Ładowanie danych do usługi Lakehouse przy użyciu notesu
Z tego samouczka dowiesz się, jak odczytywać/zapisywać dane w usłudze Fabric lakehouse za pomocą notesu. Sieć szkieletowa obsługuje interfejs API platformy Spark i interfejs API biblioteki Pandas, aby osiągnąć ten cel.
Ładowanie danych przy użyciu interfejsu API platformy Apache Spark
W komórce kodu notesu użyj poniższego przykładu kodu, aby odczytać dane ze źródła i załadować je do plików, tabel lub obu sekcji usługi Lakehouse.
Aby określić lokalizację do odczytu, możesz użyć ścieżki względnej, jeśli dane pochodzą z domyślnego magazynu lakehouse bieżącego notesu. Lub jeśli dane pochodzą z innego magazynu lakehouse, możesz użyć bezwzględnej ścieżki systemu plików obiektów blob platformy Azure (ABFS). Skopiuj tę ścieżkę z menu kontekstowego danych.
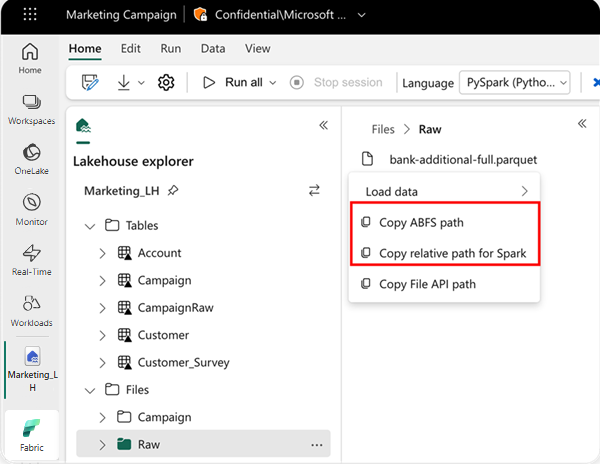
Skopiuj ścieżkę ABFS: ta opcja zwraca ścieżkę bezwzględną pliku.
Skopiuj ścieżkę względną dla platformy Spark: ta opcja zwraca względną ścieżkę pliku w domyślnym obiekcie lakehouse.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Ładowanie danych za pomocą interfejsu API biblioteki Pandas
Aby obsługiwać interfejs API biblioteki Pandas, domyślny magazyn lakehouse jest automatycznie instalowany w notesie. Punkt instalacji to "/lakehouse/default/". Za pomocą tego punktu instalacji można odczytywać/zapisywać dane z/do domyślnej bazy danych typu lakehouse. Opcja "Kopiuj ścieżkę interfejsu API pliku" z menu kontekstowego zwraca ścieżkę interfejsu API plików z tego punktu instalacji. Ścieżka zwrócona z opcji Kopiuj ścieżkę ABFS działa również dla interfejsu API biblioteki Pandas.
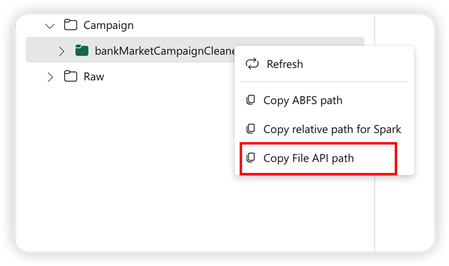
Kopiuj ścieżkę interfejsu API plików: ta opcja zwraca ścieżkę w punkcie instalacji domyślnego magazynu typu lakehouse.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Napiwek
W przypadku interfejsu API platformy Spark użyj opcji Kopiuj ścieżkę ABFS lub skopiuj ścieżkę względną dla platformy Spark, aby uzyskać ścieżkę pliku. W przypadku interfejsu API biblioteki Pandas użyj opcji Kopiuj ścieżkę ABFS lub skopiuj ścieżkę interfejsu API plików, aby uzyskać ścieżkę pliku.
Najszybszym sposobem pracy kodu z interfejsem API platformy Spark lub interfejsem API biblioteki Pandas jest użycie opcji Załaduj dane i wybranie interfejsu API, którego chcesz użyć. Kod jest generowany automatycznie w nowej komórce kodu notesu.
