Microsoft Entra Connect Sync: Omówienie architektury
W tym artykule opisano podstawową architekturę usługi Microsoft Entra Connect Sync. Jeśli znasz wcześniejsze technologie synchronizacji tożsamości, zawartość tego artykułu może cię również znać. Jeśli dopiero zaczynasz synchronizację, ten artykuł jest dla Ciebie. Nie jest wymagane poznanie szczegółów tego artykułu w celu pomyślnego wprowadzania dostosowań do usługi Microsoft Entra Connect Sync (nazywanej aparatem synchronizacji w tym artykule).
Architektura
Aparat synchronizacji tworzy zintegrowany widok obiektów przechowywanych w wielu połączonych źródłach danych i zarządza informacjami o tożsamości w tych źródłach danych. Informacje o tożsamości pobrane ze połączonych źródeł danych określają ten zintegrowany widok. Zestaw reguł określa sposób przetwarzania tych informacji.
Połączone źródła danych i łączniki
Aparat synchronizacji przetwarza informacje o tożsamościach z różnych repozytoriów danych, takich jak usługa Active Directory lub baza danych programu SQL Server. Każde repozytorium danych, które organizuje swoje dane w formacie przypominającym bazę danych i które zapewnia standardowe metody dostępu do danych, jest potencjalnym kandydatem źródła danych dla aparatu synchronizacji. Repozytoria danych synchronizowane przez aparat synchronizacji są nazywane połączonych źródeł danych lub połączonych katalogów (CD).
Silnik synchronizacji hermetyzuje interakcję z połączonym źródłem danych w module nazwanym Connector. Każdy typ połączonego źródła danych ma określony łącznik. Łącznik tłumaczy wymaganą operację na format zrozumiały dla połączonego źródła danych.
Łączniki tworzą wywołania interfejsu API w celu wymiany informacji o tożsamości (zarówno do odczytu, jak i zapisu) z połączonym źródłem danych. Istnieje również możliwość dodania łącznika niestandardowego przy użyciu rozszerzalnej platformy łączności. Na poniższej ilustracji pokazano, jak łącznik łączy połączone źródło danych z aparatem synchronizacji.
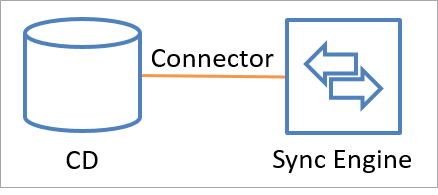
Dane mogą przepływać w obu kierunkach, ale nie mogą przepływać jednocześnie w obu kierunkach. Łącznik można skonfigurować, aby umożliwić przepływ danych z połączonego źródła danych do silnika synchronizacji lub z silnika synchronizacji do połączonego źródła danych. Jednak tylko jedna z tych operacji może wystąpić w dowolnym momencie dla jednego obiektu i atrybutu. Kierunek może być inny dla różnych obiektów i dla różnych atrybutów.
Aby skonfigurować łącznik, należy określić typy obiektów, które chcesz zsynchronizować. Określanie typów obiektów definiuje zakres obiektów, które są uwzględnione w procesie synchronizacji. Następnym krokiem jest wybranie atrybutów do synchronizacji, czyli listy dołączania atrybutów. Te ustawienia można zmienić w dowolnym momencie w odpowiedzi na zmiany reguł biznesowych. Korzystając z kreatora instalacji programu Microsoft Entra Connect, te ustawienia są konfigurowane dla Ciebie.
Aby wyeksportować obiekty do połączonego źródła danych, lista dołączania atrybutów musi zawierać co najmniej minimalne atrybuty wymagane do utworzenia określonego typu obiektu w połączonym źródle danych. Na przykład atrybut sAMAccountName musi znajdować się na liście dołączania atrybutów, aby wyeksportować obiekt użytkownika do usługi Active Directory, ponieważ wszystkie obiekty użytkownika w usłudze Active Directory muszą mieć zdefiniowany atrybut sAMAccountName. Kreator instalacji ponownie wykonuje tę konfigurację dla Ciebie.
Jeśli połączone źródło danych używa składników strukturalnych, takich jak partycje lub kontenery do organizowania obiektów, możesz ograniczyć obszary w połączonym źródle danych, które są używane dla danego rozwiązania.
Wewnętrzna struktura przestrzeni nazw aparatu synchronizacji
Cała przestrzeń nazw aparatu synchronizacji składa się z dwóch przestrzeni nazw, które przechowują informacje o tożsamości. Dwie przestrzenie nazw to:
- Przestrzeń łącznika (CS)
- Metaverse (MV)
Obszar łącznika to obszar przejściowy zawierający reprezentacje wyznaczonych obiektów ze połączonego źródła danych oraz atrybuty określone na liście dołączania atrybutów. Silnik synchronizacji używa przestrzeni łącznika, aby określić, co zmieniło się w połączonym źródle danych i zapisać zmiany przychodzące. Mechanizm synchronizacji używa również przestrzeni łącznika do przygotowania zmian wychodzących na potrzeby eksportu do powiązanego źródła danych. Aparat synchronizacji zachowuje odrębną przestrzeń łącznika jako obszar przejściowy dla każdego łącznika.
Korzystając z obszaru przejściowego, aparat synchronizacji pozostaje niezależny od połączonych źródeł danych i nie jest zależny od ich obecności i dostępności. W związku z tym można przetwarzać informacje o tożsamości w dowolnym momencie przy użyciu danych w obszarze przejściowym. Aparat synchronizacji może zażądać tylko zmian wprowadzonych w połączonym źródle danych od zakończenia ostatniej sesji komunikacji lub wypchnąć tylko zmiany informacji o tożsamości, których połączone źródło danych nie odebrało, co zmniejsza ruch sieciowy między aparatem synchronizacji a połączonym źródłem danych.
Ponadto mechanizm synchronizacji przechowuje informacje o stanie wszystkich obiektów, które etapuje w obszarze łącznika. Po odebraniu nowych danych aparat synchronizacji zawsze ocenia, czy dane zostały już zsynchronizowane.
metaverse to obszar magazynu zawierający zagregowane informacje o tożsamości z wielu połączonych źródeł danych, zapewniając jeden globalny, zintegrowany widok wszystkich połączonych obiektów. Obiekty metaverse są tworzone na podstawie informacji o tożsamości pobieranej ze połączonych źródeł danych i zestawu reguł, które umożliwiają dostosowanie procesu synchronizacji.
Na poniższej ilustracji przedstawiono przestrzeń nazw obszaru łącznika i przestrzeń nazw metaverse w silniku synchronizacji.
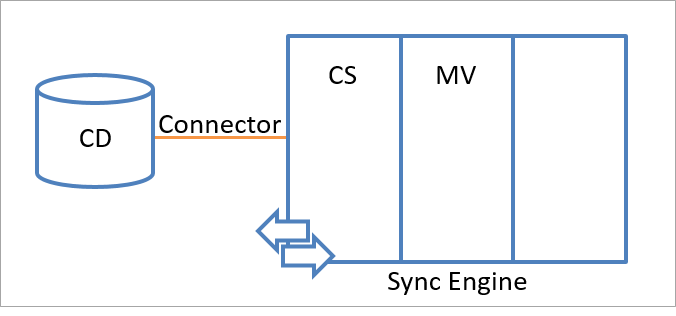
Obiekty tożsamości silnika synchronizacji
Obiekty w silniku synchronizacji reprezentują obiekty w połączonym źródle danych lub zintegrowany widok, jaki silnik synchronizacji ma na te obiekty. Każdy obiekt silnika synchronizacji musi mieć unikatowy identyfikator globalny (GUID). Identyfikatory GUID zapewniają integralność danych i wyrażają relacje między obiektami.
Obiekty obszaru łącznika
Gdy aparat synchronizacji komunikuje się z połączonym źródłem danych, odczytuje informacje o tożsamości w połączonym źródle danych i używa tych informacji do utworzenia reprezentacji obiektu tożsamości w przestrzeni łącznika. Nie można tworzyć ani usuwać tych obiektów indywidualnie. Można jednak ręcznie usunąć wszystkie obiekty w przestrzeni łącznika.
Wszystkie obiekty w przestrzeni łącznika mają dwa atrybuty:
- Unikatowy identyfikator globalny (GUID)
- Nazwa wyróżniająca (znana również jako DN)
Jeśli połączone źródło danych przypisuje unikatowy atrybut do obiektu, obiekty w przestrzeni łącznika mogą również mieć atrybut kotwicy. Atrybut kotwicy jednoznacznie identyfikuje obiekt w połączonym źródle danych. Aparat synchronizacji używa kotwicy, aby zlokalizować odpowiednią reprezentację tego obiektu w połączonym źródle danych. Aparat synchronizacji zakłada, że kotwica obiektu nigdy nie zmienia się w okresie istnienia obiektu.
Wiele łączników używa znanego unikatowego identyfikatora do automatycznego generowania kotwicy dla każdego obiektu podczas importowania. Na przykład łącznik usługi Active Directory używa atrybutu objectGUID dla kotwicy. W przypadku połączonych źródeł danych, które nie zapewniają jasno zdefiniowanego unikatowego identyfikatora, można określić generowanie kotwicy w ramach konfiguracji łącznika.
W takim przypadku kotwica jest tworzona na podstawie co najmniej jednego unikatowego atrybutu typu obiektu, który nie zmienia się i jednoznacznie identyfikuje obiekt w przestrzeni łącznika (na przykład numer pracownika lub identyfikator użytkownika).
Obiekt przestrzeni łącznika może być jednym z następujących elementów:
- Obiekt przejściowy
- Symbol zastępczy
Obiekty przygotowawcze
Obiekt przejściowy reprezentuje wystąpienie wyznaczonych typów obiektów z połączonego źródła danych. Oprócz identyfikatora GUID i nazwy wyróżniającej się, obiekt przejściowy zawsze ma wartość wskazującą typ obiektu.
Obiekty przejściowe, które są importowane, zawsze mają wartość dla atrybutu bazowego. Obiekty przejściowe, które są nowo udostępniane przez silnik synchronizacji i są w trakcie tworzenia w połączonym źródle danych, nie mają wartości dla atrybutu kotwicznego.
Obiekty przejściowe zawierają również bieżące wartości atrybutów biznesowych oraz informacje operacyjne, które są niezbędne aparatowi synchronizacji do przeprowadzenia procesu synchronizacji. Informacje operacyjne obejmują flagi wskazujące typ aktualizacji przygotowanych na obiekcie przygotowawczym. Jeśli obiekt przejściowy otrzymał nowe informacje o tożsamości z połączonego źródła danych, które nie zostały jeszcze przetworzone, obiekt jest oznaczony jako do zaimportowania. Jeśli obiekt przejściowy zawiera nowe informacje o tożsamości, które nie zostały jeszcze wyeksportowane do połączonego źródła danych, jest oflagowany jako w trakcie oczekiwania na eksport.
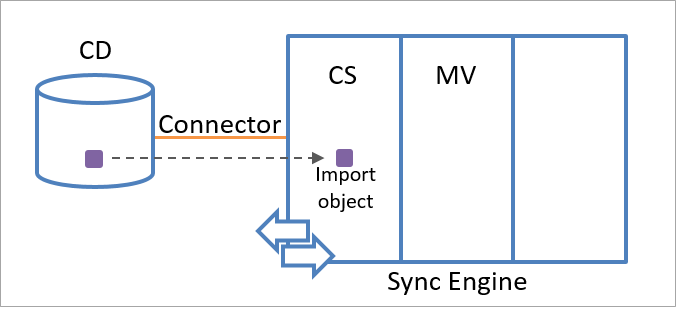
Obiekt przejściowy może być obiektem importu lub obiektem eksportu. Aparat synchronizacji tworzy obiekt importu przy użyciu informacji o obiekcie odebranych z połączonego źródła danych. Gdy aparat synchronizacji odbiera informacje o istnieniu nowego obiektu zgodnego z jednym z typów obiektów wybranych w łączniku, tworzy obiekt importu w przestrzeni łącznika jako reprezentację obiektu w połączonym źródle danych.
Poniższa ilustracja przedstawia obiekt importu reprezentujący obiekt w połączonym źródle danych.
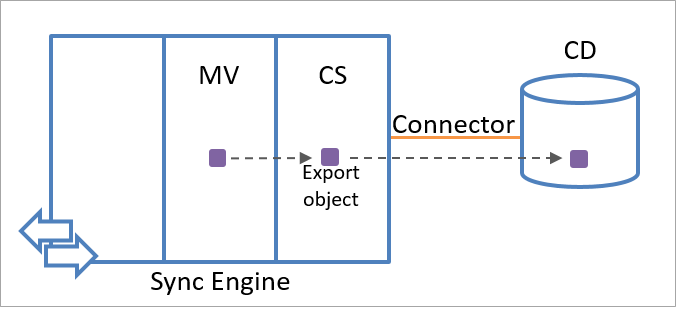
Silnik synchronizacji tworzy obiekt eksportu, używając informacji o obiekcie w metaverse. Obiekty eksportu są eksportowane do połączonego źródła danych podczas następnej sesji komunikacji. Z perspektywy aparatu synchronizacji obiekty eksportu nie istnieją jeszcze w połączonym źródle danych. W związku z tym atrybut kotwicy dla obiektu eksportu jest niedostępny. Po odebraniu obiektu z silnika synchronizacji, połączone źródło danych tworzy unikatową wartość dla atrybutu kotwicy obiektu.
Poniższa ilustracja przedstawia sposób tworzenia obiektu eksportu przy użyciu informacji o tożsamości w metaverse.
Aparat synchronizacji potwierdza eksport obiektu przez ponowne importowanie obiektu z połączonego źródła danych. Obiekty eksportowe stają się obiektami importu, kiedy aparat synchronizacji odbiera je podczas kolejnego importu z tego źródła danych.
Symbole zastępcze
Aparat synchronizacji używa płaskiej przestrzeni nazw do przechowywania obiektów. Jednak niektóre połączone źródła danych, takie jak Usługa Active Directory, używają hierarchicznej przestrzeni nazw. Aby przekształcić informacje z hierarchicznej przestrzeni nazw w płaską przestrzeń nazw, aparat synchronizacji używa symboli zastępczych do zachowania hierarchii.
Każdy symbol zastępczy reprezentuje składnik hierarchicznej nazwy obiektu, taki jak jednostka organizacyjna, który nie jest importowany do silnika synchronizacji, ale jest wymagany do konstruowania nazwy hierarchicznej. Wypełniają one luki utworzone przez odwołania w połączonym źródle danych do obiektów, które nie są obiektami przejściowymi w przestrzeni łącznika.
Silnik synchronizacji używa także symboli zastępczych do przechowywania powiązanych obiektów, które nie zostały jeszcze zaimportowane. Jeśli na przykład synchronizacja jest skonfigurowana tak, aby zawierała atrybut menedżera dla obiektu Abbie Spencer, a odebrana wartość jest obiektem, który nie został jeszcze zaimportowany, taki jak CN=Lee Sperry,CN=Users,DC=fabrikam,DC=com, informacje o menedżerze są przechowywane jako symbole zastępcze w przestrzeni łącznika. Jeśli obiekt menedżera zostanie później zaimportowany, obiekt zastępczy zostanie zastąpiony przez obiekt przejściowy reprezentujący menedżera.
Obiekty Metaverse
Obiekt metaverse zawiera zagregowany widok, który silnik synchronizacji ma na obiekty przejściowe w przestrzeni połączeń. Aparat synchronizacji tworzy obiekty metaverse przy użyciu informacji w importowanych obiektach. Kilka obiektów przestrzeni łącznika może być połączonych z pojedynczym obiektem metaverse, ale obiekt przestrzeni łącznika nie może być połączony z więcej niż jednym obiektem metaverse.
Nie można ręcznie tworzyć ani usuwać obiektów metaverse. Silnik synchronizacji automatycznie usuwa obiekty metaverse, które nie mają łącza do żadnego obiektu w przestrzeni łącznika.
Aby zamapować obiekty w połączonym źródle danych na odpowiedni typ obiektu w metaverse, aparat synchronizacji udostępnia rozszerzalny schemat ze wstępnie zdefiniowanym zestawem typów obiektów i skojarzonymi atrybutami. Można tworzyć nowe typy obiektów i atrybuty dla obiektów metaverse. Atrybuty mogą być jednowartościowe lub wielowartościowe, a typy atrybutów mogą być ciągami, odwołaniami, liczbami i wartościami logicznymi.
Relacje między obiektami przejściowymi i obiektami metaverse
W przestrzeni nazw silnika synchronizacji przepływ danych jest umożliwiany przez związek między obiektami przejściowymi a obiektami w metaverse. Obiekt przejściowy, który jest połączony z obiektem metaverse, jest nazywany połączonym obiektem (lub obiektem łącznika ). Obiekt przejściowy, który nie jest połączony z obiektem metaverse, jest nazywany rozłączonym obiektem (lub obiektem rozłączania ). Terminy przyłączone i rozłączone są preferowane, aby nie mylić z łącznikami odpowiedzialnymi za importowanie i eksportowanie danych z połączonego katalogu.
Symbole zastępcze nigdy nie są połączone z obiektem metaverse
Sprzężony obiekt składa się z obiektu przejściowego i jego połączonej relacji z pojedynczym obiektem metaverse. Sprzężone obiekty służą do synchronizowania wartości atrybutów między obiektem w przestrzeni łącznika a obiektem w metawersum.
Gdy obiekt przejściowy staje się obiektem sprzężonym podczas synchronizacji, atrybuty mogą przepływać między obiektem przejściowym a obiektem metaverse. Przepływ atrybutów jest dwukierunkowy i jest konfigurowany przy użyciu reguł atrybutów importu i reguł atrybutów eksportu.
Pojedynczy obiekt przestrzeni połączeniowej może być połączony tylko z jednym obiektem metaverse. Jednak każdy obiekt metaverse może być połączony z wieloma obiektami przestrzeni połączeń w tej samej lub w różnych przestrzeniach połączeń, jak pokazano na poniższej ilustracji.
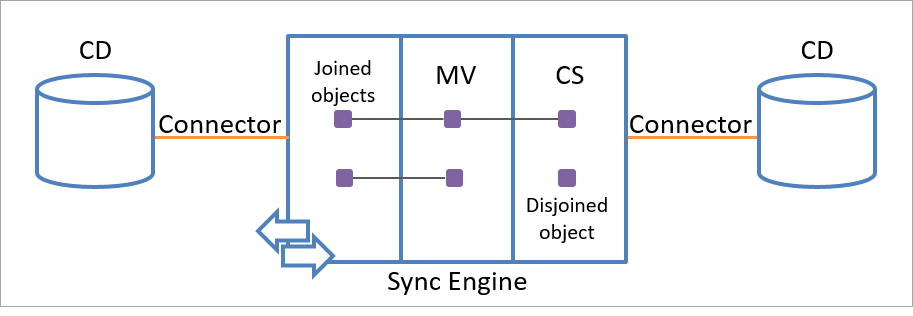
Tylko określone reguły mogą usuwać trwałą połączoną relację między obiektem przejściowym a obiektem metaverse.
Odłączony obiekt jest obiektem przejściowym, który nie jest połączony z żadnym obiektem metaverse. Wartości atrybutów rozłącznego obiektu nie są przetwarzane dalej w metaverse. Wartości atrybutów odpowiedniego obiektu w połączonym źródle danych nie są aktualizowane przez aparat synchronizacji.
Korzystając z rozdzielonych obiektów, można przechowywać informacje o tożsamości w silniku synchronizacji i przetwarzać je później. Utrzymywanie obiektu przejściowego jako rozłącznego obiektu w przestrzeni łącznika ma wiele zalet. Ponieważ system wystawił wymagane informacje o tym obiekcie, nie jest konieczne ponowne utworzenie reprezentacji tego obiektu podczas następnego importu z połączonego źródła danych. Dzięki temu aparat synchronizacji zawsze ma pełną migawkę połączonego źródła danych, nawet jeśli nie ma bieżącego połączenia z połączonym źródłem danych. Odłączone obiekty można przekonwertować na obiekty sprzężone i na odwrót, w zależności od podanych reguł.
Obiekt importu jest tworzony jako rozłączny obiekt. Obiekt eksportu musi być obiektem sprzężonym. Logika systemowa wymusza tę regułę i usuwa każdy obiekt eksportu, który nie jest obiektem sprzężonym.
Proces zarządzania tożsamością silnika synchronizacji
Proces zarządzania tożsamościami steruje sposobem aktualizowania informacji o tożsamości między różnymi połączonymi źródłami danych. Zarządzanie tożsamościami odbywa się w trzech procesach:
- Import
- Synchronizacja
- Eksport
Podczas procesu importowania aparat synchronizacji ocenia informacje o tożsamości przychodzącej z połączonego źródła danych. Po wykryciu zmian tworzy nowe obiekty przejściowe lub aktualizuje istniejące obiekty przejściowe w przestrzeni łącznika na potrzeby synchronizacji.
Podczas procesu synchronizacji silnik synchronizacji aktualizuje metaverse, aby odzwierciedlić zmiany w przestrzeni łącznika. Aktualizuje również przestrzeń łącznika, aby odzwierciedlić zmiany w metawersie.
Podczas procesu eksportowania aparat synchronizacji wypycha zmiany, które są wprowadzane w obiektach przejściowych i które są oflagowane jako oczekujące na eksport.
Na poniższej ilustracji pokazano, gdzie każdy z procesów występuje, gdy informacje o tożsamości przepływa z jednego połączonego źródła danych do innego.
pl-PL: 
Proces importowania
Podczas procesu importowania aparat synchronizacji ocenia aktualizacje informacji o tożsamości. Aparat synchronizacji porównuje informacje o tożsamości odebrane z połączonego źródła danych z informacjami o tożsamości o obiekcie buforowanym. Określa, czy obiekt przejściowy wymaga aktualizacji. Jeśli konieczne jest zaktualizowanie obiektu przejściowego przy użyciu nowych danych, obiekt przejściowy jest oflagowany jako oczekujący import.
Dzięki przemieszczaniu obiektów w przestrzeni łącznika przed synchronizacją aparat synchronizacji może przetwarzać tylko zmienione informacje o tożsamości. Ten proces zapewnia następujące korzyści:
- Wydajna synchronizacja. Ilość danych przetwarzanych podczas synchronizacji jest zminimalizowana.
- wydajna ponowna synchronizacja. Możesz zmienić sposób przetwarzania informacji o tożsamości przez aparat synchronizacji bez ponownego łączenia aparatu synchronizacji ze źródłem danych.
- Możliwość podglądu synchronizacji. Możesz wyświetlić podgląd synchronizacji, aby sprawdzić, czy założenia dotyczące procesu zarządzania tożsamościami są poprawne.
Dla każdego obiektu określonego w łączniku, mechanizm synchronizacji najpierw próbuje zlokalizować reprezentację obiektu w przestrzeni łącznika. Aparat synchronizacji sprawdza wszystkie obiekty przejściowe w przestrzeni łącznika i próbuje znaleźć odpowiedni obiekt przejściowy, który ma pasujący atrybut kotwicy. Jeśli żaden istniejący obiekt przejściowy nie ma pasującego atrybutu kotwicy, silnik synchronizacji próbuje znaleźć odpowiadający obiekt przejściowy o tej samej nazwie wyróżniającej.
Gdy silnik synchronizacji znajdzie obiekt przechowywania wstępnego, który jest zgodny z nazwą wyróżniającą, ale nie z punktem zaczepienia, występuje następujące specjalne zachowanie:
- Jeśli obiekt znajdujący się w przestrzeni łącznika nie ma kotwicy, aparat synchronizacji usuwa ten obiekt z przestrzeni łącznika i oznacza obiekt metaverse, z którym jest połączony, jako ponowna aprowizacja przy następnym uruchomieniu synchronizacji. Następnie tworzy nowy obiekt importu.
- Jeśli obiekt znajdujący się w przestrzeni łącznika ma kotwicę, aparat synchronizacji zakłada, że nazwa tego obiektu zostanie zmieniona lub usunięta w połączonym katalogu. Przypisuje tymczasową, nową nazwę wyróżniającą obiektu przestrzeni łącznika, aby umożliwić przygotowanie obiektu przychodzącego. Stary obiekt staje się następnie przejściowy, czekając, aż łącznik zaimportuje zmianę nazwy lub usunięcie, aby rozwiązać ten problem.
Obiekty przejściowe nie zawsze są problemem i mogą być widoczne nawet w zdrowym środowisku. Dla interfejsu API punktu końcowego Microsoft Entra Connect Sync w wersji 2obiekty przejściowe powinny rozwiązywać się automatycznie w kolejnych cyklach synchronizacji różnicowej. Typowy przykład, w którym można znaleźć generowane przejściowe obiekty, występuje na serwerach Microsoft Entra Connect zainstalowanych w trybie przejściowym. Dzieje się tak, gdy administrator trwale usuwa obiekt bezpośrednio w usłudze Microsoft Entra ID przy użyciu programu PowerShell, a później ponownie synchronizuje obiekt.
Jeśli aparat synchronizacji lokalizuje obiekt przejściowy, który odpowiada obiektowi określonemu w łączniku, określa, jakiego rodzaju zmiany mają być stosowane. Na przykład aparat synchronizacji może zmienić nazwę lub usunąć obiekt w połączonym źródle danych lub zaktualizować tylko wartości atrybutów obiektu.
Obiekty przejściowe ze zaktualizowanymi danymi są oznaczone jako oczekujące na import. Dostępne są różne typy oczekujących importów. W zależności od wyniku procesu importowania obiekt przejściowy w przestrzeni łącznika ma jeden z następujących oczekujących typów importu:
- None. Nie są dostępne żadne zmiany atrybutów obiektu przejściowego. Aparat synchronizacji nie flaguje tego typu jako oczekującego importu.
- Dodaj. Obiekt przejściowy to nowy obiekt importu w przestrzeni łącznika. Moduł synchronizacji flaguje ten typ jako oczekujący importu do dodatkowego przetwarzania w metaverse.
- Aktualizacja. Silnik synchronizacji znajduje odpowiedni obiekt przejściowy w przestrzeni łącznika i oznacza ten typ jako 'Oczekujący import', aby aktualizacje atrybutów mogły być przetwarzane w metaverse. Aktualizacje obejmują zmianę nazwy obiektu.
- Usuń. Mechanizm synchronizacji znajduje odpowiedni obiekt przejściowy w przestrzeni łącznika i oznacza ten typ jako oczekujący na import, co umożliwia usunięcie powiązanego obiektu.
- Usuń/Dodaj. Silnik synchronizacji znajduje odpowiedni obiekt przejściowy w przestrzeni łącznika, ale typy obiektów nie są zgodne. W takim przypadku przygotowywana jest modyfikacja polegająca na usuwaniu i dodawaniu. Modyfikacja usuwania i dodawania wskazuje aparatowi synchronizacji, że musi wystąpić pełna ponowna synchronizacja tego obiektu, ponieważ różne zestawy reguł mają zastosowanie do tego obiektu, gdy typ obiektu ulegnie zmianie.
Ustawiając stan oczekującego importu obiektu przejściowego, można znacznie zmniejszyć ilość danych przetwarzanych podczas synchronizacji. Dzięki temu system może przetwarzać tylko te obiekty, które mają zaktualizowane dane.
Proces synchronizacji
Synchronizacja składa się z dwóch powiązanych procesów:
- Synchronizacja ruchu przychodzącego, gdy zawartość metaverse jest aktualizowana przy użyciu danych w przestrzeni łącznika.
- Synchronizacja wychodząca, kiedy zawartość obszaru łącznika jest aktualizowana za pomocą danych z metaverse.
Korzystając z informacji przygotowanych w przestrzeni łącznika, proces synchronizacji danych przychodzących tworzy zintegrowany widok danych w metaverse przechowywanych w połączonych źródłach danych. Wszystkie obiekty przejściowe lub tylko te z informacjami oczekującymi na import są agregowane w zależności od tego, jak są skonfigurowane reguły.
Proces synchronizacji ruchu wychodzącego aktualizuje obiekty eksportu, gdy zmieniają się obiekty metaverse.
Synchronizacja danych przychodzących tworzy zintegrowany widok w metawersum informacji o tożsamości pochodzących z połączonych źródeł danych. Aparat synchronizacji może przetwarzać informacje o tożsamości w dowolnym momencie przy użyciu najnowszych informacji o tożsamości, które mają z połączonego źródła danych.
synchronizacja przychodząca
Synchronizacja ruchu przychodzącego obejmuje następujące procesy:
- Definicja (nazywana również Rzutowanie, jeśli ważne jest odróżnienie tego procesu od przygotowania synchronizacji ruchu wychodzącego). Silnik synchronizacji tworzy nowy obiekt metaversum na podstawie obiektu przejściowego i powiązuje je. Przydzielenie jest operacją na poziomie obiektu.
- Dołącz. Silnik synchronizacji łączy obiekt przejściowy z istniejącym obiektem metaverse. Łączenie jest operacją na poziomie obiektu.
- przepływ importowania atrybutów. Silnik synchronizacji aktualizuje wartości atrybutów, nazywane przepływem atrybutów, obiektu w metaverse. Przepływ atrybutów importu jest operacją na poziomie atrybutu, która wymaga powiązania obiektu przejściowego z obiektem metaverse.
Przydział to jedyny proces, który tworzy obiekty w metaverse. Postanowienie ma wpływ tylko na importowane obiekty, które są niepołączone. Podczas przetwarzania silnik synchronizacji tworzy obiekt metaverse, który odpowiada typowi obiektu importu i ustanawia łącze między obiema obiektami, tworząc w ten sposób połączony obiekt.
Proces łączenia ustanawia również połączenie między obiektami importu a obiektem metaverse. Proces sprzężenia wymaga, aby obiekt importu był połączony z istniejącym obiektem metaverse. Jednak proces wdrażania tworzy nowy obiekt metaverse.
Aparat synchronizacji próbuje dołączyć obiekt importu do obiektu metaverse przy użyciu kryteriów określonych w konfiguracji reguły synchronizacji.
Podczas procesów aprowizacji i łączenia silnik synchronizacji łączy rozłączny obiekt z obiektem metaverse, w wyniku czego są połączone. Po zakończeniu tych operacji na poziomie obiektu aparat synchronizacji może zaktualizować wartości atrybutów skojarzonego obiektu metaverse. Ten proces jest nazywany przepływem atrybutów importu.
Przepływ atrybutów importu występuje na wszystkich obiektach importu, które przenoszą nowe dane i są połączone z obiektem metaverse.
synchronizacji ruchu wychodzącego
Synchronizacja ruchu wychodzącego aktualizuje obiekty eksportu, gdy obiekt metaverse zmienia się, ale nie jest usuwany. Celem synchronizacji wychodzącej jest ocena, czy zmiany w obiektach metaverse wymagają aktualizacji obiektów przejściowych w przestrzeniach połączeń. W niektórych przypadkach zmiany mogą wymagać zaktualizowania obiektów przejściowych we wszystkich miejscach łącznika. Obiekty przejściowe, które są zmieniane, są oflagowane jako oczekujące na eksport, co czyni je obiektami eksportu. Te obiekty eksportu są później wypychane do połączonego źródła danych podczas procesu eksportowania.
Synchronizacja ruchu wychodzącego ma trzy procesy:
- Udostępnianie
- wycofanie aprowizacji
- Eksportuj przepływ atrybutów
Aprowizowanie i anulowanie aprowizacji to operacje na poziomie obiektu. Anulowanie prowizjonowania zależy od prowizjonowania, ponieważ tylko prowizjonowanie może je zainicjować. Anulowanie aprowizacji jest wyzwalane, gdy aprowizacja usuwa łącze między obiektem metaverse a obiektem eksportu.
Aprowizowanie jest zawsze wyzwalane, gdy zmiany są stosowane do obiektów w metaverse. Po wprowadzeniu zmian w obiektach metaverse silnik synchronizacji może wykonać jedną z następujących czynności w ramach procesu przygotowania:
- Utwórz sprzężone obiekty, w których obiekt metaverse jest połączony z nowo utworzonym obiektem eksportu.
- Zmień nazwę sprzężonego obiektu.
- Rozłączanie łączy między obiektem metaverse i obiektami przejściowymi, tworząc rozłączny obiekt.
Jeśli aprowizacja wymaga aparatu synchronizacji w celu utworzenia nowego obiektu łącznika, obiekt przejściowy połączony z obiektem metaverse jest zawsze eksportem. Jest to spowodowane tym, że obiekt nie istnieje jeszcze w połączonym źródle danych.
Jeśli aprowizacja wymaga, aby mechanizm synchronizacji rozłączył przyłączony obiekt, tworzenie rozłączonego obiektu spowoduje wyzwolenie dezaktywacji. Proces anulowania aprowizacji usuwa obiekt.
Podczas deprowizjonowania usunięcie obiektu eksportu nie usuwa go fizycznie. Obiekt jest oznaczony jako usunięty, co oznacza, że operacja usuwania jest zaplanowana na obiekcie.
Przepływ atrybutów eksportu występuje również podczas procesu synchronizacji ruchu wychodzącego, podobnie jak w przypadku przepływu atrybutów importu podczas synchronizacji ruchu przychodzącego. Przepływ atrybutów eksportu odbywa się tylko między metaverse a obiektami eksportu, które są połączone.
Proces eksportowania
Podczas procesu eksportowania aparat synchronizacji sprawdza wszystkie obiekty eksportu oznaczone jako oczekujące eksporty w przestrzeni łącznika, a następnie wysyła aktualizacje do połączonego źródła danych.
Aparat synchronizacji może określić powodzenie eksportu, ale nie może wystarczająco określić, czy proces zarządzania tożsamościami został ukończony. Inne procesy zawsze mogą zmieniać obiekty w połączonym źródle danych. Ponieważ aparat synchronizacji nie ma trwałego połączenia z połączonym źródłem danych, nie wystarczy wyciągać wnioski na temat właściwości obiektu w połączonym źródle danych jedynie na podstawie powiadomienia o pomyślnym wyeksportowaniu.
Na przykład proces w połączonym źródle danych może zmienić atrybuty obiektu z powrotem na ich oryginalne wartości (to znaczy, że połączone źródło danych może nadpisać wartości natychmiast po tym, jak dane zostaną przekazane przez silnik synchronizujący i pomyślnie zastosowane w połączonym źródle danych).
Silnik synchronizacji przechowuje informacje o stanie eksportu i importu każdego obiektu przejściowego. Jeśli wartości atrybutów określonych na liście dołączania atrybutów zostały zmienione od ostatniego eksportu, magazyn stanu importu i eksportu umożliwia aparatowi synchronizacji odpowiednie reagowanie. Aparat synchronizacji używa procesu importowania, aby potwierdzić wartości atrybutów wyeksportowane do połączonego źródła danych. Porównanie zaimportowanych i wyeksportowanych informacji, jak pokazano na poniższej ilustracji, umożliwia aparatowi synchronizacji określenie, czy eksport zakończył się pomyślnie, czy też należy go powtórzyć.
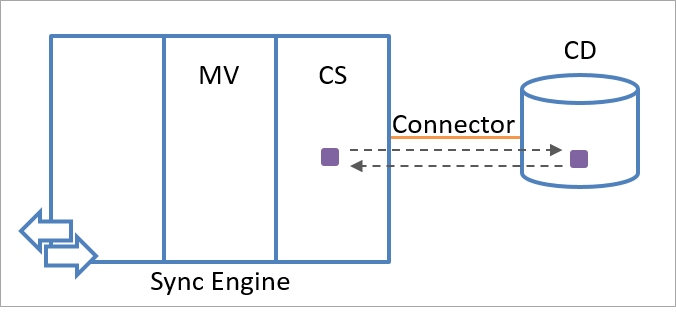
Jeśli na przykład aparat synchronizacji eksportuje atrybut C, który ma wartość 5, do połączonego źródła danych, przechowuje C=5 w pamięci stanu eksportu. Każdy dodatkowy eksport tego obiektu powoduje ponowną próbę wyeksportowania C=5 do połączonego źródła danych, ponieważ aparat synchronizacji zakłada, że ta wartość nie została trwale zastosowana do obiektu (czyli, chyba że ostatnio zaimportowano inną wartość ze połączonego źródła danych). Pamięć eksportu jest czyszczona po odebraniu C=5 podczas operacji importowania obiektu.
Następne kroki
Dowiedz się więcej o konfiguracji Microsoft Entra Connect Sync.
Dowiedz się więcej o Integrowanie tożsamości lokalnych z identyfikatorem Entra firmy Microsoft.