Co to są potoki wdrażania?
Uwaga
W artykułach w tej sekcji opisano sposób wdrażania zawartości w aplikacji. Aby uzyskać informacje na temat kontroli wersji, zobacz dokumentację integracji z usługą Git.
Narzędzie potoków wdrażania usługi Microsoft Fabric udostępnia twórcom zawartości środowisko produkcyjne, w którym mogą współpracować z innymi osobami w celu zarządzania cyklem życia zawartości organizacyjnej. Potoki wdrażania umożliwiają twórcom opracowywanie i testowanie zawartości w usłudze przed dotarciem do użytkowników. Zobacz pełną listę obsługiwanych typów elementów, które można wdrożyć.
Uwaga
- Nowy interfejs użytkownika potoku wdrażania jest obecnie w wersji zapoznawczej. Aby włączyć lub użyć nowego interfejsu użytkownika, zobacz Rozpoczynanie korzystania z nowego interfejsu użytkownika.
- Niektóre elementy potoków wdrażania są dostępne w wersji zapoznawczej. Aby uzyskać więcej informacji, zobacz listę obsługiwanych elementów.
Dowiedz się, jak używać potoków wdrażania
Aby dowiedzieć się, jak używać narzędzia potoków wdrażania, skorzystaj z tych linków.
Tworzenie potoku wdrażania i zarządzanie nim — moduł Learn, który przeprowadzi Cię przez cały proces tworzenia potoku wdrażania.
Wprowadzenie do potoków wdrażania — artykuł wyjaśniający sposób tworzenia potoku i kluczowych funkcji, takich jak wdrażanie, porównywanie zawartości na różnych etapach i tworzenie reguł wdrażania.
Obsługiwane elementy
Podczas wdrażania zawartości z jednego etapu potoku do innego skopiowana zawartość może zawierać następujące elementy:
- Pulpity nawigacyjne
- Potokidanych (wersja zapoznawcza)
- dataflows gen2(wersja zapoznawcza)
- Datamarts(wersja zapoznawcza)
- środowisko(podgląd)
- Eventhouse i baza danychKQL (wersja zapoznawcza)
EventStream (wersja zapoznawcza) - Lakehouse(wersja zapoznawcza)
- zmirorowana baza danych(wersja zapoznawcza)
- Notesy
- Aplikacje organizacyjne (wersja zapoznawcza)
- Raporty wielostronicowe
- Przepływy danych usługi Power BI
- Odruch (wersja zapoznawcza)
- Raporty (oparte na obsługiwanych modelach semantycznych)
- Modele semantyczne (pochodzące z plików pbix i nie są zestawami danych PUSH)
- Baza danych SQL (wersja zapoznawcza)
- Magazyny(wersja zapoznawcza)
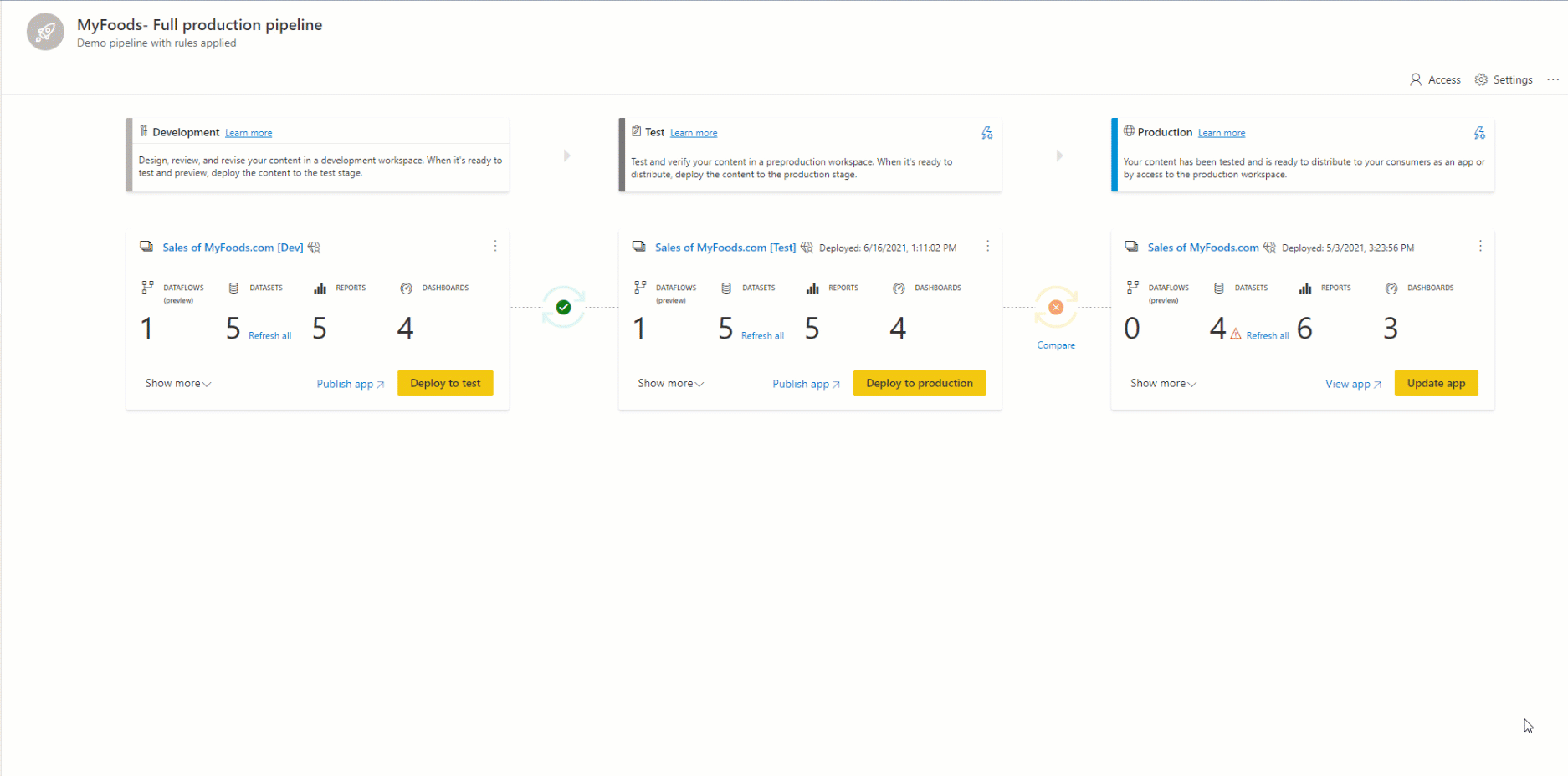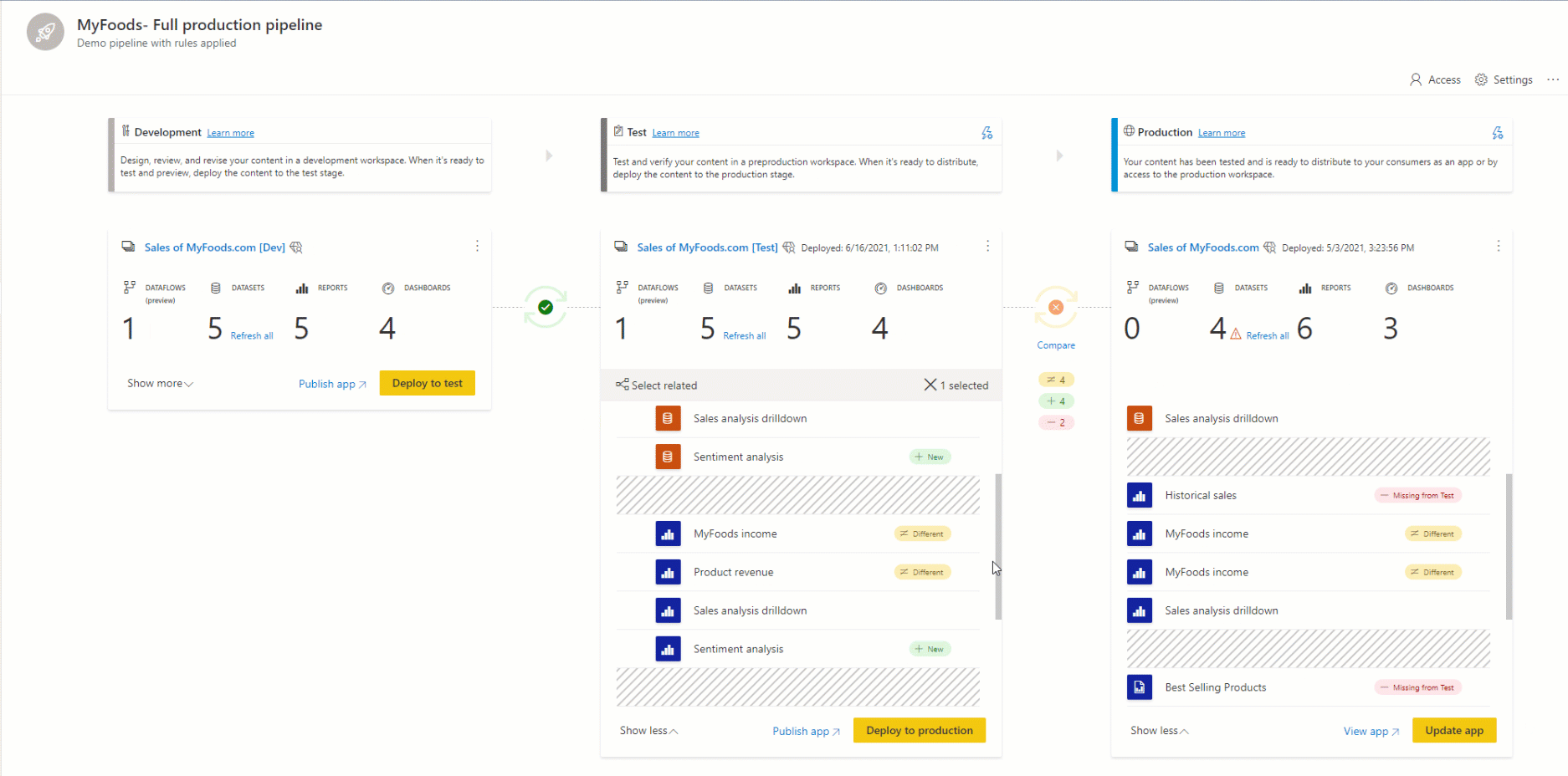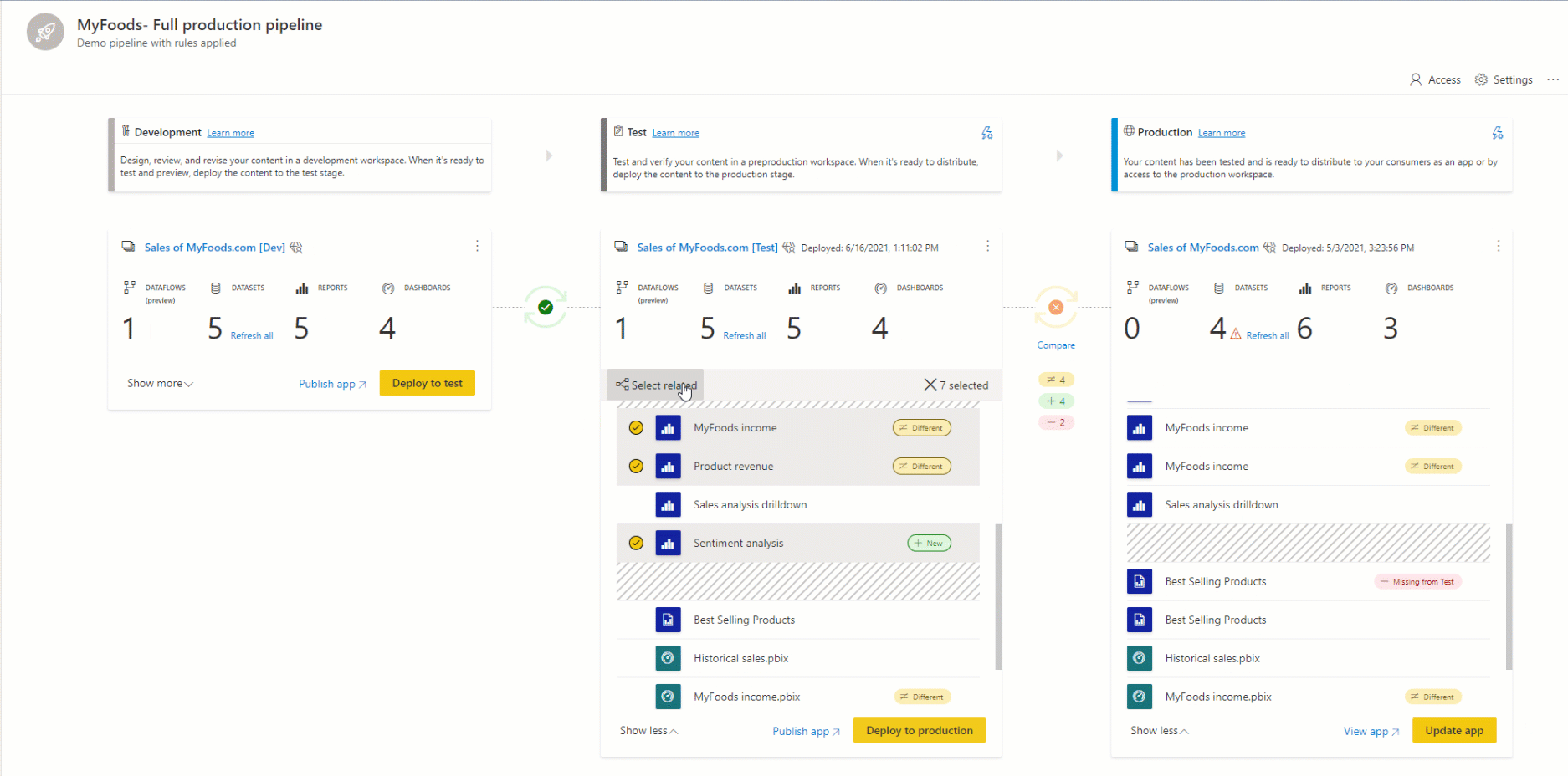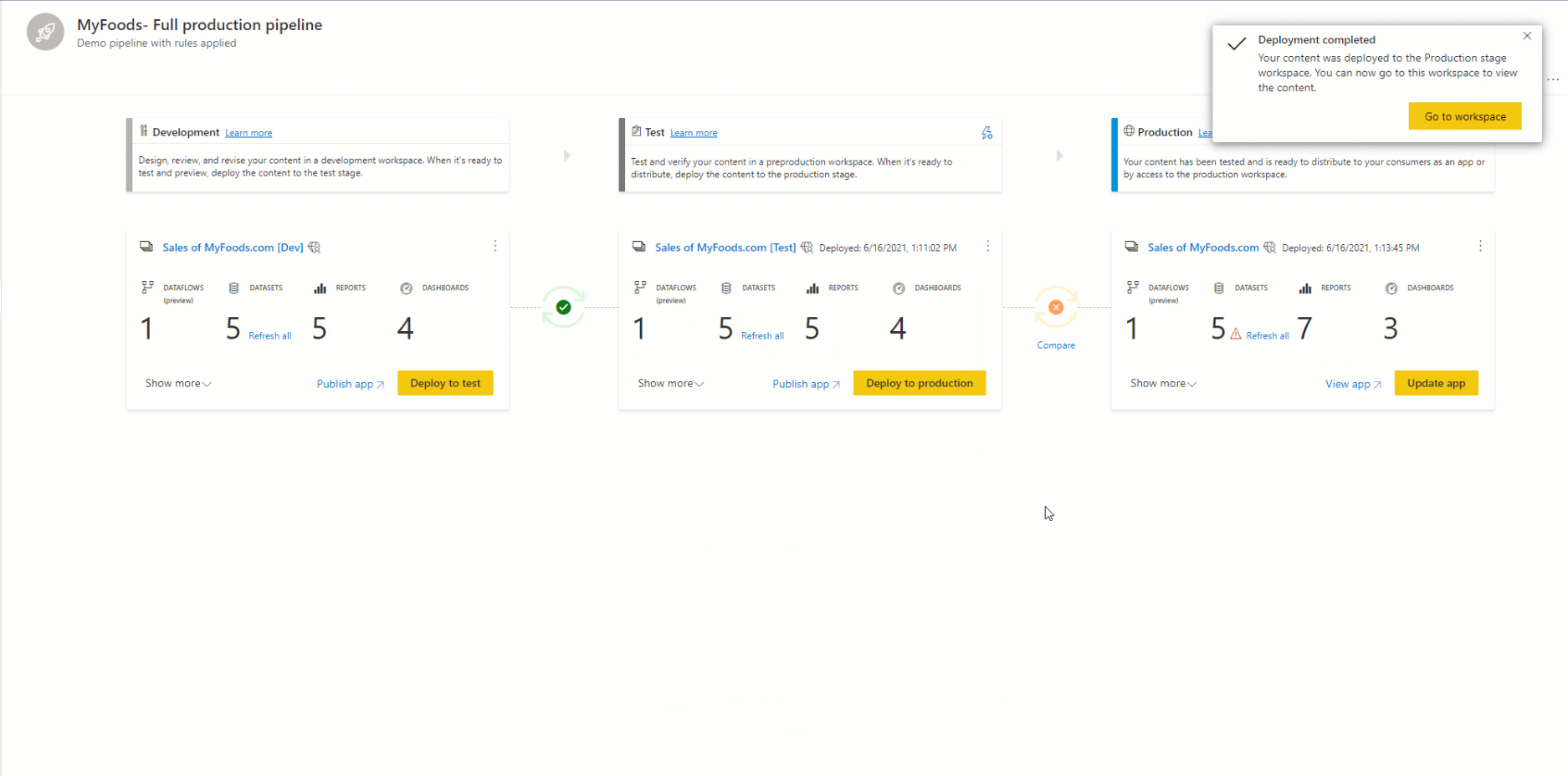
Struktura potoku
Decydujesz o tylu etapach, które mają być używane w potoku wdrażania. Może istnieć od dwóch do dziesięciu etapów. Podczas tworzenia potoku domyślne trzy typowe etapy są podane jako punkt początkowy, ale można dodawać, usuwać lub zmieniać nazwy etapów zgodnie z potrzebami. Niezależnie od tego, ile etapów istnieje, ogólne pojęcia są takie same:
-
Pierwszym etapem wdrażania jest przekazanie nowej zawartości innym twórcom. Możesz projektować i opracowywać w tym miejscu lub na innym etapie.
-
Po wprowadzeniu wszystkich wymaganych zmian w zawartości możesz przystąpić do etapu testowania. Przekaż zmodyfikowaną zawartość, aby można ją było przenieść do tego etapu testu. Oto trzy przykłady tego, co można zrobić w środowisku testowym:
Udostępnianie zawartości testerom i recenzentom
Ładowanie i uruchamianie testów z większymi ilościami danych
Przetestuj aplikację, aby zobaczyć, jak wygląda ona dla użytkowników końcowych
-
Po przetestowaniu zawartości użyj etapu produkcyjnego, aby udostępnić ostateczną wersję zawartości użytkownikom biznesowym w całej organizacji.
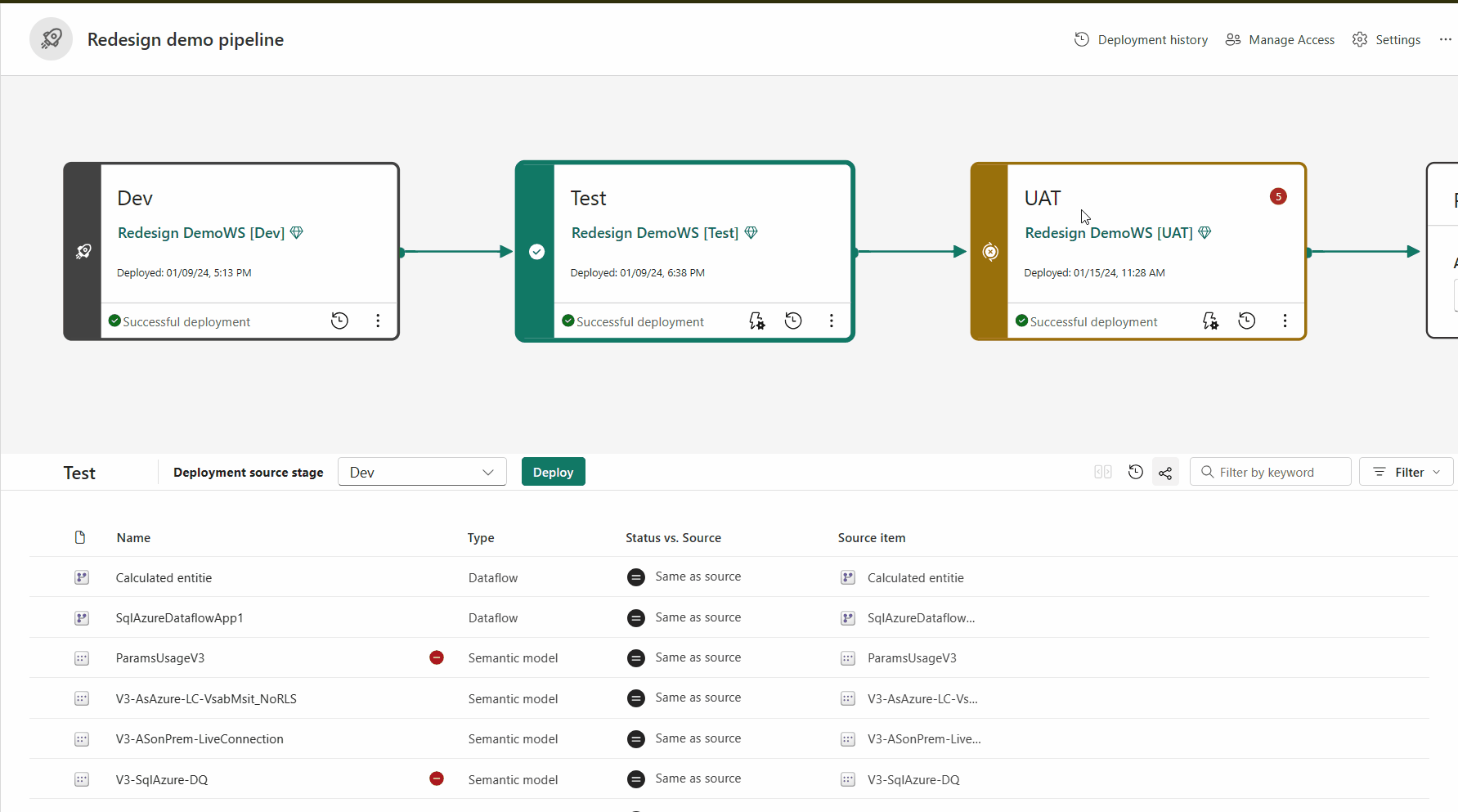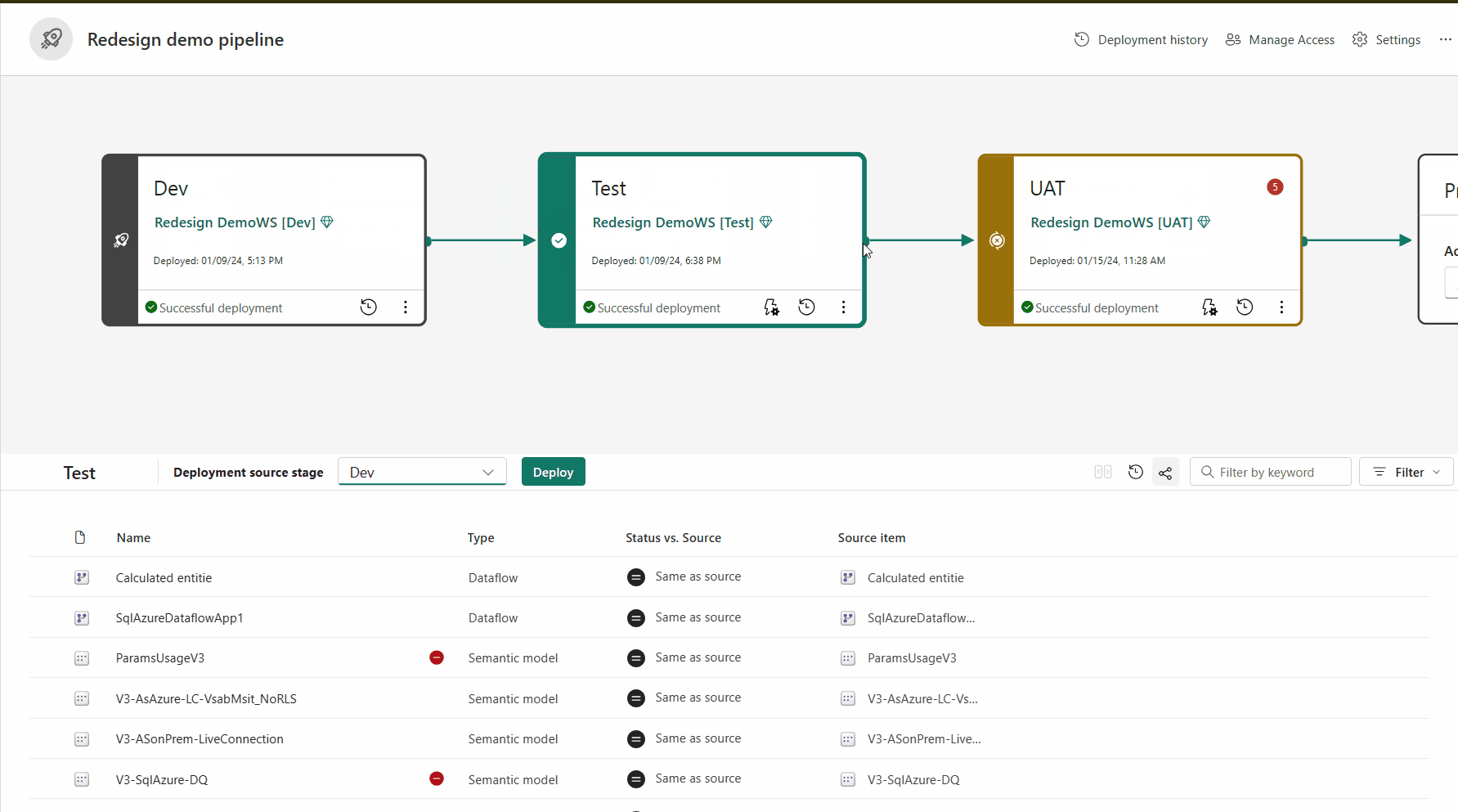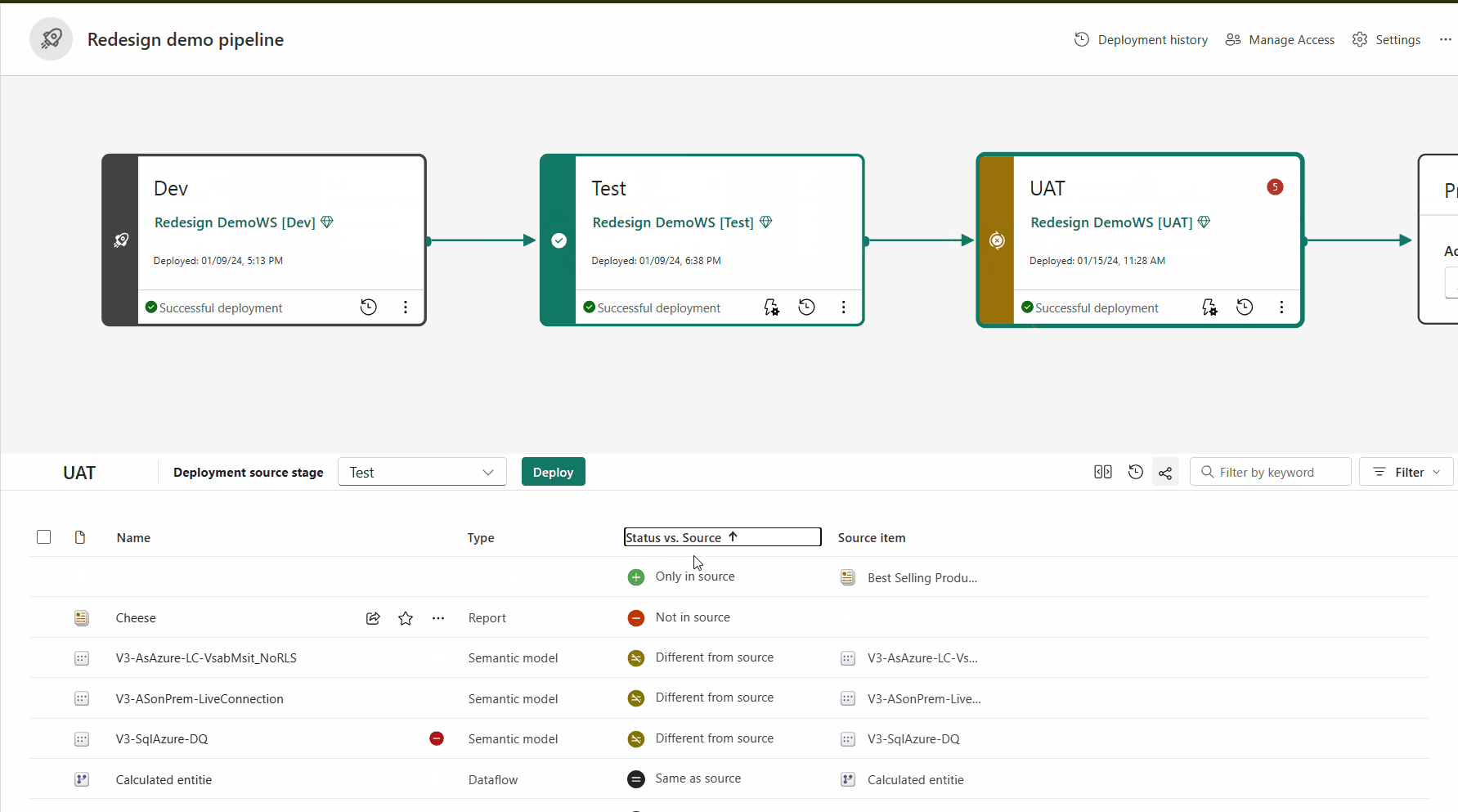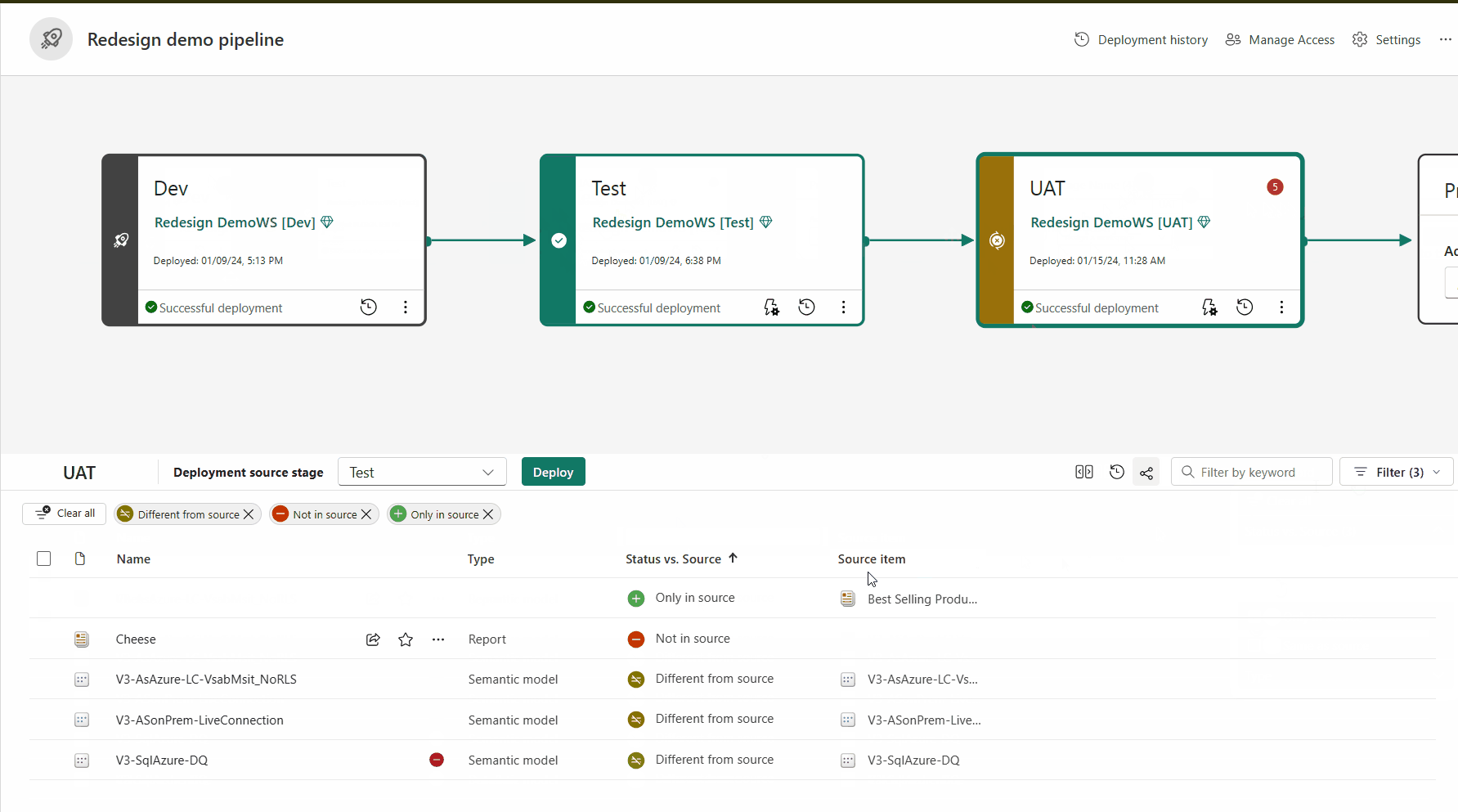
Parowanie elementów
Parowanie to proces, w którym element (taki jak raport, pulpit nawigacyjny lub model semantyczny) w jednym etapie potoku wdrażania jest skojarzony z tym samym elementem w sąsiednim etapie. Parowanie występuje podczas przypisywania obszaru roboczego do etapu wdrażania lub wdrażania nowej niezapłaconej zawartości z jednego etapu do innego (czystego wdrożenia).
Ważne jest, aby zrozumieć, jak działa parowanie, aby zrozumieć, kiedy elementy są kopiowane, kiedy są zastępowane, a kiedy wdrożenie kończy się niepowodzeniem podczas korzystania z funkcji wdrażania.
Jeśli elementy nie są sparowane, nawet jeśli wydają się być takie same (mają taką samą nazwę, typ i folder), nie zastępują wdrożenia. Zamiast tego tworzona jest zduplikowana kopia i sparowana z elementem w poprzednim etapie.
Sparowane elementy są wyświetlane w tym samym wierszu na liście zawartości potoku. Elementy, które nie są sparowane, są wyświetlane samodzielnie w wierszu:
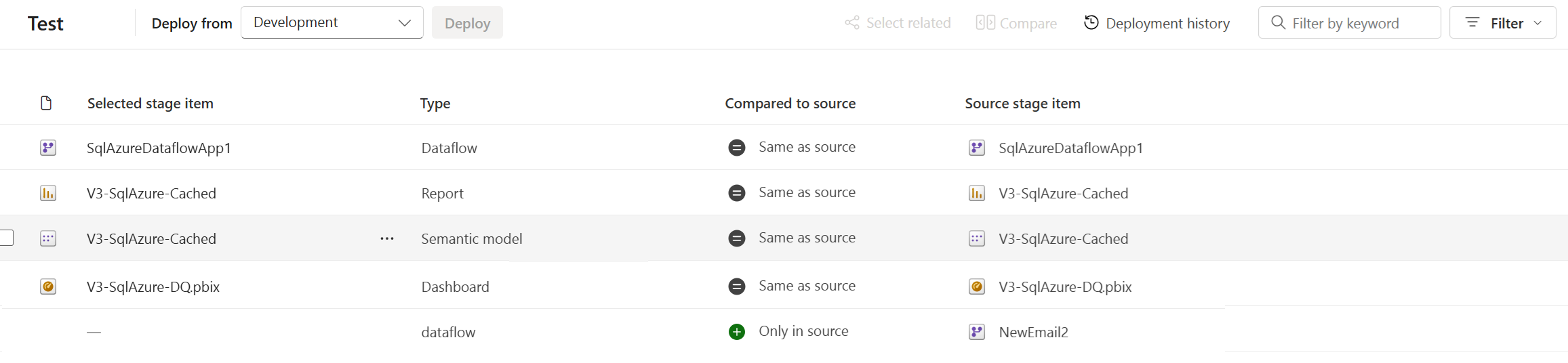
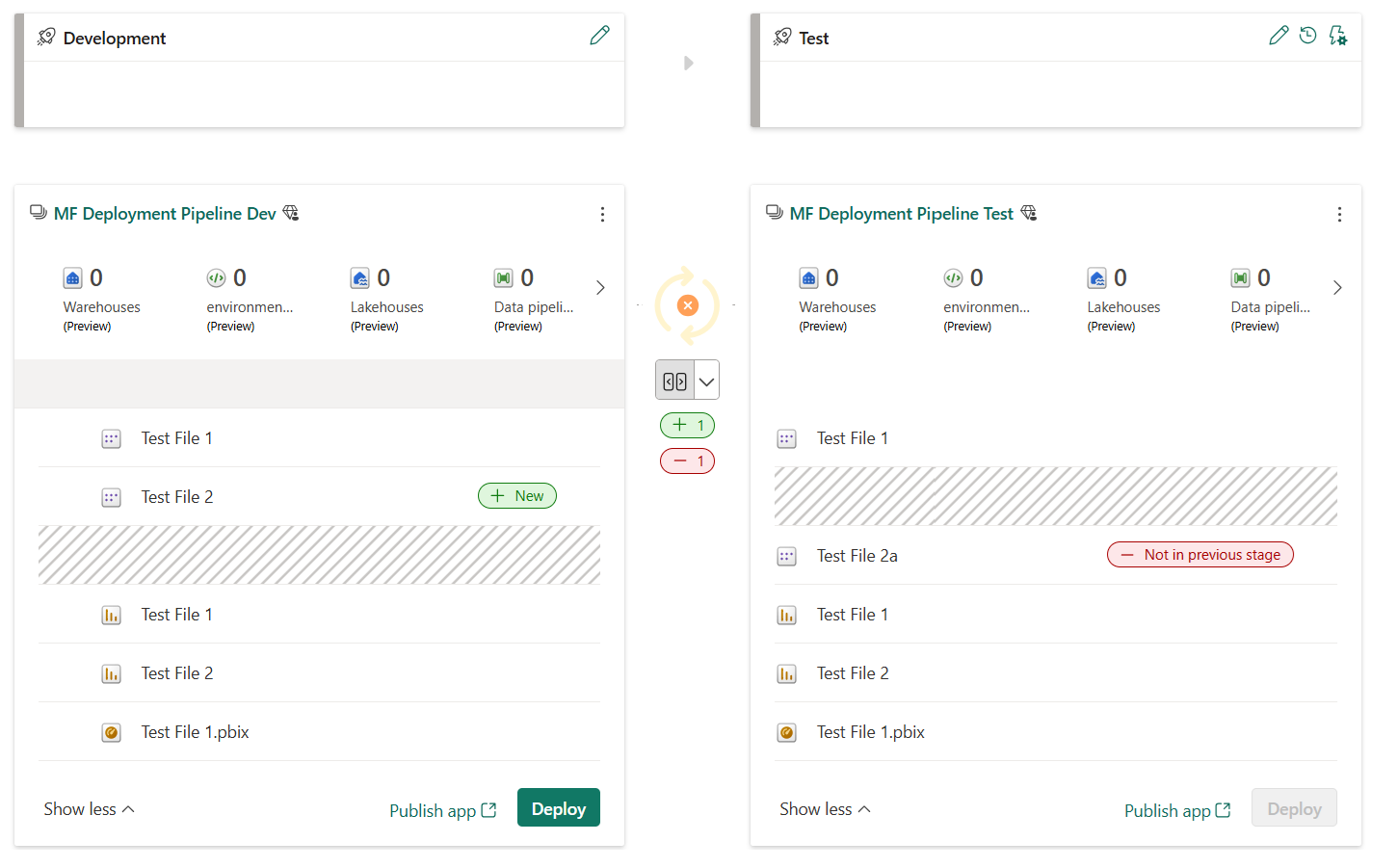
- Elementy sparowane pozostają sparowane, nawet jeśli zmienisz ich nazwy. W związku z tym sparowane elementy mogą mieć różne nazwy.
- Elementy dodane po przypisaniu obszaru roboczego do potoku nie są automatycznie sparowane. W związku z tym można mieć identyczne elementy w sąsiednich obszarach roboczych, które nie są sparowane.
Aby uzyskać szczegółowe wyjaśnienie, które elementy są sparowane i jak działa parowanie, zobacz Parowanie elementów.
Metoda wdrażania
Aby wdrożyć zawartość na innym etapie, należy wybrać co najmniej jeden element. Podczas wdrażania zawartości z jednego etapu do innego elementy kopiowane z etapu źródłowego zastępują sparowany element na etapie, w którym znajdujesz się zgodnie z regułami parowania. Elementy, które nie istnieją na etapie źródłowym, pozostają w niezmienionej postaci.
Po wybraniu pozycji Wdróż zostanie wyświetlony komunikat potwierdzający.
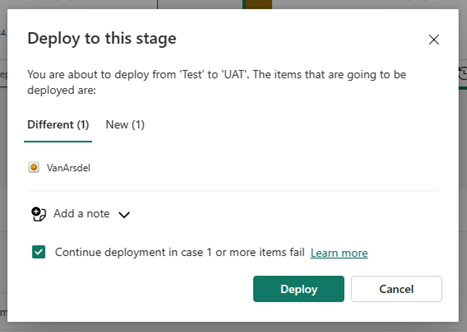
Dowiedz się więcej o tym, które właściwości elementu są kopiowane do następnego etapu i które właściwości nie są kopiowane, w artykule Opis procesu wdrażania.
Automation
Zawartość można również wdrożyć programowo przy użyciu interfejsów API REST potoków wdrażania. Dowiedz się więcej o procesie automatyzacji w temacie Automatyzowanie potoku wdrażania przy użyciu interfejsów API i metodyki DevOps.