Miejsca docelowe danych i ustawienia zarządzane przepływu danych gen2
Po wyczyszczeniu i przygotowaniu danych za pomocą usługi Dataflow Gen2 chcesz umieścić dane w miejscu docelowym. Można to zrobić przy użyciu funkcji miejsca docelowego danych w usłudze Dataflow Gen2. Dzięki tej funkcji możesz wybrać różne miejsca docelowe, takie jak Azure SQL, Fabric Lakehouse i wiele innych. Następnie przepływ danych Gen2 zapisuje dane w miejscu docelowym i stamtąd możesz użyć danych do dalszej analizy i raportowania.
Poniższa lista zawiera obsługiwane miejsca docelowe danych.
- Bazy danych Azure SQL Database
- Azure Data Explorer (Kusto)
- Sieć szkieletowa Lakehouse
- Magazyn sieci szkieletowej
- Baza danych KQL sieci szkieletowej
- Sieć szkieletowa SQL Database
Punkty wejścia
Każde zapytanie dotyczące danych w przepływie danych Gen2 może mieć miejsce docelowe danych. Funkcje i listy nie są obsługiwane; Można go stosować tylko do zapytań tabelarycznych. Możesz określić miejsce docelowe danych dla każdego zapytania indywidualnie i użyć wielu różnych miejsc docelowych w przepływie danych.
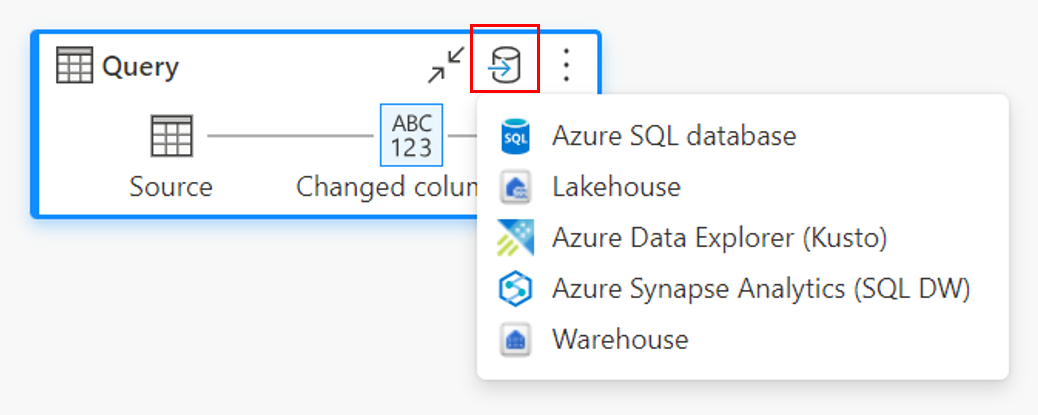
Istnieją trzy główne punkty wejścia do określenia miejsca docelowego danych:
Za pośrednictwem górnej wstążki.
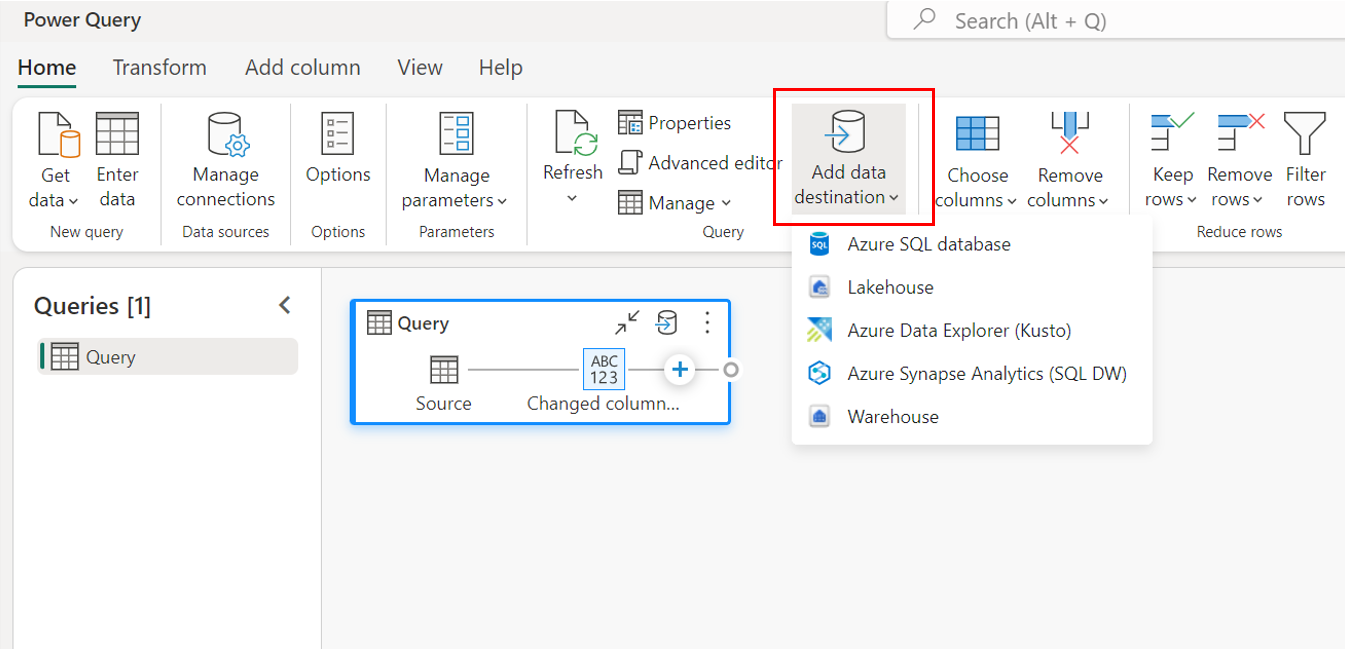
Za pomocą ustawień zapytania.
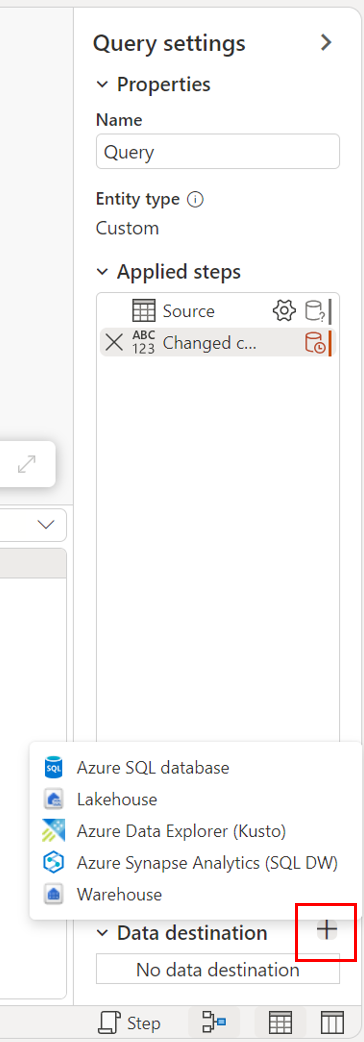
Za pomocą widoku diagramu.
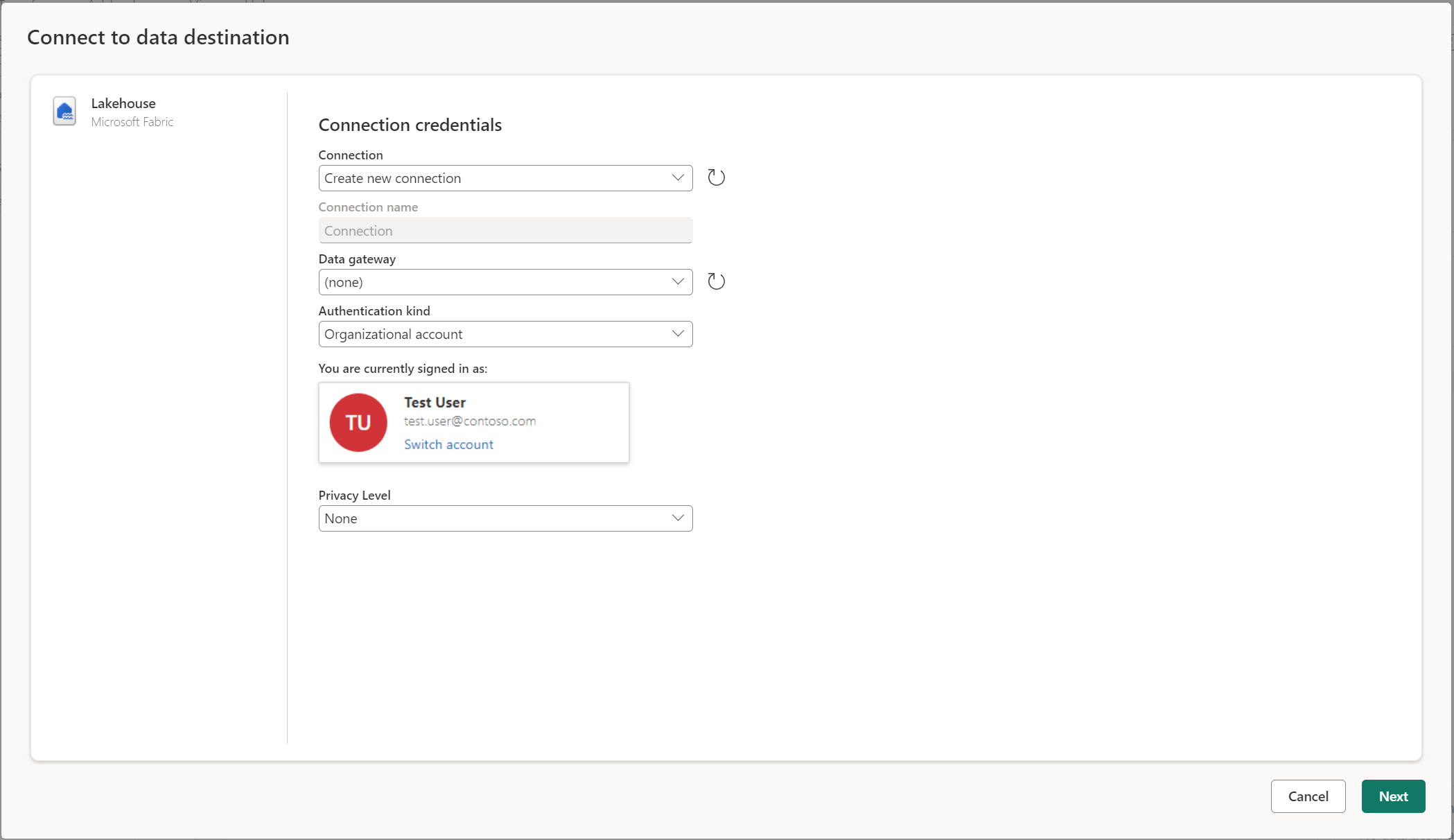
Nawiązywanie połączenia z miejscem docelowym danych
Nawiązywanie połączenia z miejscem docelowym danych jest podobne do nawiązywania połączenia ze źródłem danych. Połączenia mogą służyć zarówno do odczytywania, jak i zapisywania danych, ponieważ masz odpowiednie uprawnienia do źródła danych. Musisz utworzyć nowe połączenie lub wybrać istniejące połączenie, a następnie wybrać pozycję Dalej.
Tworzenie nowej tabeli lub wybieranie istniejącej tabeli
Podczas ładowania do miejsca docelowego danych możesz utworzyć nową tabelę lub wybrać istniejącą tabelę.
Utwórz nową tabelę
Gdy zdecydujesz się utworzyć nową tabelę, podczas odświeżania przepływu danych gen2 zostanie utworzona nowa tabela w miejscu docelowym danych. Jeśli tabela zostanie usunięta w przyszłości, ręcznie przechodząc do miejsca docelowego, przepływ danych ponownie utworzy tabelę podczas następnego odświeżania przepływu danych.
Domyślnie nazwa tabeli ma taką samą nazwę jak nazwa zapytania. Jeśli w nazwie tabeli istnieją nieprawidłowe znaki, które nie są obsługiwane przez miejsce docelowe, nazwa tabeli zostanie automatycznie skorygowana. Na przykład wiele miejsc docelowych nie obsługuje spacji ani znaków specjalnych.

Następnie należy wybrać kontener docelowy. Jeśli wybrano dowolne miejsce docelowe danych sieci szkieletowej, możesz użyć nawigatora, aby wybrać artefakt sieci szkieletowej, do którego chcesz załadować dane. W przypadku miejsc docelowych platformy Azure możesz określić bazę danych podczas tworzenia połączenia lub wybrać bazę danych w środowisku nawigatora.
Korzystanie z istniejącej tabeli
Aby wybrać istniejącą tabelę, użyj przełącznika w górnej części nawigatora. Podczas wybierania istniejącej tabeli należy wybrać zarówno artefakt sieci szkieletowej, jak i tabelę przy użyciu nawigatora.
Jeśli używasz istniejącej tabeli, nie można jej odtworzyć w żadnym scenariuszu. Jeśli tabela zostanie usunięta ręcznie z miejsca docelowego danych, usługa Dataflow Gen2 nie utworzy ponownie tabeli podczas następnego odświeżania.
Ustawienia zarządzane dla nowych tabel
Podczas ładowania do nowej tabeli ustawienia automatyczne są domyślnie włączone. Jeśli używasz ustawień automatycznych, przepływ danych Gen2 zarządza mapowaniem. Ustawienia automatyczne zapewniają następujące zachowanie:
Wymiana metody aktualizacji: dane są zastępowane podczas każdego odświeżania przepływu danych. Wszystkie dane w miejscu docelowym zostaną usunięte. Dane w miejscu docelowym są zastępowane danymi wyjściowymi przepływu danych.
Mapowanie zarządzane: mapowanie jest zarządzane. Jeśli musisz wprowadzić zmiany w danych/zapytaniu w celu dodania innej kolumny lub zmiany typu danych, mapowanie jest automatycznie dostosowywane do tej zmiany podczas ponownego publikowania przepływu danych. Nie trzeba przechodzić do środowiska docelowego danych za każdym razem, gdy wprowadzasz zmiany w przepływie danych, co pozwala na łatwe zmiany schematu podczas ponownego publikowania przepływu danych.
Upuść i utwórz ponownie tabelę: aby zezwolić na te zmiany schematu, po każdym odświeżeniu przepływu danych tabela zostanie porzucona i utworzona ponownie. Odświeżanie przepływu danych może spowodować usunięcie relacji lub miar, które zostały wcześniej dodane do tabeli.
Uwaga
Obecnie ustawienie automatyczne jest obsługiwane tylko dla usług Lakehouse i Azure SQL Database jako miejsca docelowego danych.
Ustawienia ręczne
Za pomocą funkcji Użyj ustawień automatycznych uzyskasz pełną kontrolę nad sposobem ładowania danych do miejsca docelowego danych. Możesz wprowadzić zmiany w mapowaniu kolumn, zmieniając typ źródła lub wykluczając dowolną kolumnę, której nie potrzebujesz w miejscu docelowym danych.
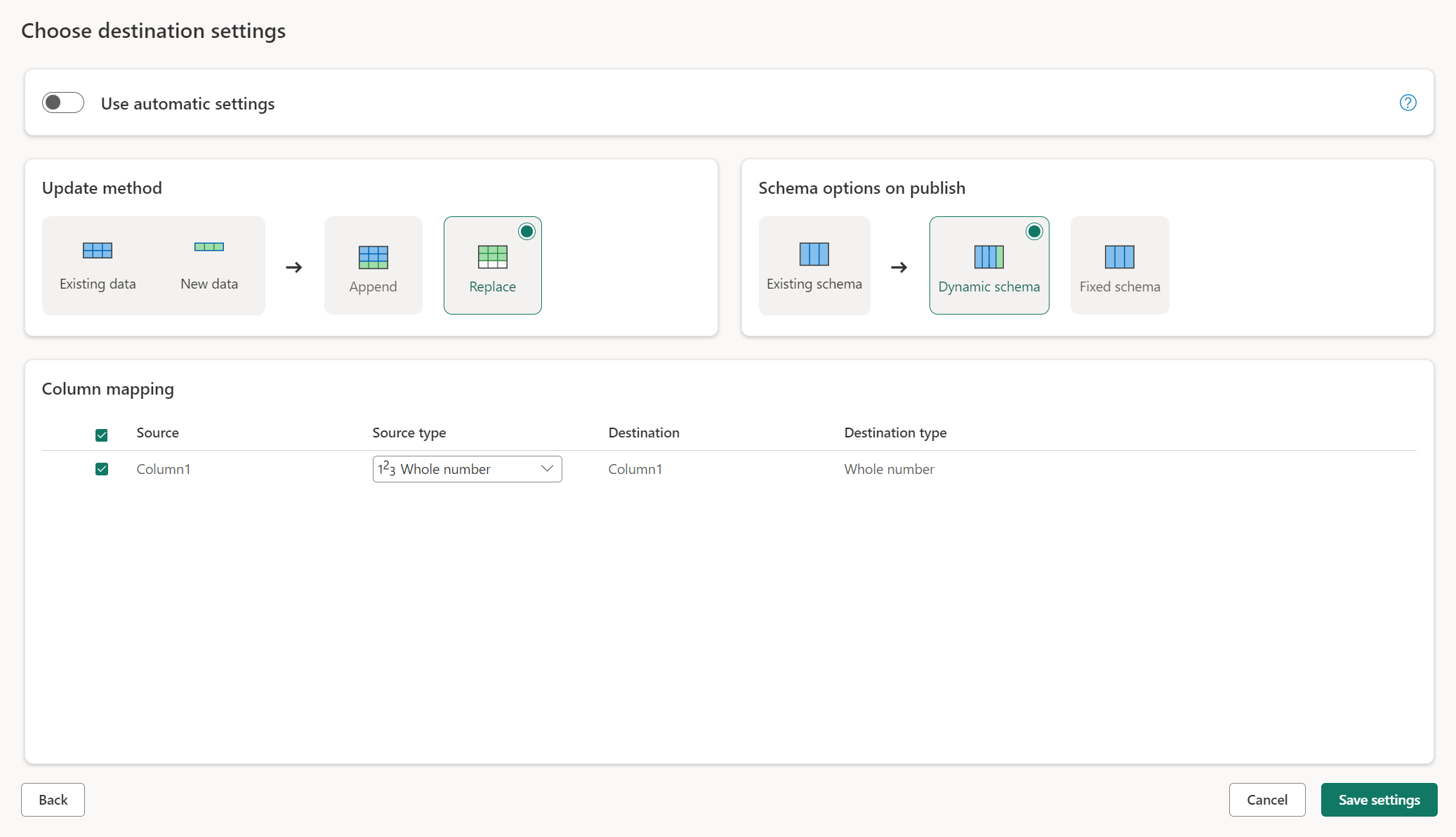
Metody aktualizacji
Większość miejsc docelowych obsługuje zarówno dołączanie, jak i zastępowanie jako metody aktualizacji. Jednak bazy danych KQL sieci szkieletowej i usługa Azure Data Explorer nie obsługują zastępowania jako metody aktualizacji.
Zastąp: podczas każdego odświeżania przepływu danych dane są usuwane z miejsca docelowego i zastępowane danymi wyjściowymi przepływu danych.
Dołączanie: podczas każdego odświeżania przepływu danych dane wyjściowe z przepływu danych są dołączane do istniejących danych w tabeli docelowej danych.
Opcje schematu publikowania
Opcje schematu publikowania mają zastosowanie tylko wtedy, gdy metoda aktualizacji zostanie zamieniona. Podczas dołączania danych zmiany schematu nie są możliwe.
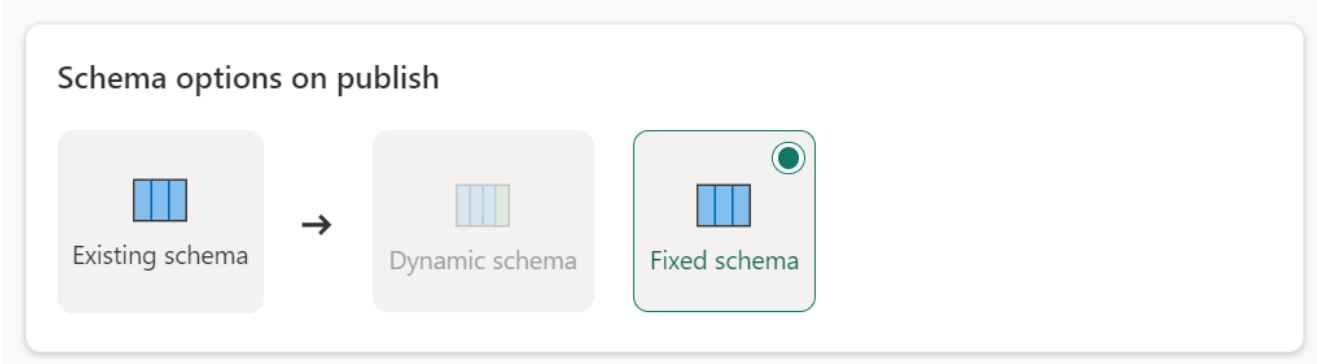
Schemat dynamiczny: podczas wybierania schematu dynamicznego można zezwolić na zmiany schematu w miejscu docelowym danych podczas ponownego publikowania przepływu danych. Ponieważ nie używasz mapowania zarządzanego, nadal musisz zaktualizować mapowanie kolumn w przepływie docelowym przepływu danych po wprowadzeniu jakichkolwiek zmian w zapytaniu. Po odświeżeniu przepływu danych tabela zostanie porzucona i ponownie utworzona. Odświeżanie przepływu danych może spowodować usunięcie relacji lub miar, które zostały wcześniej dodane do tabeli.
Stały schemat: po wybraniu stałego schematu zmiany schematu nie są możliwe. Po odświeżeniu przepływu danych tylko wiersze w tabeli zostaną porzucone i zastąpione danymi wyjściowymi z przepływu danych. Wszystkie relacje lub miary w tabeli pozostają nienaruszone. Jeśli wprowadzisz jakiekolwiek zmiany w zapytaniu w przepływie danych, publikowanie przepływu danych zakończy się niepowodzeniem, jeśli wykryje, że schemat zapytania nie jest zgodny ze schematem docelowym danych. Użyj tego ustawienia, jeśli nie planujesz zmiany schematu i mają relacje lub miarę dodaną do tabeli docelowej.
Uwaga
Podczas ładowania danych do magazynu obsługiwane jest tylko stałe schematy.
Obsługiwane typy źródeł danych na miejsce docelowe
| Obsługiwane typy danych na lokalizację magazynu | DataflowStagingLakehouse | Dane wyjściowe usługi Azure DB (SQL) | Dane wyjściowe usługi Azure Data Explorer | Wyjście usługi Fabric Lakehouse (LH) | Dane wyjściowe magazynu sieci szkieletowej (WH) | Dane wyjściowe usługi Sql Database (SQL) sieci szkieletowej |
|---|---|---|---|---|---|---|
| Akcja | Nie | Nie. | Nie. | Nie. | Nie. | Nie. |
| Dowolne | Nie | Nie. | Nie. | Nie. | Nie. | Nie. |
| Plik binarny | Nie | Nie. | Nie. | Nie. | Nie. | Nie |
| Waluta | Tak | Tak | Tak | Tak | Nie | Tak |
| DateTimeZone | Tak | Tak | Tak | Nie. | Nie. | Tak |
| Duration | Nie | Nie. | Tak | Nie. | Nie. | Nie. |
| Function | Nie | Nie. | Nie. | Nie. | Nie. | Nie |
| Brak | Nie | Nie. | Nie. | Nie. | Nie. | Nie. |
| Null (zero) | Nie | Nie. | Nie. | Nie. | Nie. | Nie. |
| Czas | Tak | Tak | Nie. | Nie. | Nie. | Tak |
| Typ | Nie | Nie. | Nie. | Nie. | Nie. | Nie. |
| Ustrukturyzowana (lista, rekord, tabela) | Nie | Nie. | Nie. | Nie. | Nie. | Nie. |
Tematy zaawansowane
Używanie przemieszczania przed załadowaniem do miejsca docelowego
Aby zwiększyć wydajność przetwarzania zapytań, przemieszczanie może być używane w ramach przepływów danych Gen2 do używania obliczeń sieci szkieletowej do wykonywania zapytań.
W przypadku włączenia przemieszczania w zapytaniach (domyślne zachowanie) dane są ładowane do lokalizacji przejściowej, która jest wewnętrzną usługą Lakehouse dostępną tylko przez przepływy danych.
Użycie lokalizacji przejściowych może zwiększyć wydajność w niektórych przypadkach, w których składanie zapytania do punktu końcowego analizy SQL jest szybsze niż w przetwarzaniu pamięci.
Podczas ładowania danych do usługi Lakehouse lub innych miejsc docelowych innych niż magazyn domyślnie wyłączamy funkcję przemieszczania, aby zwiększyć wydajność. Podczas ładowania danych do miejsca docelowego danych dane są zapisywane bezpośrednio w miejscu docelowym danych bez użycia przemieszczania. Jeśli chcesz użyć przemieszczania dla zapytania, możesz włączyć je ponownie.
Aby włączyć przemieszczanie, kliknij prawym przyciskiem myszy zapytanie i włącz przemieszczanie, wybierając przycisk Włącz przemieszczanie . Następnie zapytanie zmieni kolor na niebieski.
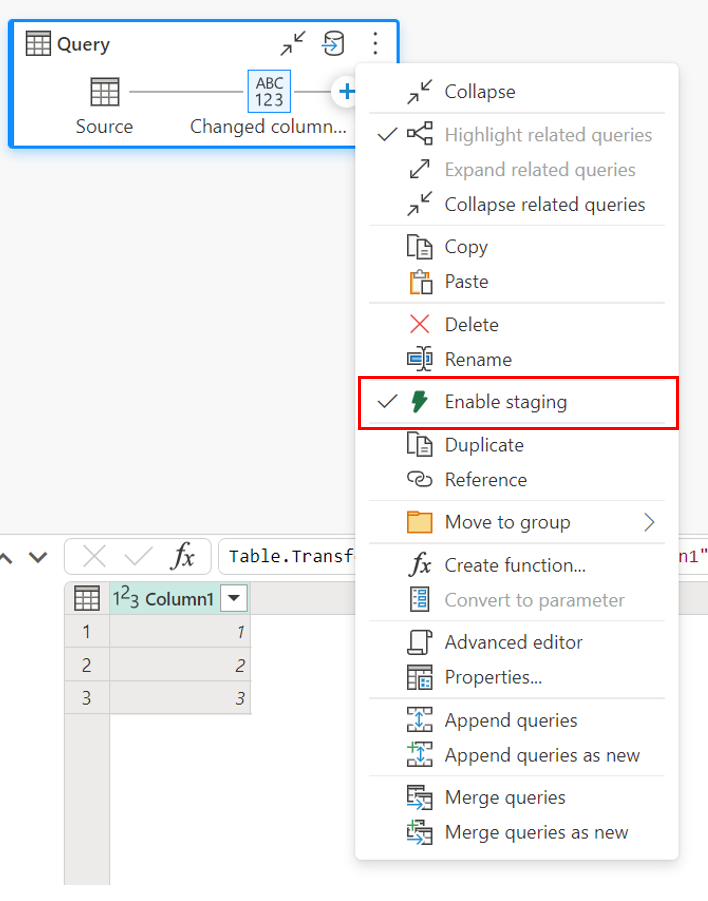
Ładowanie danych do magazynu
Podczas ładowania danych do magazynu wymagane jest przemieszczanie przed operacją zapisu w miejscu docelowym danych. To wymaganie poprawia wydajność. Obecnie obsługiwane jest tylko ładowanie do tego samego obszaru roboczego co przepływ danych. Upewnij się, że dla wszystkich zapytań ładowanych do magazynu włączono przemieszczanie.
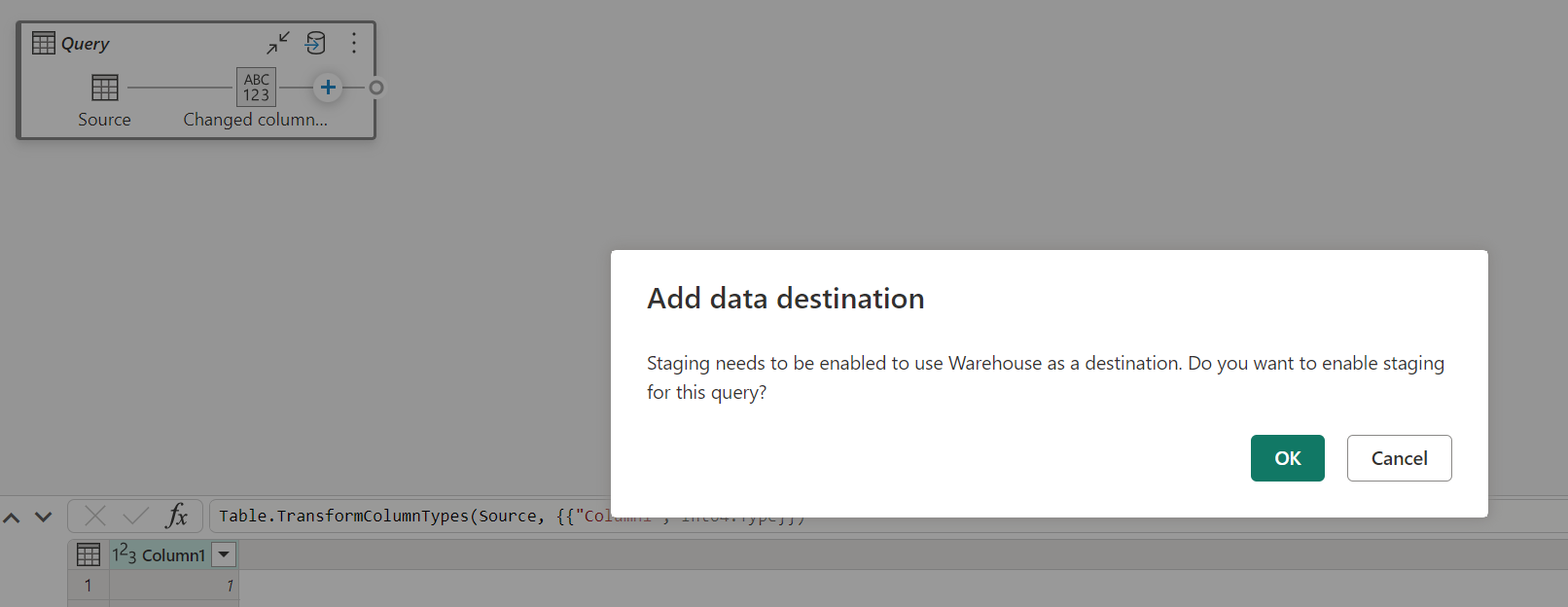
Gdy przemieszczanie jest wyłączone, a jako miejsce docelowe danych wyjściowych wybierzesz pozycję Magazyn, przed skonfigurowaniem miejsca docelowego danych zostanie wyświetlone ostrzeżenie o włączeniu przemieszczania.
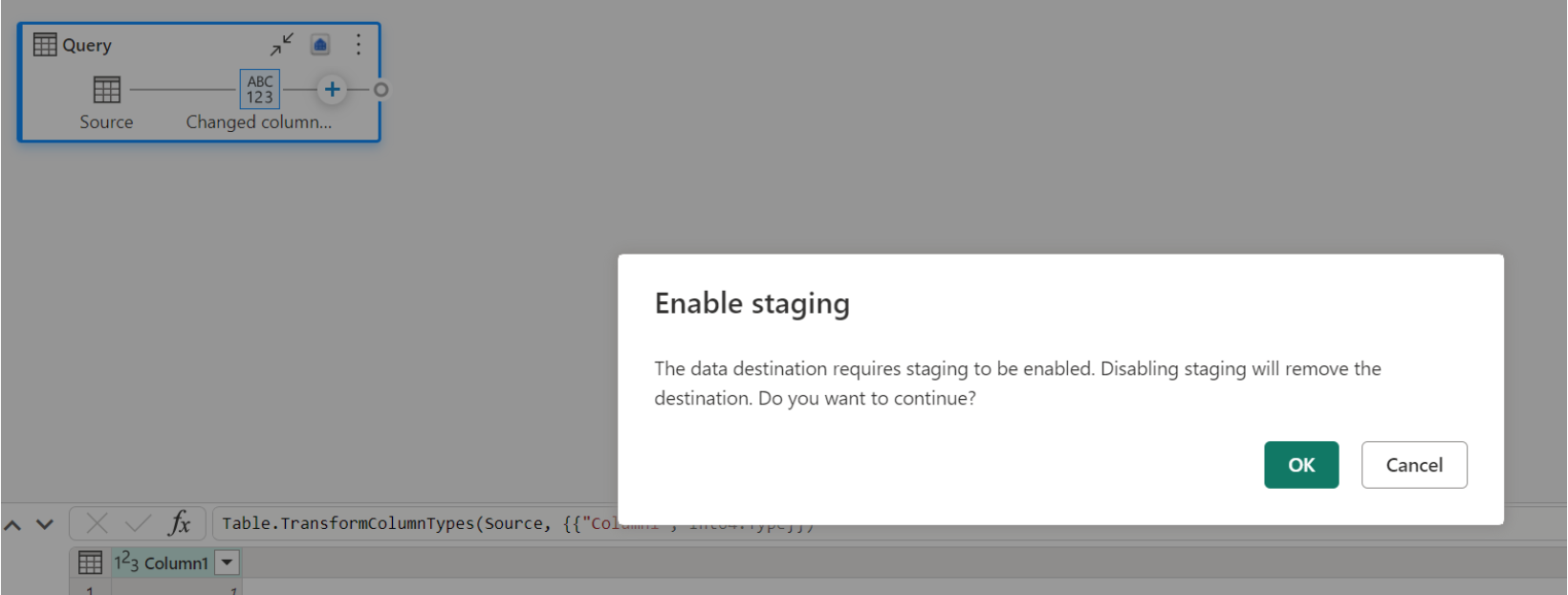
Jeśli magazyn jest już miejscem docelowym i spróbuj wyłączyć przemieszczanie, zostanie wyświetlone ostrzeżenie. Magazyn można usunąć jako miejsce docelowe lub odrzucić akcję tymczasową.
Opróżnianie miejsca docelowego danych usługi Lakehouse
W przypadku korzystania z usługi Lakehouse jako miejsca docelowego dla usługi Dataflow Gen2 w usłudze Microsoft Fabric ważne jest regularne wykonywanie konserwacji w celu zapewnienia optymalnej wydajności i wydajnego zarządzania magazynem. Jednym z podstawowych zadań konserwacji jest opróżnianie miejsca docelowego danych. Ten proces pomaga usunąć stare pliki, do których nie odwołuje się już dziennik tabeli delty, optymalizując w ten sposób koszty magazynowania i utrzymując integralność danych.
Dlaczego czyszczenie jest ważne
- Optymalizacja magazynu: w miarę upływu czasu tabele delty gromadzą stare pliki, które nie są już potrzebne. Czyszczenie tych plików pomaga oczyścić te pliki, zwalniając miejsce do magazynowania i zmniejszając koszty.
- Poprawa wydajności: usunięcie niepotrzebnych plików może zwiększyć wydajność zapytań, zmniejszając liczbę plików, które należy skanować podczas operacji odczytu.
- Integralność danych: zapewnienie, że tylko odpowiednie pliki są przechowywane, pomaga zachować integralność danych, zapobiegając potencjalnym problemom z niezatwierdzonych plików, które mogą prowadzić do błędów czytnika lub uszkodzenia tabeli.
Jak opróżnić miejsce docelowe danych
Aby opróżnić tabele usługi Delta w usłudze Lakehouse, wykonaj następujące kroki:
- Przejdź do usługi Lakehouse: z poziomu konta usługi Microsoft Fabric przejdź do żądanej usługi Lakehouse.
- Konserwacja tabeli dostępu: w Eksploratorze usługi Lakehouse kliknij prawym przyciskiem myszy tabelę, którą chcesz zachować, lub użyj wielokropka, aby uzyskać dostęp do menu kontekstowego.
- Wybierz opcje konserwacji: wybierz pozycję Menu Konserwacja i wybierz opcję Opróżnij.
- Uruchom polecenie opróżniania: ustaw próg przechowywania (wartość domyślna to siedem dni) i wykonaj polecenie opróżniania, wybierając pozycję Uruchom teraz.
Najlepsze rozwiązania
- Okres przechowywania: ustaw interwał przechowywania wynoszący co najmniej siedem dni, aby upewnić się, że stare migawki i niezatwierdzone pliki nie zostaną przedwcześnie usunięte, co może spowodować zakłócenia współbieżnych czytników tabel i składników zapisywania.
- Regularna konserwacja: Zaplanuj regularne czyszczenie w ramach procedury konserwacji danych, aby zachować zoptymalizowane i gotowe tabele delta do analizy.
Dzięki włączeniu czyszczenia do strategii konserwacji danych można zapewnić, że miejsce docelowe usługi Lakehouse pozostaje wydajne, ekonomiczne i niezawodne dla operacji przepływu danych.
Aby uzyskać bardziej szczegółowe informacje na temat konserwacji tabel w usłudze Lakehouse, zapoznaj się z dokumentacją konserwacji tabeli delty.
Dopuszczający wartość null
W niektórych przypadkach, gdy masz kolumnę dopuszczaną do wartości null, jest wykrywana przez dodatek Power Query jako niepusta, a podczas zapisywania w miejscu docelowym danych typ kolumny jest niepusty. Podczas odświeżania występuje następujący błąd:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Aby wymusić kolumny dopuszczane do wartości null, możesz wypróbować następujące kroki:
Usuń tabelę z miejsca docelowego danych.
Usuń miejsce docelowe danych z przepływu danych.
Przejdź do przepływu danych i zaktualizuj typy danych przy użyciu następującego kodu dodatku Power Query:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Dodaj miejsce docelowe danych.
Konwersja typów danych i skalowanie upscaling
W niektórych przypadkach typ danych w przepływie danych różni się od tego, co jest obsługiwane w miejscu docelowym danych poniżej, to niektóre domyślne konwersje wprowadzone w celu zapewnienia, że nadal można uzyskać dane w miejscu docelowym danych:
| Element docelowy | Typ danych przepływu danych | Docelowy typ danych |
|---|---|---|
| Magazyn sieci szkieletowej | Int8.Type | Int16.Type |