Przekształcanie danych przez uruchomienie działania usługi Azure HDInsight
Działanie usługi Azure HDInsight w usłudze Data Factory dla usługi Microsoft Fabric umożliwia organizowanie następujących typów zadań usługi Azure HDInsight:
- Wykonywanie zapytań Hive
- Wywoływanie programu MapReduce
- Wykonywanie zapytań pig
- Wykonywanie programu Spark
- Wykonywanie programu usługi Hadoop Stream
Ten artykuł zawiera szczegółowy przewodnik opisujący sposób tworzenia działania usługi Azure HDInsight przy użyciu interfejsu usługi Data Factory.
Wymagania wstępne
Aby rozpocząć pracę, należy spełnić następujące wymagania wstępne:
- Konto dzierżawy z aktywną subskrypcją. Utwórz konto bezpłatnie.
- Zostanie utworzony obszar roboczy.
Dodawanie działania usługi Azure HDInsight (HDI) do potoku za pomocą interfejsu użytkownika
Utwórz nowy potok danych w obszarze roboczym.
Wyszukaj usługę Azure HDInsight na karcie ekranu głównego i wybierz ją lub wybierz działanie na pasku Działania, aby dodać ją do kanwy potoku.
Tworzenie działania na podstawie karty ekranu głównego:
Tworzenie działania na pasku Działania:
Wybierz nowe działanie usługi Azure HDInsight na kanwie edytora potoków, jeśli nie zostało jeszcze wybrane.
Zapoznaj się ze wskazówkami dotyczącymi ustawień ogólnych, aby skonfigurować opcje znajdujące się na karcie Ustawienia ogólne.

Konfigurowanie klastra usługi HDI
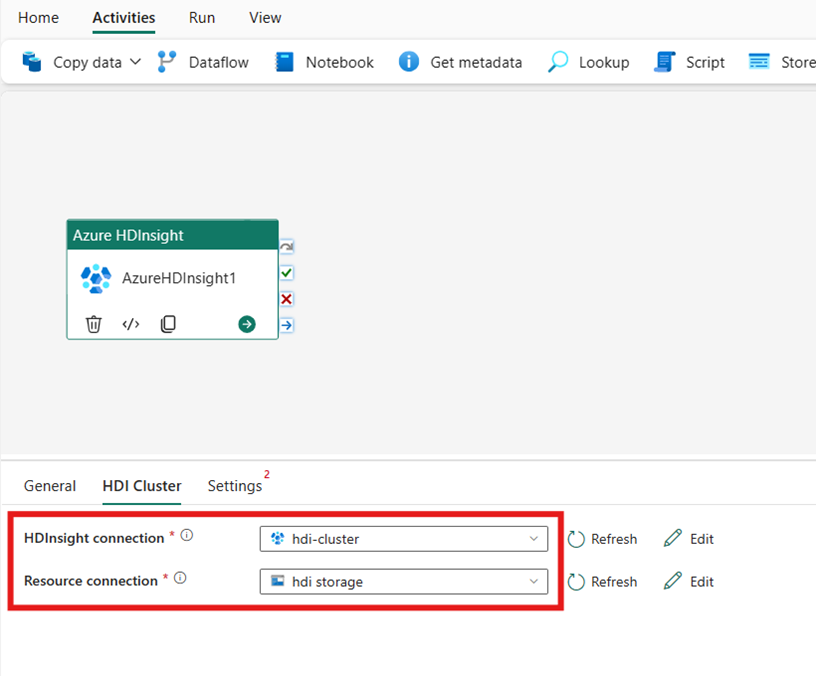
Wybierz kartę Klaster usługi HDI. Następnie możesz wybrać istniejące lub utworzyć nowe połączenie usługi HDInsight.
W polu Połączenie z zasobami wybierz usługę Azure Blob Storage, która odwołuje się do klastra usługi Azure HDInsight. Możesz wybrać istniejący magazyn obiektów blob lub utworzyć nowy.
Konfigurowanie ustawień
Wybierz kartę Ustawienia , aby wyświetlić ustawienia zaawansowane dla działania.
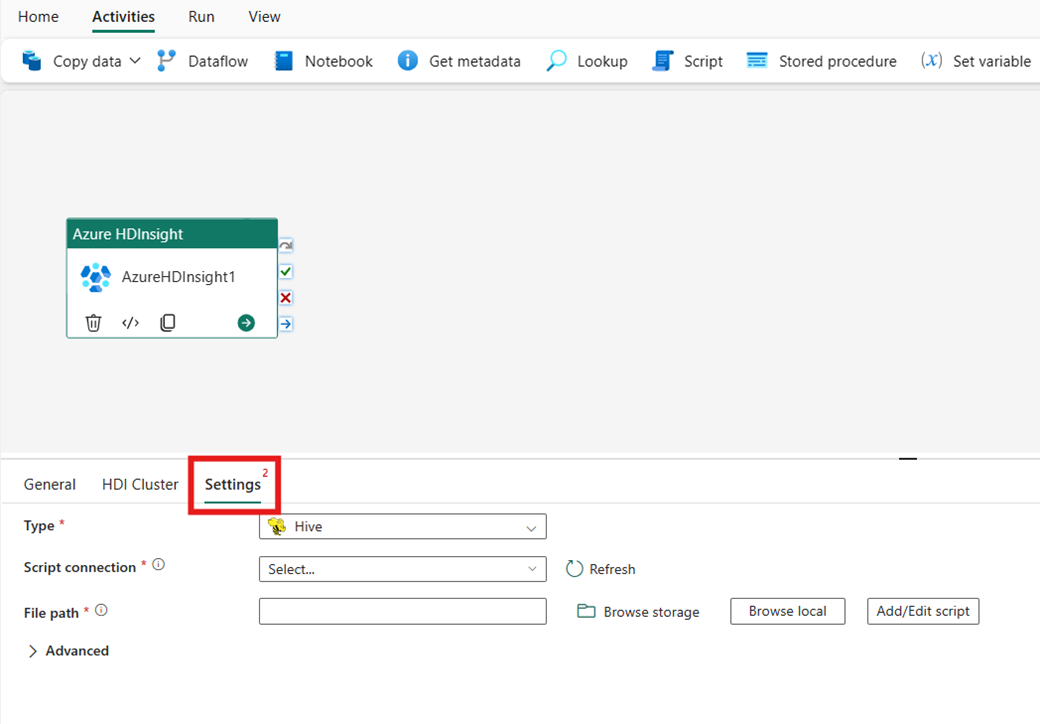
Wszystkie zaawansowane właściwości klastra i wyrażenia dynamiczne obsługiwane w połączonych usługach Azure Data Factory i Synapse Analytics HDInsight są teraz również obsługiwane w działaniu usługi Azure HDInsight dla usługi Data Factory w usłudze Microsoft Fabric w sekcji Zaawansowane w interfejsie użytkownika. Te właściwości obsługują łatwe w użyciu niestandardowe wyrażenia sparametryzowane z zawartością dynamiczną.
Typ klastra
Aby skonfigurować ustawienia dla klastra usługi HDInsight, najpierw wybierz jego typ z dostępnych opcji, w tym Hive, Map Reduce, Pig, Spark i Streaming.
Hive
Jeśli wybierzesz pozycję Hive jako Typ, działanie wykonuje zapytanie Hive. Opcjonalnie możesz określić połączenie skryptu odwołujące się do konta magazynu, które zawiera typ programu Hive. Domyślnie używane jest połączenie magazynu określone na karcie Klaster usługi HDI. Należy określić ścieżkę pliku do wykonania w usłudze Azure HDInsight. Opcjonalnie możesz określić więcej konfiguracji w sekcji Zaawansowane, informacje debugowania, limit czasu zapytania, argumenty, parametry i zmienne.
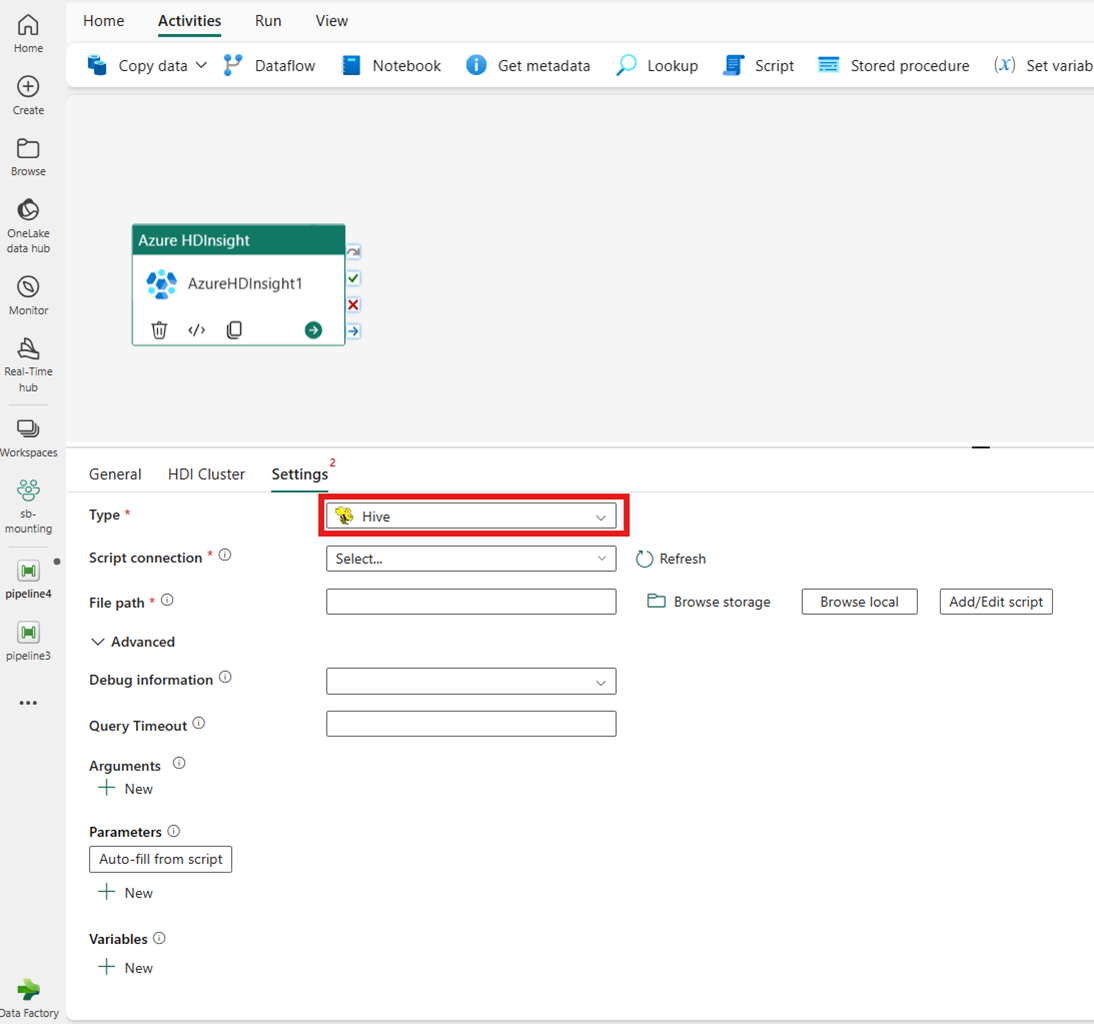
Zmniejszanie mapy
W przypadku wybrania opcji Map Reduce (Zmniejszenie mapy) dla opcji Typ działanie wywołuje program mapowania redukcji. Opcjonalnie można określić w połączeniu Jar odwołującym się do konta magazynu, które zawiera typ redukcji mapy. Domyślnie używane jest połączenie magazynu określone na karcie Klaster usługi HDI. Należy określić nazwę klasy i ścieżkę pliku do wykonania w usłudze Azure HDInsight. Opcjonalnie możesz określić więcej szczegółów konfiguracji, takich jak importowanie bibliotek Jar, informacje o debugowaniu, argumenty i parametry w sekcji Zaawansowane .
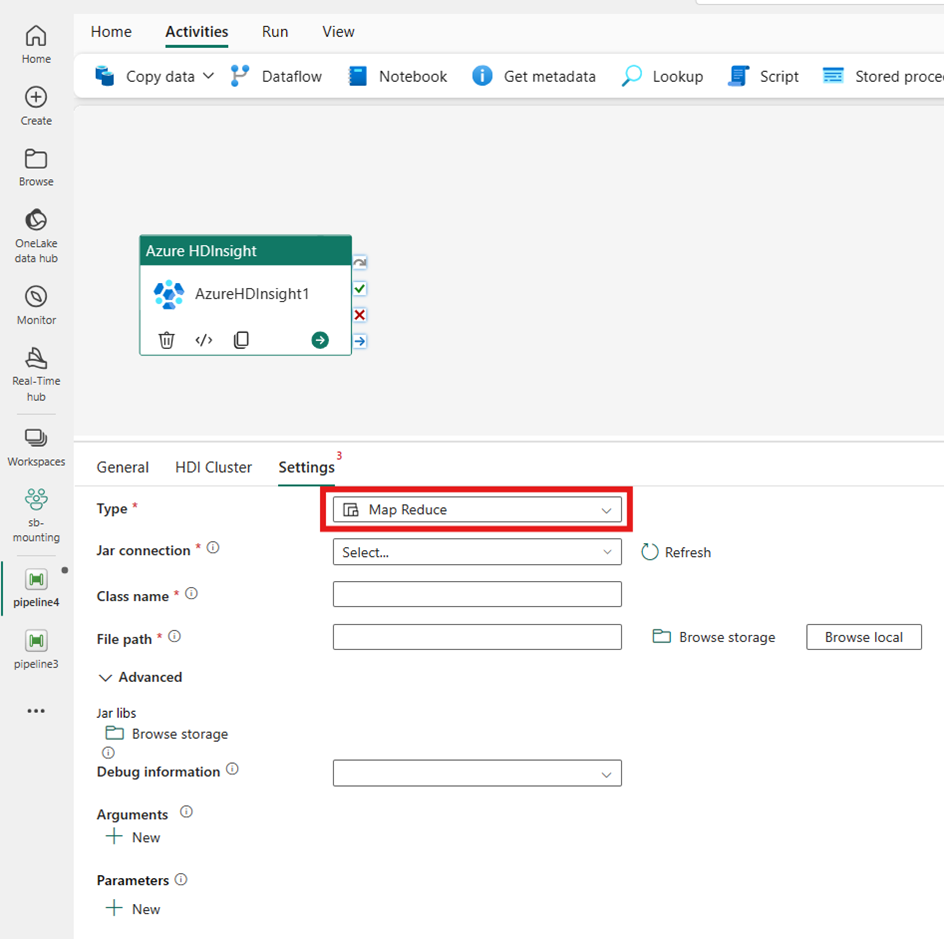
Pig
Jeśli wybierzesz wartość Pig dla pozycji Typ, działanie wywołuje zapytanie Pig. Opcjonalnie możesz określić ustawienie Połączenia skryptu, które odwołuje się do konta magazynu, które zawiera typ pig. Domyślnie używane jest połączenie magazynu określone na karcie Klaster usługi HDI. Należy określić ścieżkę pliku do wykonania w usłudze Azure HDInsight. Opcjonalnie możesz określić więcej konfiguracji, takich jak informacje o debugowaniu, argumenty, parametry i zmienne w sekcji Zaawansowane .
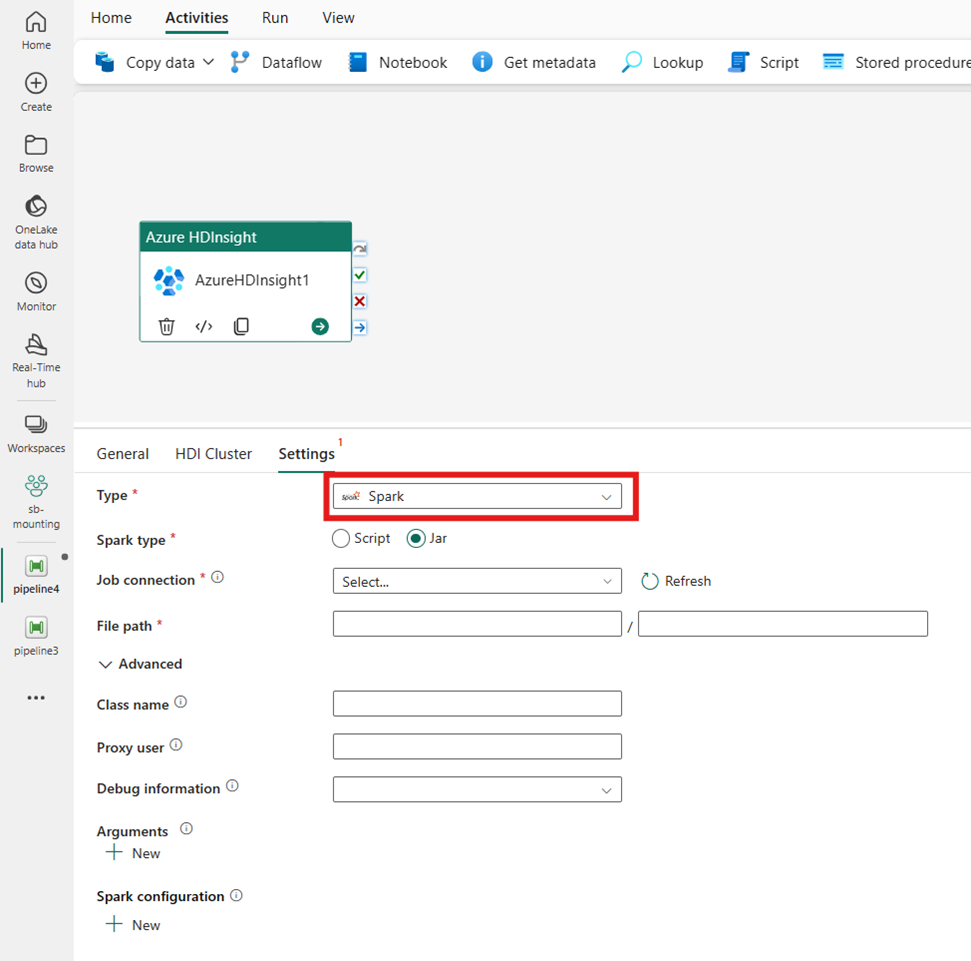
platforma Spark
Jeśli wybierzesz wartość Spark dla pozycji Typ, działanie wywołuje program Spark. Wybierz skrypt lub plik Jar dla typu platformy Spark. Opcjonalnie możesz określić połączenie zadania odwołujące się do konta magazynu, które zawiera typ platformy Spark. Domyślnie używane jest połączenie magazynu określone na karcie Klaster usługi HDI. Należy określić ścieżkę pliku do wykonania w usłudze Azure HDInsight. Opcjonalnie możesz określić więcej konfiguracji, takich jak nazwa klasy, użytkownik proxy, informacje debugowania, argumenty i konfiguracja platformy Spark w sekcji Zaawansowane.
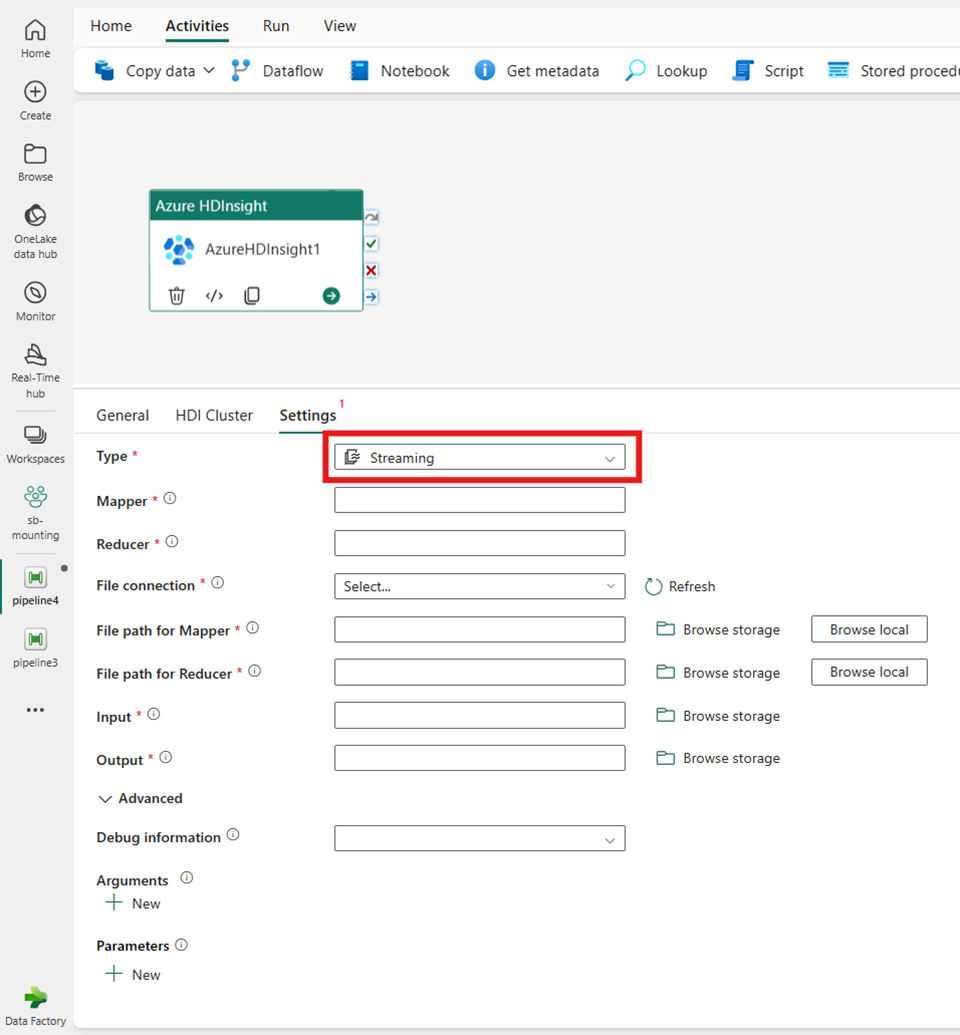
Przesyłanie strumieniowe
W przypadku wybrania opcji Przesyłanie strumieniowe dla pozycji Typ działanie wywołuje program przesyłania strumieniowego. Określ nazwy mapatora i reduktora, a opcjonalnie możesz określić połączenie z plikiem odwołujące się do konta magazynu, które zawiera typ przesyłania strumieniowego. Domyślnie używane jest połączenie magazynu określone na karcie Klaster usługi HDI. Należy określić ścieżkę pliku dla mapatora i ścieżki pliku dla reduktora do wykonania w usłudze Azure HDInsight. Uwzględnij opcje Dane wejściowe i wyjściowe , a także ścieżkę WASB. Opcjonalnie możesz określić więcej konfiguracji, takich jak informacje o debugowaniu, argumenty i parametry w sekcji Zaawansowane.
Odwołanie do właściwości
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | W przypadku działania przesyłania strumieniowego usługi Hadoop typ działania to HDInsightStreaming | Tak |
| Mapowania | Określa nazwę pliku wykonywalnego mapatora | Tak |
| Reduktor | Określa nazwę pliku wykonywalnego reduktora | Tak |
| łączenie | Określa nazwę pliku wykonywalnego łączenia | Nie. |
| połączenie pliku | Odwołanie do połączonej usługi Azure Storage używanej do przechowywania programów Mapper, Combiner i Reducer do wykonania. | Nie. |
| W tym miejscu obsługiwane są tylko połączenia usługi Azure Blob Storage i ADLS Gen2. Jeśli nie określisz tego połączenia, zostanie użyte połączenie magazynu zdefiniowane w połączeniu usługi HDInsight. | ||
| filePath | Podaj tablicę ścieżek do programów Mapper, Combiner i Reducer przechowywanych w usłudze Azure Storage, do których odwołuje się połączenie pliku. | Tak |
| input | Określa ścieżkę WASB do pliku wejściowego mapatora. | Tak |
| output | Określa ścieżkę WASB do pliku wyjściowego reduktora. | Tak |
| getDebugInfo | Określa, kiedy pliki dziennika są kopiowane do usługi Azure Storage używanej przez klaster usługi HDInsight (lub) określony przez scriptLinkedService. | Nie. |
| Dozwolone wartości: Brak, Zawsze lub Niepowodzenie. Wartość domyślna: None. | ||
| Argumenty | Określa tablicę argumentów dla zadania hadoop. Argumenty są przekazywane jako argumenty wiersza polecenia do każdego zadania. | Nie. |
| Definiuje | Określ parametry jako pary klucz/wartość, aby odwoływać się do skryptu Hive. | Nie. |
Zapisywanie i uruchamianie lub planowanie potoku
Po skonfigurowaniu innych działań wymaganych dla potoku przejdź do karty Narzędzia główne w górnej części edytora potoków i wybierz przycisk zapisz, aby zapisać potok. Wybierz pozycję Uruchom , aby uruchomić go bezpośrednio lub Zaplanuj , aby go zaplanować. Historię uruchamiania można również wyświetlić tutaj lub skonfigurować inne ustawienia.
