Konfigurowanie magazynu danych w działaniu kopiowania
W tym artykule opisano sposób używania działania kopiowania w potoku danych do kopiowania danych z i do magazynu danych.
Obsługiwana konfiguracja
W przypadku konfiguracji każdej karty w działaniu kopiowania przejdź odpowiednio do poniższych sekcji.
Ogólne
W obszarze Konfiguracja karty Ogólne przejdź do pozycji Ogólne.
Źródło
Następujące właściwości są obsługiwane w przypadku magazynu danych jako źródła w działaniu kopiowania.
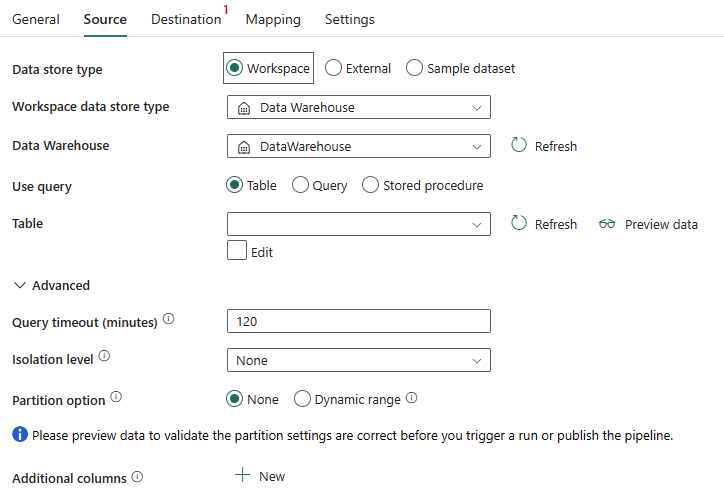
Wymagane są następujące właściwości:
Typ magazynu danych: wybierz pozycję Obszar roboczy.
Typ magazynu danych obszaru roboczego: wybierz pozycję Magazyn danych z listy typów magazynu danych.
Magazyn danych: wybierz istniejący magazyn danych z obszaru roboczego.
Użyj zapytania: Wybierz tabelę, kwerendę lub procedurę składowaną.
W przypadku wybrania pozycji Tabela wybierz istniejącą tabelę z listy tabel lub ręcznie określ nazwę tabeli, wybierając pole Edytuj .

Jeśli wybierzesz pozycję Zapytanie, użyj niestandardowego edytora zapytań SQL, aby napisać zapytanie SQL, które pobiera dane źródłowe.

Jeśli wybierzesz procedurę składowaną, wybierz istniejącą procedurę składowaną z listy rozwijanej lub określ nazwę procedury składowanej jako źródło, wybierając pole Edytuj .

W obszarze Zaawansowane można określić następujące pola:
Limit czasu zapytania (minuty): limit czasu wykonywania polecenia zapytania z wartością domyślną 120 minut. Jeśli ta właściwość jest ustawiona, dozwolone wartości są w formacie przedziału czasu, na przykład "02:00:00" (120 minut).
Poziom izolacji: określ zachowanie blokowania transakcji dla źródła SQL.
Opcja partycji: określ opcje partycjonowania danych używane do ładowania danych z magazynu danych. Możesz wybrać opcję Brak lub Zakres dynamiczny.
W przypadku wybrania pozycji Zakres dynamiczny parametr partycji zakresu (
?AdfDynamicRangePartitionCondition) jest wymagany podczas korzystania z zapytania z włączonym równoległym. Przykładowe zapytanie:SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition.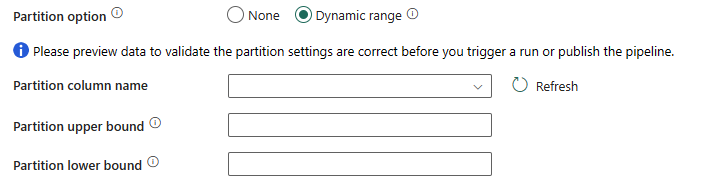
- Nazwa kolumny partycji: określ nazwę kolumny źródłowej w integer lub typ daty/daty/godziny (
int,smallint,bigintdatesmalldatetime,datetimedatetime2, lubdatetimeoffset) używany przez partycjonowanie zakresu na potrzeby kopiowania równoległego. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli jest wykrywany automatycznie i używany jako kolumna partycji. - Górna granica partycji: maksymalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania są partycjonowane i kopiowane.
- Dolna granica partycji: minimalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania są partycjonowane i kopiowane.
- Nazwa kolumny partycji: określ nazwę kolumny źródłowej w integer lub typ daty/daty/godziny (
Dodatkowe kolumny: Dodaj dodatkowe kolumny danych, aby przechowywać ścieżkę względną plików źródłowych lub wartość statyczną. Wyrażenie jest obsługiwane w przypadku tych ostatnich.


Element docelowy
Następujące właściwości są obsługiwane w przypadku magazynu danych jako miejsca docelowego w działaniu kopiowania.
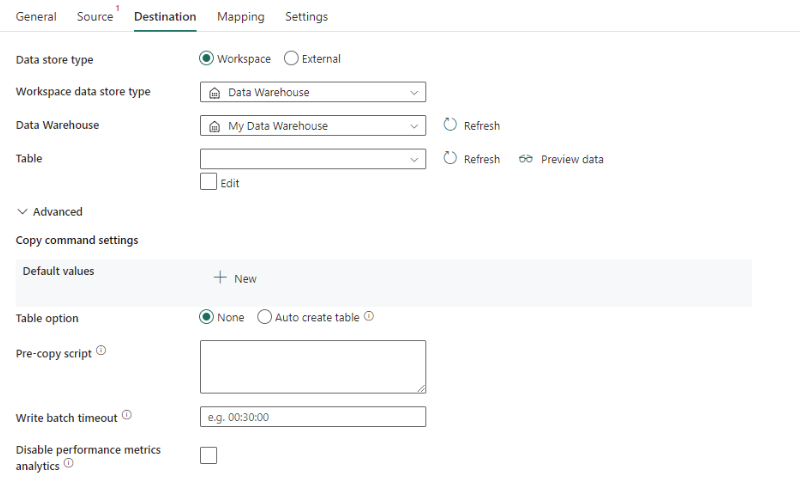
Wymagane są następujące właściwości:
- Typ magazynu danych: wybierz pozycję Obszar roboczy.
- Typ magazynu danych obszaru roboczego: wybierz pozycję Magazyn danych z listy typów magazynu danych.
- Magazyn danych: wybierz istniejący magazyn danych z obszaru roboczego.
- Tabela: wybierz istniejącą tabelę z listy tabel lub określ nazwę tabeli jako miejsce docelowe.
W obszarze Zaawansowane można określić następujące pola:
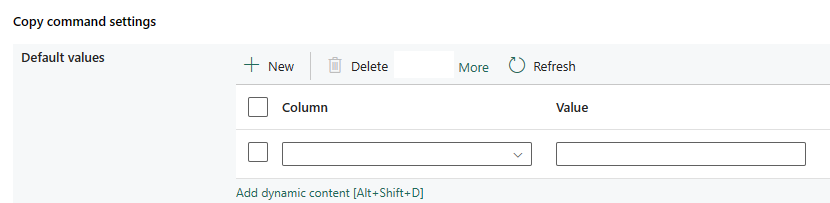
Kopiuj ustawienia polecenia: Określ właściwości polecenia kopiowania.
Opcje tabeli: określ, czy automatycznie utworzyć tabelę docelową, jeśli żadna z nich nie istnieje na podstawie schematu źródłowego. Możesz wybrać pozycję Brak lub Automatycznie utworzyć tabelę.
Skrypt wstępny: określ zapytanie SQL do uruchomienia przed zapisaniem danych w usłudze Data Warehouse w każdym uruchomieniu. Użyj tej właściwości, aby wyczyścić wstępnie załadowane dane.
Limit czasu zapisu wsadowego: czas oczekiwania na zakończenie operacji wstawiania wsadowego przed przekroczeniem limitu czasu. Dozwolone wartości są w formacie przedziału czasu. Wartość domyślna to "00:30:00" (30 minut).
Wyłącz analizę metryk wydajności: usługa zbiera metryki na potrzeby optymalizacji wydajności kopiowania i zaleceń. Jeśli interesuje Cię to zachowanie, wyłącz tę funkcję.
Kopiowanie bezpośrednie
Instrukcja COPY to podstawowy sposób pozyskiwania danych do tabel magazynu. Polecenie COPY magazynu danych obsługuje bezpośrednio usługi Azure Blob Storage i Azure Data Lake Storage Gen2 jako źródłowe magazyny danych. Jeśli dane źródłowe spełniają kryteria opisane w tej sekcji, użyj polecenia COPY, aby skopiować bezpośrednio ze źródłowego magazynu danych do magazynu danych.
Dane źródłowe i format zawierają następujące typy i metody uwierzytelniania:
Obsługiwany typ magazynu danych źródłowych Obsługiwany format Obsługiwany typ uwierzytelniania źródłowego Azure Blob Storage Rozdzielany tekst
ParquetUwierzytelnianie anonimowe
Uwierzytelnianie klucza konta
Uwierzytelnianie sygnatury dostępu współdzielonegoAzure Data Lake Storage Gen2 Rozdzielany tekst
ParquetUwierzytelnianie klucza konta
Uwierzytelnianie sygnatury dostępu współdzielonegoMożna ustawić następujące ustawienia formatu:
- W przypadku parquet: typ kompresji może mieć wartość None, snappy lub gzip.
- Dla tekstu rozdzielanego:
- Ogranicznik wierszy: podczas kopiowania tekstu rozdzielanego do magazynu danych za pomocą bezpośredniego polecenia COPY określ jawnie ogranicznik wierszy (\r; \n; lub \r\n). Tylko wtedy, gdy ogranicznik wiersza pliku źródłowego to \r\n, wartość domyślna (\r, \n lub \r\n). W przeciwnym razie włącz przemieszczanie dla danego scenariusza.
- Wartość null jest pozostawiona jako domyślna lub ustawiona na pusty ciąg ("").
- Kodowanie jest pozostawione jako domyślne lub ustawione na UTF-8 lub UTF-16.
- Pomiń liczbę wierszy jest pozostawiona jako domyślna lub ustawiona na 0.
- Typ kompresji może mieć wartość Brak lub gzip.
Jeśli źródło jest folderem, należy zaznaczyć pole wyboru Rekursywnie .
Czas rozpoczęcia (UTC) i godzina zakończenia (UTC) w obszarze Filtruj według ostatniej modyfikacji, Prefiksu, Włącz odnajdywanie partycji i Dodatkowe kolumny nie są określone.
Aby dowiedzieć się, jak pozyskiwać dane do magazynu danych przy użyciu polecenia COPY, zobacz ten artykuł.
Jeśli źródłowy magazyn danych i format nie są pierwotnie obsługiwane przez polecenie COPY, użyj funkcji kopiowania etapowego za pomocą funkcji polecenia COPY. Automatycznie konwertuje dane na format zgodny z poleceniem COPY, a następnie wywołuje polecenie COPY w celu załadowania danych do magazynu danych.
Kopia etapowa
Jeśli dane źródłowe nie są natywnie zgodne z poleceniem COPY, włącz kopiowanie danych za pośrednictwem tymczasowego magazynu przejściowego. W takim przypadku usługa automatycznie konwertuje dane, aby spełniały wymagania dotyczące formatu danych polecenia COPY. Następnie wywołuje polecenie COPY w celu załadowania danych do magazynu danych. Na koniec czyści dane tymczasowe z magazynu.
Aby użyć kopiowania etapowego, przejdź do karty Ustawienia i wybierz pozycję Włącz przemieszczanie. Możesz wybrać obszar roboczy , aby użyć automatycznie utworzonego magazynu przejściowego w ramach sieci szkieletowej. W przypadku magazynu zewnętrznego usługi Azure Blob Storage i Usługi Azure Data Lake Storage Gen2 są obsługiwane jako zewnętrzny magazyn przejściowy. Najpierw musisz utworzyć połączenie usługi Azure Blob Storage lub Azure Data Lake Storage Gen2, a następnie wybrać połączenie z listy rozwijanej, aby użyć magazynu przejściowego.
Należy pamiętać, że zakres adresów IP magazynu danych został poprawnie dozwolony z magazynu przejściowego.
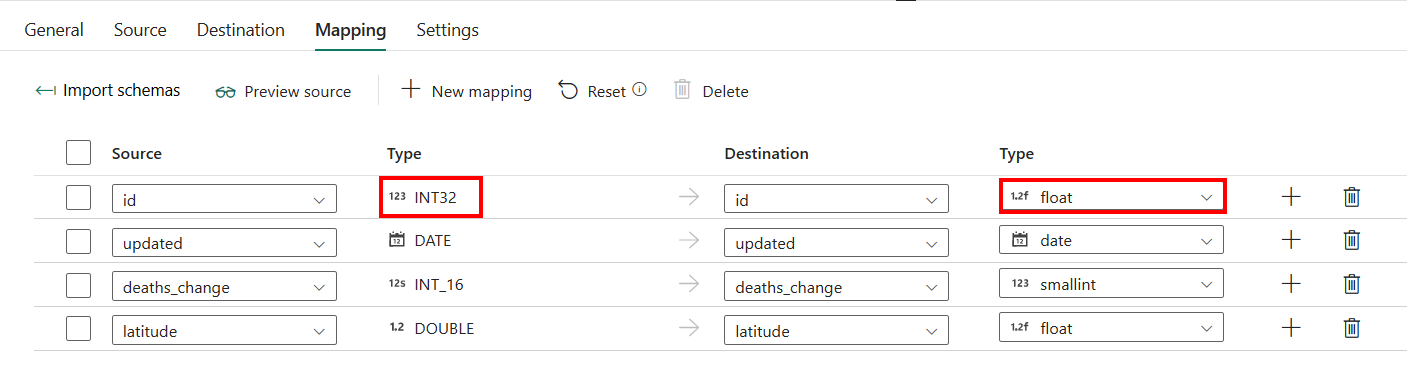
Mapowanie
W przypadku konfiguracji karty Mapowanie , jeśli nie zastosujesz magazynu danych z tabelą automatycznego tworzenia jako miejsca docelowego, przejdź do obszaru Mapowanie.
Jeśli zastosujesz magazyn danych z tabelą automatycznego tworzenia jako miejsca docelowego, z wyjątkiem konfiguracji w obszarze Mapowanie, możesz edytować typ kolumn docelowych. Po wybraniu pozycji Importuj schematy można określić typ kolumny w miejscu docelowym.
Na przykład typ kolumny ID w źródle jest int i można zmienić go na typ zmiennoprzecinkowy podczas mapowania na kolumnę docelową.
Ustawienia
W obszarze Konfiguracja karty Ustawienia przejdź do pozycji Ustawienia.
Podsumowanie tabeli
Poniższe tabele zawierają więcej informacji o działaniu kopiowania w magazynie danych.
Informacje źródłowe
| Nazwa/nazwisko | Opis | Wartość | Wymagania | Właściwość skryptu JSON |
|---|---|---|---|---|
| Typ magazynu danych | Typ magazynu danych. | Workspace | Tak | / |
| Typ magazynu danych obszaru roboczego | Sekcja do wybrania typu magazynu danych obszaru roboczego. | Magazyn danych | Tak | type |
| Magazyn danych | Magazyn danych, którego chcesz użyć. | <magazyn danych> | Tak | endpoint artifactId |
| Korzystanie z zapytania | Sposób odczytywania danych z magazynu danych. | •Tabel •Zapytanie • Procedura składowana |
Nie. | (w obszarze typeProperties ->source)• typeProperties: schema table • sqlReaderQuery • sqlReaderStoredProcedureName |
| Limit czasu zapytania (w minutach) | Limit czasu wykonywania polecenia zapytania z wartością domyślną 120 minut. Jeśli ta właściwość jest ustawiona, dozwolone wartości są w formacie przedziału czasu, na przykład "02:00:00" (120 minut). | zakres czasu | Nie. | queryTimeout |
| Poziom izolacji | Zachowanie blokowania transakcji dla źródła. | •Żaden •Migawka |
Nie. | isolationLevel |
| Opcja partycji | Opcje partycjonowania danych używane do ładowania danych z magazynu danych. | •Żaden • Zakres dynamiczny |
Nie. | partitionOption |
| Nazwa kolumny partycji | Nazwa kolumny źródłowej w liczbą całkowitą lub typu data/data/godzina (int, smallint, smalldatetimedatedatetimebigintdatetime2lub datetimeoffset), która jest używana przez partycjonowanie zakresu na potrzeby kopiowania równoległego. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli jest wykrywany automatycznie i używany jako kolumna partycji. |
<nazwa kolumny partycji> | Nie. | partitionColumnName |
| Górna granica partycji | Maksymalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania są partycjonowane i kopiowane. | <górna granica partycji> | Nie. | partitionUpperBound |
| Dolna granica partycji | Minimalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania są partycjonowane i kopiowane. | <dolna granica partycji> | Nie. | partitionLowerBound |
| Dodatkowe kolumny | Dodaj dodatkowe kolumny danych, aby przechowywać ścieżkę względną plików źródłowych lub wartość statyczną. | • Nazwa •Wartość |
Nie. | additionalColumns: •nazwa •wartość |
Informacje o lokalizacji docelowej
| Nazwa/nazwisko | Opis | Wartość | Wymagania | Właściwość skryptu JSON |
|---|---|---|---|---|
| Typ magazynu danych | Typ magazynu danych. | Workspace | Tak | / |
| Typ magazynu danych obszaru roboczego | Sekcja do wybrania typu magazynu danych obszaru roboczego. | Magazyn danych | Tak | type |
| Magazyn danych | Magazyn danych, którego chcesz użyć. | <magazyn danych> | Tak | endpoint artifactId |
| Tabela | Tabela docelowa do zapisywania danych. | <nazwa tabeli docelowej> | Tak | schemat table |
| Kopiuj ustawienia polecenia | Ustawienia właściwości polecenia copy. Zawiera ustawienia wartości domyślnej. | Wartość domyślna: •Kolumna •Wartość |
Nie. | copyCommandSettings: defaultValues: • nazwakolumny • defaultValue |
| Opcja tabeli | Czy automatycznie utworzyć tabelę docelową, jeśli żadna nie istnieje na podstawie schematu źródłowego. | •Żaden • Automatyczne tworzenie tabeli |
Nie. | tableOption: • AutoTworzenie |
| Skrypt wstępny | Zapytanie SQL do uruchomienia przed zapisaniem danych w usłudze Data Warehouse w każdym uruchomieniu. Użyj tej właściwości, aby wyczyścić wstępnie załadowane dane. | <skrypt wstępny> | Nie. | preCopyScript |
| Limit czasu zapisu wsadowego | Czas oczekiwania na zakończenie operacji wstawiania wsadowego przed upływem limitu czasu. Dozwolone wartości są w formacie przedziału czasu. Wartość domyślna to "00:30:00" (30 minut). | zakres czasu | Nie. | writeBatchTimeout |
| Wyłączanie analizy metryk wydajności | Usługa zbiera metryki dotyczące optymalizacji wydajności kopiowania i zaleceń, które wprowadzają dodatkowy dostęp do głównej bazy danych. | zaznacz lub usuń zaznaczenie | Nie. | disableMetricsCollection: prawda lub fałsz |