Zagadnienia dotyczące wydajności programu EF 4, 5 i 6
David Obando, Eric Dettinger i inni
Opublikowano: Kwiecień 2012 r.
Ostatnia aktualizacja: maj 2014 r.
1. Wprowadzenie
Struktury mapowania relacyjnego obiektów to wygodny sposób zapewnienia abstrakcji dostępu do danych w aplikacji zorientowanej na obiekt. W przypadku aplikacji platformy .NET zalecana przez firmę Microsoft funkcja O/RM to Entity Framework. Jednak z dowolną abstrakcją wydajność może stać się problemem.
Ten oficjalny dokument został napisany w celu przedstawienia zagadnień dotyczących wydajności podczas tworzenia aplikacji przy użyciu platformy Entity Framework, aby dać deweloperom pomysł na wewnętrzne algorytmy platformy Entity Framework, które mogą mieć wpływ na wydajność, oraz zapewnić wskazówki dotyczące badania i poprawy wydajności w aplikacjach korzystających z platformy Entity Framework. Istnieje wiele dobrych tematów dotyczących wydajności, które są już dostępne w Internecie, a my również próbowaliśmy wskazać te zasoby tam, gdzie to możliwe.
Wydajność jest trudnym tematem. Ten oficjalny dokument jest przeznaczony jako zasób, który ułatwia podejmowanie decyzji związanych z wydajnością aplikacji korzystających z programu Entity Framework. Uwzględniliśmy niektóre metryki testów, aby zademonstrować wydajność, ale te metryki nie są przeznaczone jako bezwzględne wskaźniki wydajności widocznej w aplikacji.
W praktycznych celach ten dokument zakłada, że program Entity Framework 4 jest uruchamiany na platformie .NET 4.0, a program Entity Framework 5 i 6 są uruchamiane na platformie .NET 4.5. Wiele ulepszeń wydajności wprowadzonych w programie Entity Framework 5 znajduje się w podstawowych składnikach, które są dostarczane z platformą .NET 4.5.
Program Entity Framework 6 jest wersją poza pasmem i nie zależy od składników programu Entity Framework, które są dostarczane z platformą .NET. Program Entity Framework 6 działa zarówno na platformie .NET 4.0, jak i na platformie .NET 4.5, i może zapewnić dużą korzyść w zakresie wydajności dla tych, którzy nie uaktualnili programu .NET 4.0, ale chcą najnowszych bitów programu Entity Framework w swojej aplikacji. Gdy ten dokument zawiera wzmiankę o programie Entity Framework 6, odwołuje się do najnowszej wersji dostępnej w momencie pisania tego dokumentu: wersja 6.1.0.
2. Zimne i ciepłe wykonywanie zapytań
Po pierwszym utworzeniu zapytania względem danego modelu platforma Entity Framework wykonuje wiele prac w tle, aby załadować i zweryfikować model. Często odwołujemy się do tego pierwszego zapytania jako zapytania "zimnego". Dalsze zapytania względem już załadowanego modelu są nazywane zapytaniami "ciepłymi" i są znacznie szybsze.
Przyjrzyjmy się ogólnej części tego, gdzie jest poświęcany czas podczas wykonywania zapytania przy użyciu platformy Entity Framework, i zobaczmy, gdzie elementy są ulepszane w programie Entity Framework 6.
Pierwsze wykonywanie zapytań — zimne zapytanie
| Pisanie przez użytkownika kodu | Akcja | Wpływ na wydajność EF4 | Wpływ na wydajność ef5 | Wpływ na wydajność ef6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Tworzenie kontekstu | Średnie | Średnie | Niska |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Tworzenie wyrażenia zapytania | Niska | Niska | Niska |
var c1 = q1.First(); |
Wykonywanie zapytań LINQ | - Ładowanie metadanych: wysokie, ale buforowane - Generowanie widoku: Potencjalnie bardzo wysokie, ale buforowane - Ocena parametru: średni rozmiar - Tłumaczenie zapytania: średni rozmiar - Generowanie materializatora: średni, ale buforowany - Wykonywanie zapytań bazy danych: Potencjalnie wysokie + Połączenie ion. Otwórz + Command.ExecuteReader + DataReader.Read Materializacja obiektów: średni rozmiar - Wyszukiwanie tożsamości: średni rozmiar |
- Ładowanie metadanych: wysokie, ale buforowane - Generowanie widoku: Potencjalnie bardzo wysokie, ale buforowane - Ocena parametru: Niska - Tłumaczenie zapytania: średni, ale buforowany - Generowanie materializatora: średni, ale buforowany - Wykonywanie zapytań bazy danych: Potencjalnie wysokie (Lepsze zapytania w niektórych sytuacjach) + Połączenie ion. Otwórz + Command.ExecuteReader + DataReader.Read Materializacja obiektów: średni rozmiar - Wyszukiwanie tożsamości: średni rozmiar |
- Ładowanie metadanych: wysokie, ale buforowane - Generowanie widoku: średni, ale buforowany - Ocena parametru: Niska - Tłumaczenie zapytania: średni, ale buforowany - Generowanie materializatora: średni, ale buforowany - Wykonywanie zapytań bazy danych: Potencjalnie wysokie (Lepsze zapytania w niektórych sytuacjach) + Połączenie ion. Otwórz + Command.ExecuteReader + DataReader.Read Materializacja obiektów: średnia (szybsza niż EF5) - Wyszukiwanie tożsamości: średni rozmiar |
} |
Połączenie ion. Zamknij | Niska | Niska | Niska |
Drugie wykonanie zapytania — ciepłe zapytanie
| Pisanie przez użytkownika kodu | Akcja | Wpływ na wydajność EF4 | Wpływ na wydajność ef5 | Wpływ na wydajność ef6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Tworzenie kontekstu | Średnie | Średnie | Niska |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Tworzenie wyrażenia zapytania | Niska | Niska | Niska |
var c1 = q1.First(); |
Wykonywanie zapytań LINQ | - Wyszukiwanie ładowania — Wyszukiwanie generowania - Ocena parametru: średni rozmiar - Wyszukiwanie tłumaczenia - Wyszukiwanie generowania - Wykonywanie zapytań bazy danych: Potencjalnie wysokie + Połączenie ion. Otwórz + Command.ExecuteReader + DataReader.Read Materializacja obiektów: średni rozmiar - Wyszukiwanie tożsamości: średni rozmiar |
- Wyszukiwanie ładowania — Wyszukiwanie generowania - Ocena parametru: Niska - Wyszukiwanie tłumaczenia - Wyszukiwanie generowania - Wykonywanie zapytań bazy danych: Potencjalnie wysokie (Lepsze zapytania w niektórych sytuacjach) + Połączenie ion. Otwórz + Command.ExecuteReader + DataReader.Read Materializacja obiektów: średni rozmiar - Wyszukiwanie tożsamości: średni rozmiar |
- Wyszukiwanie ładowania — Wyszukiwanie generowania - Ocena parametru: Niska - Wyszukiwanie tłumaczenia - Wyszukiwanie generowania - Wykonywanie zapytań bazy danych: Potencjalnie wysokie (Lepsze zapytania w niektórych sytuacjach) + Połączenie ion. Otwórz + Command.ExecuteReader + DataReader.Read Materializacja obiektów: średnia (szybsza niż EF5) - Wyszukiwanie tożsamości: średni rozmiar |
} |
Połączenie ion. Zamknij | Niska | Niska | Niska |
Istnieje kilka sposobów zmniejszenia kosztów wydajności zarówno zimnych, jak i ciepłych zapytań. Przyjrzymy się tym w poniższej sekcji. W szczególności przyjrzymy się zmniejszeniu kosztów ładowania modelu w zimnych zapytaniach przy użyciu wstępnie wygenerowanych widoków, co powinno pomóc złagodzić problemy z wydajnością występujące podczas generowania widoku. W przypadku ciepłych zapytań omówimy buforowanie planu zapytań, brak zapytań śledzenia i różne opcje wykonywania zapytań.
2.1 Co to jest generowanie widoku?
Aby zrozumieć, jakie jest generowanie widoku, musimy najpierw zrozumieć, czym są "widoki mapowania". Widoki mapowania to wykonywalne reprezentacje przekształceń określonych w mapowaniu dla każdego zestawu jednostek i skojarzenia. Wewnętrznie te widoki mapowania przyjmują kształt CQTs (kanoniczne drzewa zapytań). Istnieją dwa typy widoków mapowania:
- Widoki zapytań: reprezentują one transformację niezbędną do przejścia ze schematu bazy danych do modelu koncepcyjnego.
- Widoki aktualizacji: reprezentują one transformację niezbędną do przejścia z modelu koncepcyjnego do schematu bazy danych.
Należy pamiętać, że model koncepcyjny może różnić się od schematu bazy danych na różne sposoby. Na przykład jedna tabela może służyć do przechowywania danych dla dwóch różnych typów jednostek. Dziedziczenie i nietrywialne mapowania odgrywają rolę w złożoności widoków mapowania.
Proces przetwarzania tych widoków na podstawie specyfikacji mapowania jest tym, co nazywamy generowaniem widoku. Generowanie widoku może odbywać się dynamicznie, gdy model jest ładowany lub w czasie kompilacji przy użyciu "wstępnie wygenerowanych widoków"; te ostatnie są serializowane w postaci instrukcji Entity SQL do pliku C# lub VB.
Po wygenerowaniu widoków są one również weryfikowane. Z punktu widzenia wydajności zdecydowana większość kosztów generowania widoku jest w rzeczywistości walidacją widoków, co gwarantuje, że połączenia między jednostkami mają sens i mają poprawną kardynalność dla wszystkich obsługiwanych operacji.
Po wykonaniu zapytania względem zestawu jednostek zapytanie jest łączone z odpowiednim widokiem zapytania, a wynik tego składu jest wykonywany przez kompilator planu w celu utworzenia reprezentacji zapytania, które może zrozumieć magazyn kopii zapasowych. W przypadku programu SQL Server ostateczny wynik tej kompilacji będzie instrukcją T-SQL SELECT. Przy pierwszym wykonaniu aktualizacji zestawu jednostek widok aktualizacji jest wykonywany przez podobny proces, aby przekształcić go w instrukcje DML dla docelowej bazy danych.
2.2 Czynniki wpływające na wydajność generowania widoku
Wydajność kroku generowania widoku zależy nie tylko od rozmiaru modelu, ale także od sposobu połączenia modelu. Jeśli dwie jednostki są połączone za pośrednictwem łańcucha dziedziczenia lub skojarzenia, mówi się, że są połączone. Podobnie, jeśli dwie tabele są połączone za pośrednictwem klucza obcego, są połączone. Wraz ze wzrostem liczby połączonych jednostek i tabel w schematach zwiększa się koszt generowania widoku.
Algorytm używany do generowania i sprawdzania poprawności widoków jest wykładniczy w najgorszym przypadku, chociaż w celu poprawienia tego celu używamy niektórych optymalizacji. Największe czynniki, które wydają się negatywnie wpływać na wydajność, to:
- Rozmiar modelu odwołujący się do liczby jednostek i liczby skojarzeń między tymi jednostkami.
- Złożoność modelu, w szczególności dziedziczenie obejmujące dużą liczbę typów.
- Używanie niezależnych skojarzeń, zamiast skojarzeń kluczy obcych.
W przypadku małych, prostych modeli koszt może być wystarczająco mały, aby nie przeszkadzać przy użyciu wstępnie wygenerowanych widoków. W miarę zwiększania rozmiaru i złożoności modelu dostępnych jest kilka opcji zmniejszania kosztów generowania i walidacji widoku.
2.3 Używanie wstępnie wygenerowanych widoków w celu zmniejszenia czasu ładowania modelu
Aby uzyskać szczegółowe informacje na temat używania wstępnie wygenerowanych widoków w programie Entity Framework 6, odwiedź stronę wstępnie wygenerowane widoki mapowania
2.3.1 Wstępnie wygenerowane widoki przy użyciu programu Entity Framework Power Tools Community Edition
Możesz użyć programu Entity Framework 6 Power Tools Community Edition , aby wygenerować widoki modeli EDMX i Code First, klikając prawym przyciskiem myszy plik klasy modelu i używając menu Entity Framework, aby wybrać pozycję "Generuj widoki". Program Entity Framework Power Tools Community Edition działa tylko w kontekstach pochodnych dbContext.
2.3.2 Jak używać wstępnie wygenerowanych widoków z modelem utworzonym przez EDMGen
EDMGen to narzędzie dostarczane z platformą .NET i współdziałające z programem Entity Framework 4 i 5, ale nie z programem Entity Framework 6. EDMGen umożliwia wygenerowanie pliku modelu, warstwy obiektu i widoków z wiersza polecenia. Jednym z danych wyjściowych będzie plik Views w wybranym języku, VB lub C#. Jest to plik kodu zawierający fragmenty kodu jednostki SQL dla każdego zestawu jednostek. Aby włączyć wstępnie wygenerowane widoki, wystarczy dołączyć plik do projektu.
Jeśli ręcznie wprowadzisz zmiany w plikach schematu dla modelu, musisz ponownie wygenerować plik widoków. Można to zrobić, uruchamiając polecenie EDMGen z flagą /mode:ViewGeneration .
2.3.3 Jak używać wstępnie wygenerowanych widoków z plikiem EDMX
Można również użyć narzędzia EDMGen do generowania widoków dla pliku EDMX — wcześniej przywoływanego tematu MSDN opisano sposób dodawania zdarzenia przed kompilacją, aby to zrobić — ale jest to skomplikowane i istnieją pewne przypadki, w których nie jest to możliwe. Zazwyczaj łatwiej jest użyć szablonu T4 do generowania widoków, gdy model znajduje się w pliku edmx.
Blog zespołu ADO.NET zawiera wpis opisujący sposób używania szablonu T4 do generowania widoku ( <https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>). Ten wpis zawiera szablon, który można pobrać i dodać do projektu. Szablon został napisany dla pierwszej wersji programu Entity Framework, więc nie ma gwarancji, że będą działać z najnowszymi wersjami programu Entity Framework. Można jednak pobrać bardziej aktualny zestaw szablonów generowania widoków dla programu Entity Framework 4 i 5 z galerii programu Visual Studio:
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Jeśli używasz programu Entity Framework 6, możesz pobrać szablony generacji widoku T4 z galerii programu Visual Studio pod adresem <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>.
2.4 Zmniejszenie kosztów generowania widoku
Użycie wstępnie wygenerowanych widoków przenosi koszt generowania widoku z ładowania modelu (czasu wykonywania) do czasu projektowania. Chociaż poprawia to wydajność uruchamiania w czasie wykonywania, podczas opracowywania nadal będzie występować ból generowania widoku. Istnieje kilka dodatkowych wskazówek, które mogą pomóc zmniejszyć koszt generowania widoku, zarówno w czasie kompilacji, jak i w czasie wykonywania.
2.4.1 Używanie skojarzeń kluczy obcych w celu zmniejszenia kosztów generowania
Widzieliśmy wiele przypadków, w których przełączanie skojarzeń w modelu z niezależnych skojarzeń do zagranicznych skojarzeń znacznie poprawiło czas spędzony w generowaniu widoku.
Aby zademonstrować to ulepszenie, wygenerowaliśmy dwie wersje modelu Navision przy użyciu narzędzia EDMGen. Uwaga: zobacz dodatek C, aby uzyskać opis modelu Navision. Model Navision jest interesujący dla tego ćwiczenia ze względu na bardzo dużą ilość jednostek i relacji między nimi.
Jedna wersja tego bardzo dużego modelu została wygenerowana za pomocą skojarzeń kluczy obcych, a druga została wygenerowana za pomocą niezależnych skojarzeń. Następnie ustaliliśmy, jak długo trwało generowanie widoków dla każdego modelu. Test programu Entity Framework 5 użył metody GenerateViews() z klasy EntityViewGenerator do wygenerowania widoków, podczas gdy test platformy Entity Framework 6 użył metody GenerateViews() z klasy StorageMappingItemCollection. Wynika to z restrukturyzacji kodu, która miała miejsce w bazie kodu Programu Entity Framework 6.
Użycie programu Entity Framework 5, generowanie widoku dla modelu z kluczami obcymi trwało 65 minut na maszynie laboratoryjnej. Nie wiadomo, jak długo zajęłoby wygenerowanie widoków dla modelu, który używał niezależnych skojarzeń. Opuściliśmy test uruchomiony przez ponad miesiąc, zanim maszyna została ponownie uruchomiona w naszym laboratorium, aby zainstalować comiesięczne aktualizacje.
Użycie programu Entity Framework 6, generowanie widoku dla modelu z kluczami obcymi trwało 28 sekund na tym samym komputerze laboratoryjnym. Generowanie widoku dla modelu używającego niezależnych skojarzeń trwało 58 sekund. Ulepszenia wprowadzone w programie Entity Framework 6 w kodzie generowania widoku oznaczają, że wiele projektów nie będzie potrzebować wstępnie wygenerowanych widoków, aby uzyskać szybsze czasy uruchamiania.
Ważne jest, aby zauważyć, że wstępnie generowane widoki w programie Entity Framework 4 i 5 można wykonywać za pomocą narzędzi EDMGen lub Entity Framework Power Tools. W przypadku generowania widoku programu Entity Framework 6 można przeprowadzić za pomocą narzędzi Entity Framework Power Tools lub programowo zgodnie z opisem w widokach mapowania wstępnie wygenerowanego.
2.4.1.1 Jak używać kluczy obcych zamiast niezależnych skojarzeń
W przypadku korzystania z programu EDMGen lub entity Projektant w programie Visual Studio domyślnie uzyskuje się zestawy FKs i pobiera tylko jedno pole wyboru lub flagę wiersza polecenia, aby przełączać się między zestawami FKs i IA.
Jeśli masz duży model Code First, użycie niezależnych skojarzeń będzie miało taki sam wpływ na generowanie widoku. Ten wpływ można uniknąć, uwzględniając właściwości klucza obcego w klasach dla obiektów zależnych, choć niektórzy deweloperzy uważają, że jest to zanieczyszczające ich model obiektów. Więcej informacji na ten temat można znaleźć w temacie <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>.
| W przypadku korzystania z | Sposób wykonania |
|---|---|
| Projektant jednostek | Po dodaniu skojarzenia między dwiema jednostkami upewnij się, że masz ograniczenie odwołania. Ograniczenia odwołań informują platformę Entity Framework o używaniu kluczy obcych zamiast niezależnych skojarzeń. Aby uzyskać dodatkowe informacje, odwiedź stronę <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | W przypadku generowania plików z bazy danych przy użyciu narzędzia EDMGen klucze obce będą przestrzegane i dodawane do modelu jako takie. Aby uzyskać więcej informacji na temat różnych opcji udostępnianych przez EDMGen, odwiedź stronę http://msdn.microsoft.com/library/bb387165.aspx. |
| Kod pierwszy | Zapoznaj się z sekcją "Konwencja relacji" w temacie Code First Conventions (Konwencje kodów ), aby uzyskać informacje na temat dołączania właściwości klucza obcego do obiektów zależnych podczas korzystania z funkcji Code First. |
2.4.2 Przenoszenie modelu do oddzielnego zestawu
Jeśli model zostanie uwzględniony bezpośrednio w projekcie aplikacji i wygenerujesz widoki za pomocą zdarzenia przed kompilacją lub szablonu T4, generowanie i walidacja widoku będą odbywać się za każdym razem, gdy projekt zostanie ponownie skompilowany, nawet jeśli model nie został zmieniony. Jeśli przeniesiesz model do oddzielnego zestawu i odwołujesz się do niego z projektu aplikacji, możesz wprowadzić inne zmiany w aplikacji bez konieczności ponownego kompilowania projektu zawierającego model.
Uwaga: podczas przenoszenia modelu do oddzielnych zestawów pamiętaj, aby skopiować parametry połączenia dla modelu do pliku konfiguracji aplikacji projektu klienta.
2.4.3 Wyłącz walidację modelu opartego na edmx
Modele EDMX są weryfikowane w czasie kompilacji, nawet jeśli model jest niezmieniony. Jeśli model został już zweryfikowany, możesz pominąć walidację w czasie kompilacji, ustawiając właściwość "Validate on Build" na false w oknie właściwości. Po zmianie mapowania lub modelu możesz tymczasowo ponownie włączyć walidację, aby zweryfikować zmiany.
Należy pamiętać, że wprowadzono ulepszenia wydajności w programie Entity Framework Projektant dla programu Entity Framework 6, a koszt weryfikacji kompilacji jest znacznie niższy niż w poprzednich wersjach projektanta.
3 Buforowanie w programie Entity Framework
Program Entity Framework ma następujące formy wbudowanego buforowania:
- Buforowanie obiektów — obiekt ObjectStateManager wbudowany w wystąpienie ObjectContext śledzi w pamięci obiektów, które zostały pobrane przy użyciu tego wystąpienia. Jest to również nazywane pamięcią podręczną pierwszego poziomu.
- Plan zapytania Buforowanie — ponowne wykonywanie wygenerowanego polecenia magazynu, gdy zapytanie jest wykonywane więcej niż raz.
- Buforowanie metadanych — udostępnianie metadanych dla modelu między różnymi połączeniami z tym samym modelem.
Oprócz pamięci podręcznych, które program EF udostępnia w pudełku, specjalny rodzaj dostawcy danych ADO.NET znany jako dostawca opakowujący może również służyć do rozszerzania programu Entity Framework z pamięcią podręczną dla wyników pobranych z bazy danych, znanej również jako buforowanie drugiego poziomu.
Buforowanie obiektu 3.1
Domyślnie, gdy jednostka jest zwracana w wynikach zapytania, tuż przed materializuje ją EF, obiekt ObjectContext sprawdzi, czy jednostka z tym samym kluczem została już załadowana do klasy ObjectStateManager. Jeśli jednostka z tymi samymi kluczami jest już obecna, program EF uwzględni go w wynikach zapytania. Mimo że program EF nadal będzie wystawiać zapytanie względem bazy danych, to zachowanie może pominąć znaczną część kosztów materializowania jednostki wielokrotnie.
3.1.1 Pobieranie jednostek z pamięci podręcznej obiektów przy użyciu funkcji DbContext Find
W przeciwieństwie do zwykłego zapytania metoda Find w zestawie DbSet (interfejsy API uwzględnione po raz pierwszy w programie EF 4.1) wykona wyszukiwanie w pamięci, zanim jeszcze wyśle zapytanie względem bazy danych. Należy pamiętać, że dwa różne wystąpienia ObjectContext będą miały dwa różne wystąpienia ObjectStateManager, co oznacza, że mają oddzielne pamięci podręczne obiektów.
Funkcja Find używa wartości klucza podstawowego do próby znalezienia jednostki śledzonej przez kontekst. Jeśli jednostka nie znajduje się w kontekście, zapytanie zostanie wykonane i ocenione względem bazy danych, a wartość null zostanie zwrócona, jeśli jednostka nie zostanie znaleziona w kontekście lub w bazie danych. Należy pamiętać, że funkcja Find zwraca również jednostki, które zostały dodane do kontekstu, ale nie zostały jeszcze zapisane w bazie danych.
Podczas korzystania z funkcji Znajdź należy wziąć pod uwagę wydajność. Wywołania tej metody domyślnie będą wyzwalać walidację pamięci podręcznej obiektów w celu wykrycia zmian, które nadal oczekują na zatwierdzenie w bazie danych. Ten proces może być bardzo kosztowny, jeśli istnieje bardzo duża liczba obiektów w pamięci podręcznej obiektów lub w dużym grafie obiektów dodawanym do pamięci podręcznej obiektów, ale można go również wyłączyć. W niektórych przypadkach podczas wyłączania automatycznego wykrywania zmian można zauważyć różnicę o różnej wielkości w wywołaniu metody Find. Jednak drugi kolejność wielkości jest postrzegany, gdy obiekt rzeczywiście znajduje się w pamięci podręcznej, a gdy obiekt musi zostać pobrany z bazy danych. Oto przykładowy wykres z pomiarami wykonanymi przy użyciu niektórych mikrobenchmarków wyrażonych w milisekundach z obciążeniem 5000 jednostek:

Przykład znajdowania z wyłączonymi zmianami automatycznego wykrywania:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
Kwestie, które należy wziąć pod uwagę podczas korzystania z metody Find, to:
- Jeśli obiekt nie znajduje się w pamięci podręcznej, korzyści z funkcji Find są negowane, ale składnia jest nadal prostsza niż zapytanie według klucza.
- Jeśli funkcja automatycznego wykrywania zmian jest włączona, koszt metody Find może wzrosnąć o jedną kolejność wielkości, a nawet więcej w zależności od złożoności modelu i ilości jednostek w pamięci podręcznej obiektów.
Należy również pamiętać, że funkcja Find zwraca tylko szukaną jednostkę i nie ładuje automatycznie skojarzonych jednostek, jeśli nie znajdują się one jeszcze w pamięci podręcznej obiektów. Jeśli musisz pobrać skojarzone jednostki, możesz użyć zapytania według klucza z chętnym ładowaniem. Aby uzyskać więcej informacji, zobacz Ładowanie z opóźnieniem 8.1 a Zaczytywanie ładowania.
3.1.2 Problemy z wydajnością, gdy pamięć podręczna obiektów ma wiele jednostek
Pamięć podręczna obiektów pomaga zwiększyć ogólną szybkość reakcji platformy Entity Framework. Jednak gdy pamięć podręczna obiektów ma bardzo dużą ilość załadowanych jednostek, może to mieć wpływ na niektóre operacje, takie jak Dodawanie, Usuwanie, Znajdowanie, Wprowadzanie, ZapisywanieZmiany i inne. W szczególności operacje wyzwalające wywołanie funkcji DetectChanges będą negatywnie wpływać na bardzo duże pamięci podręczne obiektów. Funkcja DetectChanges synchronizuje graf obiektu z menedżerem stanu obiektu, a jego wydajność będzie określana bezpośrednio przez rozmiar grafu obiektu. Aby uzyskać więcej informacji na temat funkcji DetectChanges, zobacz Śledzenie zmian w jednostkach POCO.
W przypadku korzystania z programu Entity Framework 6 deweloperzy mogą wywoływać metody AddRange i RemoveRange bezpośrednio w zestawie dbSet, zamiast iterować w kolekcji i wywoływać funkcję Dodaj raz na wystąpienie. Zaletą używania metod zakresu jest to, że koszt funkcji DetectChanges jest opłacany tylko raz dla całego zestawu jednostek, a nie raz dla każdej dodanej jednostki.
3.2 Buforowanie planu zapytania
Po pierwszym wykonaniu zapytania przechodzi przez kompilator wewnętrzny plan, aby przetłumaczyć zapytanie koncepcyjne na polecenie magazynu (na przykład T-SQL, który jest wykonywany podczas uruchamiania względem programu SQL Server). Jeśli buforowanie planu zapytania jest włączone, następnym razem, gdy zapytanie zostanie wykonane, polecenie magazynu zostanie pobrane bezpośrednio z pamięci podręcznej planu zapytania na potrzeby wykonywania, pomijając kompilator planu.
Pamięć podręczna planu zapytania jest współdzielona między wystąpieniami ObjectContext w ramach tej samej domeny aplikacji. Nie musisz przechowywać wystąpienia ObjectContext, aby korzystać z buforowania planu zapytania.
3.2.1 Niektóre uwagi dotyczące planu zapytań Buforowanie
- Pamięć podręczna planu zapytania jest współdzielona dla wszystkich typów zapytań: Entity SQL, LINQ to Entities i CompiledQuery obiektów.
- Domyślnie buforowanie planu zapytań jest włączone dla zapytań Entity SQL, niezależnie od tego, czy są wykonywane za pośrednictwem entityCommand, czy za pośrednictwem zapytania ObjectQuery. Jest ona również domyślnie włączona dla zapytań LINQ to Entities w programie Entity Framework na platformie .NET 4.5 i w programie Entity Framework 6
- Buforowanie planu zapytania można wyłączyć, ustawiając właściwość EnablePlan Buforowanie (w poleceniu EntityCommand lub ObjectQuery) na false. Przykład:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- W przypadku zapytań sparametryzowanych zmiana wartości parametru będzie nadal osiągać buforowane zapytanie. Jednak zmiana aspektów parametru (na przykład rozmiar, precyzja lub skala) spowoduje trafienie innego wpisu w pamięci podręcznej.
- W przypadku korzystania z jednostki SQL ciąg zapytania jest częścią klucza. Zmiana zapytania w ogóle spowoduje wyświetlenie różnych wpisów pamięci podręcznej, nawet jeśli zapytania są funkcjonalnie równoważne. Obejmuje to zmiany wielkości liter lub odstępów.
- W przypadku korzystania z LINQ zapytanie jest przetwarzane w celu wygenerowania części klucza. Zmiana wyrażenia LINQ spowoduje wygenerowanie innego klucza.
- Mogą obowiązywać inne ograniczenia techniczne; Aby uzyskać więcej informacji, zobacz Autokompilowane zapytania.
3.2.2 Algorytm eksmisji pamięci podręcznej
Zrozumienie sposobu działania algorytmu wewnętrznego pomoże Ci ustalić, kiedy włączyć lub wyłączyć buforowanie planu zapytania. Algorytm oczyszczania jest następujący:
- Gdy pamięć podręczna zawiera zestaw wpisów (800), uruchamiamy czasomierz, który okresowo (raz na minutę) zamiata pamięć podręczną.
- Podczas zamiatania pamięci podręcznej wpisy są usuwane z pamięci podręcznej na podstawie LFRU (najmniej często — ostatnio używane). Ten algorytm uwzględnia zarówno liczbę trafień, jak i wiek podczas podejmowania decyzji, które wpisy są wyrzucane.
- Na końcu każdego zamiatania pamięci podręcznej pamięć podręczna ponownie zawiera 800 wpisów.
Wszystkie wpisy pamięci podręcznej są traktowane równie samo podczas określania, które wpisy mają być eksmitowane. Oznacza to, że polecenie magazynu dla zapytania CompiledQuery ma taką samą szansę eksmisji, jak polecenie magazynu dla zapytania SQL jednostki.
Należy pamiętać, że czasomierz eksmisji pamięci podręcznej jest uruchamiany, gdy w pamięci podręcznej znajduje się 800 jednostek, ale pamięć podręczna jest przetoczyła się tylko 60 sekund po uruchomieniu tego czasomierza. Oznacza to, że przez maksymalnie 60 sekund pamięć podręczna może być dość duża.
3.2.3 Metryki testów pokazujące wydajność buforowania planu zapytania
Aby zademonstrować wpływ buforowania planu zapytań na wydajność aplikacji, przeprowadziliśmy test, w którym wykonaliśmy kilka zapytań Entity SQL względem modelu Navision. Zobacz dodatek, aby zapoznać się z opisem modelu Navision i typami zapytań, które zostały wykonane. W tym teście najpierw wykonujemy iterację po liście zapytań i wykonujemy je raz, aby dodać je do pamięci podręcznej (jeśli buforowanie jest włączone). Ten krok jest niedostępny. Następnie przesypimy główny wątek przez ponad 60 sekund, aby umożliwić zamiatanie pamięci podręcznej; na koniec iterujemy po drugiej godzinie listy w celu wykonania buforowanych zapytań. Ponadto pamięć podręczna planu programu SQL Server jest opróżniana przed wykonaniem każdego zestawu zapytań, dzięki czemu czasy uzyskania dokładnie odzwierciedlają korzyść podaną przez pamięć podręczną planu zapytania.
3.2.3.1 Wyniki testów
| Przetestuj | EF5 — brak pamięci podręcznej | Pamięć podręczna EF5 | EF6 — brak pamięci podręcznej | Pamięć podręczna EF6 |
|---|---|---|---|---|
| Wyliczanie wszystkich zapytań 18723 | 124 | 125.4 | 124.3 | 125.3 |
| Unikanie zamiatania (tylko pierwsze 800 zapytań, niezależnie od złożoności) | 41.7 | 5.5 | 40.5 | 5,4 |
| Tylko zapytania AggregatingSubtotals (łącznie 178 — co pozwala uniknąć zamiatania) | 39.5 | 4.5 | 38.1 | 4.6 |
Wszystkie czasy w sekundach.
Moralne — podczas wykonywania wielu odrębnych zapytań (na przykład dynamicznie tworzonych zapytań) buforowanie nie pomaga, a wynikowe opróżnianie pamięci podręcznej może zachować zapytania, które najbardziej skorzystają z buforowania planu z rzeczywistego użycia.
Zapytania AggregatingSubtotals to najbardziej złożone zapytania, z których testowaliśmy. Zgodnie z oczekiwaniami tym bardziej złożone jest zapytanie, tym większa korzyść wynika z buforowania planu zapytania.
Ponieważ zapytanie CompiledQuery jest naprawdę zapytaniem LINQ z buforowanym planem, porównanie zapytania CompiledQuery w porównaniu z równoważnym zapytaniem Entity SQL powinno mieć podobne wyniki. W rzeczywistości, jeśli aplikacja ma wiele dynamicznych zapytań ENTITY SQL, wypełnianie pamięci podręcznej zapytaniami spowoduje również, że kompilowanequery będą "dekompilowane", gdy zostaną opróżnione z pamięci podręcznej. W tym scenariuszu wydajność może zostać ulepszona przez wyłączenie buforowania w zapytaniach dynamicznych w celu nadania priorytetów kompilowanym zapytaniom. Oczywiście lepszym rozwiązaniem byłoby ponowne zapisywanie aplikacji w celu używania zapytań sparametryzowanych zamiast zapytań dynamicznych.
3.3 Używanie kompilowanego zapytania w celu zwiększenia wydajności zapytań LINQ
Nasze testy wskazują, że użycie funkcji CompiledQuery może przynieść korzyść 7% w porównaniu z autokompilowanymi zapytaniami LINQ; Oznacza to, że będziesz poświęcać 7% mniej czasu na wykonywanie kodu ze stosu programu Entity Framework; Nie oznacza to, że aplikacja będzie 7% szybsza. Mówiąc ogólnie, koszt pisania i obsługi obiektów CompiledQuery w programie EF 5.0 może nie być wart problemu w porównaniu z korzyściami. Przebieg może się różnić, więc przećwiczyć tę opcję, jeśli projekt wymaga dodatkowego wypchnięcia. Należy pamiętać, że funkcja CompiledQueries jest zgodna tylko z modelami pochodnymi objectContext i nie jest zgodna z modelami pochodnymi dbContext.
Aby uzyskać więcej informacji na temat tworzenia i wywoływania kompilowanego zapytania, zobacz Kompilowane zapytania (LINQ to Entities).
Istnieją dwie kwestie, które należy wziąć pod uwagę podczas korzystania z zapytania kompilowanego, a mianowicie wymagania dotyczące używania wystąpień statycznych i problemów, które mają z kompilatorem. Poniżej przedstawiono szczegółowe wyjaśnienie tych dwóch zagadnień.
3.3.1 Używanie statycznych wystąpień compiledQuery
Ponieważ kompilowanie zapytania LINQ jest czasochłonnym procesem, nie chcemy tego robić za każdym razem, gdy musimy pobrać dane z bazy danych. Wystąpienia compiledQuery umożliwiają kompilowanie raz i uruchamianie wiele razy, ale należy zachować ostrożność i ponownie użyć tego samego wystąpienia CompiledQuery za każdym razem, zamiast kompilować je ponownie. Użycie statycznych elementów członkowskich do przechowywania wystąpień CompiledQuery staje się konieczne; w przeciwnym razie nie zobaczysz żadnych korzyści.
Załóżmy na przykład, że strona ma następującą treść metody do obsługi wyświetlania produktów dla wybranej kategorii:
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
W takim przypadku utworzysz nowe wystąpienie CompiledQuery na bieżąco za każdym razem, gdy metoda zostanie wywołana. Zamiast widzieć korzyści z wydajności przez pobranie polecenia magazynu z pamięci podręcznej planu zapytania, kompilator CompiledQuery przejdzie przez kompilator planu za każdym razem, gdy zostanie utworzone nowe wystąpienie. W rzeczywistości pamięć podręczna planu zapytań będzie zanieczyszczana przy użyciu nowego wpisu CompiledQuery za każdym razem, gdy metoda jest wywoływana.
Zamiast tego chcesz utworzyć statyczne wystąpienie skompilowanego zapytania, więc wywoływanie tego samego skompilowanego zapytania jest wywoływane za każdym razem, gdy metoda jest wywoływana. Jednym ze sposobów jest dodanie wystąpienia CompiledQuery jako elementu członkowskiego kontekstu obiektu. Następnie możesz zrobić coś bardziej czystszego, korzystając z metody compiledQuery za pomocą metody pomocniczej:
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
Ta metoda pomocnika zostanie wywołana w następujący sposób:
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Tworzenie kompilowanego zapytania
Możliwość tworzenia dowolnego zapytania LINQ jest niezwykle przydatna; w tym celu po prostu wywołaj metodę po zapytaniu, na przykład Skip() lub Count().. Jednak zasadniczo zwraca nowy obiekt IQueryable. Chociaż nie ma nic, aby technicznie przestać kompilować kompilowane zapytanie, spowoduje to wygenerowanie nowego obiektu IQueryable, który wymaga ponownego przejścia przez kompilator planu.
Niektóre składniki będą korzystać z złożonych obiektów IQueryable w celu włączenia zaawansowanych funkcji. Na przykład element GridView platformy ASP.NET może być powiązany z obiektem IQueryable za pośrednictwem właściwości SelectMethod. Następnie kontrolka GridView utworzy obiekt IQueryable, aby umożliwić sortowanie i stronicowanie modelu danych. Jak widać, użycie skompilowanego zapytania dla kontrolki GridView nie spowoduje trafienia w skompilowane zapytanie, ale wygeneruje nowe autokompilowane zapytanie.
Jednym z miejsc, w których można to napotkać, jest dodanie filtrów progresywnych do zapytania. Załóżmy na przykład, że masz stronę Klienci z kilkoma listami rozwijanymi dla opcjonalnych filtrów (na przykład Country i OrdersCount). Te filtry można tworzyć w wynikach zapytania IQueryable, ale spowoduje to przejście przez kompilator planu za każdym razem, gdy go wykonasz.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Aby uniknąć ponownej kompilacji, możesz ponownie napisać kompilowane zapytanie, aby uwzględnić możliwe filtry:
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
Które wywołano w interfejsie użytkownika, na przykład:
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Tutaj kompromis polega na tym, że wygenerowane polecenie magazynu zawsze będzie mieć filtry z sprawdzaniem wartości null, ale powinny one być dość proste dla serwera bazy danych w celu optymalizacji:
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 Buforowanie metadanych
Program Entity Framework obsługuje również buforowanie metadanych. Jest to zasadniczo buforowanie informacji o typie i mapowaniu typu do bazy danych między różnymi połączeniami z tym samym modelem. Pamięć podręczna metadanych jest unikatowa dla elementu AppDomain.
3.4.1 Algorytm Buforowanie metadanych
Informacje o metadanych modelu są przechowywane w kolekcji ItemCollection dla każdej jednostki Połączenie ion.
- Zwróć uwagę na to, że istnieją różne obiekty ItemCollection dla różnych części modelu. Na przykład StoreItemCollections zawiera informacje o modelu bazy danych; ObjectItemCollection zawiera informacje o modelu danych; Obiekt EdmItemCollection zawiera informacje o modelu koncepcyjnym.
Jeśli dwa połączenia używają tego samego parametry połączenia, będą współużytkują to samo wystąpienie ItemCollection.
Równoważna funkcjonalnie, ale tekstowo inna parametry połączenia może spowodować powstanie różnych pamięci podręcznych metadanych. Tokenizujemy parametry połączenia, więc po prostu zmiana kolejności tokenów powinna spowodować udostępnienie metadanych. Ale dwa parametry połączenia, które wydają się funkcjonalnie takie same, mogą nie być oceniane jako identyczne po tokenizacji.
Element ItemCollection jest okresowo sprawdzany pod kątem użycia. Jeśli okaże się, że obszar roboczy nie został ostatnio uzyskiwany, zostanie oznaczony do oczyszczenia podczas następnego zamiatania pamięci podręcznej.
Jedynie utworzenie jednostki Połączenie ion spowoduje utworzenie pamięci podręcznej metadanych (choć kolekcje elementów w niej nie zostaną zainicjowane do momentu otwarcia połączenia). Ten obszar roboczy pozostanie w pamięci, dopóki algorytm buforowania nie określi, że nie jest używany.
Zespół doradczy ds. klientów napisał wpis w blogu, w którym opisano przechowywanie odwołania do elementu ItemCollection w celu uniknięcia "wycofywania" w przypadku korzystania z dużych modeli: <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>.
3.4.2 Relacja między Buforowanie metadanych a planem zapytania Buforowanie
Wystąpienie pamięci podręcznej planu zapytania znajduje się w kolekcji ItemCollection elementu MetadataWorkspace typów magazynów. Oznacza to, że buforowane polecenia magazynu będą używane do wykonywania zapytań względem dowolnego kontekstu utworzonego przy użyciu danego elementu MetadataWorkspace. Oznacza to również, że jeśli masz dwa parametry połączeń, które są nieco inne i nie są zgodne po tokenizowaniu, będziesz mieć różne wystąpienia pamięci podręcznej planu zapytań.
3.5 Buforowanie wyników
Dzięki buforowaniu wyników (nazywanej również buforowaniem drugiego poziomu) wyniki zapytań są przechowywane w lokalnej pamięci podręcznej. Podczas wykonywania zapytania najpierw sprawdź, czy wyniki są dostępne lokalnie przed wykonaniem zapytania względem magazynu. Buforowanie wyników nie jest obsługiwane bezpośrednio przez program Entity Framework, ale można dodać pamięć podręczną drugiego poziomu przy użyciu dostawcy opakowującego. Przykładem dostawcy opakowującego pamięć podręczną drugiego poziomu jest pamięć podręczna platformy Entity Framework drugiego poziomu firmy Alachisoft oparta na usłudze NCache.
Ta implementacja buforowania drugiego poziomu jest funkcją wstrzykniętą, która odbywa się po ocenie wyrażenia LINQ (i funcletized), a plan wykonywania zapytań jest obliczany lub pobierany z pamięci podręcznej pierwszego poziomu. Pamięć podręczna drugiego poziomu będzie przechowywać tylko nieprzetworzone wyniki bazy danych, więc potok materializacji będzie nadal wykonywany później.
3.5.1 Dodatkowe odwołania do buforowania wyników za pomocą dostawcy opakowującego
- Julie Lerman napisał artykuł MSDN "Second-Level Buforowanie in Entity Framework and Windows Azure" (Drugi poziom Buforowanie w programach Entity Framework i Windows Azure), który zawiera informacje na temat aktualizowania przykładowego dostawcy opakowującego w celu korzystania z buforowania appfabric systemu Windows Server:https://msdn.microsoft.com/magazine/hh394143.aspx
- Jeśli pracujesz z programem Entity Framework 5, blog zespołu zawiera wpis opisujący sposób uruchamiania elementów za pomocą dostawcy buforowania dla programu Entity Framework 5: <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>. Zawiera również szablon T4, który ułatwia automatyzację dodawania buforowania drugiego poziomu do projektu.
4 automatycznie skompilowane zapytania
Gdy zapytanie jest wystawiane względem bazy danych przy użyciu programu Entity Framework, musi przejść przez serię kroków, zanim faktycznie zmaterializują wyniki; jednym z takich kroków jest kompilacja zapytań. Zapytania Entity SQL były znane z dobrej wydajności, ponieważ są automatycznie buforowane, więc drugi lub trzeci raz wykonasz to samo zapytanie, które może pominąć kompilator planu i zamiast tego użyć buforowanego planu.
Program Entity Framework 5 wprowadził automatyczne buforowanie dla zapytań LINQ to Entities. W poprzednich wersjach programu Entity Framework tworzących zapytanie skompilowane w celu przyspieszenia wydajności była powszechna praktyka, ponieważ spowodowałoby to możliwość buforowania zapytań LINQ to Entities. Ponieważ buforowanie jest teraz wykonywane automatycznie bez użycia kompilowanego zapytania, nazywamy tę funkcję "zapytaniami autokompilowanymi". Aby uzyskać więcej informacji na temat pamięci podręcznej planu zapytań i jego mechaniki, zobacz Plan zapytań Buforowanie.
Program Entity Framework wykrywa, kiedy zapytanie wymaga ponownego skompilowania i robi to, gdy zapytanie jest wywoływane, nawet jeśli zostało skompilowane wcześniej. Typowe warunki, które powodują ponowne skompilowane zapytanie, to:
- Zmiana opcji MergeOption skojarzonej z zapytaniem. Nie będzie używane buforowane zapytanie, a zamiast tego kompilator planu zostanie uruchomiony ponownie, a nowo utworzony plan zostanie buforowany.
- Zmiana wartości ContextOptions.UseCSharpNullComparisonBehavior. Uzyskasz taki sam efekt, jak zmiana scalaniaOption.
Inne warunki mogą uniemożliwić korzystanie z pamięci podręcznej przez zapytanie. Typowe przykłady:
- Przy użyciu funkcji IEnumerable<T>. Contains<>(wartość T).
- Korzystanie z funkcji tworzących zapytania ze stałymi.
- Używanie właściwości obiektu niemapowanego.
- Łączenie zapytania z innym zapytaniem, które wymaga ponownego skompilowania.
4.1 Przy użyciu funkcji Ienumerable<T>. Zawiera<wartość T>(T)
Program Entity Framework nie buforuje zapytań, które wywołują IEnumerable<T>. Zawiera<wartość T>(T) względem kolekcji w pamięci, ponieważ wartości kolekcji są uznawane za nietrwałe. Następujące przykładowe zapytanie nie będzie buforowane, więc zawsze będzie przetwarzane przez kompilator planu:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Należy pamiętać, że rozmiar elementu IEnumerable, względem którego funkcja Contains jest wykonywana, określa szybkość lub szybkość kompilowania zapytania. Wydajność może znacznie ucierpieć w przypadku korzystania z dużych kolekcji, takich jak ta pokazana w powyższym przykładzie.
Program Entity Framework 6 zawiera optymalizacje sposobu IEnumerable<T>. Funkcja Zawiera<wartość T>(T) działa po wykonaniu zapytań. Wygenerowany kod SQL jest znacznie szybszy do tworzenia i bardziej czytelny, a w większości przypadków jest również wykonywany szybciej na serwerze.
4.2 Używanie funkcji tworzących zapytania ze stałymi
Operatory Skip(), Take(), Contains() i DefautIfEmpty() LINQ nie generują zapytań SQL z parametrami, ale zamiast tego umieszczają wartości przekazane do nich jako stałe. W związku z tym zapytania, które w przeciwnym razie mogą być identyczne, powodują zanieczyszczanie pamięci podręcznej planu zapytań, zarówno na stosie EF, jak i na serwerze bazy danych, i nie są ponownie wykorzystywane, chyba że te same stałe są używane w kolejnym wykonaniu zapytania. Przykład:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
W tym przykładzie za każdym razem, gdy to zapytanie jest wykonywane z inną wartością identyfikatora, zapytanie zostanie skompilowane w nowym planie.
W szczególności należy zwrócić uwagę na użycie funkcji Pomijanie i wykonywanie podczas stronicowania. W programie EF6 te metody mają przeciążenie lambda, które skutecznie sprawia, że buforowany plan zapytań może być wielokrotnego użytku, ponieważ program EF może przechwytywać zmienne przekazywane do tych metod i tłumaczyć je na parametry SQLparametry. Pomaga to również zachować czyszczenie pamięci podręcznej, ponieważ w przeciwnym razie każde zapytanie o innej stałej dla pozycji Pomiń i Pobierz otrzyma własny wpis pamięci podręcznej planu zapytania.
Rozważ następujący kod, który jest nieoptymalny, ale ma na celu jedynie przykład tej klasy zapytań:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Szybsza wersja tego samego kodu wymaga wywołania metody Skip z lambda:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Drugi fragment kodu może działać do 11% szybciej, ponieważ ten sam plan zapytania jest używany za każdym razem, gdy zapytanie jest uruchamiane, co pozwala zaoszczędzić czas procesora CPU i uniknąć zanieczyszczania pamięci podręcznej zapytań. Ponadto, ponieważ parametr Skip znajduje się w zamknięciu, kod może również wyglądać następująco:
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Używanie właściwości obiektu niemapowanego
Gdy zapytanie używa właściwości niemapowanego typu obiektu jako parametru, zapytanie nie zostanie buforowane. Przykład:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
W tym przykładzie przyjęto założenie, że klasa NonMappedType nie jest częścią modelu jednostki. To zapytanie można łatwo zmienić, aby nie używać typu niemapowanego, a zamiast tego użyć zmiennej lokalnej jako parametru do zapytania:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
W takim przypadku zapytanie będzie mogło zostać zapisane w pamięci podręcznej i będzie korzystać z pamięci podręcznej planu zapytania.
4.4 Łączenie z zapytaniami, które wymagają ponownej kompilacji
W tym samym przykładzie co powyżej, jeśli masz drugie zapytanie, które opiera się na zapytaniu, które musi zostać ponownie skompilowane, całe drugie zapytanie również zostanie ponownie skompilowane. Oto przykład ilustrowania tego scenariusza:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
Przykład jest ogólny, ale ilustruje, w jaki sposób łączenie z pierwszym zapytaniem powoduje, że drugie zapytanie nie może zostać zapisane w pamięci podręcznej. Gdyby zapytanie firstQuery nie było zapytaniem, które wymaga ponownego skompilowania, zapytanie secondQuery byłoby buforowane.
5 Kwerendy NoTracking
5.1 Wyłączanie śledzenia zmian w celu zmniejszenia obciążenia związanego z zarządzaniem stanem
Jeśli pracujesz w scenariuszu tylko do odczytu i chcesz uniknąć obciążenia związanego z ładowaniem obiektów do obiektu ObjectStateManager, możesz wydać zapytania "Brak śledzenia". Śledzenie zmian można wyłączyć na poziomie zapytania.
Należy jednak pamiętać, że wyłączenie śledzenia zmian powoduje efektywne wyłączenie pamięci podręcznej obiektów. Podczas wykonywania zapytań dotyczących jednostki nie można pominąć materializacji, ściągając wcześniej zmaterializowane wyniki zapytania z obiektu ObjectStateManager. Jeśli wielokrotnie wykonujesz zapytania dotyczące tych samych jednostek w tym samym kontekście, możesz zobaczyć, że wydajność może przynieść korzyści z włączenia śledzenia zmian.
Podczas wykonywania zapytań przy użyciu obiektu ObjectContext wystąpienia ObjectQuery i ObjectSet zapamiętują klasę MergeOption po jej ustawieniu, a zapytania, które składają się na nich, będą dziedziczyć obowiązującą metodę MergeOption zapytania nadrzędnego. W przypadku korzystania z elementu DbContext śledzenie można wyłączyć, wywołując modyfikator AsNoTracking() w zestawie dbSet.
5.1.1 Wyłączanie śledzenia zmian dla zapytania podczas korzystania z elementu DbContext
Tryb zapytania można przełączyć na wartość NoTracking, łącząc wywołanie metody AsNoTracking() w zapytaniu. W przeciwieństwie do obiektu ObjectQuery klasy DbSet i DbQuery w interfejsie API DbContext nie mają właściwości modyfikowalnej dla klasy MergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Wyłączanie śledzenia zmian na poziomie zapytania przy użyciu obiektuContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Wyłączanie śledzenia zmian dla całego zestawu jednostek przy użyciu obiektuContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Metryki testowe przedstawiające korzyść wydajności zapytań NoTracking
W tym teście przyjrzymy się kosztowi wypełnienia obiektu ObjectStateManager, porównując śledzenie z zapytaniami NoTracking dla modelu Navision. Zobacz dodatek, aby zapoznać się z opisem modelu Navision i typami zapytań, które zostały wykonane. W tym teście wykonujemy iterowanie po liście zapytań i wykonywanie każdego z nich raz. Uruchomiliśmy dwie odmiany testu, raz z zapytaniami NoTracking i raz z domyślną opcją scalania "AppendOnly". Uruchamialiśmy każdą odmianę 3 razy i bierzemy średnią wartość przebiegów. Między testami wyczyścimy pamięć podręczną zapytań w programie SQL Server i zmniejszymy bazę danych tempdb, uruchamiając następujące polecenia:
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE (tempdb, 0)
Wyniki testów, mediana ponad 3 przebiegów:
| BRAK ŚLEDZENIA — ZESTAW ROBOCZY | BRAK ŚLEDZENIA — CZAS | TYLKO DOŁĄCZANIE — ZESTAW ROBOCZY | TYLKO DOŁĄCZANIE — CZAS | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536 ms | 596545536 | 1273042 ms |
| Entity Framework 6 | 647127040 | 190228 ms | 832798720 | 195521 ms |
Program Entity Framework 5 będzie miał mniejsze zużycie pamięci na końcu działania niż program Entity Framework 6. Dodatkowa pamięć zużywana przez program Entity Framework 6 jest wynikiem dodatkowych struktur pamięci i kodu, które umożliwiają korzystanie z nowych funkcji i lepszej wydajności.
Istnieje również wyraźna różnica w rozmiarze pamięci podczas korzystania z obiektu ObjectStateManager. Program Entity Framework 5 zwiększył swój ślad o 30% podczas śledzenia wszystkich jednostek, które zmaterializowaliśmy z bazy danych. Program Entity Framework 6 zwiększył swój ślad o 28% w tym przypadku.
Jeśli chodzi o czas, program Entity Framework 6 przewyższa program Entity Framework 5 w tym teście o duży margines. Program Entity Framework 6 ukończył test w około 16% czasu zużywanego przez program Entity Framework 5. Ponadto program Entity Framework 5 zajmuje 9% więcej czasu na ukończenie procesu użycia obiektu ObjectStateManager. Dla porównania program Entity Framework 6 używa 3% więcej czasu podczas korzystania z objectStateManager.
6 Opcje wykonywania zapytań
Platforma Entity Framework oferuje kilka różnych sposobów wykonywania zapytań. Przyjrzymy się następującym opcjom, porównamy zalety i wady każdej z nich oraz przeanalizujemy ich charakterystykę wydajności:
- LINQ to Entities.
- Brak śledzenia LINQ to Entities.
- Jednostka SQL w trybie ObjectQuery.
- Jednostka SQL za pośrednictwem polecenia EntityCommand.
- ExecuteStoreQuery.
- SqlQuery.
- Kompilowane zapytanie.
6.1 Zapytania LINQ to Entities
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Zalety
- Nadaje się do obsługi operacji CUD.
- W pełni zmaterializowane obiekty.
- Najprostsze pisanie przy użyciu składni wbudowanej w język programowania.
- Dobra wydajność.
Wady
- Niektóre ograniczenia techniczne, takie jak:
- Wzorce używające elementu DefaultIfEmpty dla zapytań OUTER JOIN powodują bardziej złożone zapytania niż proste instrukcje OUTER JOIN w jednostce SQL.
- Nadal nie można używać funkcji LIKE z ogólnym dopasowaniem wzorca.
6.2 Brak śledzenia zapytań LINQ to Entities
Gdy kontekst pochodzi z obiektu ObjectContext:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Gdy kontekst pochodzi z elementu DbContext:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Zalety
- Zwiększona wydajność w przypadku zwykłych zapytań LINQ.
- W pełni zmaterializowane obiekty.
- Najprostsze pisanie przy użyciu składni wbudowanej w język programowania.
Wady
- Nie nadaje się do obsługi operacji CUD.
- Niektóre ograniczenia techniczne, takie jak:
- Wzorce używające elementu DefaultIfEmpty dla zapytań OUTER JOIN powodują bardziej złożone zapytania niż proste instrukcje OUTER JOIN w jednostce SQL.
- Nadal nie można używać funkcji LIKE z ogólnym dopasowaniem wzorca.
Należy pamiętać, że zapytania dotyczące właściwości skalarnych projektu nie są śledzone, nawet jeśli nie określono parametru NoTracking. Przykład:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
To konkretne zapytanie nie określa jawnie wartości NoTracking, ale ponieważ nie materializuje typu znanego menedżerowi stanu obiektu, wynik zmaterializowany nie jest śledzony.
6.3 Jednostka SQL w trybie ObjectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Zalety
- Nadaje się do obsługi operacji CUD.
- W pełni zmaterializowane obiekty.
- Obsługuje buforowanie planu zapytania.
Wady
- Obejmuje ciągi zapytania tekstowego, które są bardziej podatne na błąd użytkownika niż konstrukcje zapytań wbudowane w język.
6.4 Jednostka SQL za pomocą polecenia jednostki
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Zalety
- Obsługuje buforowanie planu zapytań na platformie .NET 4.0 (buforowanie planu jest obsługiwane przez wszystkie inne typy zapytań na platformie .NET 4.5).
Wady
- Obejmuje ciągi zapytania tekstowego, które są bardziej podatne na błąd użytkownika niż konstrukcje zapytań wbudowane w język.
- Nie nadaje się do obsługi operacji CUD.
- Wyniki nie są automatycznie zmaterializowane i muszą być odczytywane z czytnika danych.
6.5 SqlQuery i ExecuteStoreQuery
Zapytanie sql w bazie danych:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
Zapytanie Sql w bazie danych DbSet:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Zalety
- Ogólnie najszybsza wydajność, ponieważ kompilator planu jest pomijany.
- W pełni zmaterializowane obiekty.
- Nadaje się do wykonywania operacji CUD w przypadku użycia z zestawu dbSet.
Wady
- Zapytanie jest tekstowe i podatne na błędy.
- Zapytanie jest powiązane z określonym zapleczem przy użyciu semantyki magazynu zamiast semantyki koncepcyjnej.
- Gdy dziedziczenie jest obecne, ręcznie wykonane zapytanie musi uwzględniać warunki mapowania żądanego typu.
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Zalety
- Zapewnia maksymalnie 7% poprawę wydajności w porównaniu z regularnymi zapytaniami LINQ.
- W pełni zmaterializowane obiekty.
- Nadaje się do obsługi operacji CUD.
Wady
- Zwiększona złożoność i nakład pracy programistycznej.
- Poprawa wydajności zostanie utracona podczas kompilowania skompilowanego zapytania.
- Niektóre zapytania LINQ nie mogą być zapisywane jako kompilowane zapytanie — na przykład projekcje typów anonimowych.
6.7 Porównanie wydajności różnych opcji zapytania
Proste mikrobenchmarki, w których tworzenie kontekstu nie zostało wprowadzone do testu. Mierzyliśmy zapytania 5000 razy dla zestawu niebuforowanych jednostek w kontrolowanym środowisku. Te liczby mają zostać wykonane z ostrzeżeniem: nie odzwierciedlają rzeczywistych liczb generowanych przez aplikację, ale zamiast tego są one bardzo dokładnym pomiarem, ile różnicy wydajności występuje, gdy różne opcje zapytań są porównywane apples-to-apples, z wyłączeniem kosztów tworzenia nowego kontekstu.
| EF | Przetestuj | Czas (ms) | Pamięć |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | Zapytanie Linq ObjectContext | 2692 | 38277120 |
| EF5 | DbContext Linq Query No Tracking | 2818 | 41840640 |
| EF5 | Zapytanie DbContext Linq | 2930 | 41771008 |
| EF5 | ObjectContext Linq Query No Tracking | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | Zapytanie Linq ObjectContext | 3074 | 45248512 |
| EF6 | DbContext Linq Query No Tracking | 3125 | 47575040 |
| EF6 | Zapytanie DbContext Linq | 3420 | 47652864 |
| EF6 | ObjectContext Linq Query No Tracking | 3593 | 45260800 |
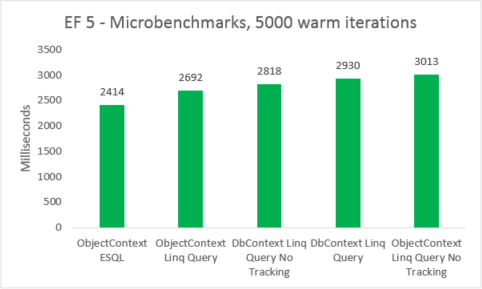
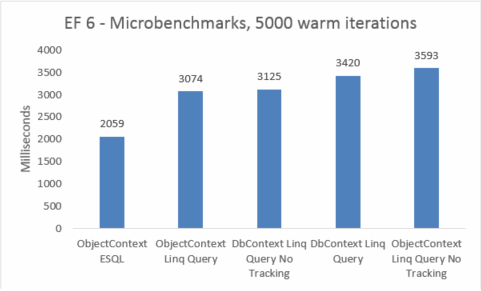
Mikrobenchmarki są bardzo wrażliwe na małe zmiany w kodzie. W tym przypadku różnica między kosztami programu Entity Framework 5 i Entity Framework 6 wynika z dodawania ulepszeń przechwytywania i transakcji. Te liczby mikrobenchmarków są jednak wzmocnioną wizją w bardzo mały fragment tego, co robi platforma Entity Framework. Rzeczywiste scenariusze ciepłych zapytań nie powinny widzieć regresji wydajności podczas uaktualniania z programu Entity Framework 5 do programu Entity Framework 6.
Aby porównać rzeczywistą wydajność różnych opcji zapytania, utworzyliśmy 5 oddzielnych odmian testowych, w których używamy innej opcji zapytania, aby wybrać wszystkie produkty, których nazwa kategorii to "Napoje". Każda iteracja obejmuje koszt tworzenia kontekstu oraz koszt materializowania wszystkich zwracanych jednostek. 10 iteracji jest uruchamianych w czasie przed wykonaniem sumy 1000 iteracji czasowych. Wyświetlane wyniki to mediana przebiegu pobrana z 5 przebiegów każdego testu. Aby uzyskać więcej informacji, zobacz Dodatek B zawierający kod testu.
| EF | Przetestuj | Czas (ms) | Pamięć |
|---|---|---|---|
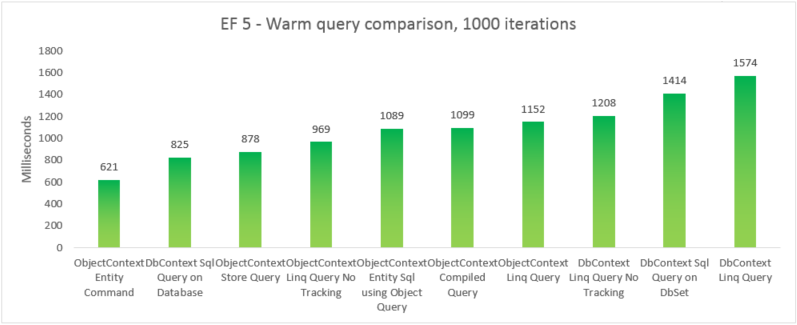
| EF5 | ObjectContext Entity , polecenie | 621 | 39350272 |
| EF5 | DbContext Sql Query on Database | 825 | 37519360 |
| EF5 | Zapytanie magazynu obiektówContext | 878 | 39460864 |
| EF5 | ObjectContext Linq Query No Tracking | 969 | 38293504 |
| EF5 | ObjectContext Entity Sql using Object Query | 1089 | 38981632 |
| EF5 | Zapytanie skompilowane objectContext | 1099 | 38682624 |
| EF5 | Zapytanie Linq ObjectContext | 1152 | 38178816 |
| EF5 | DbContext Linq Query No Tracking | 1208 | 41803776 |
| EF5 | DbContext Sql Query on DbSet | 1414 | 37982208 |
| EF5 | Zapytanie DbContext Linq | 1574 | 41738240 |
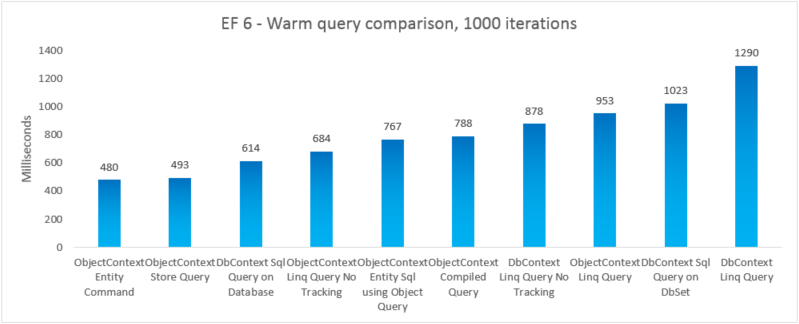
| EF6 | ObjectContext Entity , polecenie | 480 | 47247360 |
| EF6 | Zapytanie magazynu obiektówContext | 493 | 46739456 |
| EF6 | DbContext Sql Query on Database | 614 | 41607168 |
| EF6 | ObjectContext Linq Query No Tracking | 684 | 46333952 |
| EF6 | ObjectContext Entity Sql using Object Query | 767 | 48865280 |
| EF6 | Zapytanie skompilowane objectContext | 788 | 48467968 |
| EF6 | DbContext Linq Query No Tracking | 878 | 47554560 |
| EF6 | Zapytanie Linq ObjectContext | 953 | 47632384 |
| EF6 | DbContext Sql Query on DbSet | 1023 | 41992192 |
| EF6 | Zapytanie DbContext Linq | 1290 | 47529984 |
Uwaga
Aby uzyskać kompletność, dołączyliśmy odmianę, w której wykonujemy zapytanie Entity SQL w jednostce EntityCommand. Jednak ponieważ wyniki nie są zmaterializowane dla takich zapytań, porównanie niekoniecznie apples-to-apples. Test zawiera bliskie przybliżenie materializowania, aby spróbować zrobić porównanie sprawiedliwsze.
W tym przypadku end-to-end program Entity Framework 6 przewyższa program Entity Framework 5 ze względu na ulepszenia wydajności wprowadzone w kilku częściach stosu, w tym znacznie lżejsze inicjowanie DbContext i szybsze wyszukiwania MetadataCollection<T> .
7 Zagadnienia dotyczące wydajności czasu projektowania
7.1 Strategie dziedziczenia
Kolejną kwestią do rozważenia podczas korzystania z programu Entity Framework jest strategia dziedziczenia, której używasz. Program Entity Framework obsługuje 3 podstawowe typy dziedziczenia i ich kombinacje:
- Tabela na hierarchię (TPH) — gdzie każdy zestaw dziedziczenia mapuje tabelę z dyskryminującą kolumną, aby wskazać, który konkretny typ w hierarchii jest reprezentowany w wierszu.
- Tabela na typ (TPT) — gdzie każdy typ ma własną tabelę w bazie danych; tabele podrzędne definiują tylko kolumny, których tabela nadrzędna nie zawiera.
- Tabela na klasę (TPC) — gdzie każdy typ ma własną pełną tabelę w bazie danych; tabele podrzędne definiują wszystkie pola, w tym te zdefiniowane w typach nadrzędnych.
Jeśli model używa dziedziczenia TPT, wygenerowane zapytania będą bardziej złożone niż te, które są generowane przy użyciu innych strategii dziedziczenia, co może spowodować dłuższy czas wykonywania w magazynie. Generowanie zapytań w modelu TPT i materializowanie wynikowych obiektów zwykle trwa dłużej.
Zobacz wpis w blogu MSDN "Zagadnienia dotyczące wydajności podczas korzystania z dziedziczenia TPT (tabela na typ) w witrynie Entity Framework: <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>.
7.1.1 Unikanie TPT w aplikacjach Model First lub Code First
Podczas tworzenia modelu na istniejącej bazie danych, która ma schemat TPT, nie masz wielu opcji. Jednak podczas tworzenia aplikacji przy użyciu modelu First lub Code First należy unikać dziedziczenia TPT w przypadku problemów z wydajnością.
Jeśli używasz metody Model First w Kreatorze Projektant jednostki, otrzymasz TPT dla dowolnego dziedziczenia w modelu. Jeśli chcesz przełączyć się na strategię dziedziczenia TPH za pomocą funkcji Model First, możesz użyć opcji "Entity Projektant Database Generation Power Pack" dostępnej w galerii programu Visual Studio ( <http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>).
W przypadku używania funkcji Code First do skonfigurowania mapowania modelu z dziedziczeniem program EF będzie domyślnie używać funkcji TPH, dlatego wszystkie jednostki w hierarchii dziedziczenia będą mapowane na tę samą tabelę. Aby uzyskać więcej szczegółów, zobacz sekcję "Mapowanie za pomocą interfejsu API Fluent" artykułu "Code First in Entity Framework4.1" ( http://msdn.microsoft.com/magazine/hh126815.aspxMapowanie za pomocą interfejsu API Fluent API).
7.2 Uaktualnianie z programu EF4 w celu poprawy czasu generowania modelu
Ulepszenie specyficzne dla programu SQL Server dla algorytmu, który generuje warstwę magazynu (SSDL) modelu, jest dostępne w programie Entity Framework 5 i 6 oraz jako aktualizacja programu Entity Framework 4 po zainstalowaniu programu Visual Studio 2010 z dodatkiem SP1. Poniższe wyniki testów pokazują poprawę podczas generowania bardzo dużego modelu, w tym przypadku modelu Navision. Zobacz Dodatek C, aby uzyskać więcej informacji na ten temat.
Model zawiera zestawy jednostek 1005 i zestawy skojarzeń 4227.
| Konfigurowanie | Podział czasu zużytego |
|---|---|
| Visual Studio 2010, Entity Framework 4 | Generacja SSDL: 2 godz. 27 min Generowanie mapowania: 1 sekunda Generacja CSDL: 1 sekunda Generacja ObiektuLayer: 1 sekunda Generowanie widoku: 2 godz. 14 min |
| Visual Studio 2010 SP1, Entity Framework 4 | Generacja SSDL: 1 sekunda Generowanie mapowania: 1 sekunda Generacja CSDL: 1 sekunda Generacja ObiektuLayer: 1 sekunda Generowanie widoku: 1 godz. 53 min |
| Visual Studio 2013, Entity Framework 5 | Generacja SSDL: 1 sekunda Generowanie mapowania: 1 sekunda Generacja CSDL: 1 sekunda Generacja ObiektuLayer: 1 sekunda Generowanie widoku: 65 minut |
| Visual Studio 2013, Entity Framework 6 | Generacja SSDL: 1 sekunda Generowanie mapowania: 1 sekunda Generacja CSDL: 1 sekunda Generacja ObiektuLayer: 1 sekunda Generowanie widoku: 28 sekund. |
Warto zauważyć, że podczas generowania dysków SSDL obciążenie jest prawie całkowicie wydawane na program SQL Server, podczas gdy maszyna dewelopera klienta czeka bezczynnie, aby wyniki wróciły z serwera. Administratorzy baz danych powinni szczególnie docenić tę poprawę. Warto również zauważyć, że w tej chwili w obszarze Generowanie widoku odbywa się cały koszt generowania modelu.
7.3 Dzielenie dużych modeli przy użyciu najpierw bazy danych i modelu
W miarę zwiększania rozmiaru modelu powierzchnia projektanta staje się zaśmiecona i trudna do użycia. Zazwyczaj rozważamy model z ponad 300 jednostkami, aby był zbyt duży, aby efektywnie korzystać z projektanta. W poniższym wpisie w blogu opisano kilka opcji dzielenia dużych modeli: <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>.
Wpis został napisany dla pierwszej wersji programu Entity Framework, ale kroki nadal mają zastosowanie.
7.4 Zagadnienia dotyczące wydajności związane z kontrolą źródła danych jednostki
Widzieliśmy przypadki w wielowątowych testach wydajności i obciążeniowych, w których wydajność aplikacji internetowej korzystającej z kontrolki EntityDataSource znacznie się pogarsza. Podstawową przyczyną jest to, że jednostka EntityDataSource wielokrotnie wywołuje element MetadataWorkspace.LoadFromAssembly w zestawach, do których odwołuje się aplikacja internetowa, aby odnaleźć typy, które mają być używane jako jednostki.
Rozwiązaniem jest ustawienie parametru ContextTypeName klasy EntityDataSource na nazwę typu pochodnej klasy ObjectContext. Spowoduje to wyłączenie mechanizmu, który skanuje wszystkie zestawy, do których odwołuje się typ jednostki.
Ustawienie pola ContextTypeName uniemożliwia również problem funkcjonalny polegający na tym, że element EntityDataSource na platformie .NET 4.0 zgłasza błąd Emocje ionTypeLoadException, gdy nie może załadować typu z zestawu za pośrednictwem odbicia. Ten problem został rozwiązany na platformie .NET 4.5.
7.5 Jednostek POCO i serwerów proxy śledzenia zmian
Program Entity Framework umożliwia używanie niestandardowych klas danych wraz z modelem danych bez wprowadzania żadnych modyfikacji samych klas danych. Oznacza to, że można użyć "zwykłych" obiektów CLR (POCO), takich jak istniejące obiekty domeny, z modelem danych. Te klasy danych POCO (znane również jako obiekty bez trwałości), które są mapowane na jednostki zdefiniowane w modelu danych, obsługują większość tych samych zapytań, wstawiania, aktualizowania i usuwania zachowań jako typów jednostek generowanych przez narzędzia modelu danych jednostki.
Program Entity Framework może również tworzyć klasy serwerów proxy pochodzące z typów POCO, które są używane, gdy chcesz włączyć funkcje, takie jak ładowanie z opóźnieniem i automatyczne śledzenie zmian w jednostkach POCO. Klasy POCO muszą spełniać pewne wymagania, aby umożliwić programowi Entity Framework korzystanie z serwerów proxy, zgodnie z opisem w tym miejscu: http://msdn.microsoft.com/library/dd468057.aspx.
Serwery proxy śledzenia szans będą powiadamiać menedżera stanu obiektu za każdym razem, gdy każda z właściwości jednostek uległa zmianie, więc program Entity Framework zna rzeczywisty stan jednostek przez cały czas. Odbywa się to przez dodanie zdarzeń powiadomień do treści metod ustawiania właściwości i przetworzenie takich zdarzeń przez menedżera stanu obiektu. Należy pamiętać, że tworzenie jednostki serwera proxy jest zwykle droższe niż tworzenie jednostki poCO bez serwera proxy ze względu na dodany zestaw zdarzeń utworzonych przez program Entity Framework.
Gdy jednostka POCO nie ma serwera proxy śledzenia zmian, zmiany są znajdowane przez porównanie zawartości jednostek z kopią poprzedniego zapisanego stanu. To głębokie porównanie stanie się długotrwałym procesem, gdy masz wiele jednostek w kontekście lub gdy jednostki mają bardzo dużą ilość właściwości, nawet jeśli żadne z nich nie uległo zmianie od czasu ostatniego porównania.
Podsumowując: zapłacisz za wydajność podczas tworzenia serwera proxy śledzenia zmian, ale śledzenie zmian pomoże przyspieszyć proces wykrywania zmian, gdy jednostki mają wiele właściwości lub wiele jednostek w modelu. W przypadku jednostek z niewielką liczbą właściwości, w których ilość jednostek nie zwiększa się zbytnio, posiadanie serwerów proxy śledzenia zmian może nie przynieść dużej korzyści.
8 Ładowanie powiązanych jednostek
8.1 Ładowanie leniwe a ładowanie chętne
Program Entity Framework oferuje kilka różnych sposobów ładowania jednostek powiązanych z jednostką docelową. Na przykład podczas wykonywania zapytań dotyczących produktów istnieją różne sposoby ładowania powiązanych zamówień do Menedżera stanu obiektu. Z punktu widzenia wydajności największym pytaniem, które należy wziąć pod uwagę podczas ładowania powiązanych jednostek, będzie to, czy używać ładowania leniwego, czy chętnego ładowania.
W przypadku korzystania z ładowania chętnego powiązane jednostki są ładowane wraz z zestawem jednostek docelowych. W zapytaniu użyjesz instrukcji Include, aby wskazać powiązane jednostki, które chcesz wprowadzić.
W przypadku korzystania z ładowania z opóźnieniem początkowe zapytanie wprowadza tylko zestaw jednostek docelowych. Jednak za każdym razem, gdy uzyskujesz dostęp do właściwości nawigacji, kolejne zapytanie jest wystawiane względem magazynu w celu załadowania powiązanej jednostki.
Po załadowaniu jednostki wszelkie dalsze zapytania dotyczące jednostki będą ładować je bezpośrednio z Menedżera stanu obiektów, niezależnie od tego, czy używasz leniwego ładowania, czy ładowania z dużym obciążeniem.
8.2 Jak wybrać między ładowaniem leniwym i chętnym ładowaniem
Ważne jest, aby zrozumieć różnicę między ładowaniem leniwym i chętnym ładowaniem, dzięki czemu można dokonać właściwego wyboru dla aplikacji. Pomoże to ocenić kompromis między wieloma żądaniami względem bazy danych a pojedynczym żądaniem, które może zawierać duży ładunek. Może być konieczne użycie chętnego ładowania w niektórych częściach aplikacji i leniwego ładowania w innych częściach.
Jako przykład tego, co dzieje się pod maską, załóżmy, że chcesz wysłać zapytanie do klientów, którzy mieszkają w Wielkiej Brytanii i ich liczby zamówień.
Korzystanie z ładowania chętnego
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Korzystanie z ładowania z opóźnieniem
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
W przypadku korzystania z chętnego ładowania wydasz pojedyncze zapytanie, które zwraca wszystkich klientów i wszystkie zamówienia. Polecenie sklepu wygląda następująco:
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
W przypadku korzystania z ładowania z opóźnieniem początkowo wydasz następujące zapytanie:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
Za każdym razem, gdy uzyskujesz dostęp do właściwości nawigacji Orders klienta innego zapytania, takiego jak następujące, jest wystawiane względem sklepu:
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
Aby uzyskać więcej informacji, zobacz Ładowanie powiązanych obiektów.
8.2.1 Lazy Loading versus Eager Loading ściągawka
Nie ma czegoś takiego jak jeden rozmiar pasuje do wszystkich, aby wybrać chętne ładowanie i leniwe ładowanie. Najpierw spróbuj zrozumieć różnice między obiem strategią, aby móc dobrze poinformować o decyzji; Należy również rozważyć, czy kod pasuje do dowolnego z następujących scenariuszy:
| Scenariusz | Nasza sugestia |
|---|---|
| Czy musisz uzyskać dostęp do wielu właściwości nawigacji z pobranych jednostek? | Nie — obie opcje prawdopodobnie zrobią. Jeśli jednak ładunek, który przynosi zapytanie, nie jest zbyt duży, może wystąpić korzyści z wydajności przy użyciu opcji Ładowanie chętne, ponieważ będzie wymagać mniejszej liczby rund sieci w celu zmaterializowania obiektów. Tak — jeśli musisz uzyskać dostęp do wielu właściwości nawigacji z jednostek, należy to zrobić przy użyciu wielu instrukcji include w zapytaniu z chętnym ładowaniem. Im więcej uwzględnisz jednostek, tym większy ładunek zostanie zwrócony przez zapytanie. Po dołączeniu trzech lub większej liczby jednostek do zapytania rozważ przełączenie na ładowanie z opóźnieniem. |
| Czy wiesz dokładnie, jakie dane będą potrzebne w czasie wykonywania? | Nie - Ładowanie leniwe będzie dla Ciebie lepsze. W przeciwnym razie możesz wykonać zapytanie dotyczące danych, których nie potrzebujesz. Tak — Ładowanie chętne jest prawdopodobnie najlepszym rozwiązaniem. Pomoże to szybciej załadować całe zestawy. Jeśli zapytanie wymaga pobrania bardzo dużej ilości danych i stanie się to zbyt wolne, spróbuj zamiast tego użyć funkcji ładowania z opóźnieniem. |
| Czy kod jest wykonywany daleko od bazy danych? (zwiększone opóźnienie sieci) | Nie — jeśli opóźnienie sieci nie jest problemem, użycie ładowania z opóźnieniem może uprościć kod. Pamiętaj, że topologia aplikacji może ulec zmianie, więc nie należy blisko bazy danych. Tak — gdy sieć jest problemem, tylko ty możesz zdecydować, co lepiej pasuje do danego scenariusza. Zazwyczaj chętne ładowanie będzie lepsze, ponieważ wymaga mniejszej liczby rund. |
8.2.2 Problemy z wydajnością z wieloma elementami Obejmuje
Gdy słyszymy pytania dotyczące wydajności, które obejmują problemy z czasem odpowiedzi serwera, źródłem problemu są często zapytania z wieloma instrukcjami Include. Chociaż uwzględnienie powiązanych jednostek w zapytaniu jest zaawansowane, ważne jest, aby zrozumieć, co dzieje się w ramach okładek.
Wykonywanie zapytania z wieloma instrukcjami Include w nim zajmuje stosunkowo dużo czasu, aby przejść przez nasz kompilator planu wewnętrznego w celu utworzenia polecenia magazynu. Większość tego czasu poświęca się na próbę zoptymalizowania wynikowego zapytania. Wygenerowane polecenie magazynu będzie zawierać sprzężenia zewnętrznego lub unii dla każdego dołączania, w zależności od mapowania. Zapytania takie jak te spowodują wprowadzenie dużych połączonych grafów z bazy danych w jednym ładunku, co spowoduje, że wystąpią problemy z przepustowością, zwłaszcza gdy w ładunku występuje wiele nadmiarowości (na przykład gdy wiele poziomów include jest używanych do przechodzenia skojarzeń w kierunku jeden do wielu).
Możesz sprawdzić przypadki, w których zapytania zwracają zbyt duże ładunki, korzystając z bazowego TSQL dla zapytania przy użyciu funkcji ToTraceString i wykonując polecenie magazynu w programie SQL Server Management Studio, aby wyświetlić rozmiar ładunku. W takich przypadkach możesz spróbować zmniejszyć liczbę instrukcji Include w zapytaniu, aby po prostu wprowadzić potrzebne dane. Możesz też podzielić zapytanie na mniejszą sekwencję podzapytania, na przykład:
Przed przerwaniem zapytania:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Po przerwaniu zapytania:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Będzie to działać tylko w przypadku śledzonych zapytań, ponieważ korzystamy z możliwości, jakie kontekst musi automatycznie wykonywać rozpoznawanie tożsamości i naprawianie skojarzeń.
Podobnie jak w przypadku leniwego ładowania, kompromis będzie bardziej zapytań dotyczących mniejszych ładunków. Można również użyć projekcji poszczególnych właściwości, aby jawnie wybrać tylko potrzebne dane z każdej jednostki, ale w tym przypadku nie będą ładowane jednostki, a aktualizacje nie będą obsługiwane.
8.2.3 Obejście, aby pobrać leniwe ładowanie właściwości
Program Entity Framework obecnie nie obsługuje opóźnionego ładowania właściwości skalarnych ani złożonych. Jednak w przypadkach, gdy masz tabelę zawierającą duży obiekt, taki jak obiekt BLOB, można użyć dzielenia tabeli, aby oddzielić duże właściwości do oddzielnej jednostki. Załóżmy na przykład, że masz tabelę Product zawierającą kolumnę zdjęcia varbinary. Jeśli nie musisz często uzyskiwać dostępu do tej właściwości w zapytaniach, możesz użyć podziału tabeli, aby wprowadzić tylko potrzebne części jednostki. Jednostka reprezentująca zdjęcie produktu zostanie załadowana tylko wtedy, gdy będzie ona jawnie potrzebna.
Dobrym zasobem, który pokazuje, jak włączyć dzielenie tabeli, jest wpis w blogu Gil Fink "Dzielenie tabel w programie Entity Framework": <http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>.
9 Inne zagadnienia
9.1 Odzyskiwanie pamięci serwera
Niektórzy użytkownicy mogą napotkać rywalizację o zasoby, która ogranicza równoległość oczekiwaną, gdy moduł odśmiecania pamięci nie jest prawidłowo skonfigurowany. Zawsze, gdy program EF jest używany w scenariuszu wielowątkowym lub w dowolnej aplikacji podobnej do systemu po stronie serwera, upewnij się, że włączono odzyskiwanie pamięci serwera. Odbywa się to za pomocą prostego ustawienia w pliku konfiguracji aplikacji:
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
Powinno to zmniejszyć rywalizację wątków i zwiększyć przepływność o maksymalnie 30% w scenariuszach nasyconych procesorem CPU. Ogólnie rzecz biorąc, należy zawsze testować zachowanie aplikacji przy użyciu klasycznego odzyskiwania pamięci (lepiej dostosowanego do scenariuszy interfejsu użytkownika i po stronie klienta), a także odzyskiwania pamięci serwera.
9.2 Autowykrywanie zmian
Jak wspomniano wcześniej, program Entity Framework może pokazywać problemy z wydajnością, gdy pamięć podręczna obiektów ma wiele jednostek. Niektóre operacje, takie jak Add, Remove, Find, Entry i SaveChanges, wyzwalają wywołania funkcji DetectChanges, które mogą zużywać dużą ilość procesora CPU na podstawie wielkości pamięci podręcznej obiektów. Przyczyną tego jest to, że pamięć podręczna obiektów i menedżer stanu obiektu starają się pozostać tak zsynchronizowane, jak to możliwe dla każdej operacji wykonanej w kontekście, tak aby wygenerowane dane były poprawne w szerokiej tablicy scenariuszy.
Zazwyczaj dobrym rozwiązaniem jest pozostawienie automatycznego wykrywania zmian w strukturze Entity Framework włączonego dla całej aplikacji. Jeśli twój scenariusz jest negatywnie dotknięty wysokim użyciem procesora CPU, a profile wskazują, że winowajcą jest wywołanie funkcji DetectChanges, rozważ tymczasowe wyłączenie funkcji AutoDetectChanges w poufnej części kodu:
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Przed wyłączeniem funkcji AutoDetectChanges warto zrozumieć, że może to spowodować utratę możliwości śledzenia pewnych informacji o zmianach w jednostkach. W przypadku nieprawidłowej obsługi może to spowodować niespójność danych w aplikacji. Aby uzyskać więcej informacji na temat wyłączania autowykrywania zmian, przeczytaj <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Kontekst na żądanie
Konteksty programu Entity Framework mają być używane jako wystąpienia krótkotrwałe w celu zapewnienia najbardziej optymalnego środowiska wydajności. Oczekuje się, że konteksty będą krótkotrwałe i odrzucane, a w związku z tym zaimplementowano bardzo lekkie i ponownie wykorzystywane metadane, jeśli to możliwe. W scenariuszach internetowych ważne jest, aby pamiętać o tym i nie mieć kontekstu przez więcej niż czas trwania pojedynczego żądania. Podobnie w scenariuszach innych niż sieci Web kontekst powinien zostać odrzucony na podstawie zrozumienia różnych poziomów buforowania w programie Entity Framework. Ogólnie rzecz biorąc, należy unikać wystąpienia kontekstu przez cały okres życia aplikacji, a także kontekstów na wątek i konteksty statyczne.
9.4 Semantyka wartości null bazy danych
Program Entity Framework domyślnie generuje kod SQL, który ma semantyka porównania wartości null języka C#. Rozważ następujące przykładowe zapytanie:
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
W tym przykładzie porównujemy liczbę zmiennych dopuszczających wartość null względem właściwości dopuszczających wartość null w jednostce, takich jak SupplierID i UnitPrice. Wygenerowany język SQL dla tego zapytania będzie pytał, czy wartość parametru jest taka sama jak wartość kolumny, lub czy zarówno parametr, jak i wartości kolumny mają wartość null. Spowoduje to ukrycie sposobu obsługi wartości null przez serwer bazy danych i zapewni spójne środowisko null języka C# u różnych dostawców baz danych. Z drugiej strony wygenerowany kod jest nieco zawiły i może nie działać prawidłowo, gdy ilość porównań w instrukcji where instrukcji zapytania rośnie do dużej liczby.
Jednym ze sposobów radzenia sobie z tą sytuacją jest użycie semantyki o wartości null bazy danych. Należy pamiętać, że może to potencjalnie zachowywać się inaczej niż semantyka null języka C#, ponieważ teraz program Entity Framework wygeneruje prostszy kod SQL, który uwidacznia sposób obsługi wartości null przez aparat bazy danych. Semantyka null bazy danych może być aktywowana dla poszczególnych kontekstów przy użyciu jednego wiersza konfiguracji względem konfiguracji kontekstu:
context.Configuration.UseDatabaseNullSemantics = true;
Zapytania o małych i średnich rozmiarach nie będą wyświetlać zauważalnej poprawy wydajności podczas korzystania z semantyki wartości null bazy danych, ale różnica stanie się bardziej zauważalna w przypadku zapytań z dużą liczbą potencjalnych porównań o wartości null.
W powyższym przykładowym zapytaniu różnica wydajności była mniejsza niż 2% w mikrobenchmarku uruchomionym w kontrolowanym środowisku.
9.5 Async
Program Entity Framework 6 wprowadził obsługę operacji asynchronicznych podczas uruchamiania na platformie .NET 4.5 lub nowszej. W większości aplikacji, które mają rywalizację związaną z operacjami we/wy, najbardziej skorzystają z używania asynchronicznych operacji zapytań i zapisywania. Jeśli aplikacja nie cierpi na rywalizację o operacje we/wy, użycie asynchronicznego działania, w najlepszych przypadkach, uruchomienie synchroniczne i zwrócenie wyniku w tym samym czasie co wywołanie synchroniczne lub w najgorszym przypadku po prostu odroczenie wykonania do zadania asynchronicznego i dodanie dodatkowego czasu do ukończenia scenariusza.
Aby uzyskać informacje na temat sposobu działania programowania asynchronicznego, które pomogą Ci zdecydować, czy asynchroniczna funkcja asynchroniczna poprawi wydajność aplikacji, zobacz Asynchroniczne programowanie za pomocą asynchronicznego i await. Aby uzyskać więcej informacji na temat korzystania z operacji asynchronicznych w programie Entity Framework, zobacz Async Query and Save (Asynchroniczne zapytanie i zapisywanie).
9.6 NGEN
Program Entity Framework 6 nie jest instalowany domyślnie w programie .NET Framework. W związku z tym zestawy Entity Framework nie są domyślnie NGEN, co oznacza, że cały kod programu Entity Framework podlega tym samym kosztom JIT co każdy inny zestaw MSIL. Może to obniżyć wydajność środowiska F5 podczas opracowywania, a także zimnego uruchamiania aplikacji w środowiskach produkcyjnych. Aby zmniejszyć koszty procesora CPU i pamięci JIT,ing zaleca się NGEN obrazy platformy Entity Framework odpowiednio. Aby uzyskać więcej informacji na temat zwiększania wydajności uruchamiania programu Entity Framework 6 za pomocą oprogramowania NGEN, zobacz Poprawianie wydajności uruchamiania za pomocą narzędzia NGen.
9.7 Code First a EDMX
Przyczyny niezgodności impedancji problemu między programowaniem obiektowym i relacyjnymi bazami danych przez przedstawienie w pamięci modelu koncepcyjnego (obiektów), schematu magazynu (bazy danych) i mapowania między nimi. Te metadane są nazywane modelem danych jednostki lub EDM krótko. Na podstawie tego modułu EDM program Entity Framework będzie uzyskiwać widoki umożliwiające zaokrąglanie danych z obiektów w pamięci do bazy danych i z powrotem.
Gdy program Entity Framework jest używany z plikiem EDMX, który formalnie określa model koncepcyjny, schemat magazynu i mapowanie, wówczas etap ładowania modelu musi sprawdzić, czy EDM jest poprawny (na przykład upewnij się, że nie brakuje mapowań), a następnie wygeneruj widoki, a następnie zweryfikuj widoki i przygotuj te metadane do użycia. Tylko wtedy można wykonać zapytanie lub zapisać nowe dane w magazynie danych.
Podejście Code First to zaawansowany generator modelu danych jednostek. Program Entity Framework musi utworzyć moduł EDM z podanego kodu; Robi to, analizując klasy zaangażowane w model, stosując konwencje i konfigurując model za pośrednictwem interfejsu API Fluent. Po utworzeniu programu EDM program Entity Framework zasadniczo zachowuje się tak samo, jak w przypadku wystąpienia pliku EDMX w projekcie. W związku z tym utworzenie modelu z funkcji Code First zwiększa złożoność, która przekłada się na wolniejszy czas uruchamiania dla programu Entity Framework w porównaniu z wersją EDMX. Koszt jest całkowicie zależny od rozmiaru i złożoności tworzonego modelu.
Podczas wybierania opcji EDMX i Code First ważne jest, aby wiedzieć, że elastyczność wprowadzona przez funkcję Code First zwiększa koszt tworzenia modelu po raz pierwszy. Jeśli aplikacja może wytrzymać koszt tego ładowania po raz pierwszy, zazwyczaj kod Pierwszy będzie preferowanym sposobem przejścia.
10 Badanie wydajności
10.1 Korzystanie z profilera programu Visual Studio
Jeśli masz problemy z wydajnością programu Entity Framework, możesz użyć profilera, takiego jak wbudowany w program Visual Studio, aby zobaczyć, gdzie aplikacja spędza czas. To narzędzie zostało użyte do wygenerowania wykresów kołowych w wpisie w blogu "Eksplorowanie wydajności ADO.NET Entity Framework — część 1" ( <https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>) pokazującego, gdzie program Entity Framework spędza czas podczas zimnych i ciepłych zapytań.
Wpis w blogu "Profilowanie struktury Entity Framework przy użyciu profilera programu Visual Studio 2010" napisany przez zespół doradczy ds. danych i modelowania przedstawia rzeczywisty przykład sposobu używania profilera do zbadania problemu z wydajnością. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. Ten wpis został napisany dla aplikacji systemu Windows. Jeśli musisz profilować aplikację internetową, narzędzia Windows Performance Recorder (WPR) i Windows Analizator wydajności (WPA) mogą działać lepiej niż w programie Visual Studio. WPR i WPA są częścią zestawu narzędzi Windows Performance Toolkit, który jest dołączony do zestawu Windows Assessment and Deployment Kit.
10.2 Profilowanie aplikacji/bazy danych
Narzędzia, takie jak profiler wbudowany w program Visual Studio, informują o tym, gdzie twoja aplikacja spędza czas. Dostępny jest inny typ profilera, który wykonuje dynamiczną analizę uruchomionej aplikacji, w środowisku produkcyjnym lub przedprodukcyjnym w zależności od potrzeb i szuka typowych pułapek i wzorców dostępu do bazy danych.
Dwa profilery dostępne komercyjnie to Profiler programu Entity Framework ( <http://efprof.com>) i ORMProfiler ( <http://ormprofiler.com>).
Jeśli aplikacja jest aplikacją MVC korzystającą z funkcji Code First, możesz użyć miniprofilera usługi StackExchange. Scott Hanselman opisuje to narzędzie w swoim blogu pod adresem: <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>.
Aby uzyskać więcej informacji na temat profilowania aktywności bazy danych aplikacji, zobacz artykuł Julie Lerman's MSDN Magazine zatytułowany Profilowanie aktywności bazy danych w programie Entity Framework.
10.3 Rejestrator bazy danych
Jeśli używasz programu Entity Framework 6, rozważ również użycie wbudowanych funkcji rejestrowania. Właściwość Database kontekstu można poinstruować, aby rejestrować jego działanie za pomocą prostej konfiguracji jednowierszowej:
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
W tym przykładzie działanie bazy danych zostanie zarejestrowane w konsoli, ale właściwość Dziennik można skonfigurować tak, aby wywoływać dowolny delegat ciągu> akcji<.
Jeśli chcesz włączyć rejestrowanie bazy danych bez ponownego komplikowania i używasz programu Entity Framework 6.1 lub nowszego, możesz to zrobić, dodając przechwytywanie w pliku web.config lub app.config aplikacji.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
Aby uzyskać więcej informacji na temat dodawania rejestrowania bez ponownego komplikowania, przejdź do strony <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>.
11 Dodatek
11.1 A. Środowisko testowe
To środowisko używa konfiguracji 2-maszynowej z bazą danych na osobnej maszynie od aplikacji klienckiej. Maszyny znajdują się w tym samym stojaku, więc opóźnienie sieci jest stosunkowo niskie, ale bardziej realistyczne niż środowisko pojedynczej maszyny.
11.1.1 Serwer aplikacji
11.1.1.1 Środowisko oprogramowania
- Środowisko programowe programu Entity Framework 4
- Nazwa systemu operacyjnego: Windows Server 2008 R2 Enterprise SP1.
- Visual Studio 2010 — Ultimate.
- Visual Studio 2010 SP1 (tylko w przypadku niektórych porównań).
- Środowisko programowe Entity Framework 5 i 6
- Nazwa systemu operacyjnego: Windows 8.1 Enterprise
- Visual Studio 2013 — Ultimate.
11.1.1.2 Środowisko sprzętowe
- Podwójny procesor: Procesor Intel(R) Xeon(R) CPU L5520 W3530 @ 2,27GHz, 2261 Mhz8 GHz, 4 rdzenie, 84 procesory logiczne.
- 2412 GB pamięci RamRAM.
- 136 GB SCSI250GB dysk SATA 7200 obr./s 3 GB/s podzielony na 4 partycje.
Serwer bazy danych 11.1.2
11.1.2.1 Środowisko oprogramowania
- Nazwa systemu operacyjnego: Windows Server 2008 R28.1 Enterprise SP1.
- SQL Server 2008 R22012.
11.1.2.2 Środowisko sprzętowe
- Pojedynczy procesor: Procesor Intel(R) Xeon(R) CPU L5520 @ 2,27GHz, 2261 MhzES-1620 0 @ 3,60 GHz, 4 rdzenie, 8 procesorów logicznych.
- 824 GB pamięci RamRAM.
- 465 GB ATA500GB dysk SATA 7200 obr./s 6 GB/s podzielony na 4 partycje.
11.2 B. Testy porównania wydajności zapytań
Model Northwind został użyty do wykonania tych testów. Została ona wygenerowana z bazy danych przy użyciu projektanta programu Entity Framework. Następnie do porównania wydajności opcji wykonywania zapytania użyto następującego kodu:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Model Navision
Baza danych Navision to duża baza danych używana do pokazu usługi Microsoft Dynamics — NAV. Wygenerowany model koncepcyjny zawiera zestawy jednostek 1005 i zestawy skojarzeń 4227. Model używany w teście jest "płaski" — nie dodano do niego dziedziczenia.
11.3.1 Zapytania używane na potrzeby testów navision
Lista zapytań używana w modelu Navision zawiera 3 kategorie zapytań Entity SQL:
11.3.1.1 Wyszukiwanie
Proste zapytanie wyszukiwania bez agregacji
- Liczba: 16232
- Przykład:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 Pojedyncze agregowanie
Normalne zapytanie analizy biznesowej z wieloma agregacjami, ale bez sum częściowych (pojedyncze zapytanie)
- Liczba: 2313
- Przykład:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Gdzie MDF_SessionLogin_Time_Max() jest definiowany w modelu jako:
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 AgregowanieSubtotals
Zapytanie analizy biznesowej z agregacjami i sumami częściowymi (za pośrednictwem wszystkich związków)
- Liczba: 178
- Przykład:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>