Wybierz najlepszą opcję przepływu pracy ciągłej integracji/ciągłego wdrażania sieci szkieletowej
Celem tego artykułu jest przedstawienie deweloperom sieci szkieletowej różnych opcji tworzenia procesów ciągłej integracji/ciągłego wdrażania w sieci szkieletowej w oparciu o typowe scenariusze klientów. Ten artykuł koncentruje się bardziej na ciągłym wdrażaniu procesu ciągłego wdrażania/ciągłego wdrażania . Aby zapoznać się z omówieniem części ciągłej integracji , zobacz Zarządzanie gałęziami usługi Git.
Chociaż w tym artykule opisano kilka odrębnych opcji, wiele organizacji podejmuje podejście hybrydowe.
Wymagania wstępne
Aby uzyskać dostęp do funkcji potoków wdrażania, należy spełnić następujące warunki:
Masz subskrypcję usługi Microsoft Fabric
Proces programowania
Proces programowania jest taki sam we wszystkich scenariuszach wdrażania i jest niezależny od sposobu wydawania nowych aktualizacji do środowiska produkcyjnego. Gdy deweloperzy pracują z kontrolą źródła, muszą pracować w izolowanym środowisku. W sieci szkieletowej środowisko to może być środowiskiem IDE na komputerze lokalnym (takim jak Program Power BI Desktop lub VS Code) albo innym obszarem roboczym w sieci szkieletowej. Informacje o różnych zagadnieniach dotyczących procesu programowania można znaleźć w temacie Zarządzanie gałęziami usługi Git
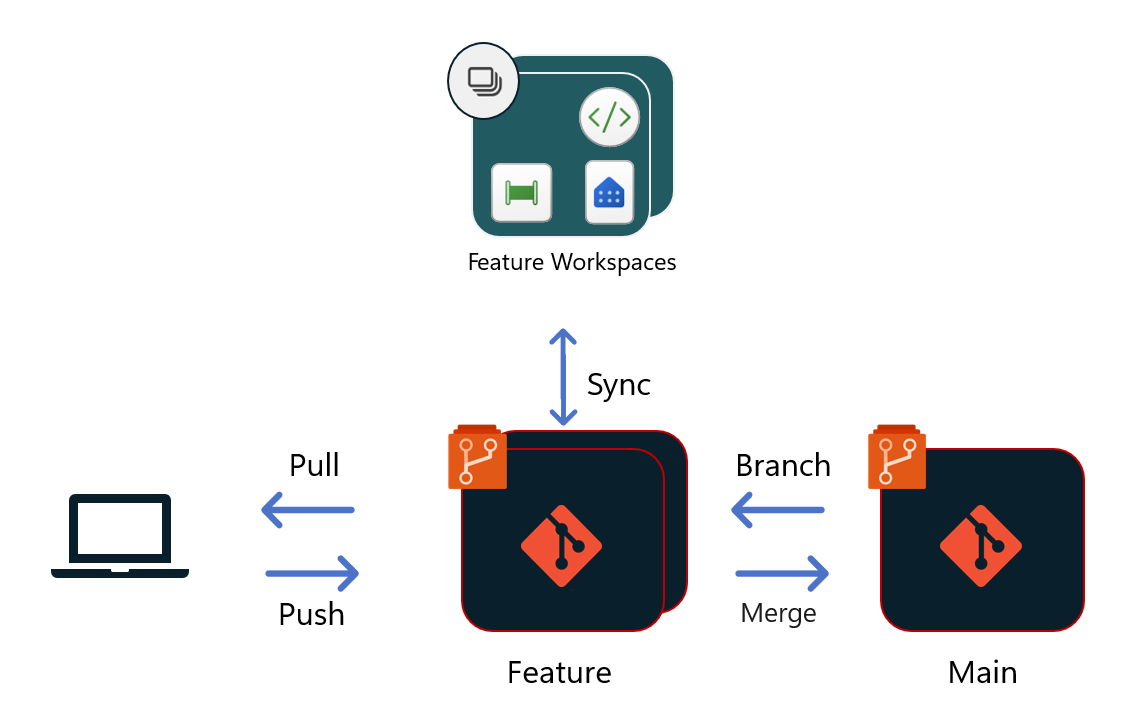
Proces wydawania
Proces wydania rozpoczyna się po zakończeniu nowych aktualizacji, a żądanie ściągnięcia (PR) scalone z udostępnioną gałęzią zespołu (na przykład Main, Dev itp.). Od tego momentu istnieją różne opcje tworzenia procesu wydania w sieci szkieletowej.
Opcja 1 — wdrożenia oparte na usłudze Git
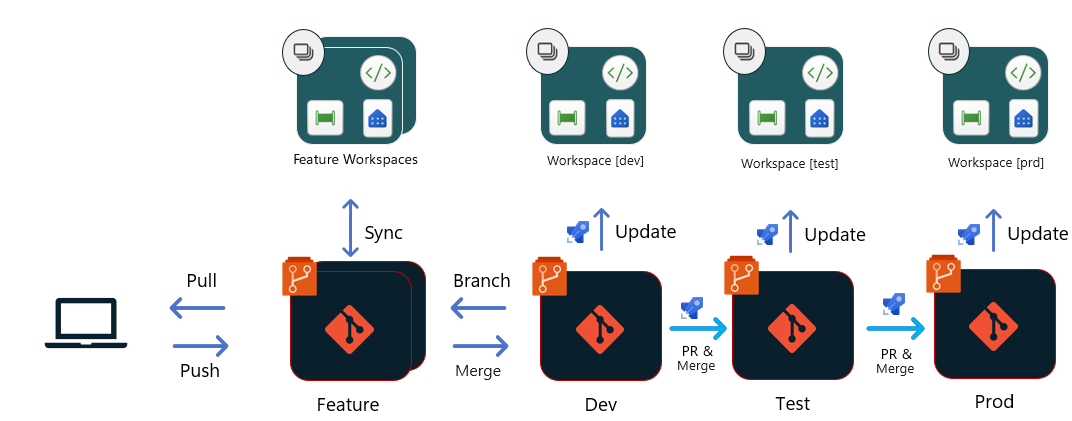
Dzięki tej opcji wszystkie wdrożenia pochodzą z repozytorium Git. Każdy etap w potoku wydania ma dedykowaną gałąź podstawową (na diagramie te etapy to Tworzenie, testowanie i Prod), które są źródłem odpowiedniego obszaru roboczego w sieci szkieletowej.
Po zatwierdzeniu i scaleniu żądania ściągnięcia z gałęzią Dev :
- Potok wydania jest wyzwalany w celu zaktualizowania zawartości obszaru roboczego Deweloper . Ten proces może również obejmować potok kompilacji do uruchamiania testów jednostkowych, ale rzeczywiste przekazywanie plików odbywa się bezpośrednio z repozytorium do obszaru roboczego przy użyciu interfejsów API git sieci szkieletowej. Może być konieczne wywołanie innych interfejsów API sieci szkieletowej dla operacji po wdrożeniu, które ustawiają określone konfiguracje dla tego obszaru roboczego, lub pozyskiwanie danych.
- Żądanie ściągnięcia jest następnie tworzone w gałęzi Test . W większości przypadków żądanie ściągnięcia jest tworzone przy użyciu gałęzi wydania, która może wybrać zawartość, aby przejść do następnego etapu. Żądanie ściągnięcia powinno obejmować te same procesy przeglądu i zatwierdzania, co każdy inny w twoim zespole lub organizacji.
- Inny potok kompilacji i wydania jest wyzwalany w celu zaktualizowania obszaru roboczego Test przy użyciu procesu podobnego do opisanego w pierwszym kroku.
- Żądanie ściągnięcia jest tworzone w gałęzi Prod przy użyciu procesu podobnego do opisanego w kroku 2.
- Inny potok kompilacji i wydania jest wyzwalany w celu zaktualizowania obszaru roboczego usługi Prod przy użyciu procesu podobnego do tego opisanego w pierwszym kroku.
Kiedy należy rozważyć użycie opcji #1?
- Jeśli chcesz użyć repozytorium Git jako pojedynczego źródła prawdy i źródła wszystkich wdrożeń.
- Gdy twój zespół jest zgodny ze strategią rozgałęziania, w tym z wieloma gałęziami podstawowymi.
- Przekazywanie z repozytorium przechodzi bezpośrednio do obszaru roboczego, ponieważ nie potrzebujemy środowisk kompilacji , aby zmienić pliki przed wdrożeniami. Można to zmienić, wywołując interfejsy API lub uruchamiając elementy w obszarze roboczym po wdrożeniu.
Opcja 2 — wdrożenia oparte na usłudze Git przy użyciu środowisk kompilacji
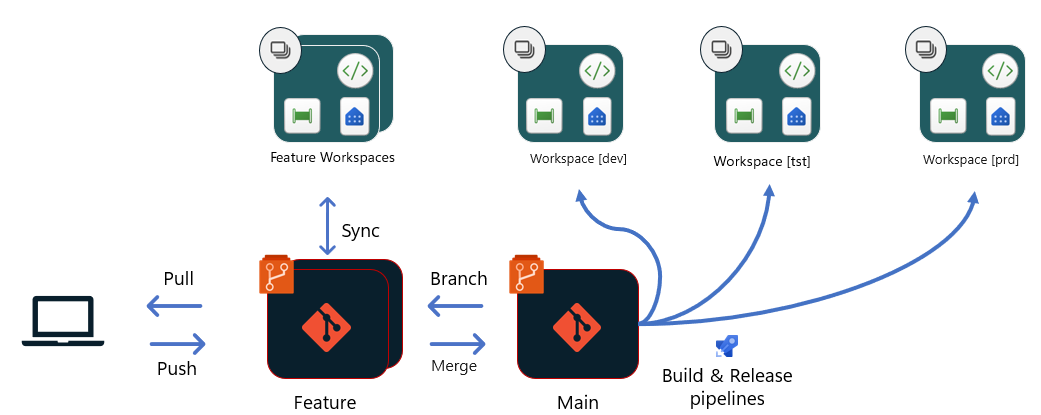
W przypadku tej opcji wszystkie wdrożenia pochodzą z tej samej gałęzi repozytorium Git (Main). Każdy etap w potoku wydania ma dedykowany potok kompilacji i wydania . Te potoki mogą używać środowiska kompilacji do uruchamiania testów jednostkowych i skryptów, które zmieniają niektóre definicje w elementach przed przekazaniem ich do obszaru roboczego. Na przykład możesz zmienić połączenie ze źródłem danych, połączenia między elementami w obszarze roboczym lub wartości parametrów, aby dostosować konfigurację dla odpowiedniego etapu.
Po zatwierdzeniu i scaleniu żądania ściągnięcia z gałęzią dewelopera :
- Potok kompilacji jest wyzwalany w celu uruchomienia nowego środowiska kompilacji i uruchamiania testów jednostkowych dla etapu deweloperskiego. Następnie potok wydania jest wyzwalany w celu przekazania zawartości do środowiska kompilacji, uruchamiania skryptów w celu zmiany niektórych konfiguracji, dostosowywania konfiguracji do etapu deweloperskiego i używania interfejsów API definicji elementu aktualizacji sieci szkieletowej w celu przekazania plików do obszaru roboczego.
- Po zakończeniu tego procesu, w tym pozyskiwaniu danych i zatwierdzania od menedżerów wersji, można utworzyć kolejne potoki kompilacji i wydania na potrzeby etapu testowania . Te etapy są tworzone w procesie podobnym do opisanego w pierwszym kroku. W przypadku etapu testu inne testy automatyczne lub ręczne mogą być wymagane po wdrożeniu, aby sprawdzić, czy zmiany są gotowe do wydania na etapie prod .
- Po zakończeniu wszystkich testów automatycznych i ręcznych menedżer wersji może zatwierdzić i uruchomić potoki kompilacji i wydania do etapu Prod . Ponieważ etap prod zwykle ma różne konfiguracje niż etapy testowania/tworzenia, ważne jest również przetestowanie zmian po wdrożeniu. Ponadto wdrożenie powinno wyzwolić więcej pozyskiwania danych w oparciu o zmianę, aby zminimalizować potencjalne brak dostępności dla konsumentów.
Kiedy należy rozważyć użycie opcji #2?
- Jeśli chcesz użyć usługi Git jako pojedynczego źródła prawdy i źródła wszystkich wdrożeń.
- Gdy zespół jest zgodny z przepływem pracy opartym na magistrali jako strategią rozgałęziania.
- Do zmiany atrybutów specyficznych dla obszaru roboczego, takich jak connectionId i lakehouseId, przed wdrożeniem potrzebne jest środowisko kompilacji (z niestandardowym skryptem).
- Potrzebujesz potoku wydania (skryptu niestandardowego), aby pobrać zawartość elementu z usługi git i wywołać odpowiedni interfejs API elementu sieci szkieletowej do tworzenia, aktualizowania lub usuwania zmodyfikowanych elementów sieci szkieletowej.
Opcja 3 — wdrażanie przy użyciu potoków wdrażania sieci szkieletowej
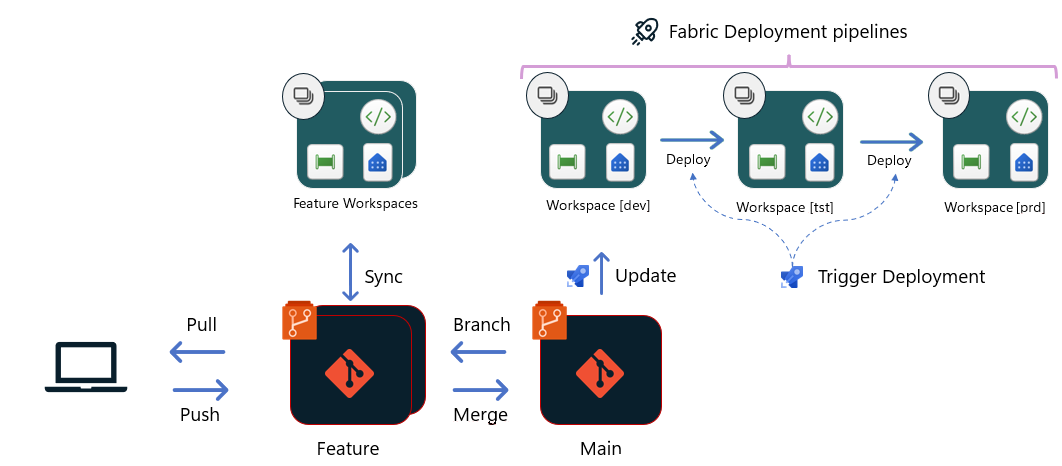
W przypadku tej opcji usługa Git jest połączona tylko do etapu deweloperskiego. Na etapie tworzenia wdrożenia są wykonywane bezpośrednio między obszarami roboczymi środowiska Tworzenie i testowanie/prod przy użyciu potoków wdrażania sieci szkieletowej. Chociaż samo narzędzie jest wewnętrzne w usłudze Fabric, deweloperzy mogą używać interfejsów API potoków wdrażania do organizowania wdrożenia w ramach potoku wydania platformy Azure lub przepływu pracy usługi GitHub. Te interfejsy API umożliwiają zespołowi tworzenie podobnego procesu kompilacji i wydania , tak jak w innych opcjach, przy użyciu testów automatycznych (które można wykonać w samym obszarze roboczym lub przed etapem deweloperskim ), zatwierdzenia itp.
Po zatwierdzeniu i scaleniu żądania ściągnięcia z gałęzią główną :
- Potok kompilacji jest wyzwalany, który przekazuje zmiany do etapu deweloperskiego przy użyciu interfejsów API git usługi Fabric. W razie potrzeby potok może wyzwolić inne interfejsy API, aby rozpocząć operacje/testy po wdrożeniu na etapie deweloperskim.
- Po zakończeniu wdrażania deweloperskiego potok wydania rozpoczyna się w celu wdrożenia zmian z etapu deweloperskiego do etapu testowania . Testy automatyczne i ręczne powinny odbywać się po wdrożeniu, aby upewnić się, że zmiany są dobrze przetestowane przed dotarciem do środowiska produkcyjnego.
- Po zakończeniu testów, a menedżer wydania zatwierdzi wdrożenie na etapie Prod, wydanie do wersji Prod rozpoczyna i kończy wdrożenie.
Kiedy należy rozważyć użycie opcji #3?
- Jeśli używasz kontroli źródła tylko do celów programistycznych i wolisz wdrażać zmiany bezpośrednio między etapami potoku wydania.
- W przypadku reguł wdrażania automatyczne powiązanie i inne dostępne interfejsy API są wystarczające do zarządzania konfiguracjami między etapami potoku wydania.
- Jeśli chcesz użyć innych funkcji potoków wdrażania sieci szkieletowej, takich jak wyświetlanie zmian w sieci szkieletowej, historia wdrożenia itp.
- Należy również rozważyć, że wdrożenia w potokach wdrażania sieci szkieletowej mają strukturę liniową i wymagają innych uprawnień do tworzenia potoku i zarządzania nim.
Opcja 4 — ciągła integracja/ciągłe wdrażanie dla niezależnych dostawców oprogramowania w sieci szkieletowej (zarządzanie wieloma klientami/rozwiązaniami)
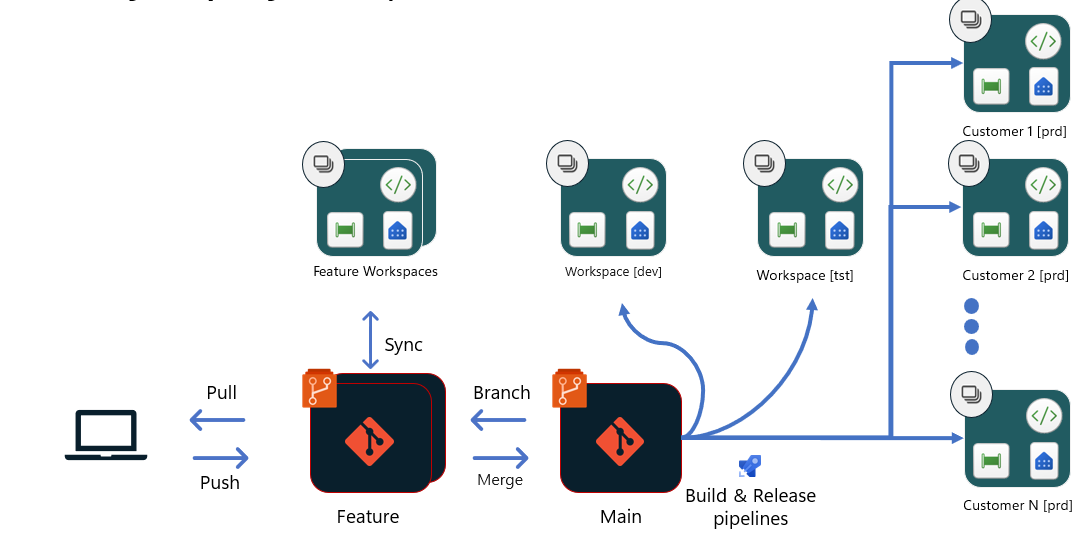
Ta opcja różni się od innych. Jest to najbardziej istotne dla niezależnych dostawców oprogramowania (ISV), którzy tworzą aplikacje SaaS dla swoich klientów na platformie Szkieletowej. Niezależni dostawcy oprogramowania zwykle mają oddzielny obszar roboczy dla każdego klienta i mogą mieć aż kilkaset lub tysięcy obszarów roboczych. Gdy struktura analizy udostępnianej każdemu klientowi jest podobna i nieaktualna, zalecamy scentralizowany proces programowania i testowania, który dzieli się na każdego klienta tylko na etapie Prod .
Ta opcja jest oparta na opcji 2. Po zatwierdzeniu i scaleniu żądania ściągnięcia z głównym żądaniem ściągnięcia:
- Potok kompilacji jest wyzwalany w celu uruchomienia nowego środowiska kompilacji i uruchamiania testów jednostkowych dla etapu deweloperskiego. Po zakończeniu testów zostanie wyzwolony potok wydania . Ten potok może przekazać zawartość do środowiska kompilacji, uruchomić skrypty, aby zmienić część konfiguracji, dostosować konfigurację do etapu deweloperskiego, a następnie użyć interfejsów API definicji elementu aktualizacji sieci szkieletowej, aby przekazać pliki do obszaru roboczego.
- Po zakończeniu tego procesu, w tym pozyskiwaniu danych i zatwierdzania przez menedżerów wydań, kolejne potoki kompilacji i wydania na etapie testowania mogą rozpocząć się. Ten proces jest podobny do opisanego w pierwszym kroku. W przypadku etapu testowania inne testy automatyczne lub ręczne mogą być wymagane po wdrożeniu, aby sprawdzić, czy zmiany są gotowe do wydania na etapie Prod w wysokiej jakości.
- Po zakończeniu wszystkich testów i zakończeniu procesu zatwierdzania można rozpocząć wdrażanie dla klientów wersji Prod . Każdy klient ma własne wydanie z własnymi parametrami, dzięki czemu jego konkretna konfiguracja i połączenie danych mogą mieć miejsce w obszarze roboczym odpowiedniego klienta. Zmiana konfiguracji może wystąpić za pomocą skryptów w środowisku kompilacji lub przy użyciu interfejsów API po wdrożeniu. Wszystkie wydania mogą występować równolegle, ponieważ nie są ze sobą powiązane ani zależne.
Kiedy należy rozważyć użycie opcji #4?
- Jesteś niezależnego dostawcą oprogramowania tworzącym aplikacje w sieci szkieletowej.
- Do zarządzania wieloma dzierżawami aplikacji używasz różnych obszarów roboczych dla każdego klienta
- W przypadku większej separacji lub określonych testów dla różnych klientów warto mieć wiele dzierżaw we wcześniejszych etapach tworzenia lub testowania. W takim przypadku należy wziąć pod uwagę, że w przypadku wielu dzierżaw liczba wymaganych obszarów roboczych znacznie się zwiększa.
Podsumowanie
Ten artykuł zawiera podsumowanie głównych opcji ciągłej integracji/ciągłego wdrażania dla zespołu, który chce utworzyć zautomatyzowany proces ciągłej integracji/ciągłego wdrażania w sieci szkieletowej. Chociaż opisano cztery opcje, rzeczywiste ograniczenia i architektura rozwiązania mogą dawać się do opcji hybrydowych lub zupełnie innych. Możesz użyć tego artykułu, aby zapoznać się z różnymi opcjami i sposobami ich kompilowania, ale nie musisz wybierać tylko jednej z opcji.
Niektóre scenariusze lub określone elementy mogą mieć ograniczenia , które mogą uniemożliwić wdrożenie dowolnego z tych scenariuszy.
To samo dotyczy narzędzi. Chociaż w tym miejscu wspominamy o różnych narzędziach, możesz wybrać inne narzędzia, które mogą zapewnić ten sam poziom funkcjonalności. Należy wziąć pod uwagę, że sieć szkieletowa ma lepszą integrację z niektórymi narzędziami, dlatego wybranie innych powoduje zwiększenie ograniczeń wymagających różnych obejść.