Usuwanie duplikatów w każdej tabeli w celu ich ujednolicenia
Deduplikacja znajduje i usuwa zduplikowane rekordy klienta z tabeli źródłowej, dzięki czemu każdy klient jest reprezentowany przez jeden wiersz w każdej tabeli. Każda tabela jest oddzielnie powtarzana przy użyciu reguł w celu zidentyfikowania rekordów danego klienta.
Każda reguła deduplikacji jest uruchamiana dla każdego wiersza. Jeśli pierwsza reguła pasuje do wierszy 1 i 2, a reguła 2 pasuje do wierszy 2 i 3, wiersze 1, 2 i 3 są dopasowane. Po znalezieniu pasujących wierszy wybierany jest zwycięski wiersz, który będzie reprezentował tego klienta na podstawie preferencji scalania (Najczęściej wypełnione, Najnowsze lub Najstarsze). Użyj opcji Zaawansowane , aby utworzyć zwycięski wiersz, wybierając pola z różnych dopasowanych wierszy, takich jak ostatni adres e-mail, ale najczęściej wypełniony adres.
Customer Insights - Data automatycznie wykonuje następujące czynności:
- Deduplikuj rekordy o tej samej wartości klucza podstawowego, wybierając pierwszy wiersz w zestawie danych jako zwycięzcę.
- Deduplikacja rekordów przy użyciu reguł dopasowywania zdefiniowanych dla tabeli podczas dopasowywania wierszy między tabelami.
Zdefiniuj reguły deduplikacji
Dobrym regułą jest zidentyfikowanie unikatowego klienta. Rozważ swoje dane. Wystarczy identyfikować klientów na podstawie pola takiego jak adres e-mail. Jeśli jednak chcemy rozróżniać klientów współkorzystających z poczty e-mail, można określić regułę z dwoma warunkami, porównującą adres e-mail + Imię. Aby uzyskać więcej informacji, zobacz Najlepsze praktyki w zakresie deduplikacji.
Na stronie Reguły deduplikacji wybierz tabelę i wybierz Dodaj regułę w celu zdefiniowania reguł deduplikacji.
Porada
Jeśli wzbogacono tabele na poziomie źródła danych, aby poprawić wyniki ujednolicenia, zaznacz Użyj wzbogaconych tabel na górze strony. Aby uzyskać więcej informacji, zobacz Wzbogacanie dla źródeł danych.
W okienku Dodaj regułę wprowadź następujące informacje:
Wybierz pole: Wybierz z listy dostępne pola tabeli, które chcesz sprawdzić pod kątem duplikatów. Wybierz pola, które będą unikatowe dla każdego pojedynczego klienta. Może to być na przykład adres e-mail lub kombinacja imienia i nazwiska, miasta oraz numeru telefonu.
Normalizowanie: wybór opcji normalizowania kolumny. Normalizowanie wpływa jedynie na pasujący krok i nie zmienia danych.
Normalizacja Przykłady Cyfry Konwertuje wiele symboli Unicode reprezentujących liczby na liczby proste.
Przykłady: ❽ i Ⅷ są znormalizowane do liczby 8.
Uwaga: symbole muszą być zakodowane w formacie punktowym Unicode.Symbole Usuwa symbole i znaki specjalne.
Przykłady: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ]Tekst na małe litery Konwertuje wielkie litery na małe litery.
Przykład: „TO JeSt PRzYKŁad” jest konwertowane na „to jest przykład”Typ — telefon Konwertuje telefony w różnych formatach na cyfry i uwzględnia różnice w sposobie prezentowania kodów krajów i rozszerzeń. Symbole i odstępy są ignorowane. Wiodące cyfry "0" w kodach krajów są ignorowane, pasując do +1 i +01. Rozszerzenia oznaczone przedrostkiem literowym są ignorowane (X 123). Znormalizowany kod kraju jest istotny, więc telefon z kodem kraju nie będzie pasował do telefonu bez kodu kraju.
Przykład: +01 425.555.1212 pasuje do 1 (425) 555-1212
+01 425.555.1212 nie pasuje do (425) 555-1212Typ — nazwa Konwertuje ponad 500 odmian nazw zwyczajowych i tytułów.
Przykłady: „debby” -> „Deborah”, „prof” i „profesor” -> „Prof.”Typ — adres Konwertuje wspólne części adresów
Przykłady: „ulica” -> „st” i „północny-zachód” -> „pn.-zach.”Typ — organizacja Usuwa około 50 „szumiących słów” z nazwy firmy, takich jak „co”, „corp”, „corporation” i „ltd”. Unicode na ASCII Unicode na ASCII: konwertowanie znaków Unicode na ich odpowiednika literowego ASCII
Przykład: znaki „à”, „á”, „â”, „À”, „Á”, „”, „Ô, „Ę”, „Ⓐ” i „A” są konwertowane na „a”.Znak odstępu Usuwa wszystkie białe znaki Mapowanie aliasu Umożliwia przesłanie niestandardowej listy par ciągów, których można następnie użyć do wskazania ciągów, które zawsze należy uważać za dopasowanie dokładne.
Użyj mapowania aliasów, jeśli masz konkretne przykłady danych, które Twoim zdaniem powinny pasować, a które nie są dopasowane przy użyciu jednego z pozostałych wzorców normalizacji.
Przykład: Scott i Scooter lub MSFT i Microsoft.Obejście niestandardowe Umożliwia przesłanie niestandardowej listy ciągów, których można następnie użyć do wskazania ciągów, których nigdy nie należy uważać za dopasowanie.
Obejście niestandardowe jest przydatne, gdy masz dane o typowych wartościach, które należy zignorować, takie jak fikcyjny numer telefonu lub fałszywy adres e-mail.
Przykład: nigdy nie dopasowuj numeru telefonu 555-1212 lub test@contoso.com
Dokładność: Ustaw poziom dokładności. Precyzja jest używana do dokładnego dopasowania i dopasowania rozmytego i określa, jak blisko muszą znajdować się dwa ciągi, aby zostały uznane za zgodne.
- Podstawowa: wybierz opcję Niska (30%), Średnia (60%), Wysoka (80%) i Dokładnie (100%). Wybierz opcję Dokładnie, aby dopasować tylko rekordy zgodne w 100 procentach.
- Niestandardowa: ustaw procent, do którego należy dopasować rekordy. System będzie dopasowywać tylko rekordy przekraczające ten próg.
Nazwa: Nazwa reguły.
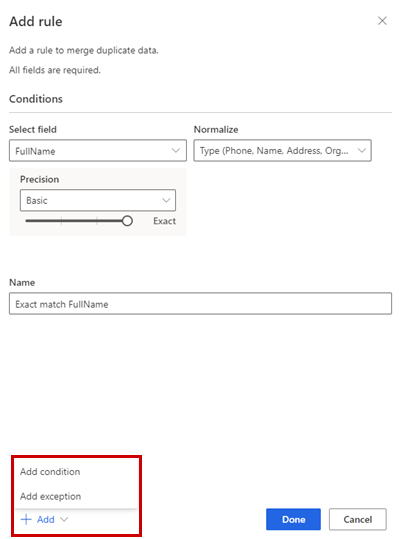
Opcjonalnie wybierz Dodaj>Dodaj warunek, aby dodać więcej warunków do reguły. Warunki są połączone z operatorem logicznym AND i dlatego są wykonywane tylko wtedy, gdy zostaną spełnione wszystkie warunki.
Opcjonalnie, Dodaj>Dodaj wyjątek, aby dodać wyjątki do reguły. Wyjątki są stosowane w rzadkich przypadkach fałszywych pozytywów i fałszywych negatywów.
Wybierz opcję Gotowe, aby utworzyć regułę.
Opcjonalnie dodaj więcej reguł.

Wybierz preferencje dotyczące scalania
Po uruchomieniu reguł i zidentyfikowaniu zduplikowanych rekordów dla klienta wybierany jest "wiersz zwycięzcy" na podstawie zasad scalania. Wiersz zwycięzcy reprezentuje klienta w następnym kroku ujednolicania, który dopasowuje rekordy między tabelami. Dane w wierszach innych niż zwycięzcy ("alternatywnych") są używane w kroku ujednolicania reguł dopasowywania w celu dopasowania rekordów z innych tabel do wiersza zwycięzcy. Takie podejście poprawia wyniki dopasowywania, umożliwiając informacje, takie jak poprzednie numery telefonów, w celu ułatwienia identyfikowania pasujących rekordów. Zwycięski wiersz można skonfigurować tak, aby był najczęściej wypełnionym, najnowszym lub najnowszym ze znalezionych zduplikowanych rekordów.
Wybierz tabelę, a następnie Edytuj preferencje scalania. Pojawia się okienko Preferencje łączenia.
Wybierz jedną z trzech opcji, aby określić, który rekord ma zostać zachowany, jeśli zostanie znaleziony duplikat:
- Większość wypełniona : identyfikuje rekord z najbardziej zapełnionymi kolumnami jako rekord zwyciężający. Jest to opcja domyślna scalania.
- Najnowsze: Identyfikuje rekord zwycięzcy na podstawie aktualności. Wymaga daty lub pola liczbowego do zdefiniowania aktualności.
- Najstarsze: Identyfikuje rekord zwycięzcy na podstawie najmniejszej aktualności. Wymaga daty lub pola liczbowego do zdefiniowania aktualności.
Jeśli dostępne są wyniki, rekord zwycięzcy to ten z wartością MAX(PK) lub większą wartością klucza podstawowego.
Opcjonalnie, aby zdefiniować preferencje scalania dla poszczególnych kolumn tabeli, wybierz opcję Zaawansowane u dołu okienka. Można na przykład zachować najnowszą wiadomość e-mail ORAZ najbardziej pełny adres z różnych rekordów. Rozwiń tabelę, aby zobaczyć wszystkie jej kolumny i określ, której opcji użyć dla poszczególnych kolumn. Jeśli wybierzesz opcję opartą na niedawności, musisz również określić pole daty/czasu definiujące niedawność.
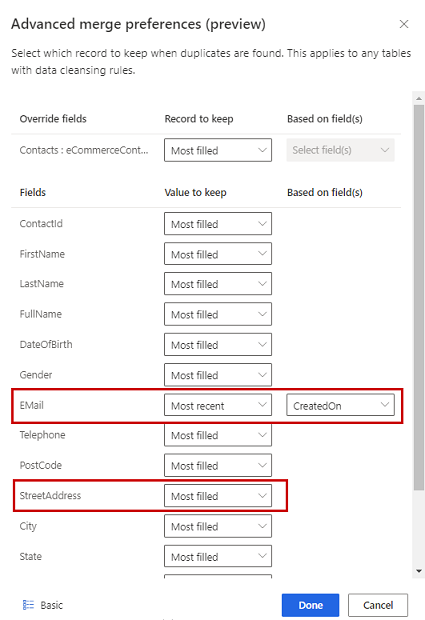
Wybierz Gotowe, aby zastosować swoje preferencje scalania.
Po określeniu reguł deduplikacji i preferencji scalania wybierz Dalej.