Nawiązywanie połączenia z tabelami usługi Common Data Model w Azure Data Lake Storage
Uwaga
Azure Active Directory nosi teraz nazwę Microsoft Entra ID. Dowiedz się więcej
Przetwarzanie danych w Dynamics 365 Customer Insights - Data użyciu konta Azure Data Lake Storage w tabelach Common Data Model. Pozyskiwanie danych może być pełna lub stopniowe.
Wymagania wstępne
Konto usługi Azure Data Lake Storage musi mieć włączone hierarchiczne obszary nazw. Dane muszą być przechowywane w hierarchicznym formacie folderów definiującym folder główny, który ma podfoldery dla każdej tabeli. Podfoldery mogą mieć pełne dane lub stopniowe foldery danych.
Aby uwierzytelnić się w głównej usłudze Microsoft Entra, należy się upewnić, że jest ona skonfigurowana w dzierżawie. Aby uzyskać więcej informacji, zobacz temat Łączenie się z kontem Azure Data Lake Storage z jednostką usługi Microsoft Entra.
Aby połączyć się z magazynem chronionym przez zapory, Skonfiguruj Azure Private Links.
Jeśli jezioro danych ma obecnie jakiekolwiek połączenia z łączem prywatnym, Customer Insights - Data musi również łączyć się za pomocą łącza prywatnego, niezależnie od ustawień dostępu do sieci.
Usługa Azure Data Lake Storage, którą chcesz połączyć i z której chcesz pozyskiwać dane musi znajdować się w tym samym regionie Azure, co środowisko Dynamics 365 Customer Insights, a subskrypcje muszą należeć do tej samej dzierżawy. Połączenia z folderem Common Data Model z data lake w innym regionie świadczenia usługi Azure nie są obsługiwane. Aby poznać region Azure środowiska, przejdź do Ustawienia>System>Informacje w Customer Insights - Data.
Dane przechowywane w usługach online mogą być przechowywane w innej lokalizacji niż ta, w której dane są przetwarzane lub przechowywane. Importując lub łącząc się z danymi w usługach online, użytkownik zgadza się, że dane mogą być przenoszone. Więcej informacji znajduje się w Centrum zaufania Microsoft.
Aby uzyskać dostęp do konta magazynu, główna usługa Customer Insights - Data musi mieć jedną z następujących ról. Aby uzyskać więcej informacji, zobacz Nadaj uprawnienia usłudze głównej w celu uzyskania dostępu do konta magazynu.
- Czytnik danych Storage Blob
- Właściciel danych Storage Blob
- Współautor danych w usłudze Blob Storage
Podczas łączenia się z usługą Azure Storage przy użyciu opcji Azure subscription użytkownik konfigurujący połączenie źródło danych potrzebuje co najmniej uprawnień do danych obiektu blob magazynu jako współautor na koncie magazynu.
Podczas łączenia się z usługą Azure Storage przy użyciu opcji Zasoby Azure użytkownik konfigurujący połączenie źródło danych potrzebuje co najmniej uprawnień Microsoft.Storage/storageAccounts/read na koncie magazynu. Wbudowaną rolą platformy Azure obejmującą tę akcję jest rola Czytelnik. Aby ograniczyć dostęp tylko do niezbędnej akcji, utwórz niestandardową rolę platformy Azure, która zawiera tylko tę akcję.
Aby zapewnić optymalną wydajność, rozmiar partycji nie może przekraczać 1 GB lub mniejszej, a liczba plików partycji w folderze nie może przekraczać 1000.
Dane w magazynie Data Lake Storage powinny być zgodne ze standardem Common Data Model dla przechowywania danych oraz mają Common Data Model reprezentujący schemat plików danych (*.csv lub *.parquet). W manifeście muszą być podane szczegółowe informacje o tabelach, takie jak kolumny tabel i typy danych, a także o lokalizacji i typie pliku danych. Aby uzyskać więcej informacji, zobacz Manifest Common Data Model. Jeśli ten manifest nie istnieje, administratorzy z dostępem właściciela danych obiektów blob magazynu lub współautora danych obiektów blob magazynu mogą zdefiniować schemat podczas pozyskiwania danych.
Uwaga
Jeśli któreś z pól w plikach .parquet ma typ danych Int96, dane mogą nie być wyświetlane na stronie Tabele. Zaleca się użycie standardowych typów danych, takich jak formatowanie Unix (reprezentujące liczbę sekund od 1 stycznia 1970 do północy czasu UTC).
Ograniczenia
- Customer Insights - Data nie obsługuje kolumn typu dziesiętnego z dokładnością większą niż 16.
Nawiązywanie połączenia z usługą Azure Data Lake Storage
Nazwy połączeń danych, ścieżki danych, takie jak foldery w kontenerze, oraz nazwy tabel muszą używać nazw rozpoczynających się od litery. Nazwa może zawierać tylko litery, cyfry i podkreślenia (_). Znaki specjalne nie są obsługiwane.
Przejdź do Dane>Źródła danych.
Wybierz Dodaj źródło danych.
Wybierz tabele Common Data Model usługi Azure Data Lake.

Wprowadź Nazwa źródła danych dla źródła danych i opcjonalnie Opis. Nazwa ta jest przywoływana w dalszych procesach i nie można jej zmienić po utworzeniu źródła danych.
Wybierz jedną z następujących opcji Połącz używanie magazynu. Aby uzyskać więcej informacji, zobacz temat Łączenie się z kontem Azure Data Lake Storage z jednostką usługi Microsoft Entra.
- Zasób Azure: wprowadź Identyfikator zasoby.
- Subskrypcja Azure: wybierz Subskrypcję, a następnie konto Grupa zasobów i Konto magazynu.
Uwaga
Potrzebujesz jednej z następujących ról w kontenerze do utworzenia źródła danych:
- Magazyn danych obiektów Blob czytnik wystarczy do odczytu z konta magazynu i pobierania danych do Customer Insights - Data.
- Dane obiektów Blob. ich współautor lub właściciel, jest wymagany, aby edytować pliki manifestów bezpośrednio w Customer Insights - Data.
Rola na koncie magazynu zapewni tę samą rolę we wszystkich jego kontenerach.
Wybierz nazwę Kontener zawierającą dane i schemat (plik model.json lub manifest.json), z których chcesz zaimportować dane, i wybierz przycisk Dalej.
Uwaga
Żaden plik model.json lub manifest.json powiązany z innym źródłem danych w środowisku nie zostanie wyświetlony na liście. Jednak ten sam plik model.json lub manifest.json może być używany dla źródeł danych w wielu środowiskach.
Opcjonalnie, jeśli chcesz uzyskać dane z konta magazynu za pośrednictwem łącza Azure Private Link, wybierz opcję Włącz łącze prywatne. Aby uzyskać więcej informacji, zobacz Łącza Private Links.
Aby utworzyć nowy schemat, przejdź do Tworzenie nowego pliku schematu.
Aby użyć istniejącego schematu, przejdź do folderu zawierającego plik model.json lub manifest.cdm.json. Plik można wyszukać w katalogu.
Wybierz plik json, a następnie wybierz Dalej. Wyświetli się lista dostępnych tabel.
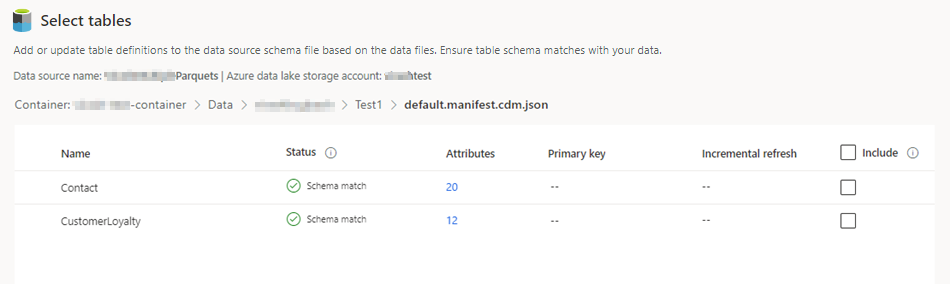
Wybierz tabele, które chcesz uwzględnić.
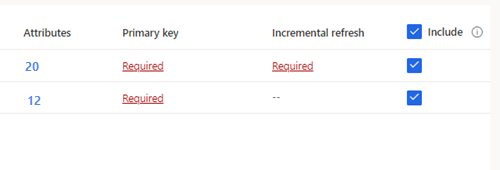
Napiwek
Aby edytować tabelę w interfejsie edycji JSON, wybierz tabelę, a następnie Edytuj plik schematu. Wprowadź zmiany i wybierz Zapisz.
W przypadku wybranych tabel, których klucz podstawowy nie został zdefiniowany, opcja Wymagane jest wyświetlana w obszarze Klucz podstawowy. Dla każdej z tych tabel:
- Wybierz Wymagane. Zostanie wyświetlony panel Edytowanie tabeli.
- Wybierz Klucz podstawowy. Klucz podstawowy jest atrybutem unikalnym dla danej tabeli. Aby atrybut był prawidłowym kluczem podstawowym, nie może zawierać zduplikowanych wartości, brakujących wartości ani wartości null. Atrybuty typu ciąg, liczba całkowita i GUID są obsługiwane jako klucze podstawowe.
- Opcjonalnie można zmienić wzorzec partycji.
- Wybierz Zamknij, by zapisać i zamknąć panel.
Wybierz liczbę Kolumny dla każdej dołączonej tabeli. Zostanie wyświetlona strona Zarządzanie atrybutami.
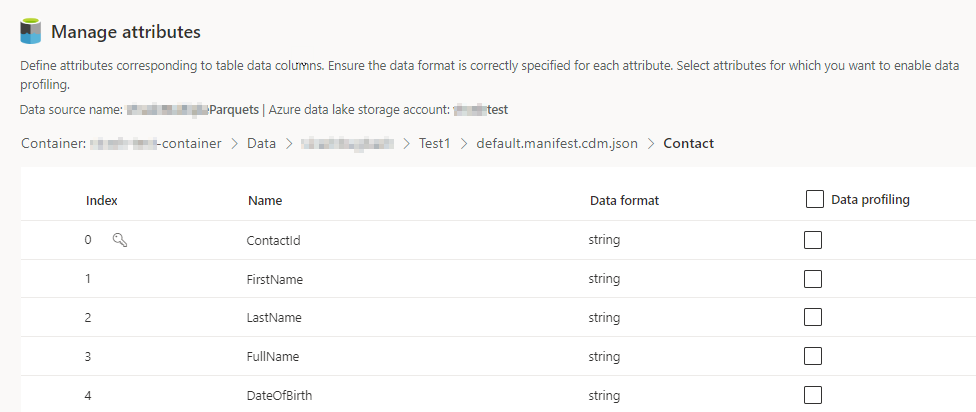
- Tworzenie nowych kolumn, edytowanie lub usuwanie istniejących. Można zmienić nazwę, format danych lub dodać typ semantyczny.
- Aby włączyć analizy i inne funkcje, wybierz opcję Profilowanie danych dla całej tabeli lub dla określonych kolumn. Domyślnie żadne tabele nie są włączone do profilowania danych.
- Wybierz Gotowe.
Wybierz pozycję Zapisz. Zostanie otwarta strona Źródła danych z nowymi źródło danych Odświeżania.
Napiwek
Zadania i procesy mają swoje stany. Większość procesów zależy od innych procesów nadrzędnych, takich jak źródła danych i odświeżenia profilowania danych.
Wybierz stan obok okienka Szczegóły postępu, aby wyświetlić postęp zadania. Aby anulować zadanie, wybierz opcję Anuluj zadanie w dolnej części okienka.
Pod każdym zadaniem możesz wybrać Zobacz szczegóły, aby uzyskać więcej informacji o postępie, takich jak czas przetwarzania, data ostatniego przetwarzania oraz wszystkie odpowiednie błędy i ostrzeżenia związane z zadaniem lub procesem. Wybierz Wyświetl stan systemu u dołu panelu, aby wyświetlić inne procesy w systemie.

Ładowanie danych może zająć czas. Po pomyślnym odświeżeniu dane z pobierania można przejrzeć na stronie Tabele.
Utwórz nowy plik schematu
Wybierz Utwórz plik schematu.
Wprowadź nazwę dla pliku i wybierz Zapisz.
Wybierz pozycję Nowa tabela. Zostanie wyświetlony panel Nowa tabela.
Wprowadź nazwę tabeli i wybierz Lokalizację plików danych.
- Wiele plików .csv lub .parquet: przejdź do folderu głównego, wybierz typ wzorca i wprowadź wyrażenie.
- Pojedyncze pliki .csv lub .parquet: przejdź do pliku .csv lub .parquet i go zaznacz.
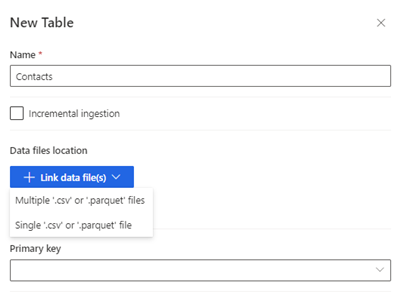
Wybierz pozycję Zapisz.
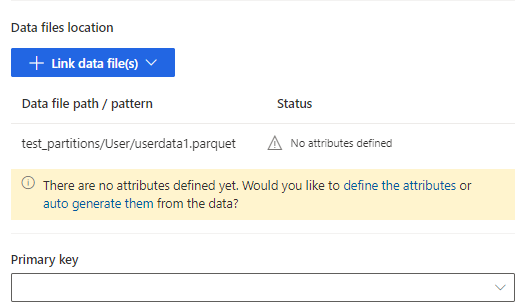
Wybierz określ atrybuty, by ręcznie dodać atrybuty, lub wybierz opcję automatycznego generowania atrybutów. Aby zdefiniować atrybuty, wprowadź nazwę, wybierz format danych i opcjonalny typ semantyczny. Do automatycznego generowania atrybutów:
Po automatycznym wygenerowaniu atrybutów wybierz opcję Przejrzyj atrybuty. Zostanie wyświetlona strona Zarządzanie atrybutami.
Upewnij się, że format danych dla każdego atrybutu jest poprawny.
Aby włączyć analizy i inne funkcje, wybierz Profilowanie danych dla całej tabeli lub dla określonych kolumn. Domyślnie żadne tabele nie są włączone do profilowania danych.
Wybierz Gotowe. Zostanie wyświetlona strona Wybieranie tabel.
W razie potrzeby kontynuuj dodawanie tabel i kolumn.
Po dodaniu wszystkich tabel wybierz opcję Uwzględnij, aby uwzględnić tabel w pozyskiwaniu źródła danych.
W przypadku wybranych tabel, których klucz podstawowy nie został zdefiniowany, opcja Wymagane jest wyświetlana w obszarze Klucz podstawowy. Dla każdej z tych tabel:
- Wybierz Wymagane. Zostanie wyświetlony panel Edytowanie tabeli.
- Wybierz Klucz podstawowy. Klucz podstawowy jest atrybutem unikalnym dla danej tabeli. Aby atrybut był prawidłowym kluczem podstawowym, nie może zawierać zduplikowanych wartości, brakujących wartości ani wartości null. Atrybuty typu ciąg, liczba całkowita i GUID są obsługiwane jako klucze podstawowe.
- Opcjonalnie można zmienić wzorzec partycji.
- Wybierz Zamknij, by zapisać i zamknąć panel.
Wybierz pozycję Zapisz. Zostanie otwarta strona Źródła danych z nowymi źródło danych Odświeżania.
Napiwek
Zadania i procesy mają swoje stany. Większość procesów zależy od innych procesów nadrzędnych, takich jak źródła danych i odświeżenia profilowania danych.
Wybierz stan obok okienka Szczegóły postępu, aby wyświetlić postęp zadania. Aby anulować zadanie, wybierz opcję Anuluj zadanie w dolnej części okienka.
Pod każdym zadaniem możesz wybrać Zobacz szczegóły, aby uzyskać więcej informacji o postępie, takich jak czas przetwarzania, data ostatniego przetwarzania oraz wszystkie odpowiednie błędy i ostrzeżenia związane z zadaniem lub procesem. Wybierz Wyświetl stan systemu u dołu panelu, aby wyświetlić inne procesy w systemie.
Ładowanie danych może zająć czas. Po pomyślnym odświeżeniu pozyskane dane można przejrzeć na stronie Dane>Tabele.
Edytuj źródło danych Azure Data Lake Storage
Możesz zaktualizować za pomocą opcji Połącz z kontem magazynu, używając. Aby uzyskać więcej informacji, zobacz temat Łączenie się z kontem Azure Data Lake Storage z jednostką usługi Microsoft Entra. Aby połączyć się z innym kontenerem z konta magazynu lub zmienić nazwę konta, utwórz nowe połączenie źródła danych.
Przejdź do Dane>Źródła danych. Obok źródła danych, które chcesz zaktualizować, wybierz Edytuj.
Zmień którekolwiek z poniższych informacji:
opis
Podłącz magazyn przy użyciu i informacje o połączeniu. Podczas aktualizowania połączenia nie można zmieniać informacji o Kontenerze.
Uwaga
Do konta lub kontenera magazynu musi być przypisana jedna z następujących ról:
- Czytnik danych Storage Blob
- Właściciel danych Storage Blob
- Współautor danych w usłudze Blob Storage
Jeśli chcesz uzyskać dane z konta magazynu za pośrednictwem łącza Azure Private Link, wybierz opcję Włącz łącze prywatne. Aby uzyskać więcej informacji, zobacz Łącza Private Links.
Wybierz Dalej.
Zmień dowolną z następujących czynności:
Przejdź do innego pliku model.json lub manifest.json z innym zestawem tabel z kontenera.
Aby dodać kolejne tabele do pozyskania, wybierz opcję Nowa tabela.
Aby usunąć wszystkie już wybrane tabele, jeśli brak zależności, wybierz tabelę i pozycję Usuń.
Ważne
Jeśli istnieją zależności między istniejącym plikiem model.json lub manifest.json a zestawem tabel, zostanie wyświetlony komunikat o błędzie i nie będzie można wybrać innego pliku model.json lub manifest.json. Usuń te zależności przed zmianą pliku model.json lub manifest.json lub utwórz nowe źródło danych z plikiem model.json lub manifest.json, którego chcesz użyć, aby uniknąć usuwania zależności.
Aby zmienić lokalizację pliku danych lub klucz podstawowy, wybierz opcję Edytuj.
Należy zmienić nazwę tabeli tak, aby odpowiadała nazwie tabeli w pliku json.
Uwaga
Po iniekcji zawsze należy zachować nazwę tabeli tak samo, jak nazwa tabeli w pliku model.json lub manifest.json. Customer Insights - Data sprawdza poprawność wszystkich nazw tabel przy użyciu pliku model.json lub manifest.json podczas każdego odświeżenia systemu. Zmiana nazwy tabeli występuje, ponieważ Customer Insights - Data nie może znaleźć nowej nazwy tabeli w pliku json. Jeśli nazwa tabeli, która została przypadkowo zmieniona, należy edytować nazwę tabeli w celu jej dopasowania do nazwy w pliku json.
Wybierz Kolumny, które chcesz dodać lub zmienić, albo w celu włączenia funkcji profilowania danych. Następnie wybierz Gotowe.
Wybierz przycisk Zapisz, aby zastosować zmiany i wrócić do strony Źródła danych.
Napiwek
Zadania i procesy mają swoje stany. Większość procesów zależy od innych procesów nadrzędnych, takich jak źródła danych i odświeżenia profilowania danych.
Wybierz stan obok okienka Szczegóły postępu, aby wyświetlić postęp zadania. Aby anulować zadanie, wybierz opcję Anuluj zadanie w dolnej części okienka.
Pod każdym zadaniem możesz wybrać Zobacz szczegóły, aby uzyskać więcej informacji o postępie, takich jak czas przetwarzania, data ostatniego przetwarzania oraz wszystkie odpowiednie błędy i ostrzeżenia związane z zadaniem lub procesem. Wybierz Wyświetl stan systemu u dołu panelu, aby wyświetlić inne procesy w systemie.