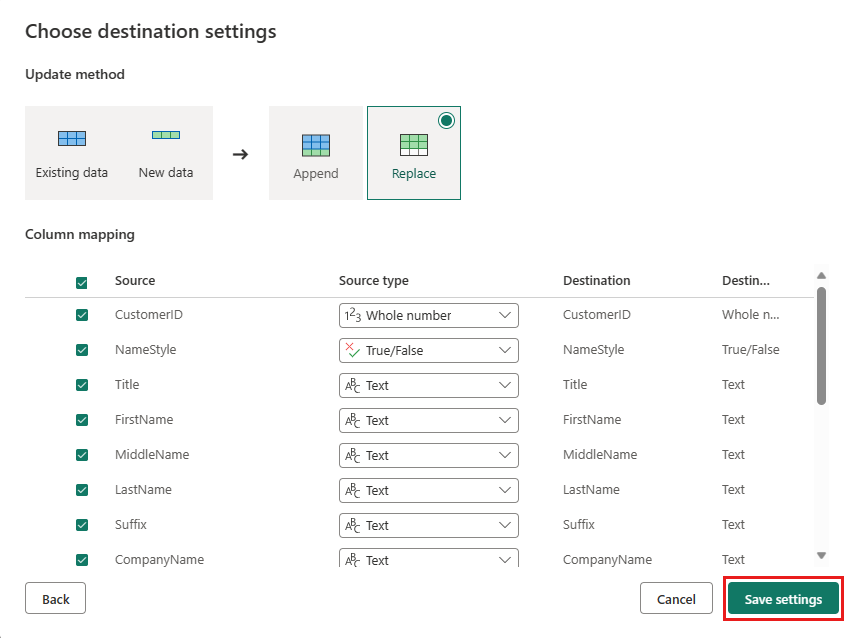
Wybierz pozycję Opublikuj z powrotem na stronie edytora przepływów danych, aby opublikować przepływ danych.



Przenoszenie danych za pomocą potoków danych
Teraz, gdy utworzyłeś przepływ danych Gen2, możesz na nim operować w potoku. W tym przykładzie skopiujesz dane wygenerowane z przepływu danych do formatu tekstowego na koncie usługi Azure Blob Storage.
Krok 1. Tworzenie nowego potoku danych
W obszarze roboczym wybierz pozycję Nowy, a następnie wybierz pozycję Potok danych.
Nadaj nazwę potokowi, a następnie wybierz Utwórz.
Krok 2. Konfigurowanie przepływu danych
Dodaj nowe działanie przepływu danych do potoku danych, wybierając pozycję Przepływ danych na karcie Działania.

Wybierz przepływ danych na kanwie potoku, a następnie kartę Ustawienia. Wybierz utworzony wcześniej przepływ danych z listy rozwijanej.
Wybierz pozycję Zapisz, a następnie Uruchom, aby uruchomić przepływ danych, aby początkowo wypełnić scaloną tabelę zapytań zaprojektowaną w poprzednim kroku.
Krok 3. Dodawanie działania kopiowania za pomocą asystenta kopiowania
Wybierz pozycję Kopiuj dane na kanwie, aby otworzyć narzędzie asystenta kopiowania, aby rozpocząć pracę. Możesz też wybrać pozycję Użyj asystenta kopiowania z listy rozwijanej kopiowania danych znajdującej się na karcie Działania na wstążce.
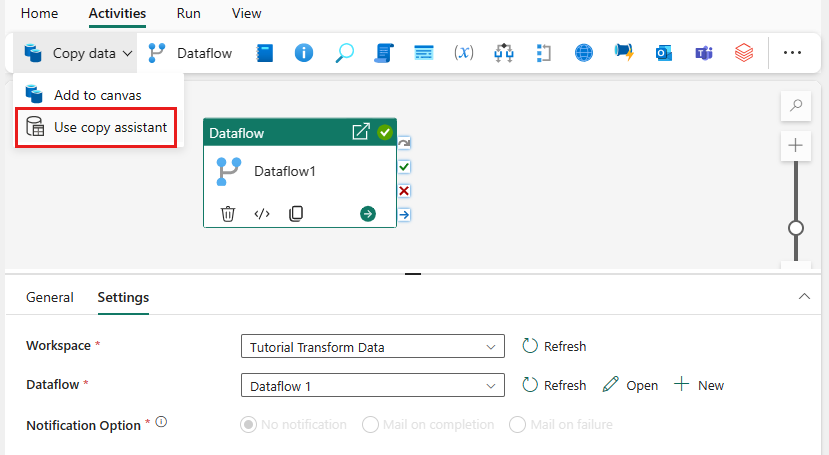
Wybierz źródło danych, wybierając typ źródła danych. W tym samouczku użyjesz usługi Azure SQL Database użytej wcześniej podczas tworzenia przepływu danych, aby wygenerować nowe zapytanie scalania. Przewiń w dół, poniżej przykładowych ofert danych, i wybierz kartę Azure, a następnie Azure SQL Database. Następnie wybierz pozycję Dalej, aby kontynuować.
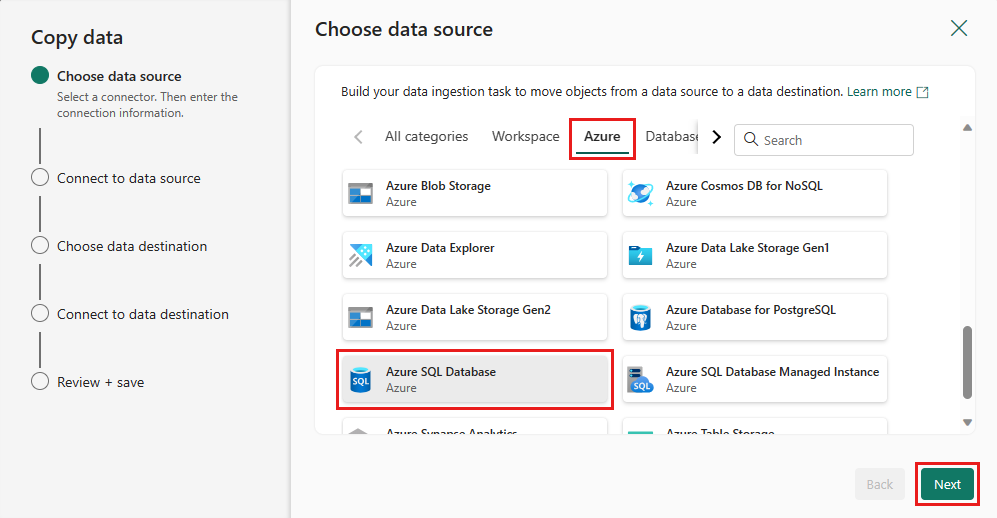
Utwórz połączenie ze źródłem danych, wybierając pozycję Utwórz nowe połączenie. Wypełnij wymagane informacje o połączeniu na panelu, a następnie wprowadź nazwę AdventureWorksLT jako nazwę bazy danych, w której wygenerowaliśmy zapytanie scalania w przepływie danych. Następnie wybierz pozycję Dalej.
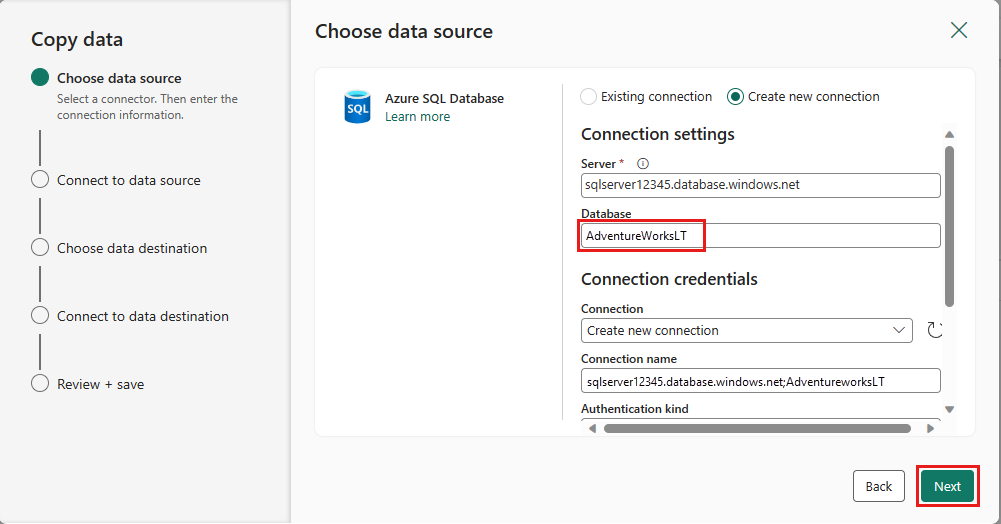
Wybierz tabelę wygenerowaną wcześniej w kroku przepływu danych, a następnie wybierz pozycję Dalej.
Jako miejsce docelowe wybierz Azure Blob Storage, a następnie Dalej.
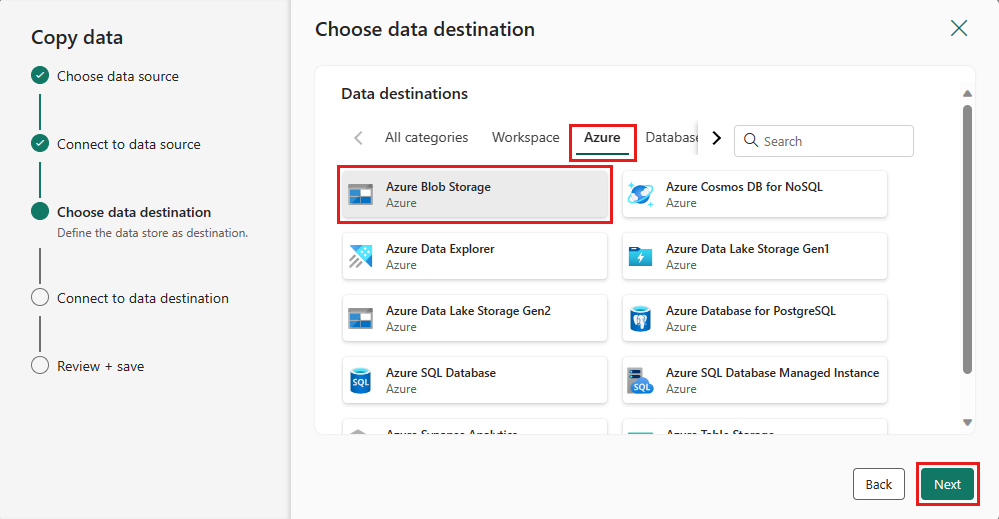
Utwórz połączenie z miejscem docelowym, wybierając pozycję Utwórz nowe połączenie. Podaj szczegóły połączenia, a następnie wybierz pozycję Dalej.
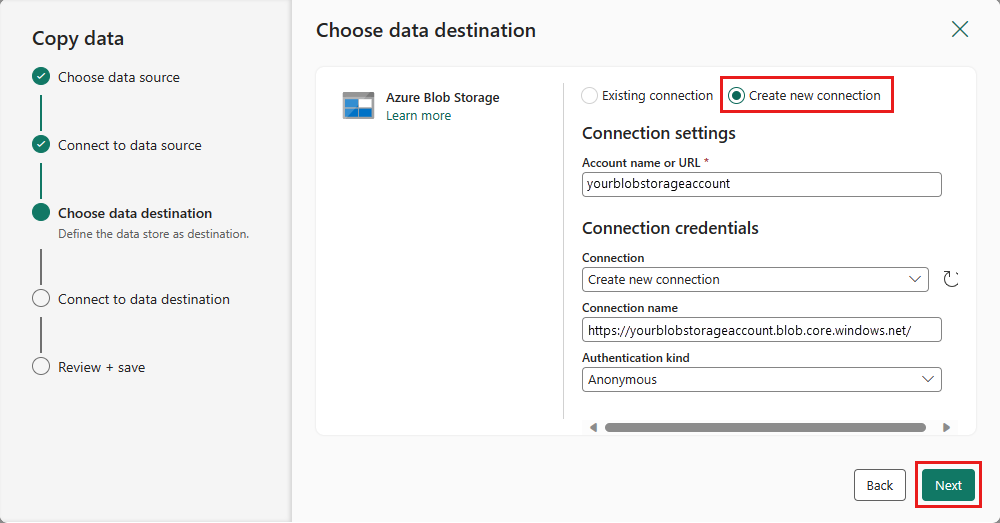
Wybierz ścieżkę folderu i podaj nazwę pliku , a następnie wybierz pozycję Dalej.
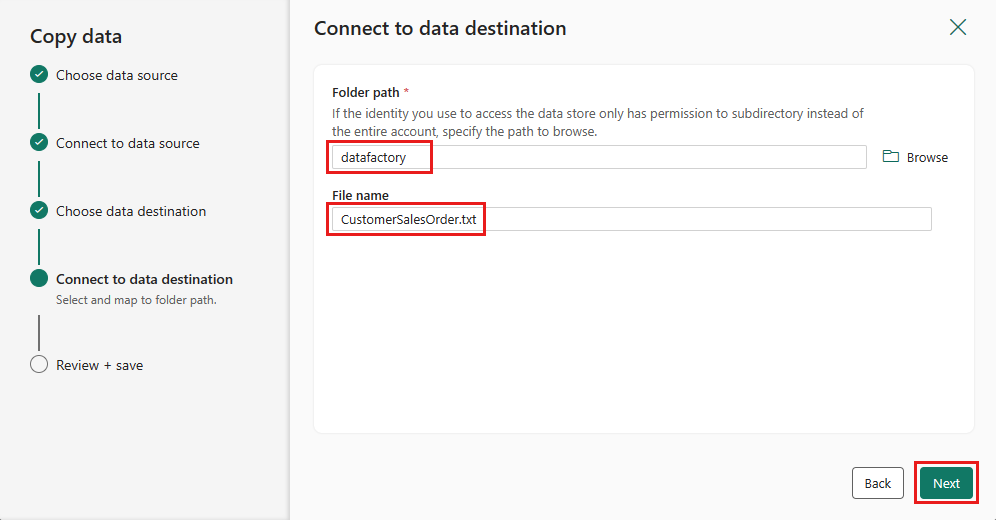
Wybierz ponownie Dalej, aby zaakceptować domyślny format pliku, ogranicznik kolumny, ogranicznik wierszy i typ kompresji, opcjonalnie w tym nagłówek.
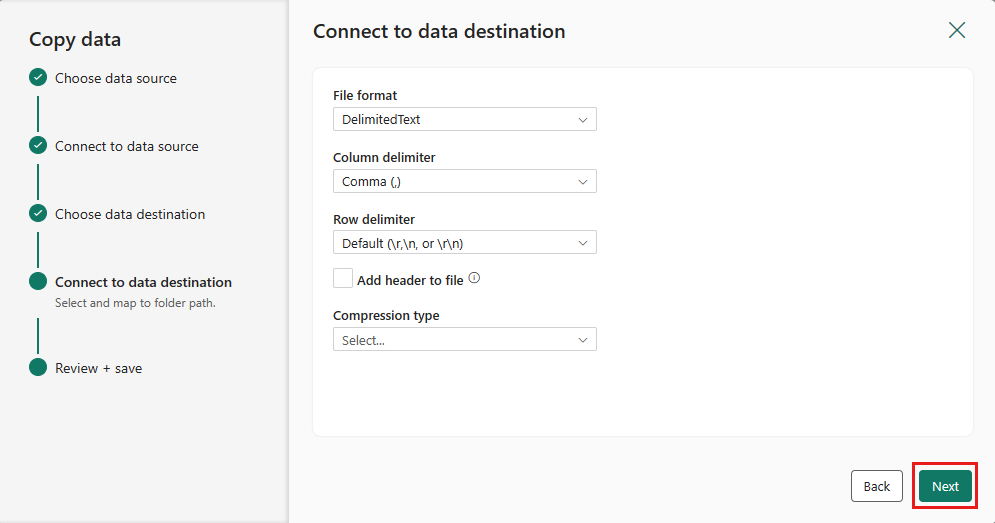
Finalizuj ustawienia. Następnie przejrzyj i wybierz pozycję Zapisz i uruchom, aby zakończyć proces.
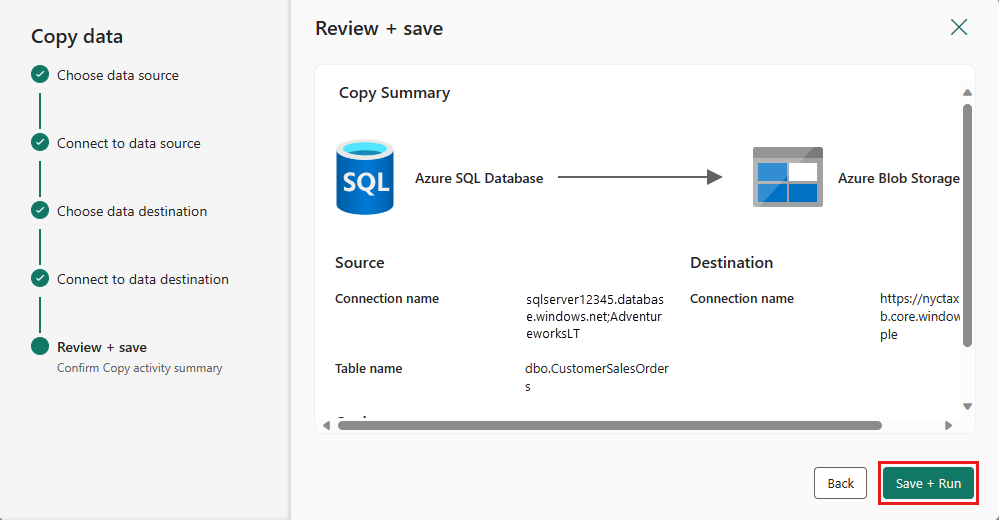
Krok 5: Zaprojektuj swój potok danych i zapisz do uruchomienia oraz załadowania danych
Aby uruchomić działanie kopiowania po działaniu Przepływ danych, przeciągnij z działania Powodzeniena działanie przepływu danych kopiowania. Działanie Kopiowanie jest uruchamiane tylko po pomyślnym zakończeniu działania Przepływ danych.

Wybierz Zapisz, aby zapisać potok danych. Następnie wybierz pozycję Uruchom, aby uruchomić potok danych i załadować dane.
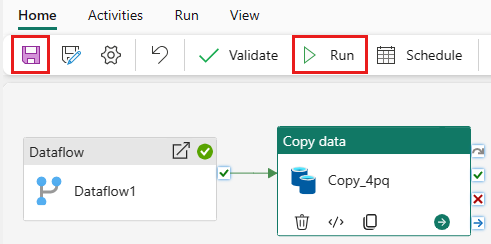
Harmonogram wykonywania potoku
Po zakończeniu tworzenia i testowania potoku możesz zaplanować jego automatyczne wykonanie.
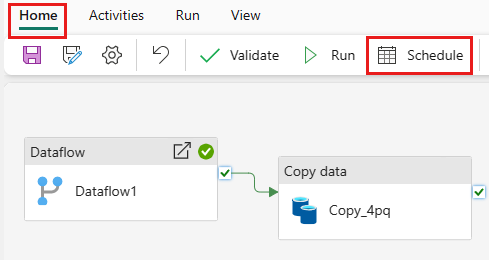
Na karcie Narzędzia główne okna edytora potoków wybierz pozycję Harmonogram.
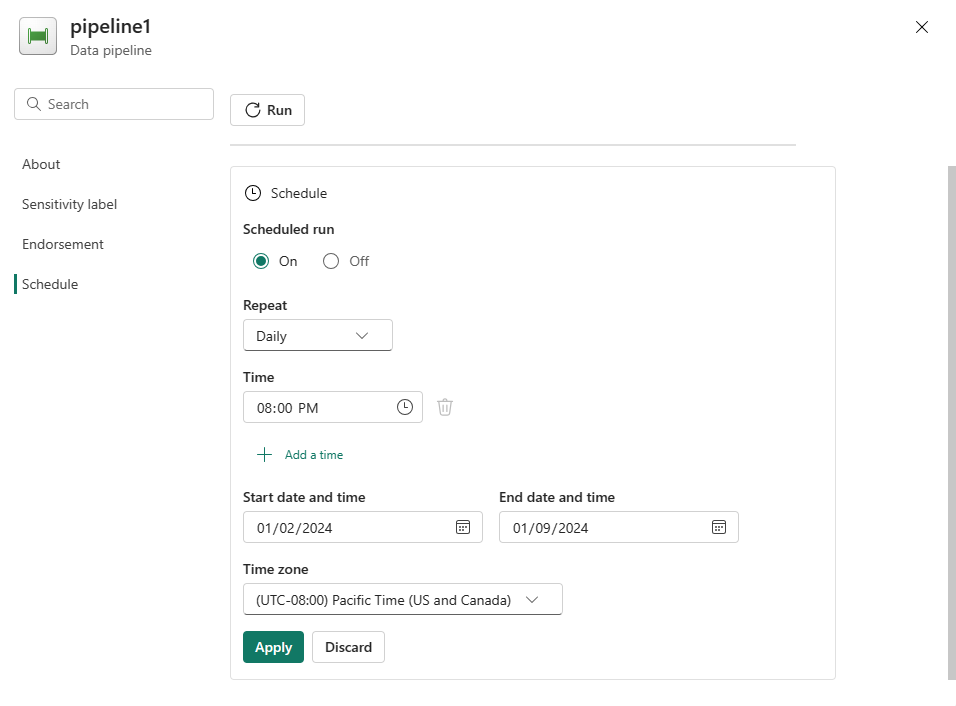
Skonfiguruj harmonogram zgodnie z wymaganiami. W tym przykładzie zaplanowano wykonywanie potoku codziennie o godzinie 18:00 do końca roku.
Powiązana zawartość
W tym przykładzie pokazano, jak utworzyć i skonfigurować przepływ danych Gen2 w celu utworzenia zapytania scalania i zapisania go w bazie danych Azure SQL Database, a następnie skopiować dane z bazy danych do pliku tekstowego w usłudze Azure Blob Storage. Wiesz już, jak wykonać następujące działania:
- Tworzenie przepływu danych.
- Przekształcanie danych za pomocą przepływu danych.
- Utwórz potok danych przy użyciu przepływu danych.
- Zleć wykonywanie kroków w potoku.
- Kopiowanie danych za pomocą Asystenta kopiowania.
- Uruchom i zaplanuj swój potok danych.
Następnie kontynuuj, aby dowiedzieć się więcej na temat monitorowania przebiegów potoku.