Monitorowanie kondycji logowania aplikacji w celu uzyskania odporności
Aby zwiększyć odporność infrastruktury, skonfiguruj monitorowanie kondycji logowania aplikacji dla krytycznych aplikacji. Gdy wystąpi zdarzenie wpływające na zdarzenie, możesz otrzymać alert. W tym artykule opisano konfigurowanie skoroszytu kondycji logowania aplikacji w celu monitorowania zakłóceń w logowaniu użytkowników.
Alerty można skonfigurować na podstawie skoroszytu kondycji logowania aplikacji. Ten skoroszyt umożliwia administratorom monitorowanie żądań uwierzytelniania dla aplikacji w ich dzierżawach. Zapewnia następujące kluczowe możliwości:
- Skonfiguruj skoroszyt tak, aby monitorował wszystkie lub poszczególne aplikacje z danymi niemal w czasie rzeczywistym.
- Skonfiguruj alerty pod kątem zmian wzorca uwierzytelniania, aby można było badać i reagować.
- Porównaj trendy w danym okresie. Tydzień w tygodniu jest ustawieniem domyślnym skoroszytu.
Uwaga
Zobacz wszystkie dostępne skoroszyty i wymagania wstępne dotyczące korzystania z nich w temacie How to use Azure Monitor workbooks for reports (Jak używać skoroszytów usługi Azure Monitor dla raportów).
Podczas zdarzenia mającego wpływ mogą wystąpić dwie rzeczy:
- Liczba logów dla aplikacji może nagle spaść, gdy użytkownicy nie mogą się zalogować.
- Liczba niepowodzeń logowania może wzrosnąć.
Wymagania wstępne
- Dzierżawa firmy Microsoft Entra.
- Użytkownik przypisał co najmniej rolę Administratora zabezpieczeń.
- Obszar roboczy usługi Log Analytics w subskrypcji platformy Azure do wysyłania dzienników do dzienników usługi Azure Monitor. Dowiedz się, jak utworzyć obszar roboczy usługi Log Analytics.
- Dzienniki firmy Microsoft Entra zintegrowane z dziennikami usługi Azure Monitor. Dowiedz się, jak zintegrować dzienniki logowania firmy Microsoft z usługą Azure Monitor Stream.
Konfigurowanie skoroszytu kondycji logowania aplikacji
Aby uzyskać dostęp do skoroszytów w witrynie Azure Portal, wybierz pozycję Microsoft Entra ID, wybierz pozycję Skoroszyty.
Skoroszyty są wyświetlane w obszarze Użycie, Dostęp warunkowy i Rozwiązywanie problemów. Skoroszyt kondycji logowania aplikacji zostanie wyświetlony w sekcji Kondycja. Po użyciu skoroszytu może zostać wyświetlony w sekcji Ostatnio zmodyfikowane skoroszyty .
Możesz użyć skoroszytu kondycji logowania aplikacji, aby zwizualizować, co się dzieje z logowaniem. Jak pokazano na poniższym zrzucie ekranu, skoroszyt przedstawia dwa wykresy.
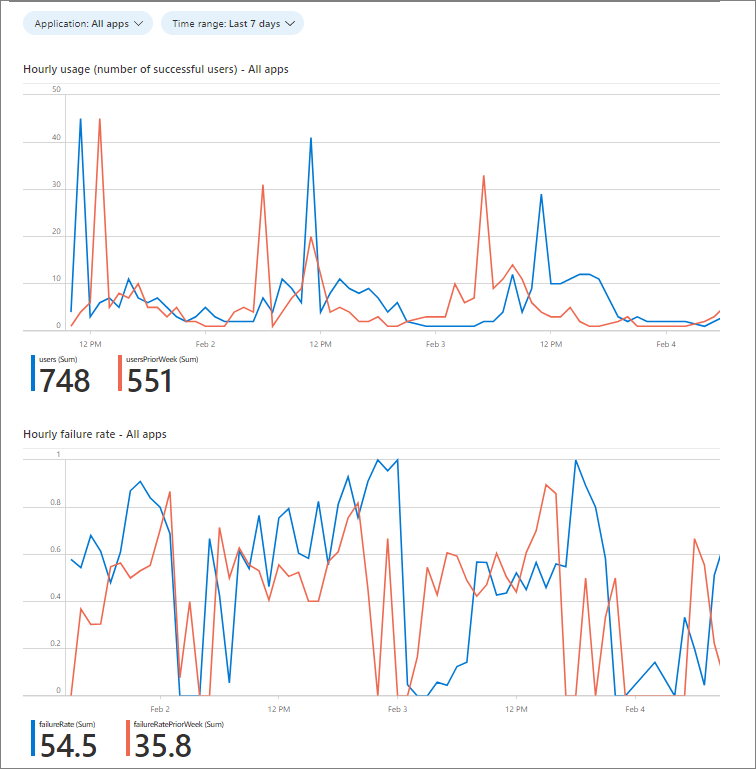
Na powyższym zrzucie ekranu znajdują się dwa wykresy:
- Użycie godzinowe (liczba pomyślnych użytkowników). Porównanie bieżącej liczby pomyślnych użytkowników z typowym okresem użycia pomaga wykryć spadek użycia, który może wymagać zbadania. Spadek pomyślnego współczynnika użycia może pomóc w wykrywaniu problemów z wydajnością i wykorzystaniem, których nie można wykryć. Jeśli na przykład użytkownicy nie mogą nawiązać połączenia z aplikacją, aby spróbować się zalogować, występuje spadek użycia, ale nie występują błędy. Zobacz przykładowe zapytanie dotyczące tych danych w następnej sekcji tego artykułu.
- Częstotliwość błędów godzinowych. Wzrost współczynnika błędów może wskazywać na problem z mechanizmami uwierzytelniania. Miary współczynnika niepowodzeń są wyświetlane tylko wtedy, gdy użytkownicy mogą podjąć próbę uwierzytelnienia. Jeśli użytkownicy nie mogą uzyskać dostępu do próby, nie ma żadnych niepowodzeń.
Konfigurowanie zapytania i alertów
Reguły alertów można tworzyć w usłudze Azure Monitor i automatycznie uruchamiać zapisane zapytania lub niestandardowe wyszukiwania dzienników w regularnych odstępach czasu. Można skonfigurować alert, który powiadamia określoną grupę, gdy użycie lub szybkość awarii przekracza określony próg.
Skorzystaj z poniższych instrukcji, aby utworzyć alerty e-mail na podstawie zapytań odzwierciedlonych na wykresach. Przykładowe skrypty wysyłają powiadomienie e-mail w następujących przypadkach:
- Pomyślne użycie spada o 90% z tej samej godziny dwa dni temu, jak pokazano w poprzednim przykładzie wykresu użycia godzinowego.
- Wskaźnik awarii zwiększa się o 90% z tej samej godziny dwa dni temu, jak pokazano w poprzednim przykładzie wykresu współczynnika błędów godzinowych.
Aby skonfigurować zapytanie bazowe i ustawić alerty, wykonaj następujące kroki, korzystając z przykładowego zapytania jako podstawy konfiguracji. Na końcu tej sekcji zostanie wyświetlony opis struktury zapytania. Dowiedz się, jak tworzyć, wyświetlać alerty dzienników i zarządzać nimi przy użyciu usługi Azure Monitor w temacie Zarządzanie alertami dzienników.
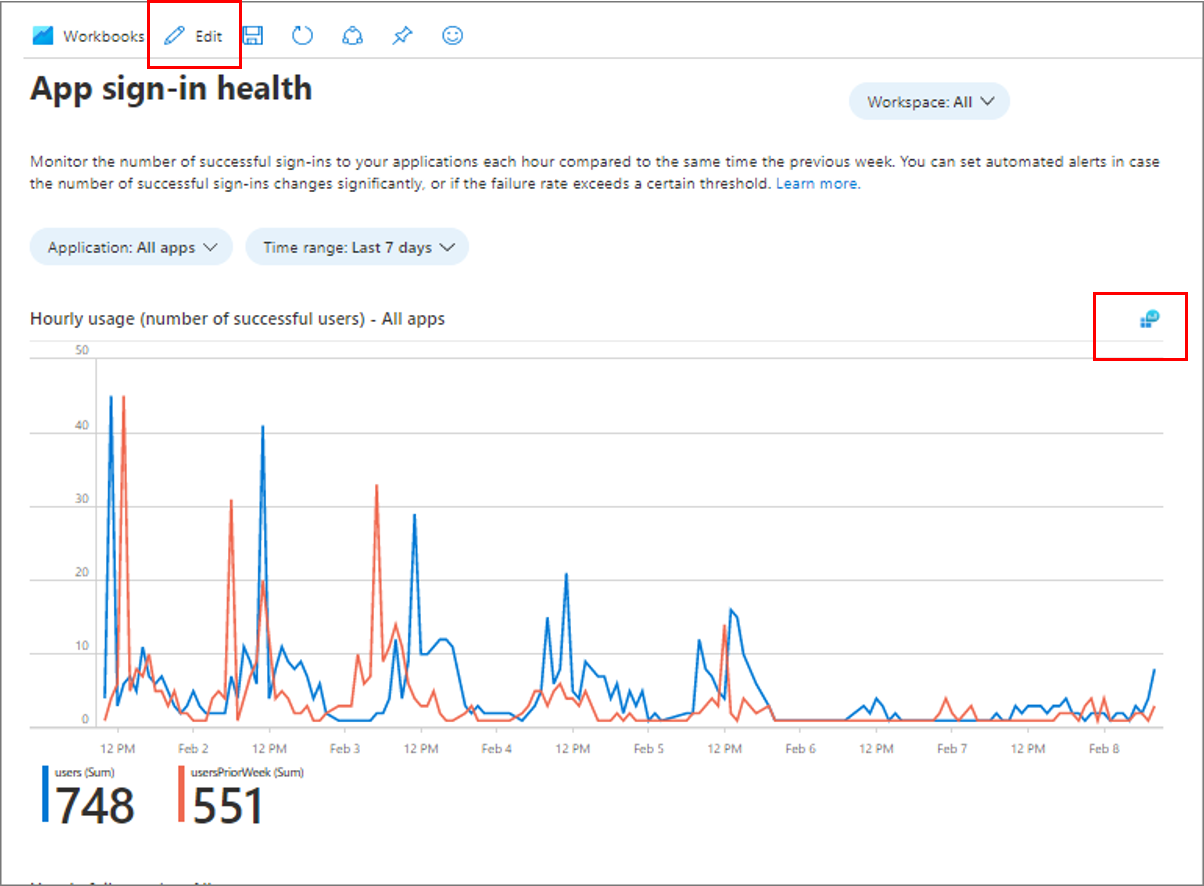
W skoroszycie wybierz pozycję Edytuj , jak pokazano na poniższym zrzucie ekranu. Wybierz ikonę zapytania w prawym górnym rogu grafu.
Wyświetl dziennik zapytań, jak pokazano na poniższym zrzucie ekranu.
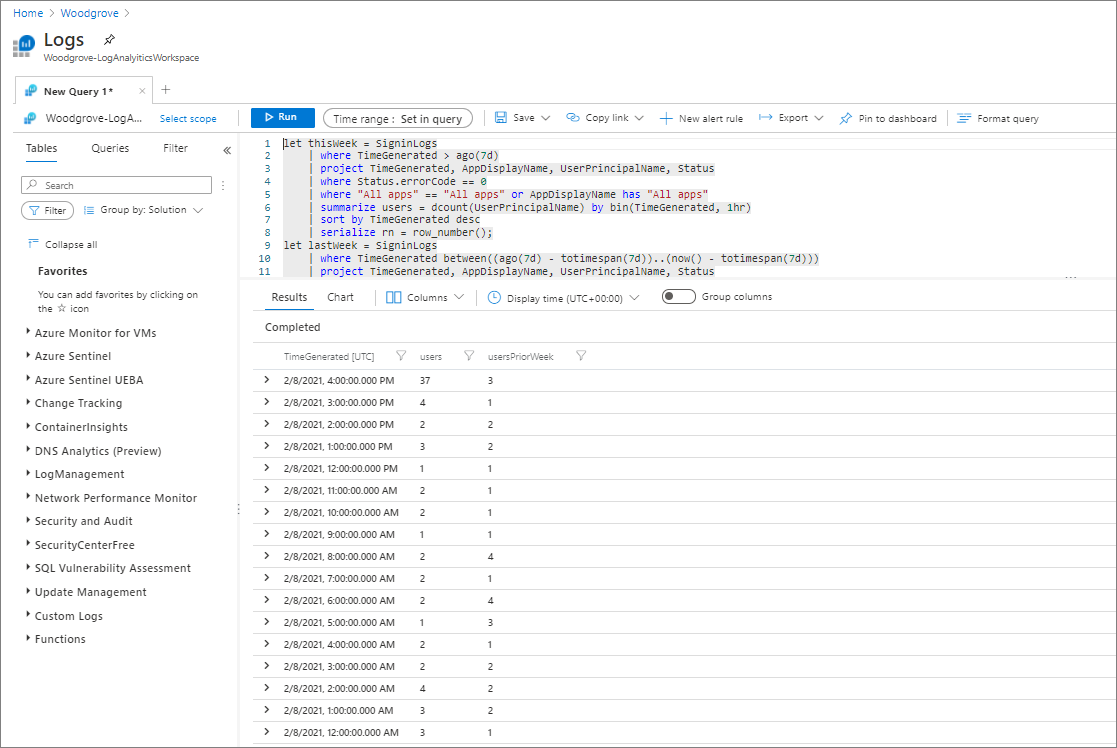
Skopiuj jeden z następujących przykładowych skryptów dla nowego zapytania Kusto.
Wklej zapytanie w oknie. Wybierz Uruchom. Poszukaj komunikatu Ukończono i wyników zapytania, jak pokazano na poniższym zrzucie ekranu.
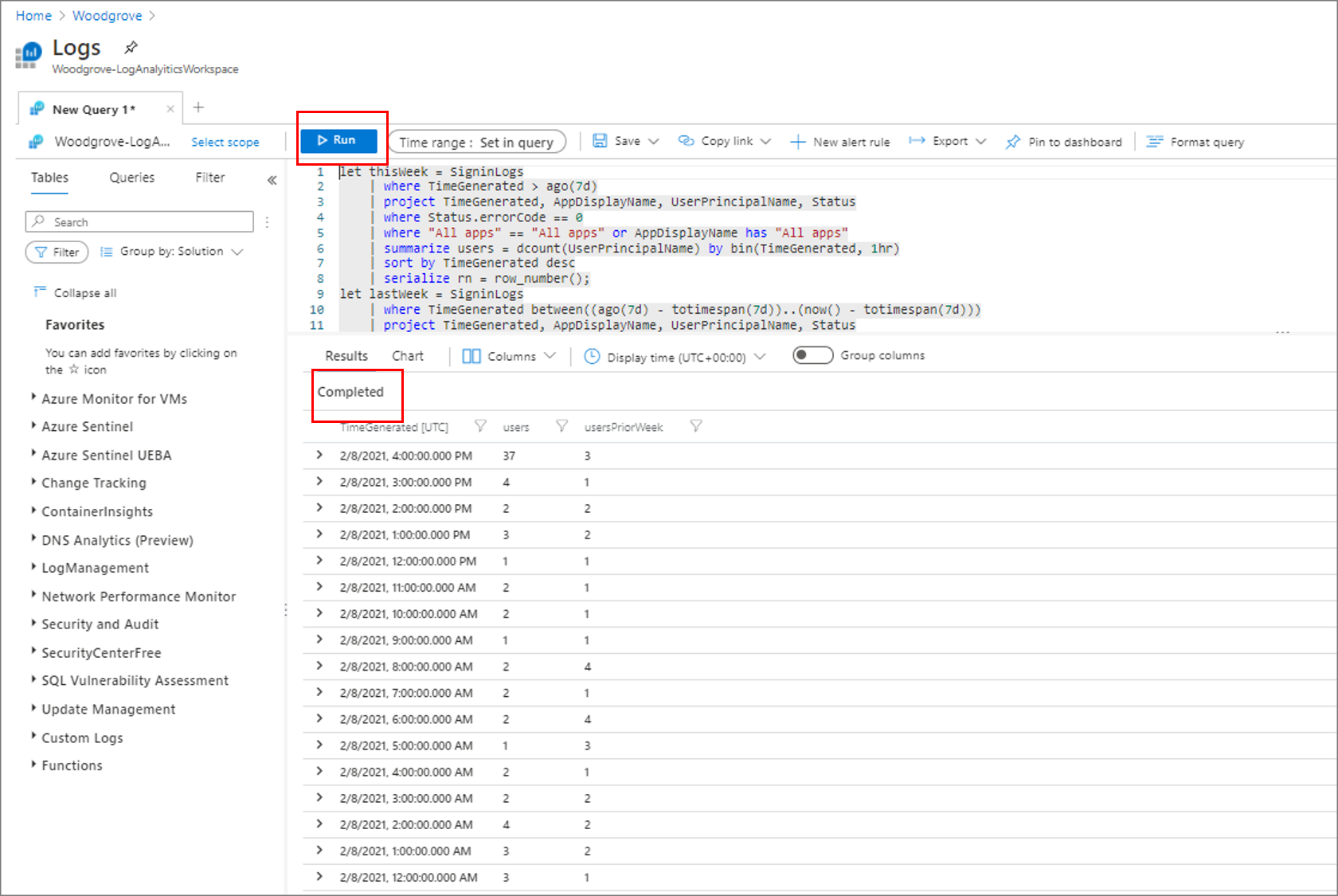
Wyróżnij zapytanie. Wybierz pozycję + Nowa reguła alertu.
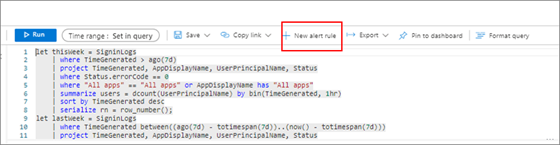
Konfigurowanie warunków alertu. Jak pokazano na poniższym przykładowym zrzucie ekranu, w sekcji Warunek w obszarze Miara wybierz pozycję Wiersze tabeli dla pozycji Miara. Wybierz pozycję Liczba dla pozycji Typ agregacji. Wybierz 2 dni w obszarze Stopień szczegółowości agregacji.
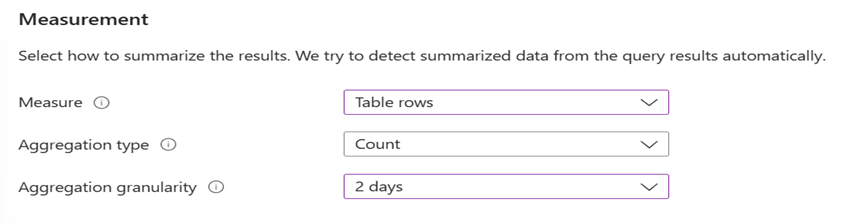
- Wiersze tabeli. Możesz użyć liczby wierszy zwracanych do pracy ze zdarzeniami, takimi jak dzienniki zdarzeń systemu Windows, dziennik syslog i wyjątki aplikacji.
- Typ agregacji. Punkty danych zastosowane z liczbą.
- Stopień szczegółowości agregacji. Ta wartość definiuje okres, który działa z częstotliwością oceny.
W obszarze Logika alertu skonfiguruj parametry, jak pokazano na przykładowym zrzucie ekranu.
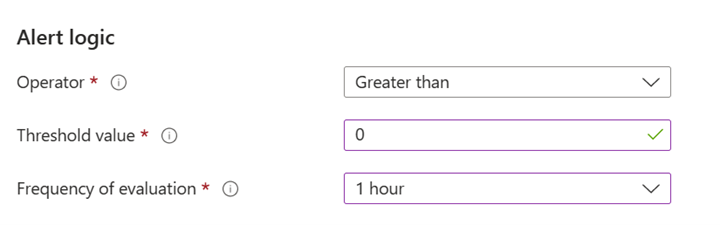
- Wartość progowa: 0. Ta wartość powoduje alerty dotyczące wszystkich wyników.
- Częstotliwość oceny: 1 godzina. Ta wartość ustawia okres oceny na raz na godzinę dla poprzedniej godziny.
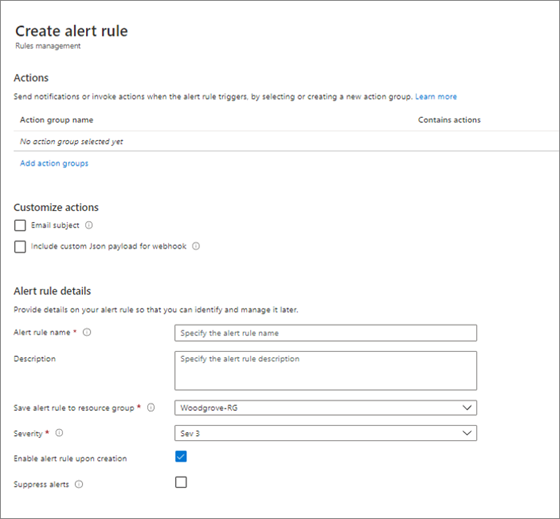
W sekcji Akcje skonfiguruj ustawienia, jak pokazano na przykładowym zrzucie ekranu.
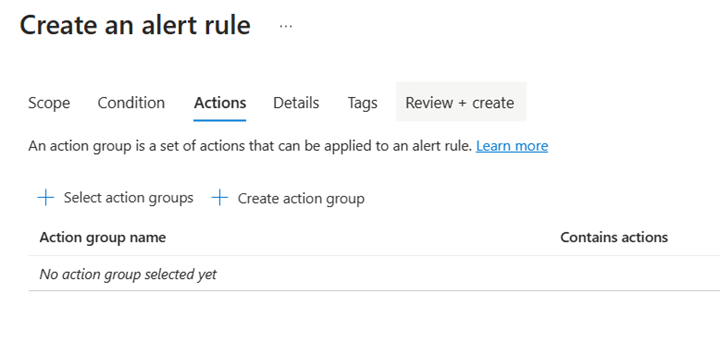
- Wybierz pozycję Wybierz grupę akcji i dodaj grupę, dla której chcesz otrzymywać powiadomienia o alertach.
- W obszarze Dostosowywanie akcji wybierz pozycję Alerty e-mail.
- Dodaj wiersz tematu.
W sekcji Szczegóły skonfiguruj ustawienia, jak pokazano na przykładowym zrzucie ekranu.
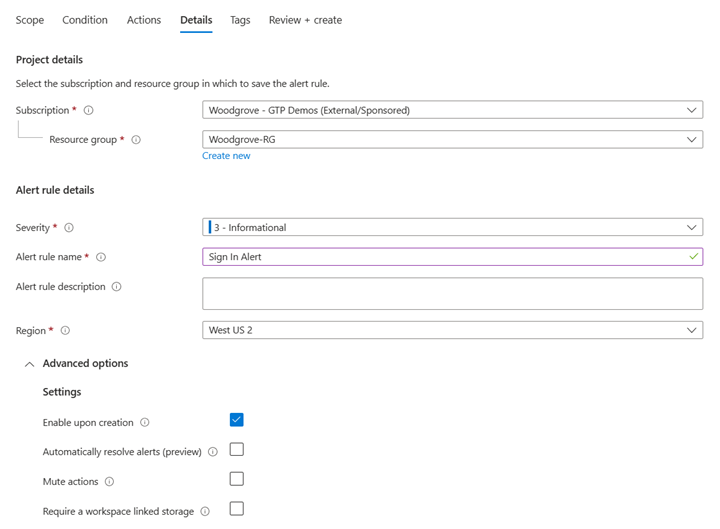
- Dodaj nazwę subskrypcji i opis.
- Wybierz grupę zasobów, do której chcesz dodać alert.
- Wybierz domyślną ważność.
- Wybierz pozycję Włącz po utworzeniu , jeśli chcesz natychmiast przejść na żywo. W przeciwnym razie wybierz pozycję Wycisz akcje.
W sekcji Przeglądanie i tworzenie skonfiguruj ustawienia, jak pokazano na przykładowym zrzucie ekranu.
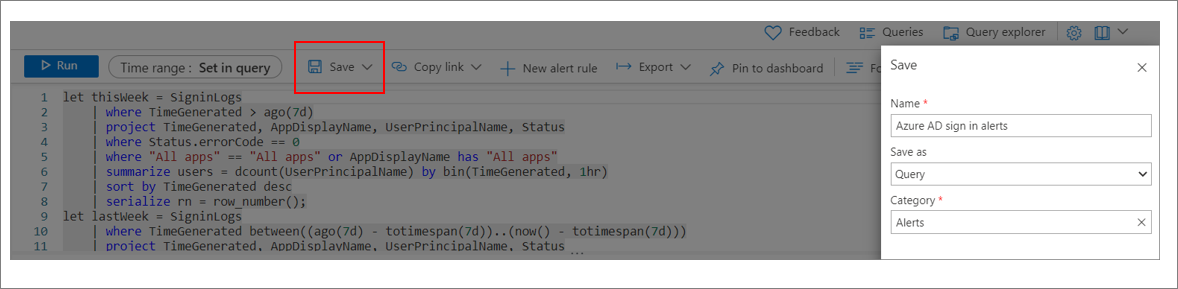
Wybierz pozycję Zapisz. Wprowadź nazwę zapytania. W polu Zapisz jako wybierz pozycję Zapytanie. W obszarze Kategoria wybierz pozycję Alert. Ponownie wybierz pozycję Zapisz.
Uściślij zapytania i alerty
Aby zmodyfikować zapytania i alerty w celu uzyskania maksymalnej skuteczności:
- Zawsze testuj alerty.
- Zmodyfikuj poufność i częstotliwość alertów, aby otrzymywać ważne powiadomienia. Administratorzy mogą zostać zniewrażliwi na alerty i przegapić coś ważnego, jeśli otrzymają zbyt wiele.
- W klientach poczty e-mail administratora dodaj wiadomość e-mail, z której alerty pochodzą do listy dozwolonych nadawców. Takie podejście uniemożliwia nieodebrane powiadomienia z powodu filtru spamu na klientach poczty e-mail.
- Zgodnie z projektem zapytania alertów w usłudze Azure Monitor mogą zawierać tylko wyniki z ostatnich 48 godzin.
Przykładowe skrypty
Zapytanie Kusto w celu zwiększenia współczynnika niepowodzeń
W poniższym zapytaniu wykrywamy rosnące współczynniki niepowodzeń. W razie potrzeby można dostosować stosunek u dołu. Reprezentuje ona zmianę procentu ruchu w ciągu ostatniej godziny w porównaniu z wczorajszym ruchem w tym samym czasie. Wynik 0,5 wskazuje na różnicę 50% ruchu.
let today = SigninLogs
| where TimeGenerated > ago(1h) // Query failure rate in the last hour
| project TimeGenerated, UserPrincipalName, AppDisplayName, status = case(Status.errorCode == "0", "success", "failure")
// Optionally filter by a specific application
//| where AppDisplayName == **APP NAME**
| summarize success = countif(status == "success"), failure = countif(status == "failure") by bin(TimeGenerated, 1h) // hourly failure rate
| project TimeGenerated, failureRate = (failure * 1.0) / ((failure + success) * 1.0)
| sort by TimeGenerated desc
| serialize rowNumber = row_number();
let yesterday = SigninLogs
| where TimeGenerated between((ago(1h) – totimespan(1d))..(now() – totimespan(1d))) // Query failure rate at the same time yesterday
| project TimeGenerated, UserPrincipalName, AppDisplayName, status = case(Status.errorCode == "0", "success", "failure")
// Optionally filter by a specific application
//| where AppDisplayName == **APP NAME**
| summarize success = countif(status == "success"), failure = countif(status == "failure") by bin(TimeGenerated, 1h) // hourly failure rate at same time yesterday
| project TimeGenerated, failureRateYesterday = (failure * 1.0) / ((failure + success) * 1.0)
| sort by TimeGenerated desc
| serialize rowNumber = row_number();
today
| join (yesterday) on rowNumber // join data from same time today and yesterday
| project TimeGenerated, failureRate, failureRateYesterday
// Set threshold to be the percent difference in failure rate in the last hour as compared to the same time yesterday
// Day variable is the number of days since the previous Sunday. Optionally ignore results on Sat, Sun, and Mon because large variability in traffic is expected.
| extend day = dayofweek(now())
| where day != time(6.00:00:00) // exclude Sat
| where day != time(0.00:00:00) // exclude Sun
| where day != time(1.00:00:00) // exclude Mon
| where abs(failureRate – failureRateYesterday) > 0.5
Zapytanie Kusto dotyczące spadku użycia
W poniższym zapytaniu porównujemy ruch w ciągu ostatniej godziny z wczorajszym ruchem w tym samym czasie. Wykluczamy sobotę, niedzielę i poniedziałek, ponieważ spodziewamy się dużej zmienności w ruchu z poprzedniego dnia w tym samym czasie.
W razie potrzeby można dostosować stosunek u dołu. Reprezentuje ona zmianę procentu ruchu w ciągu ostatniej godziny w porównaniu z wczorajszym ruchem w tym samym czasie. Wynik 0,5 wskazuje na różnicę 50% ruchu. Dostosuj te wartości, aby dopasować je do modelu operacji biznesowych.
Let today = SigninLogs // Query traffic in the last hour
| where TimeGenerated > ago(1h)
| project TimeGenerated, AppDisplayName, UserPrincipalName
// Optionally filter by AppDisplayName to scope query to a single application
//| where AppDisplayName contains "Office 365 Exchange Online"
| summarize users = dcount(UserPrincipalName) by bin(TimeGenerated, 1hr) // Count distinct users in the last hour
| sort by TimeGenerated desc
| serialize rn = row_number();
let yesterday = SigninLogs // Query traffic at the same hour yesterday
| where TimeGenerated between((ago(1h) – totimespan(1d))..(now() – totimespan(1d))) // Count distinct users in the same hour yesterday
| project TimeGenerated, AppDisplayName, UserPrincipalName
// Optionally filter by AppDisplayName to scope query to a single application
//| where AppDisplayName contains "Office 365 Exchange Online"
| summarize usersYesterday = dcount(UserPrincipalName) by bin(TimeGenerated, 1hr)
| sort by TimeGenerated desc
| serialize rn = row_number();
today
| join // Join data from today and yesterday together
(
yesterday
)
on rn
// Calculate the difference in number of users in the last hour compared to the same time yesterday
| project TimeGenerated, users, usersYesterday, difference = abs(users – usersYesterday), max = max_of(users, usersYesterday)
| extend ratio = (difference * 1.0) / max // Ratio is the percent difference in traffic in the last hour as compared to the same time yesterday
// Day variable is the number of days since the previous Sunday. Optionally ignore results on Sat, Sun, and Mon because large variability in traffic is expected.
| extend day = dayofweek(now())
| where day != time(6.00:00:00) // exclude Sat
| where day != time(0.00:00:00) // exclude Sun
| where day != time(1.00:00:00) // exclude Mon
| where ratio > 0.7 // Threshold percent difference in sign-in traffic as compared to same hour yesterday
Tworzenie procesów do zarządzania alertami
Po skonfigurowaniu zapytań i alertów utwórz procesy biznesowe do zarządzania alertami.
- Kto monitoruje skoroszyt i kiedy?
- Kiedy występują alerty, kto je bada?
- Jakie są potrzeby komunikacyjne? Kto tworzy komunikację i kto je otrzymuje?
- Kiedy wystąpi awaria, jakie procesy biznesowe mają zastosowanie?
Następne kroki
Dowiedz się więcej o skoroszytach