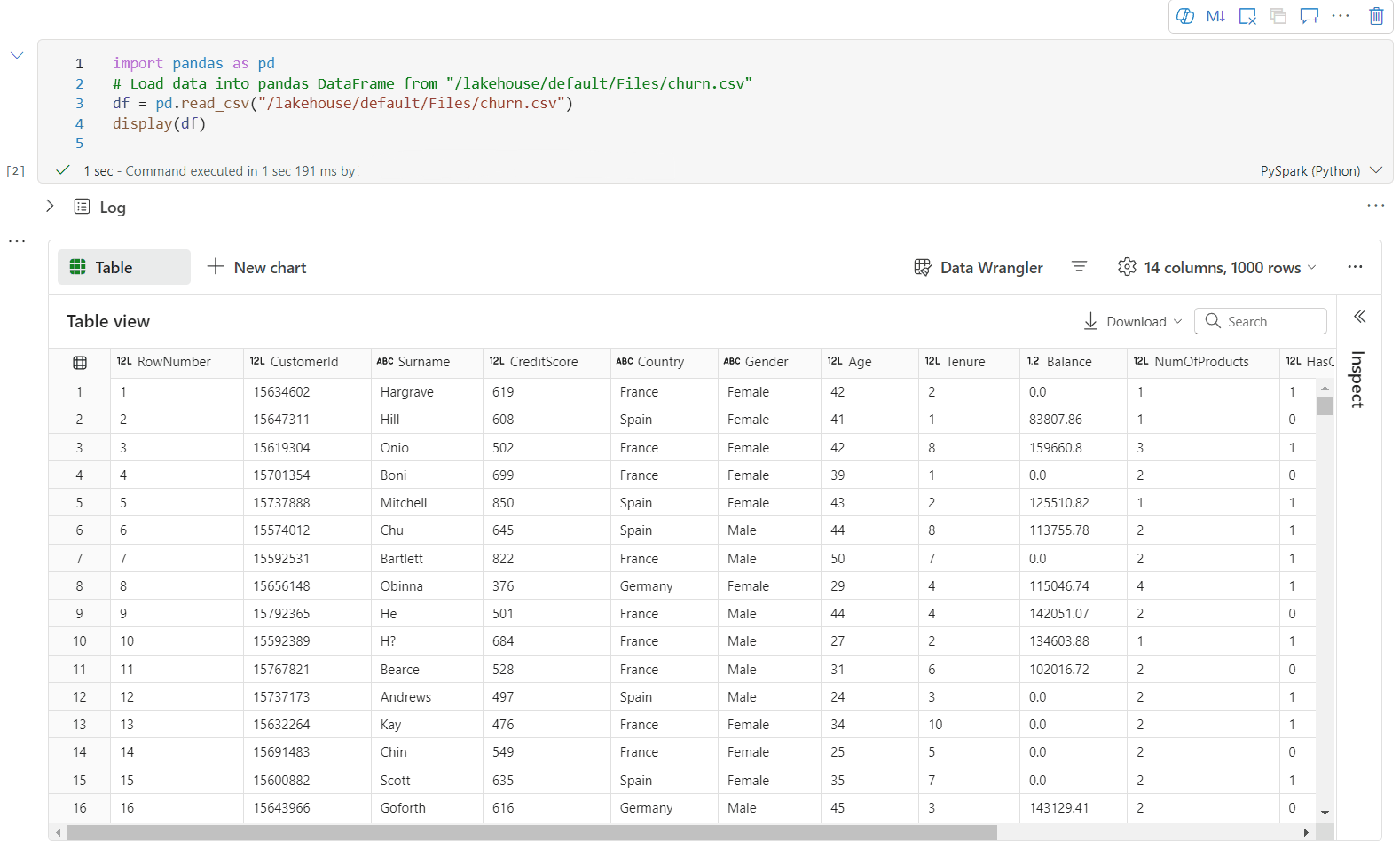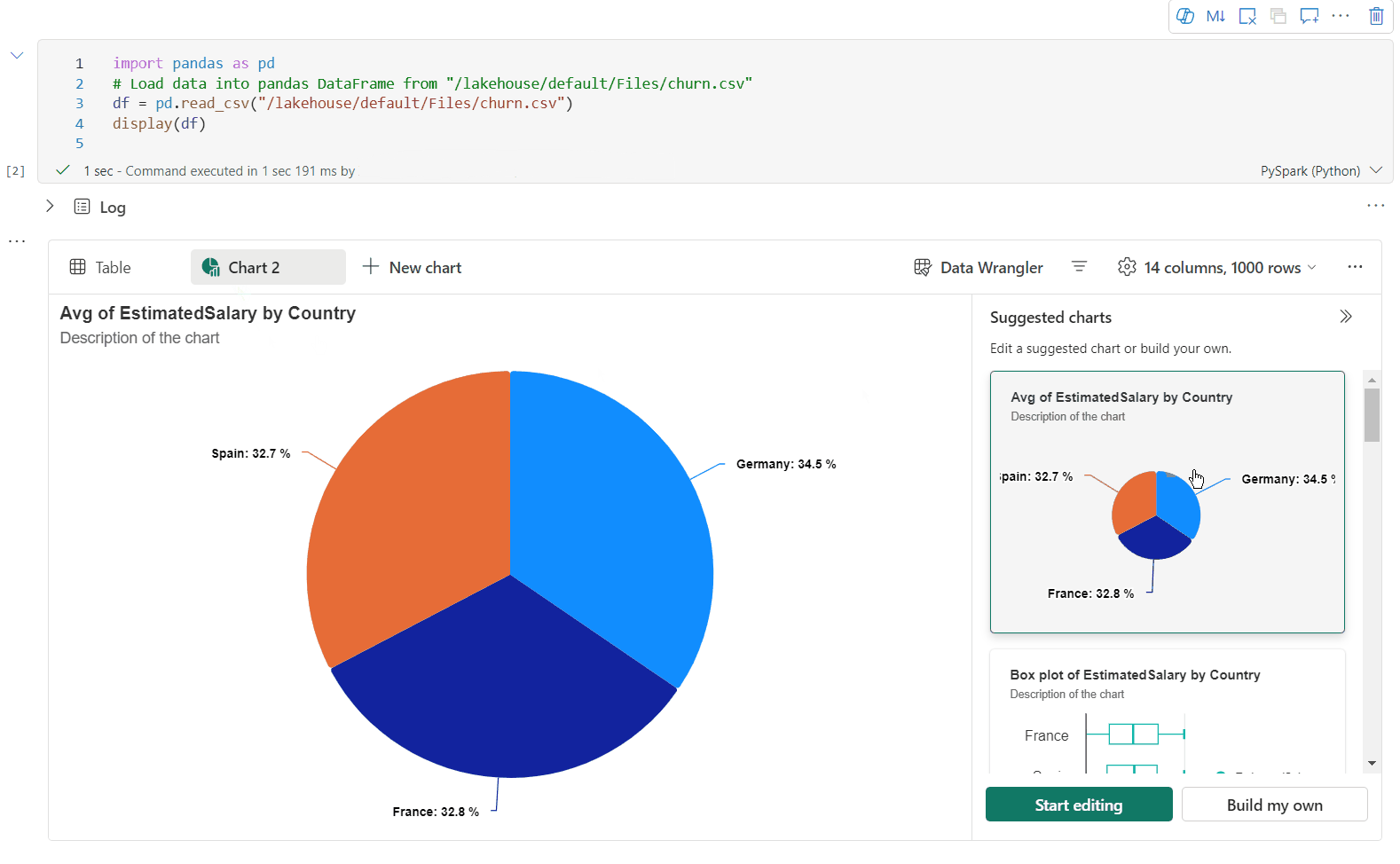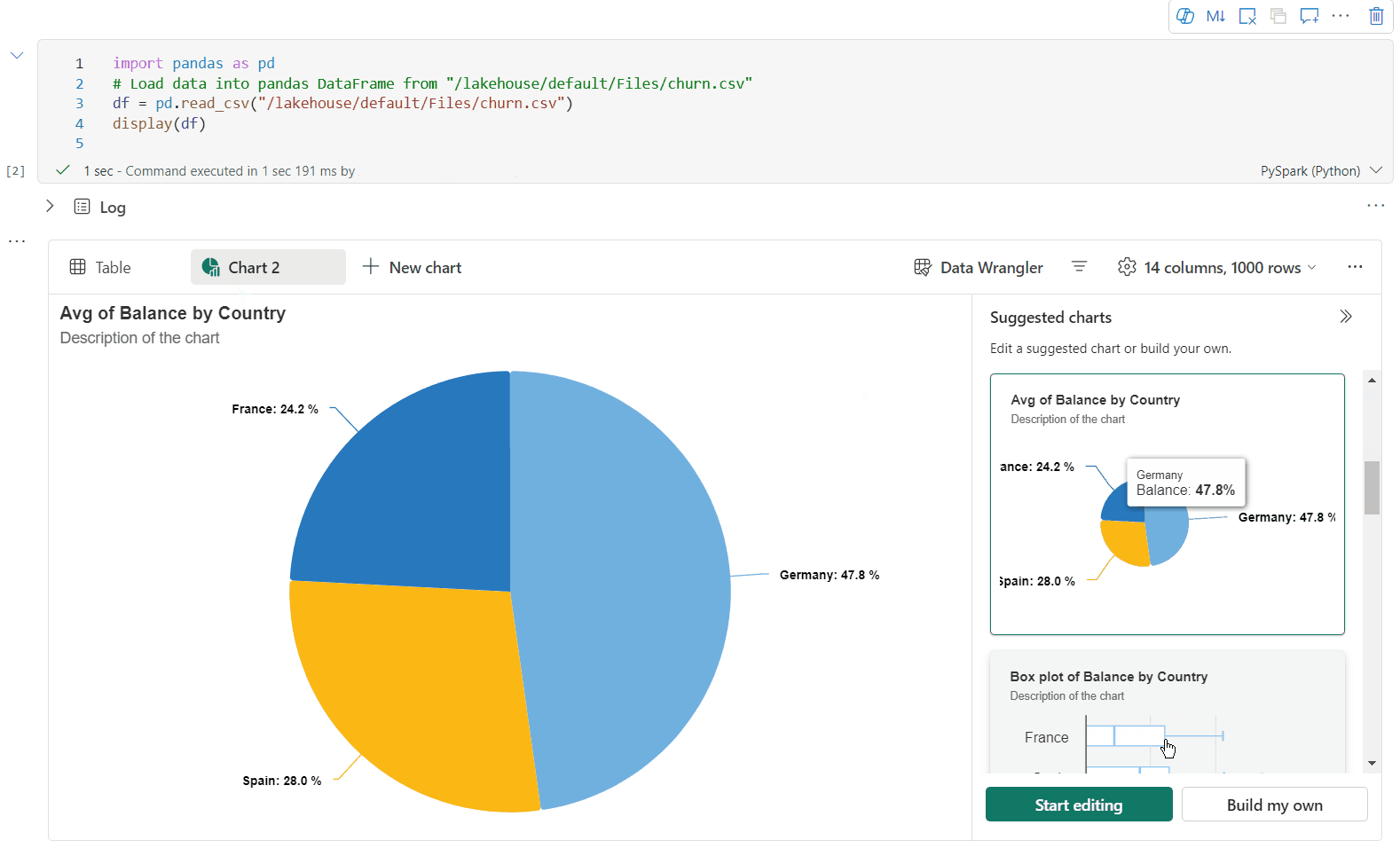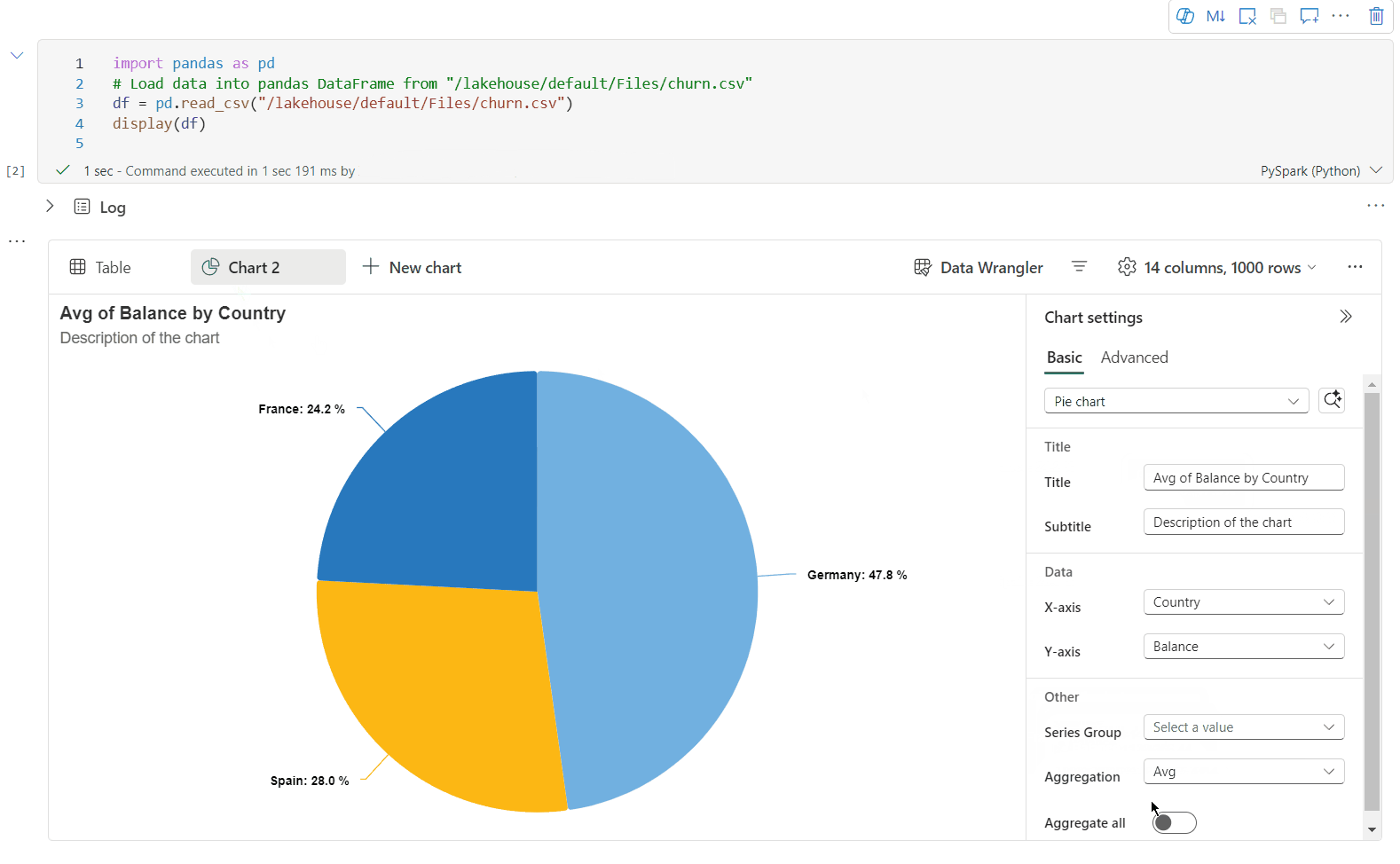
Wizualizacja notesu w usłudze Microsoft Fabric
Microsoft Fabric to zintegrowana usługa analityczna, która przyspiesza czas wglądu w magazyny danych i systemy analizy danych big data. Wizualizacja danych w notesach to kluczowy składnik, który umożliwia uzyskanie wglądu w dane. Ułatwia to zrozumienie dużych i małych danych przez ludzi. Ułatwia również wykrywanie wzorców, trendów i wartości odstających w grupach danych.
W przypadku korzystania z platformy Apache Spark w usłudze Fabric dostępne są różne wbudowane opcje ułatwiające wizualizowanie danych, w tym opcje wykresu notesu sieci szkieletowej i dostęp do popularnych bibliotek typu open source.
W przypadku korzystania z notesu usługi Fabric możesz przekształcić widok wyników tabelarycznych w dostosowany wykres przy użyciu opcji wykresu. W tym miejscu możesz wizualizować dane bez konieczności pisania kodu.
Wbudowane polecenie wizualizacji — funkcja display()
Wbudowana funkcja wizualizacji w systemie Fabric umożliwia przekształcanie DataFrame'ów Apache Spark, DataFrame'ów Pandas oraz wyników zapytań SQL w rozbudowane wizualizacje danych.
Funkcję wyświetlania można używać w ramkach danych utworzonych w PySpark i Scala w ramkach danych platformy Spark lub funkcjach Odpornych rozproszonych zestawów danych (RDD) w celu utworzenia rozbudowanego widoku tabeli ramek danych i widoku wykresu.
Liczbę wierszy renderowanych ramek danych można określić. Wartość domyślna to 1000. Widżet danych wyjściowych notesu wyświetla obsługuje wyświetlanie i profilowanie 10000 wierszy ramki danych.

Możesz użyć funkcji filtru na globalnym pasku narzędzi, aby skutecznie filtrować dane mapowane zgodnie z niestandardową regułą. Warunek stosuje się do określonej kolumny, a wynik filtru odzwierciedla się zarówno w widoku tabeli, jak i wykresu.

Dane wyjściowe instrukcji SQL domyślnie przyjmują ten sam widżet wyjściowy z display().
Widok tabeli wzbogaconej ramki danych
Możliwość swobodnego wyboru w widoku tabeli
Widok tabeli jest domyślnie renderowany podczas korzystania z polecenia display(). Bogaty podgląd ramki danych w notatniku oferuje funkcję swobodnego wyboru, zaprojektowaną w celu ulepszenia doświadczenia analizy danych dzięki elastycznym i intuicyjnym możliwościom wyboru. Ta funkcja umożliwia użytkownikom wydajniejszą interakcję z ramkami danych i uzyskiwanie bardziej szczegółowych informacji z łatwością.
wybór kolumny
- pojedyncza kolumna: Kliknij nagłówek kolumny, aby wybrać całość kolumny.
- wiele kolumn: po wybraniu pojedynczej kolumny naciśnij i przytrzymaj "Shift", a następnie kliknij inny nagłówek kolumny, aby wybrać wiele kolumn.
wybór wiersza
- pojedynczy wiersz: kliknij nagłówek wiersza, aby wybrać cały wiersz.
- wiele wierszy: po wybraniu jednego wiersza naciśnij i przytrzymaj "Shift", a następnie kliknij inny nagłówek wiersza, aby wybrać wiele wierszy.
Podgląd zawartości komórki: wyświetl podgląd zawartości poszczególnych komórek, aby uzyskać szybki i szczegółowy przegląd danych bez konieczności pisania dodatkowego kodu.
Podsumowanie kolumny: Uzyskaj podsumowanie każdej kolumny, w tym rozkładu danych i kluczowych statystyk, aby szybko zrozumieć charakterystykę danych.
Dowolne zaznaczenie obszaru: Wybierz dowolny ciągły fragment tabeli, aby mieć przegląd wszystkich zaznaczonych komórek oraz wartości liczbowych znajdujących się w wybranym obszarze.
kopiowanie wybranej zawartości: we wszystkich przypadkach wyboru możesz szybko skopiować wybraną zawartość, używając skrótu "Ctrl + C". Wybrane dane są kopiowane w formacie CSV, co ułatwia przetwarzanie w innych aplikacjach.
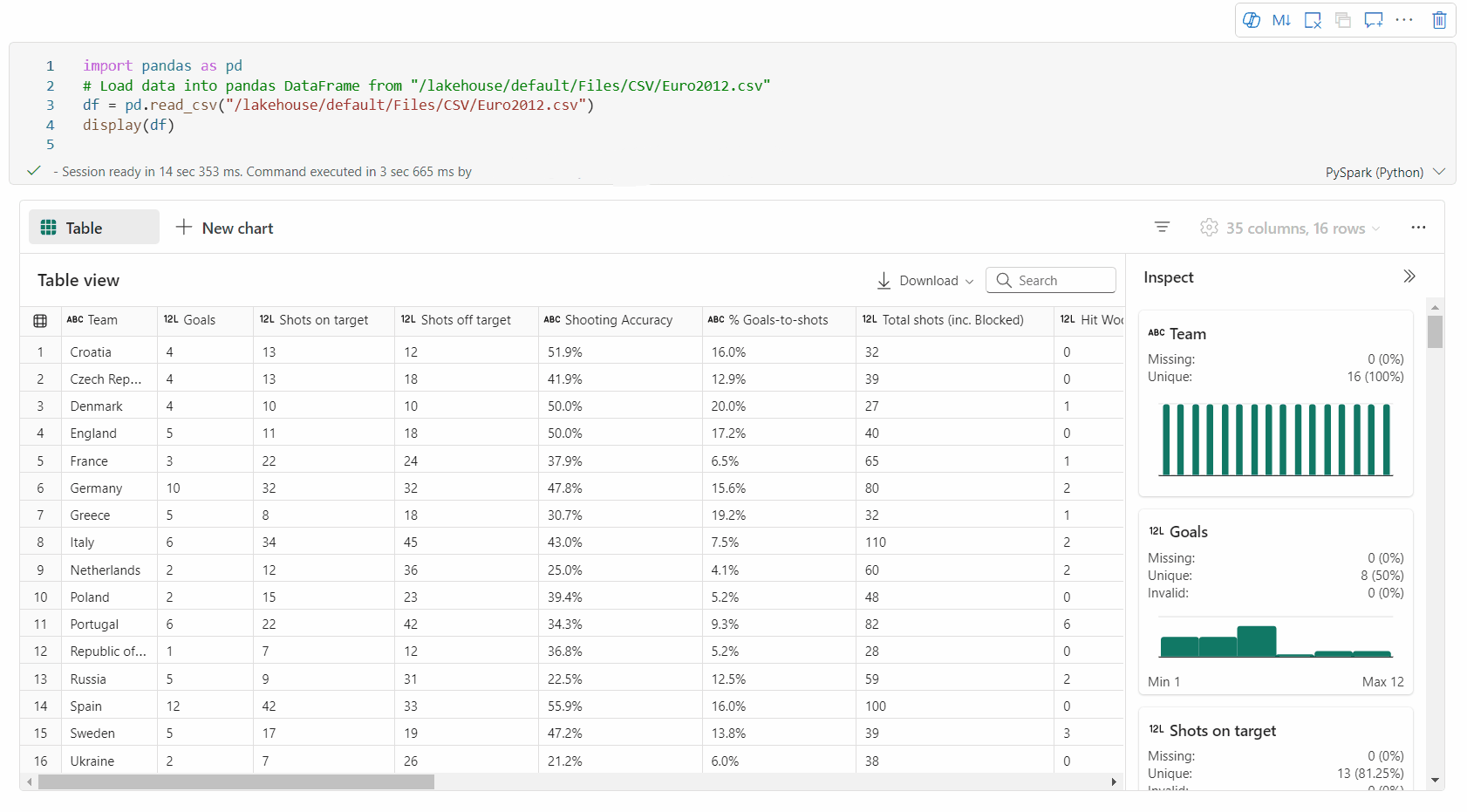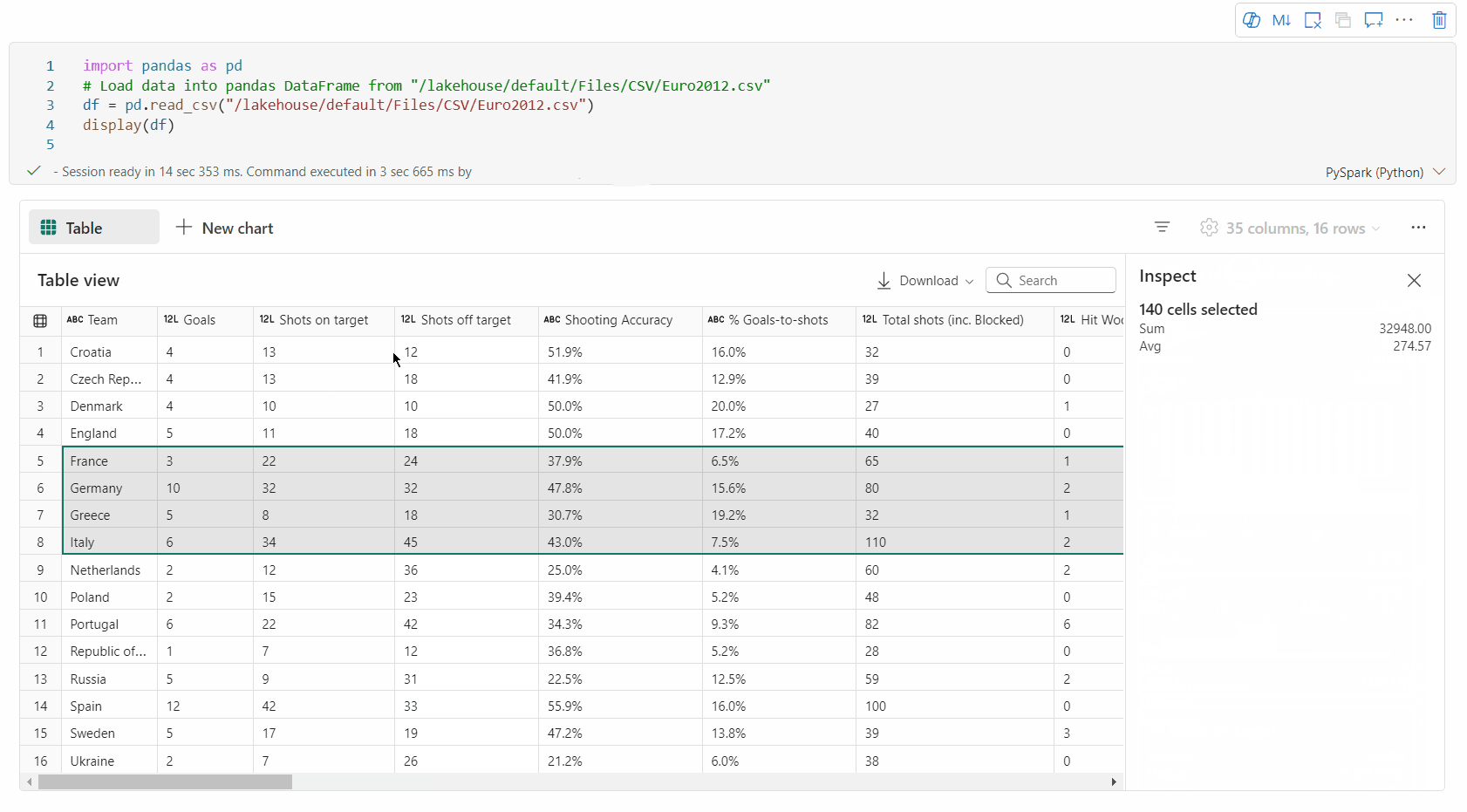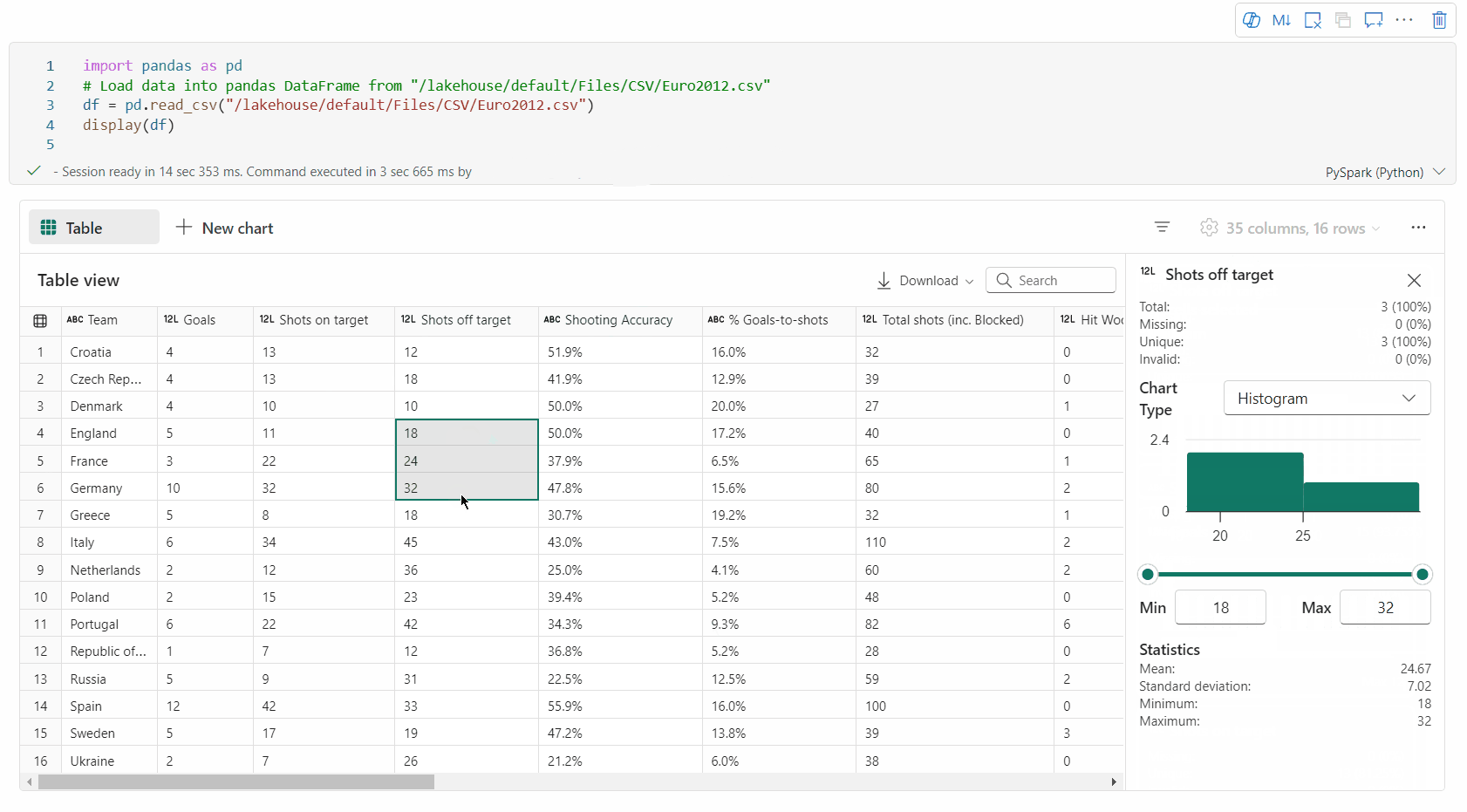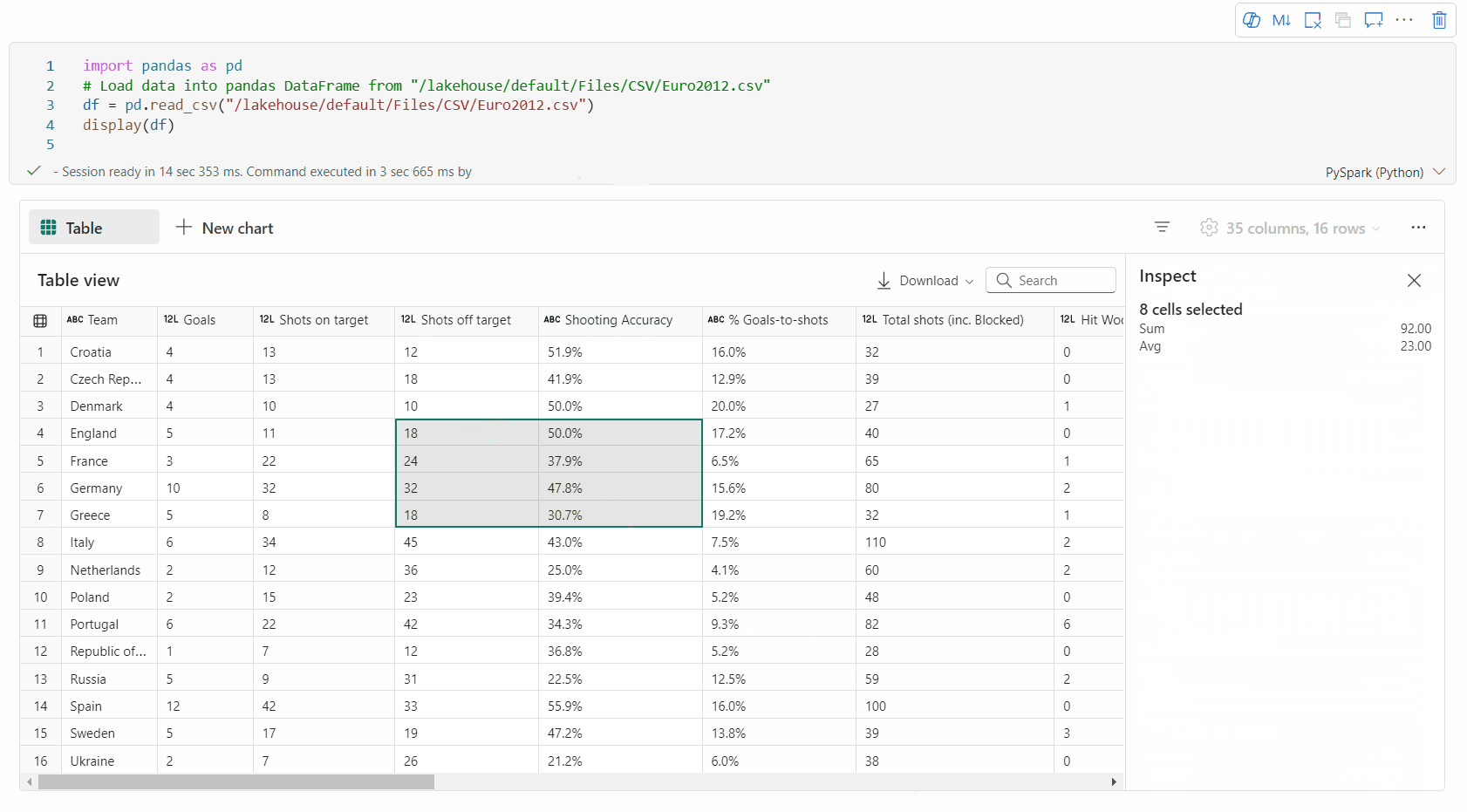
Obsługa profilowania danych w okienku Inspekcji
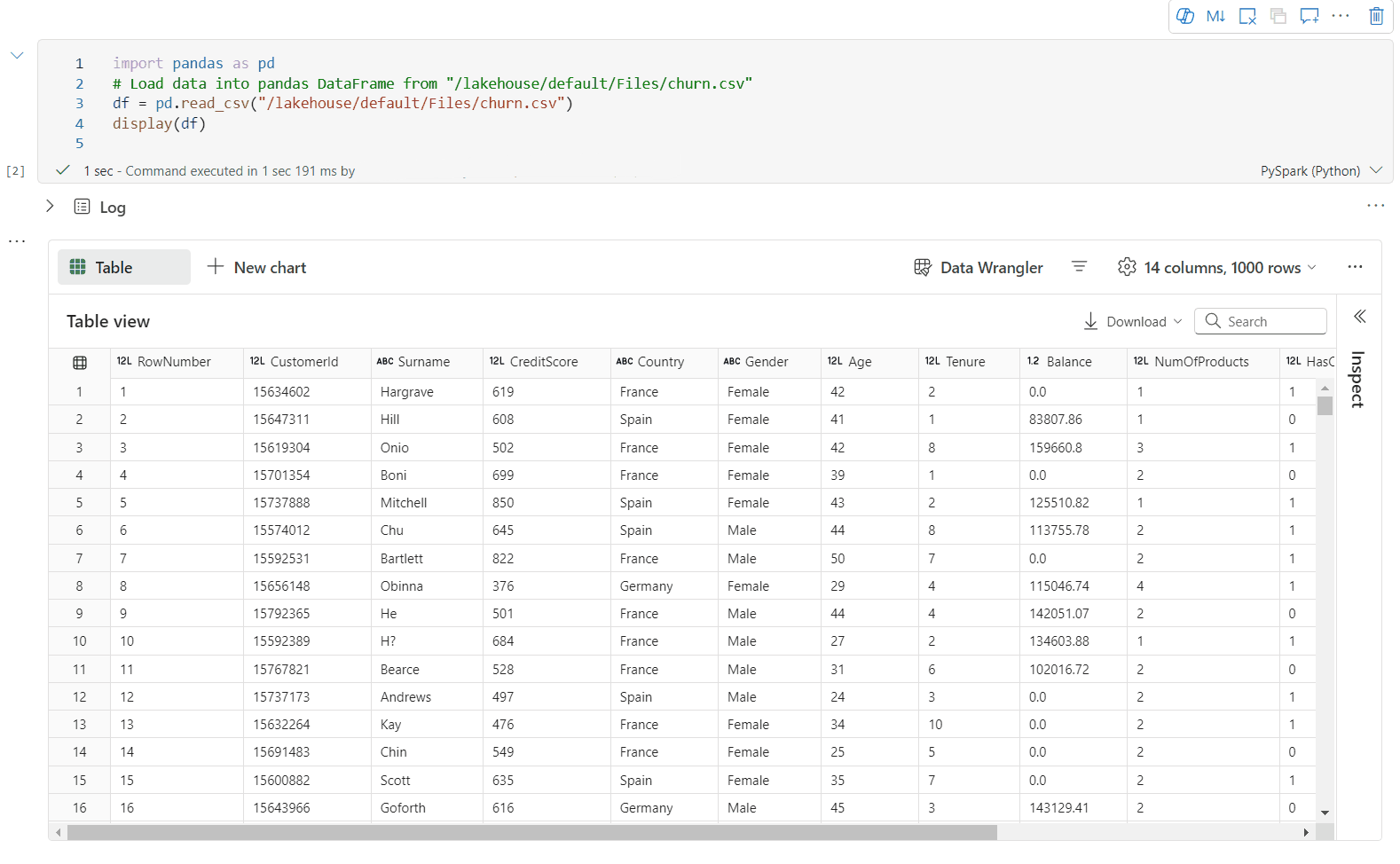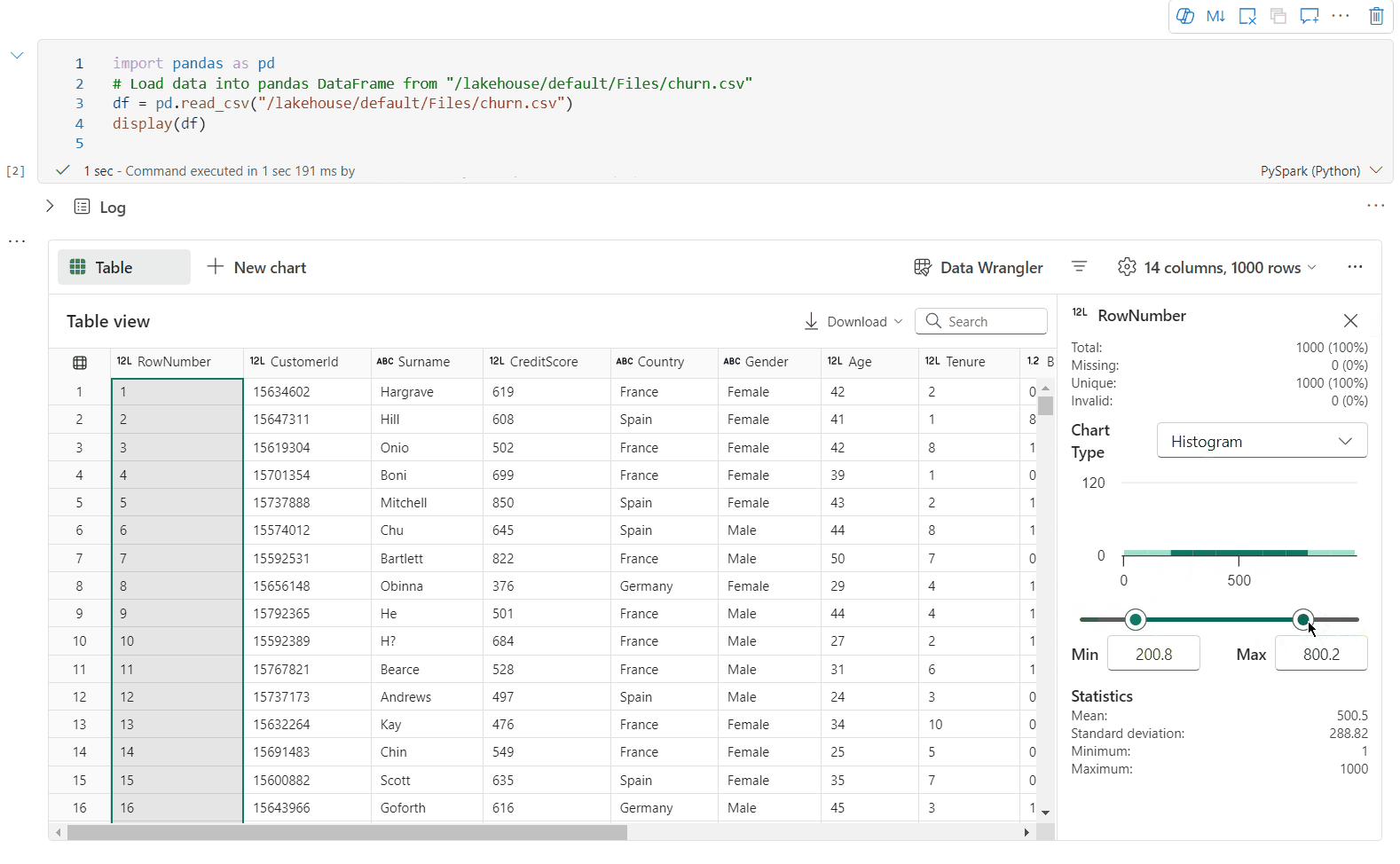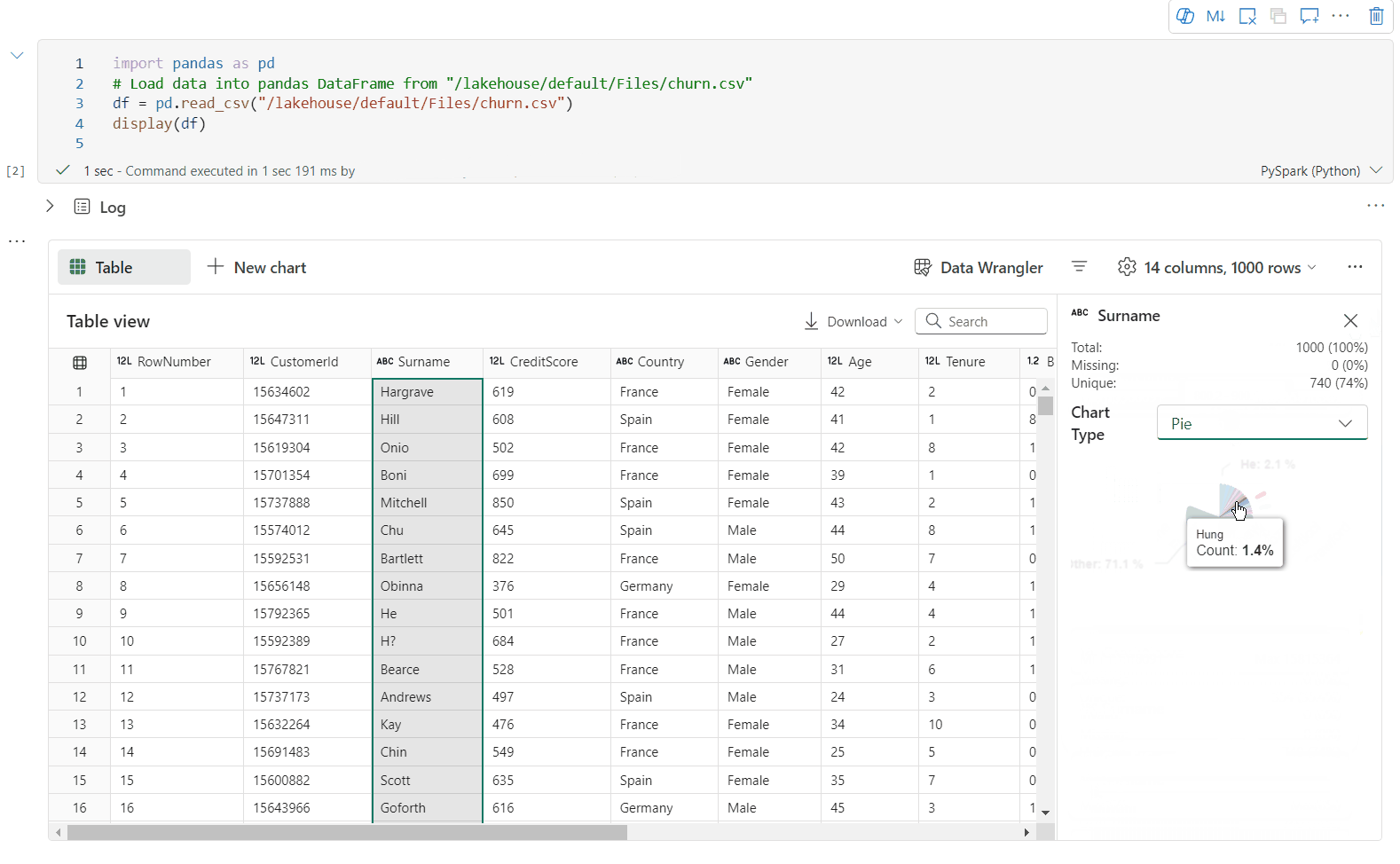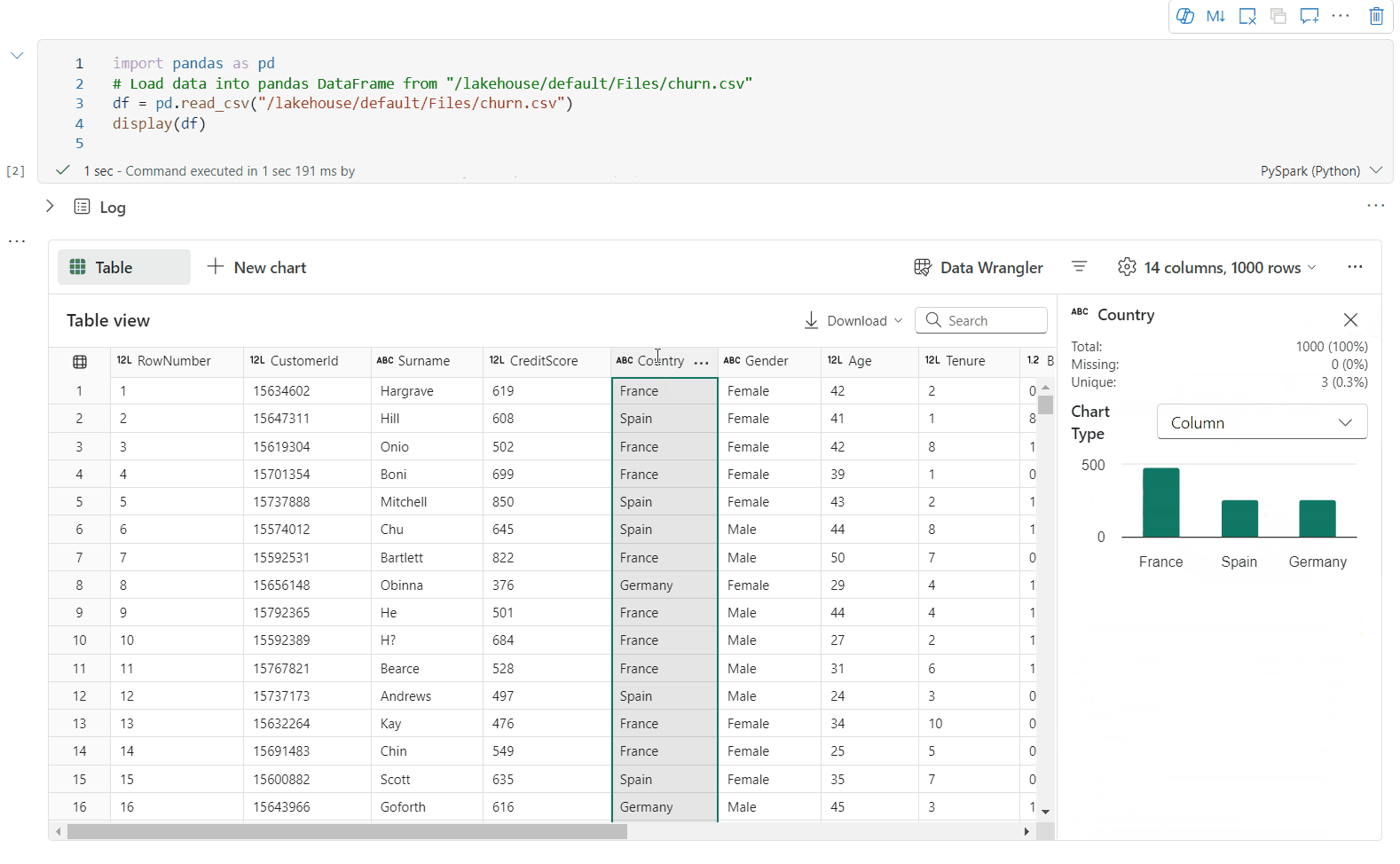
Możesz profilować ramkę danych, klikając przycisk Sprawdź . Udostępnia on podsumowanie rozkładu danych i przedstawia statystyki każdej kolumny.
Każda karta w okienku bocznym Inspekcja jest mapowana na kolumnę ramki danych, aby wyświetlić więcej szczegółów, klikając kartę lub wybierając kolumnę w tabeli.
Szczegóły komórki można wyświetlić, klikając komórkę tabeli. Ta funkcja jest przydatna, gdy ramka danych zawiera długi typ ciągu zawartości.
Nowy bogaty widok wykresu ramek danych
Uwaga
Obecnie funkcja jest dostępna w wersji zapoznawczej.
Ulepszony widok wykresu jest dostępny w poleceniu display(). Zapewnia bardziej intuicyjne i zaawansowane środowisko wizualizacji danych przy użyciu polecenia display().
Teraz możesz dodać do 5 wykresów w jednym widżecie danych wyjściowych display(), klikając pozycję Nowy wykres, umożliwiając tworzenie wielu wykresów na podstawie różnych kolumn i łatwe porównywanie wykresów.
Podczas tworzenia nowych wykresów możesz uzyskać listę zaleceń dotyczących wykresu na podstawie docelowej ramki danych. Możesz edytować zalecany wykres lub utworzyć własny wykres od podstaw.
Teraz możesz dostosować wizualizację, określając następujące ustawienia. Opcje ustawień mogą ulec zmianie zgodnie z wybranym typem wykresu:
Kategoria Ustawienia podstawowe Opis Typ wykresu Funkcja wyświetlania obsługuje szeroką gamę typów wykresów, w tym wykresy słupkowe, wykresy punktowe, wykresy liniowe, tabele przestawne i inne. Tytuł Tytuł Tytuł wykresu. Tytuł Podtytuł Podtytuł wykresu z bardziej opisami. Data Osi Określ klucz wykresu. Data Oś y Określ wartości wykresu. Legenda Pokaż legendę Włączanie/wyłączanie legendy. Legenda Position Dostosuj położenie legendy. Inne Grupa serii Użyj tej konfiguracji, aby określić grupy dla agregacji. Inne Agregacja Ta metoda służy do agregowania danych w wizualizacji. Inne Skumulowany Skonfiguruj styl wyświetlania wyniku. Uwaga
Domyślnie funkcja display(df) przyjmuje tylko pierwsze 1000 wierszy danych do renderowania wykresów. Wybierz pozycję Agregacja dla wszystkich wyników , a następnie wybierz pozycję Zastosuj , aby zastosować generowanie wykresu z całej ramki danych. Zadanie platformy Spark jest wyzwalane po zmianie ustawienia wykresu. Wykonanie obliczeń i renderowanie wykresu może potrwać kilka minut.
Kategoria Ustawienia zaawansowane Opis Color Motyw Zdefiniuj zestaw kolorów motywu wykresu. Osi Etykieta Określ etykietę na osi X. Osi Skaluj Określ funkcję skalowania osi X. Osi Zakres Określ oś X zakresu wartości. Oś y Etykieta Określ etykietę na osi Y. Oś y Skaluj Określ funkcję skalowania osi Y. Oś y Zakres Określ oś Y zakresu wartości. Wyświetlanie Pokaż etykiety Pokaż/ukryj etykiety wyników na wykresie. Zmiany konfiguracji zaczynają obowiązywać natychmiast, a wszystkie konfiguracje są automatycznie zapisane w zawartości notesu.
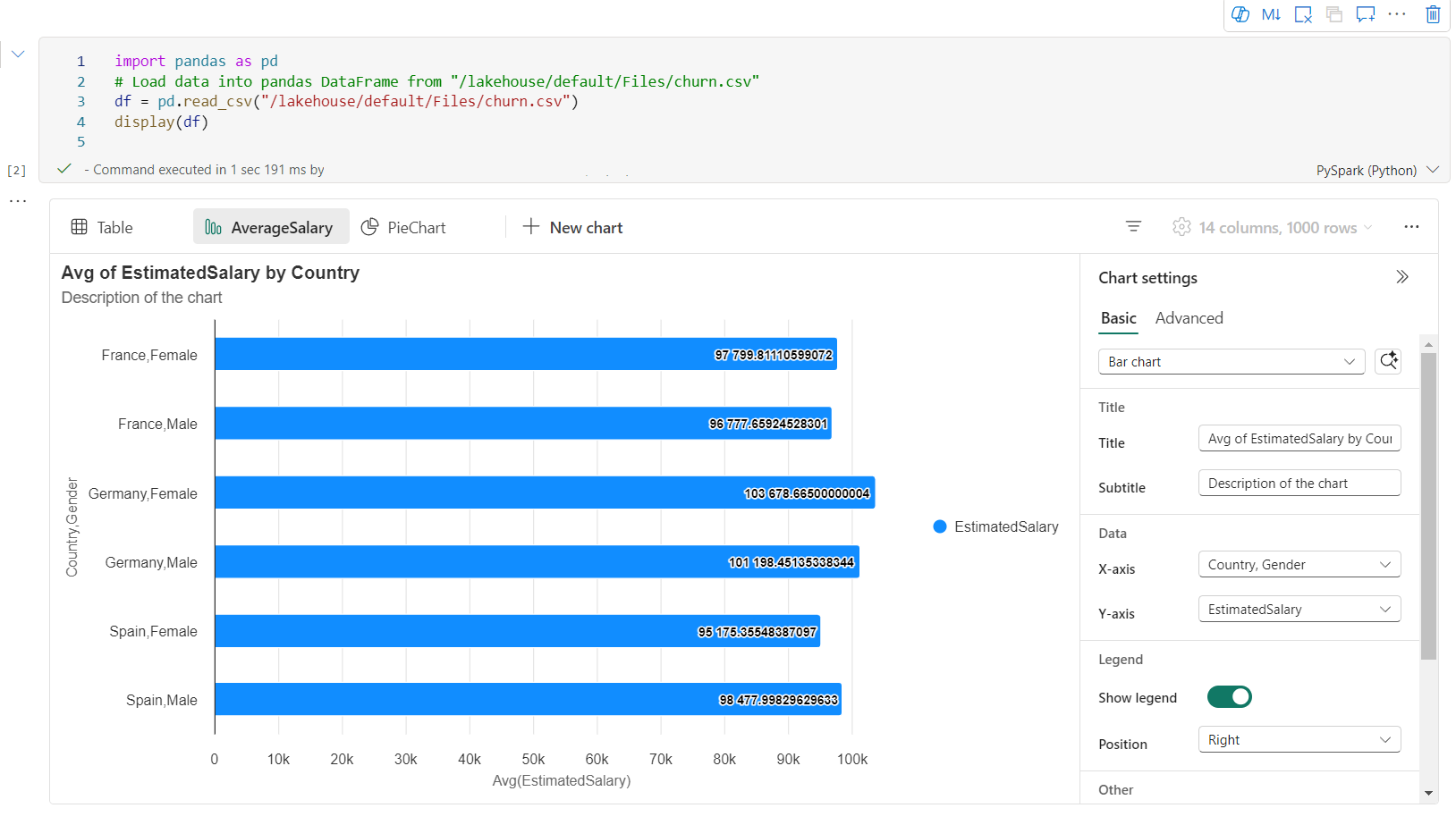
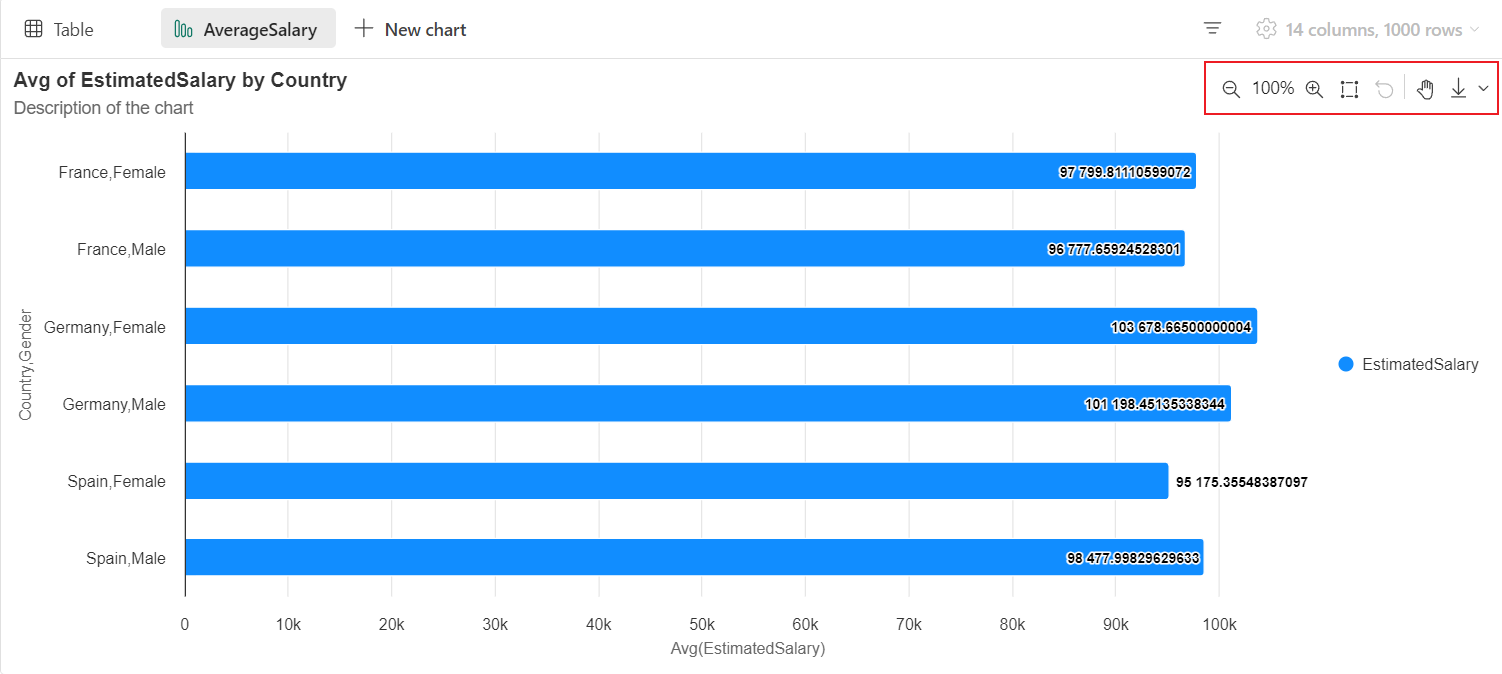
Możesz łatwo zmieniać nazwy, duplikować lub usuwać wykresy w menu kart wykresu.

Interaktywny pasek narzędzi jest dostępny w nowym środowisku wykresu, gdy użytkownik umieści wskaźnik myszy na wykresie. Operacje pomocy technicznej, takie jak powiększanie, powiększanie, powiększanie, zaznaczanie, resetowanie, przesuwanie itp.



Widok starszego wykresu
Uwaga
Starszy widok wykresu zostanie wycofany po zakończeniu podglądu nowego widoku wykresu.
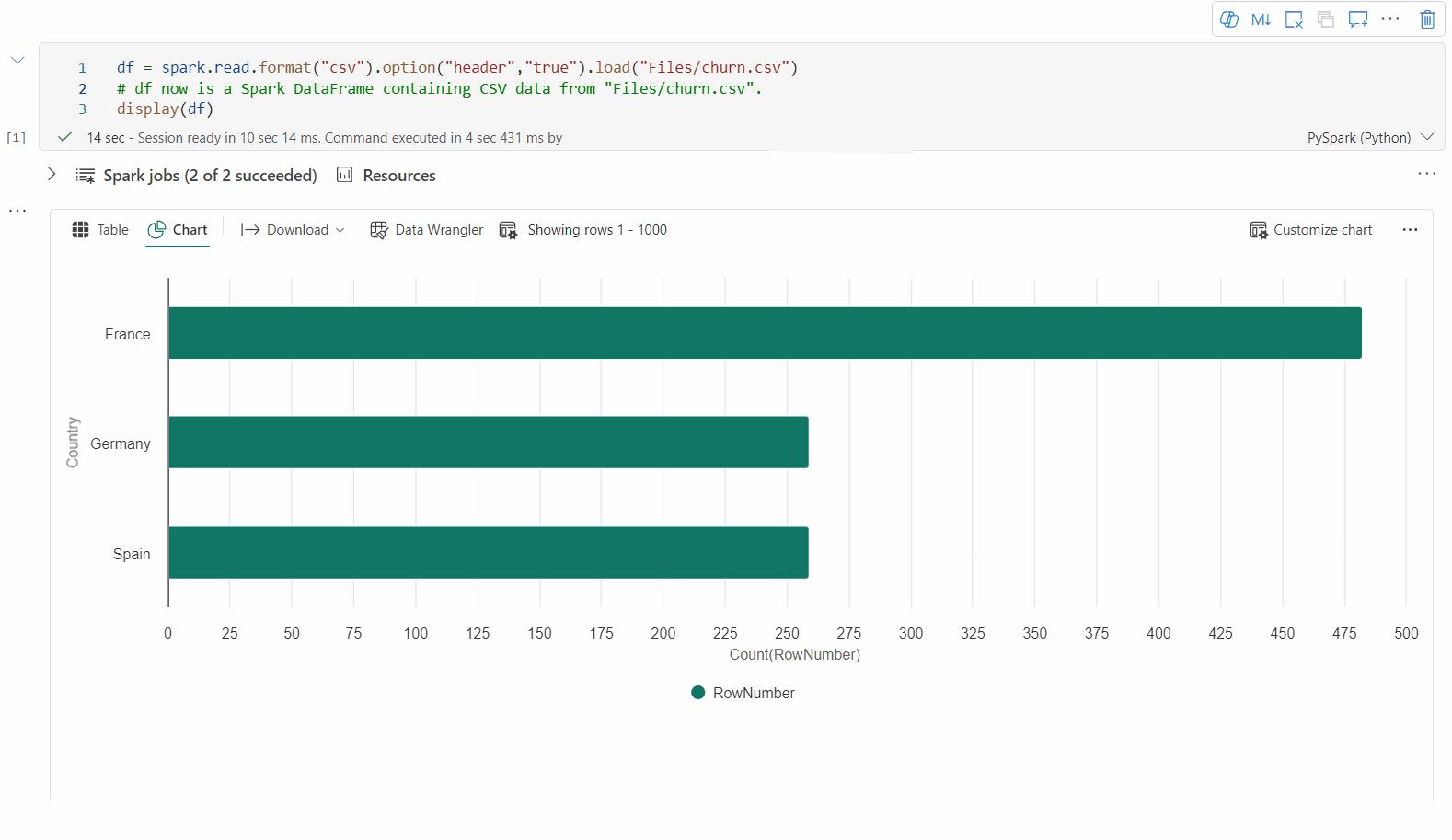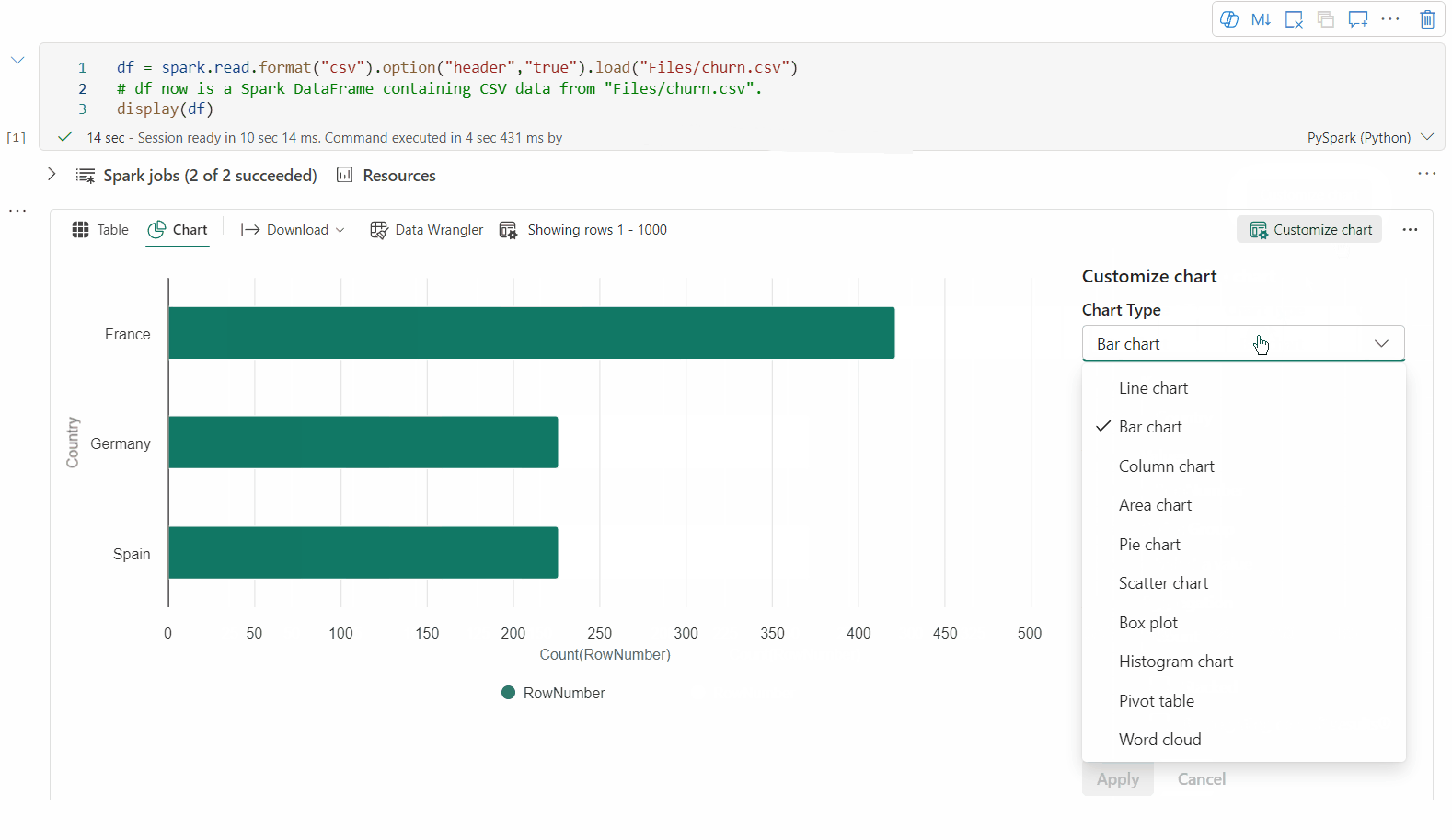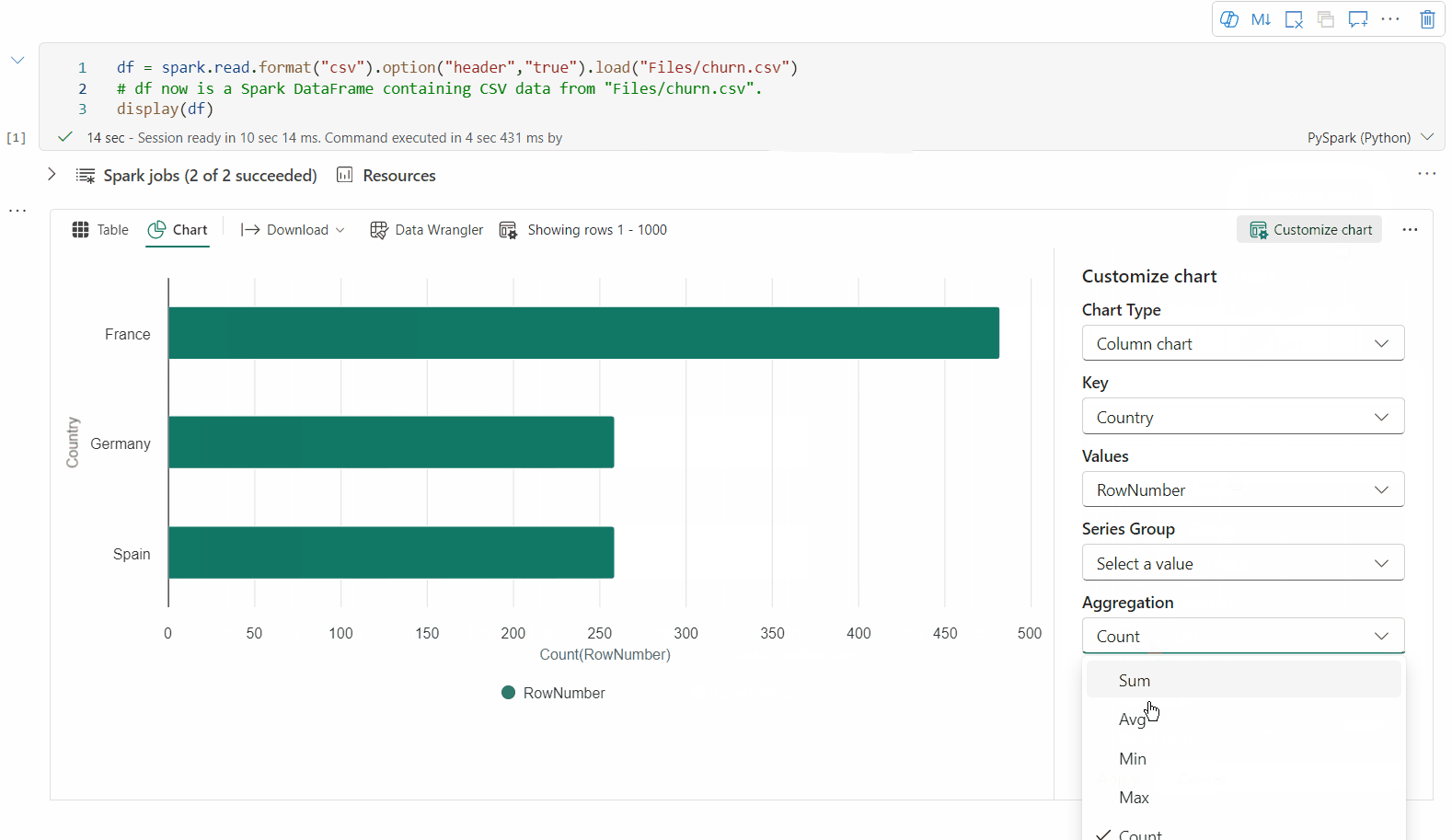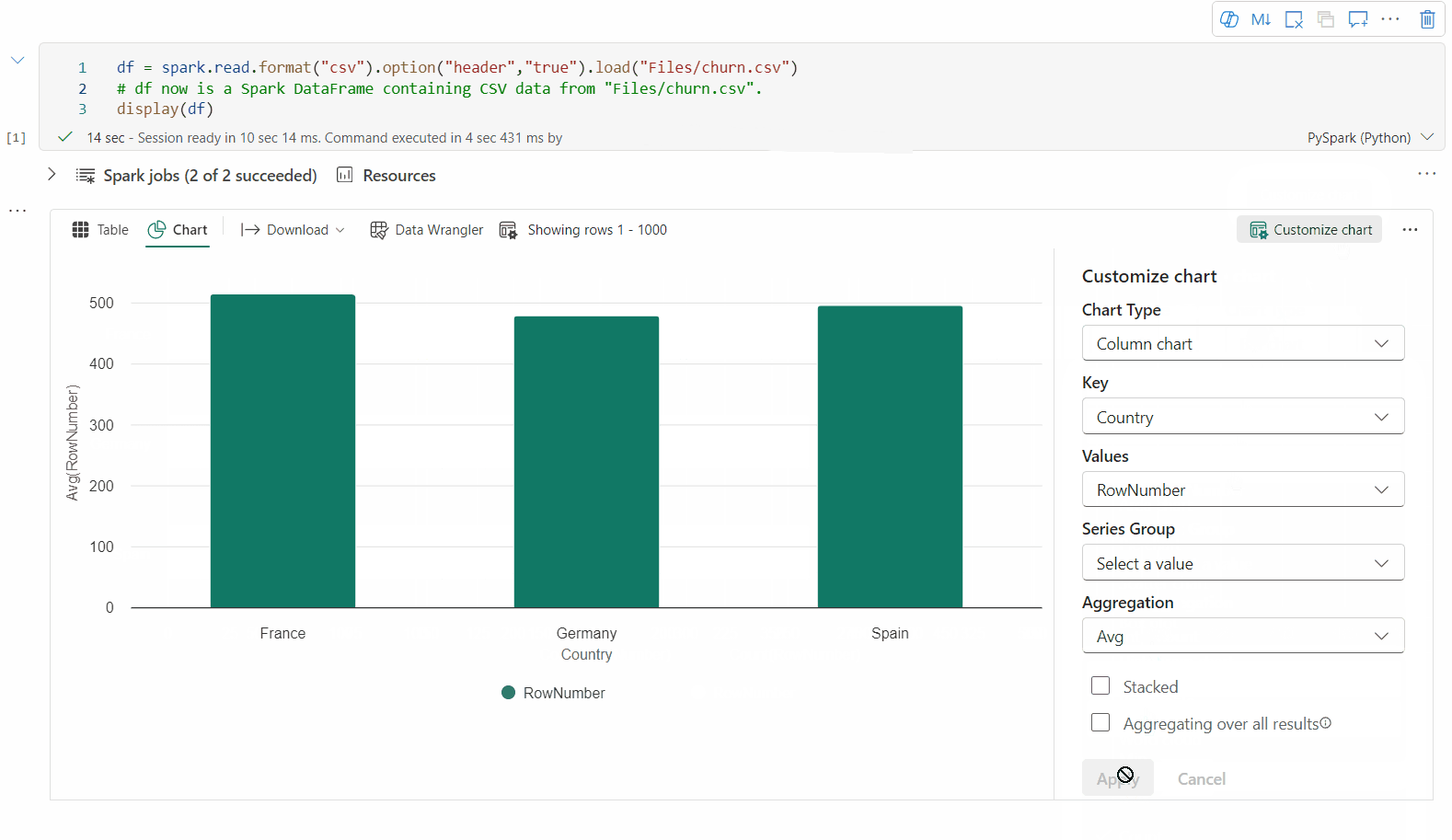
Możesz wrócić do starszego widoku wykresu, przełączając przełącznik "Nowa wizualizacja". Nowe środowisko jest domyślnie włączone.
Gdy masz renderowany widok tabeli, przejdź do widoku Wykres .
Notatnik Fabryka automatycznie proponuje wykresy na podstawie docelowej ramki danych, aby uczynić wykres bardziej przydatnym i zrozumiałym dzięki wnioskom z danych.
Teraz możesz dostosować wizualizację, określając następujące wartości:
Konfiguracja Opis Typ wykresu Funkcja wyświetlania obsługuje szeroką gamę typów wykresów, w tym wykresy słupkowe, wykresy punktowe, wykresy liniowe i inne. Klucz Określ zakres wartości dla osi x. Wartość Określ zakres wartości dla wartości osi y. Grupa serii Użyj tej konfiguracji, aby określić grupy dla agregacji. Agregacja Ta metoda służy do agregowania danych w wizualizacji. Konfiguracje są automatycznie zapisane w zawartości wyjściowej notesu.
Uwaga
Domyślnie funkcja display(df) pobiera tylko pierwsze 1000 wierszy danych w celu renderowania wykresów. Wybierz pozycję Agregacja dla wszystkich wyników , a następnie wybierz pozycję Zastosuj , aby zastosować generowanie wykresu z całej ramki danych. Zadanie platformy Spark jest wyzwalane po zmianie ustawienia wykresu. Wykonanie obliczeń i renderowanie wykresu może potrwać kilka minut.
Po zakończeniu zadania możesz wyświetlać ostateczne wizualizacje i korzystać z niej.

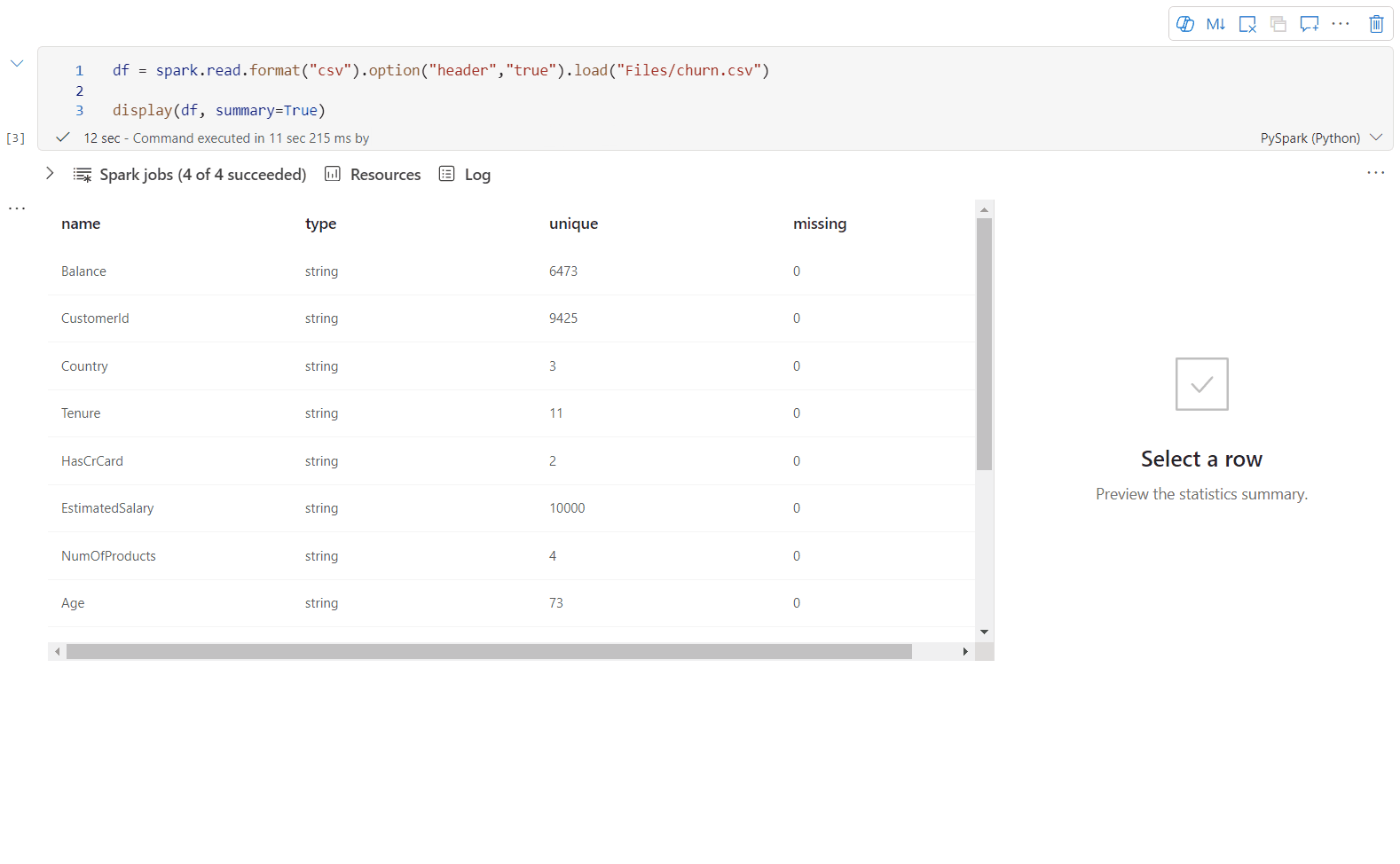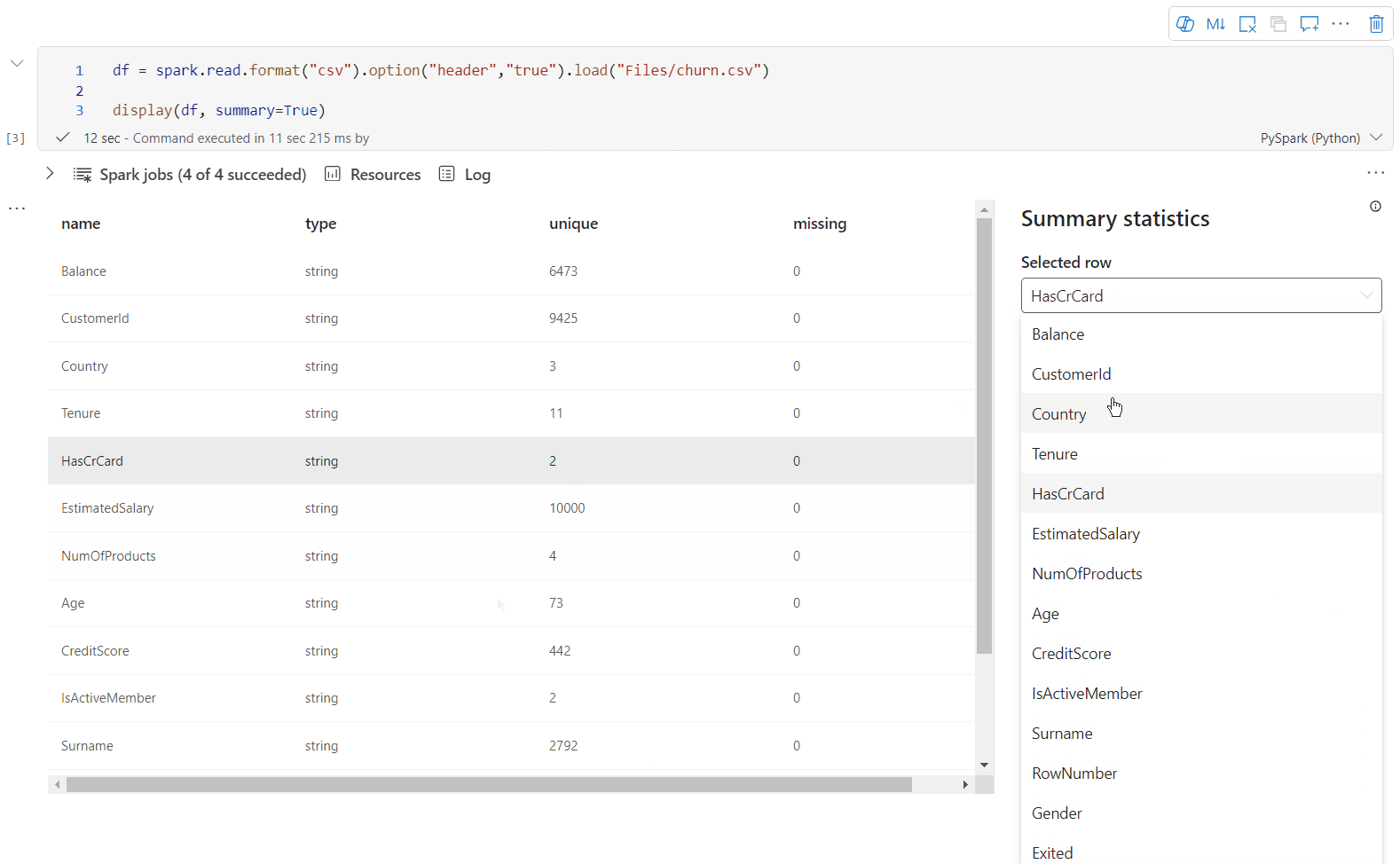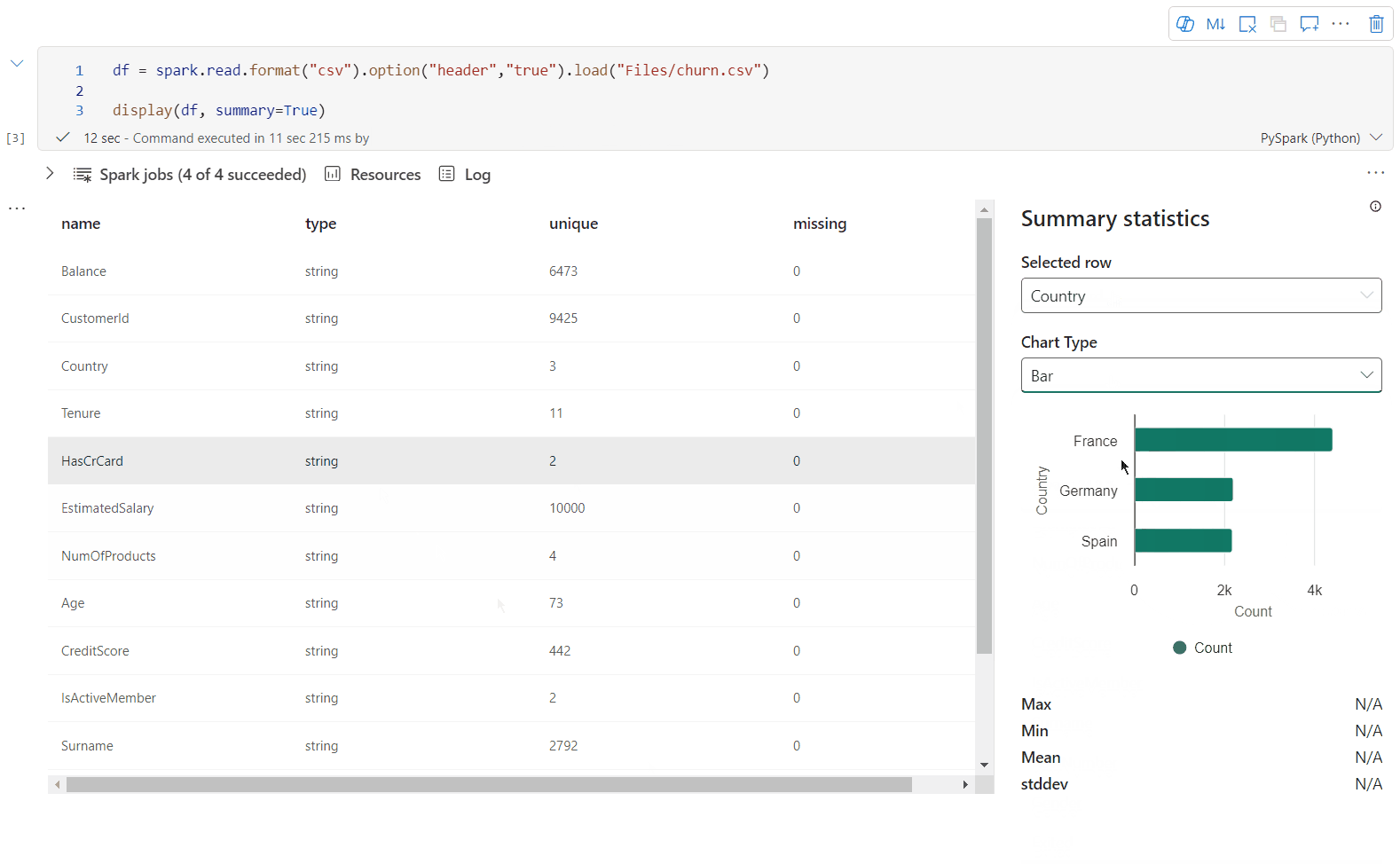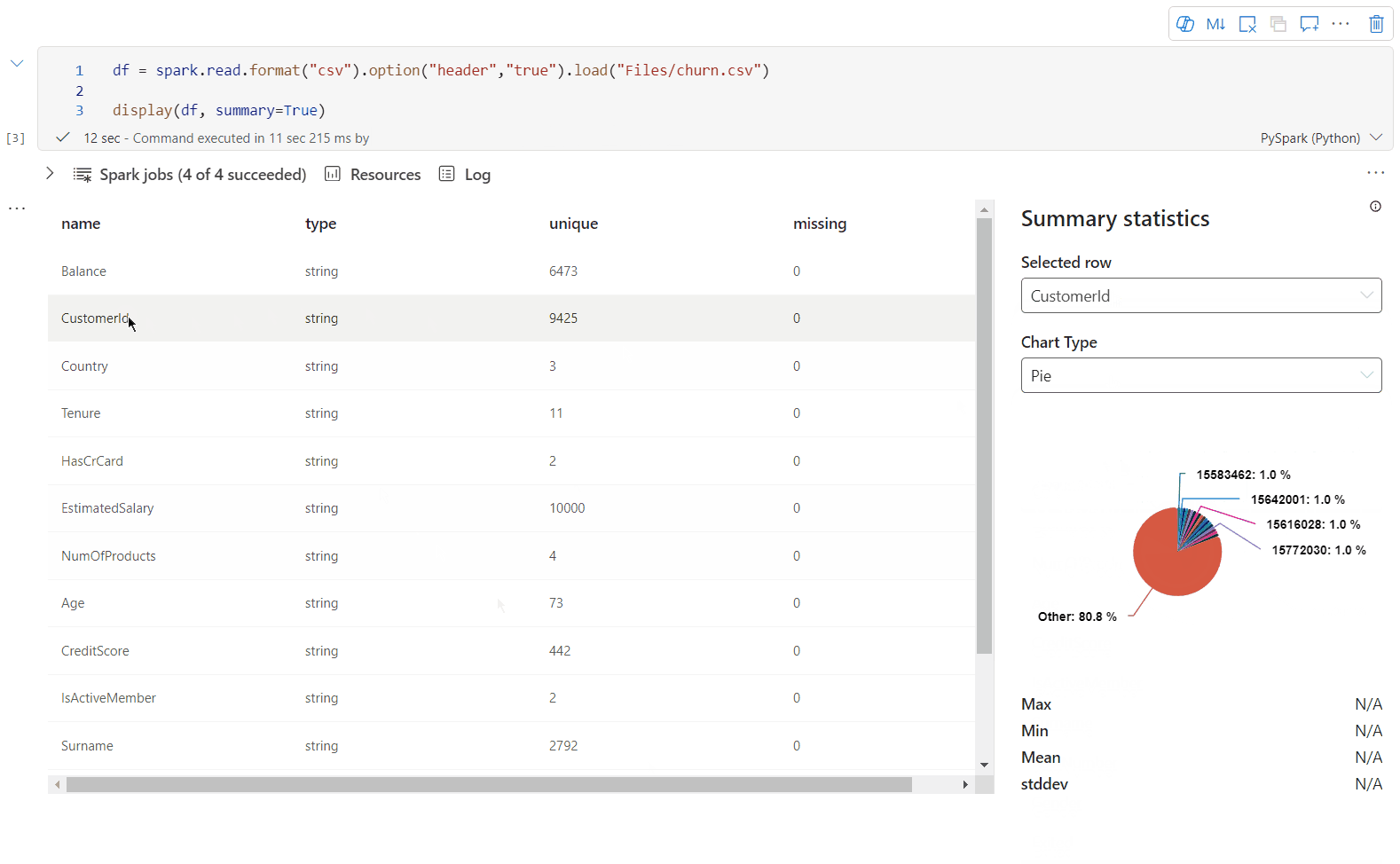
display() widok podsumowania
Użyj funkcji display(df, summary = true), aby sprawdzić podsumowanie statystyk danej ramki danych platformy Apache Spark. Podsumowanie zawiera nazwę kolumny, typ kolumny, unikatowe wartości i brakujące wartości dla każdej kolumny. Możesz również wybrać określoną kolumnę, aby wyświetlić jej wartość minimalną, maksymalną wartość, wartość średnią i odchylenie standardowe.
displayHTML() opcja
Notesy sieci szkieletowej obsługują grafikę HTML przy użyciu funkcji displayHTML .
Na poniższej ilustracji przedstawiono przykład tworzenia wizualizacji przy użyciu D3.js.

Aby utworzyć tę wizualizację, uruchom następujący kod.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Osadzanie raportu usługi Power BI w notesie
Ważne
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Te informacje odnoszą się do produktu w wersji wstępnej, który może zostać znacząco zmodyfikowany przed osiągnięciem ogólnej dostępnej wersji. Firma Microsoft nie udziela żadnych gwarancji, wyrażonych ani domniemanych, w odniesieniu do podanych tutaj informacji.
Pakiet powerbiclient języka Python jest teraz natywnie obsługiwany w notesach sieci Szkieletowej. Nie musisz wykonywać żadnych dodatkowych konfiguracji (takich jak proces uwierzytelniania) w notesie platformy Spark w sieci szkieletowej 3.4. Po prostu zaimportuj powerbiclient , a następnie kontynuuj eksplorację. Aby dowiedzieć się więcej na temat korzystania z pakietu powerbiclient, zobacz dokumentację programu powerbiclient.
Program Powerbiclient obsługuje następujące kluczowe funkcje.
Renderowanie istniejącego raportu usługi Power BI
Możesz łatwo osadzać raporty usługi Power BI i korzystać z nich w notesach za pomocą zaledwie kilku wierszy kodu.
Na poniższej ilustracji przedstawiono przykład renderowania istniejącego raportu usługi Power BI.

Uruchom następujący kod, aby renderować istniejący raport usługi Power BI.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Tworzenie wizualizacji raportu na podstawie ramki danych platformy Spark
Możesz użyć ramki danych platformy Spark w notesie, aby szybko wygenerować szczegółowe wizualizacje. Możesz również wybrać pozycję Zapisz w osadzonym raporcie, aby utworzyć element raportu w docelowym obszarze roboczym.
Na poniższej ilustracji QuickVisualize() przedstawiono przykład elementu z ramki danych platformy Spark.

Uruchom następujący kod, aby renderować raport z ramki danych Platformy Spark.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Tworzenie wizualizacji raportu na podstawie ramki danych biblioteki pandas
Raporty można również tworzyć na podstawie ramki danych biblioteki pandas w notesie.
Na poniższej ilustracji przedstawiono przykład QuickVisualize() elementu z ramki danych biblioteki pandas.

Uruchom następujący kod, aby renderować raport z ramki danych Platformy Spark.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Popularne biblioteki
Jeśli chodzi o wizualizację danych, język Python oferuje wiele bibliotek grafów, które są wyposażone w wiele różnych funkcji. Domyślnie każda pula platformy Apache Spark w usłudze Fabric zawiera zestaw wyselekcjonowanych i popularnych bibliotek typu open source.
Matplotlib
Możesz renderować standardowe biblioteki kreślenia, takie jak Matplotlib, przy użyciu wbudowanych funkcji renderowania dla każdej biblioteki.
Na poniższej ilustracji przedstawiono przykład tworzenia wykresu słupkowego przy użyciu biblioteki Matplotlib.


Uruchom następujący przykładowy kod, aby narysować ten wykres słupkowy.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
Możesz renderować biblioteki HTML lub interaktywne, takie jak bokeh, przy użyciu displayHTML(df).
Na poniższej ilustracji przedstawiono przykład kreślenia glifów na mapie przy użyciu bokeh.

Aby narysować ten obraz, uruchom następujący przykładowy kod.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Możesz renderować biblioteki HTML lub interaktywne, takie jak Plotly, przy użyciu funkcji displayHTML().
Aby narysować ten obraz, uruchom następujący przykładowy kod.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandy
Dane wyjściowe HTML ramek danych biblioteki pandas można wyświetlić jako domyślne dane wyjściowe. Notesy sieci szkieletowej automatycznie wyświetlają stylizowany kod HTML.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df