Samouczek: wykrywanie obiektów przy użyciu narzędzia ONNX w ML.NET
Dowiedz się, jak używać wstępnie wytrenowanego modelu ONNX w ML.NET do wykrywania obiektów na obrazach.
Trenowanie modelu wykrywania obiektów od podstaw wymaga ustawienia milionów parametrów, dużej ilości danych treningowych oznaczonych etykietami i ogromnej ilości zasobów obliczeniowych (setki godzin procesora GPU). Użycie wstępnie wytrenowanego modelu umożliwia skrót do procesu trenowania.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Omówienie problemu
- Dowiedz się, czym jest ONNX i jak działa z ML.NET
- Omówienie modelu
- Ponowne używanie wstępnie wytrenowanego modelu
- Wykrywanie obiektów za pomocą załadowanego modelu
Wymagania wstępne
- Visual Studio 2022.
- pakiet NuGet Microsoft.ML
- Pakiet NuGet Microsoft.ML.ImageAnalytics
- Pakiet NuGet Microsoft.ML.OnnxTransformer
- Mały model YOLOv2 wstępnie wytrenowany
- Netron (opcjonalnie)
Omówienie przykładu wykrywania obiektów ONNX
Ten przykład tworzy aplikację konsolową platformy .NET Core, która wykrywa obiekty na obrazie przy użyciu wstępnie wytrenowanego modelu ONNX uczenia głębokiego. Kod dla tego przykładu można znaleźć w repozytorium dotnet/machinelearning-samples w witrynie GitHub.
Co to jest wykrywanie obiektów?
Wykrywanie obiektów jest problemem z przetwarzaniem obrazów. Chociaż ściśle związane z klasyfikacją obrazów, wykrywanie obiektów wykonuje klasyfikację obrazów w bardziej szczegółowej skali. Wykrywanie obiektów lokalizuje i kategoryzuje jednostki na obrazach. Modele wykrywania obiektów są często trenowane przy użyciu uczenia głębokiego i sieci neuronowych. Aby uzyskać więcej informacji, zobacz Uczenie głębokie a uczenie maszynowe.
Użyj wykrywania obiektów, gdy obrazy zawierają wiele obiektów różnych typów.

Niektóre przypadki użycia wykrywania obiektów obejmują:
- Samochody samojeżdżące
- Robotyka
- Wykrywanie twarzy
- Sejf ty miejsca pracy
- Zliczanie obiektów
- Rozpoznawanie działań
Wybieranie modelu uczenia głębokiego
Uczenie głębokie to podzbiór uczenia maszynowego. Do trenowania modeli uczenia głębokiego wymagane są duże ilości danych. Wzorce w danych są reprezentowane przez serię warstw. Relacje w danych są kodowane jako połączenia między warstwami zawierającymi wagi. Im większa waga, tym silniejszy związek. Łącznie ta seria warstw i połączeń jest nazywana sztucznymi sieciami neuronowymi. Im więcej warstw w sieci, tym bardziej jest to "głębsze", dzięki czemu jest to głęboka sieć neuronowa.
Istnieją różne typy sieci neuronowych, najczęściej są to wielowarstwowe perceptron (MLP), splotowe sieci neuronowe (CNN) i rekursyjne sieci neuronowe (RNN). Najbardziej podstawowym elementem jest MLP, który mapuje zestaw danych wejściowych na zestaw danych wyjściowych. Ta sieć neuronowa jest dobra, gdy dane nie mają składnika przestrzennego lub czasu. Sieć CNN wykorzystuje warstwy splotowe do przetwarzania informacji przestrzennych zawartych w danych. Dobrym przypadkiem użycia sieci CNN jest przetwarzanie obrazów w celu wykrycia obecności funkcji w regionie obrazu (na przykład czy w środku obrazu istnieje nos?). Na koniec sieci RNN umożliwiają trwałość stanu lub pamięci, która ma być używana jako dane wejściowe. Sieci RNN są używane do analizy szeregów czasowych, gdzie kolejność sekwencyjna i kontekst zdarzeń jest ważna.
Omówienie modelu
Wykrywanie obiektów to zadanie przetwarzania obrazów. W związku z tym większość modeli uczenia głębokiego przeszkolonych w celu rozwiązania tego problemu to sieci CNN. Model używany w tym samouczku to model Tiny YOLOv2, bardziej kompaktowy model YOLOv2 opisany w dokumencie: "YOLO9000: Better, Faster, Stronger" firmy Redmon i Farhadi. Mały YOLOv2 jest trenowany na zestawie danych Pascal VOC i składa się z 15 warstw, które mogą przewidywać 20 różnych klas obiektów. Ponieważ Tiny YOLOv2 jest skróconą wersją oryginalnego modelu YOLOv2, kompromis jest między szybkością a dokładnością. Różne warstwy tworzące model można wizualizować przy użyciu narzędzi takich jak Netron. Sprawdzenie modelu spowodowałoby mapowanie połączeń między wszystkimi warstwami tworzącymi sieć neuronową, gdzie każda warstwa będzie zawierać nazwę warstwy wraz z wymiarami odpowiednich danych wejściowych/wyjściowych. Struktury danych używane do opisywania danych wejściowych i wyjściowych modelu są nazywane tensorami. Tensors można traktować jako kontenery, które przechowują dane w wymiarach N. W przypadku tiny YOLOv2 nazwa warstwy wejściowej to image i oczekuje tensor wymiarów 3 x 416 x 416. Nazwa warstwy wyjściowej to grid i generuje tensor wyjściowy wymiarów 125 x 13 x 13.
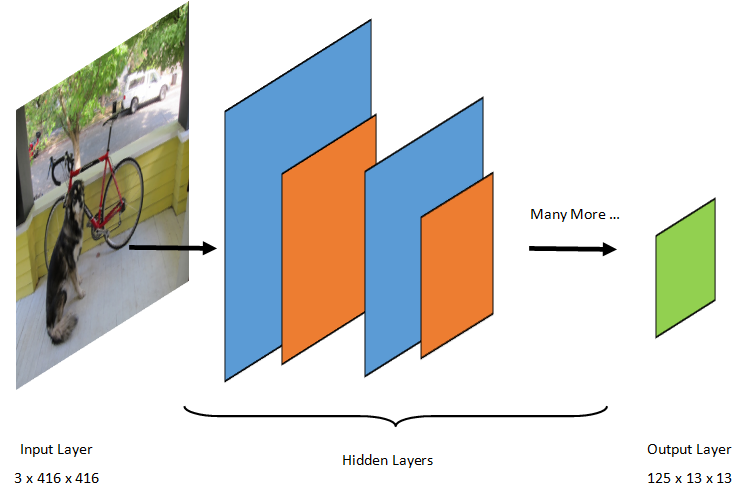
Model YOLO przyjmuje obraz 3(RGB) x 416px x 416px. Model pobiera te dane wejściowe i przekazuje je przez różne warstwy w celu wygenerowania danych wyjściowych. Dane wyjściowe dzielą obraz wejściowy na siatkę 13 x 13 , a każda komórka w siatce składa się z 125 wartości.
Co to jest model ONNX?
Open Neural Network Exchange (ONNX) to format open source dla modeli sztucznej inteligencji. Platforma ONNX obsługuje współdziałanie między platformami. Oznacza to, że można wytrenować model w jednej z wielu popularnych struktur uczenia maszynowego, takich jak PyTorch, przekonwertować go na format ONNX i korzystać z modelu ONNX w innej strukturze, takiej jak ML.NET. Aby dowiedzieć się więcej, odwiedź witrynę internetową ONNX.

Wstępnie wytrenowany model Tiny YOLOv2 jest przechowywany w formacie ONNX, serializowanej reprezentacji warstw i poznanych wzorców tych warstw. W ML.NET współdziałanie z onNX odbywa się za pomocą ImageAnalytics pakietów NuGet i OnnxTransformer . Pakiet ImageAnalytics zawiera serię przekształceń, które przyjmują obraz i koduje je do wartości liczbowych, które mogą być używane jako dane wejściowe w potoku przewidywania lub trenowania. Pakiet OnnxTransformer wykorzystuje środowisko uruchomieniowe ONNX do ładowania modelu ONNX i używa go do przewidywania na podstawie podanych danych wejściowych.
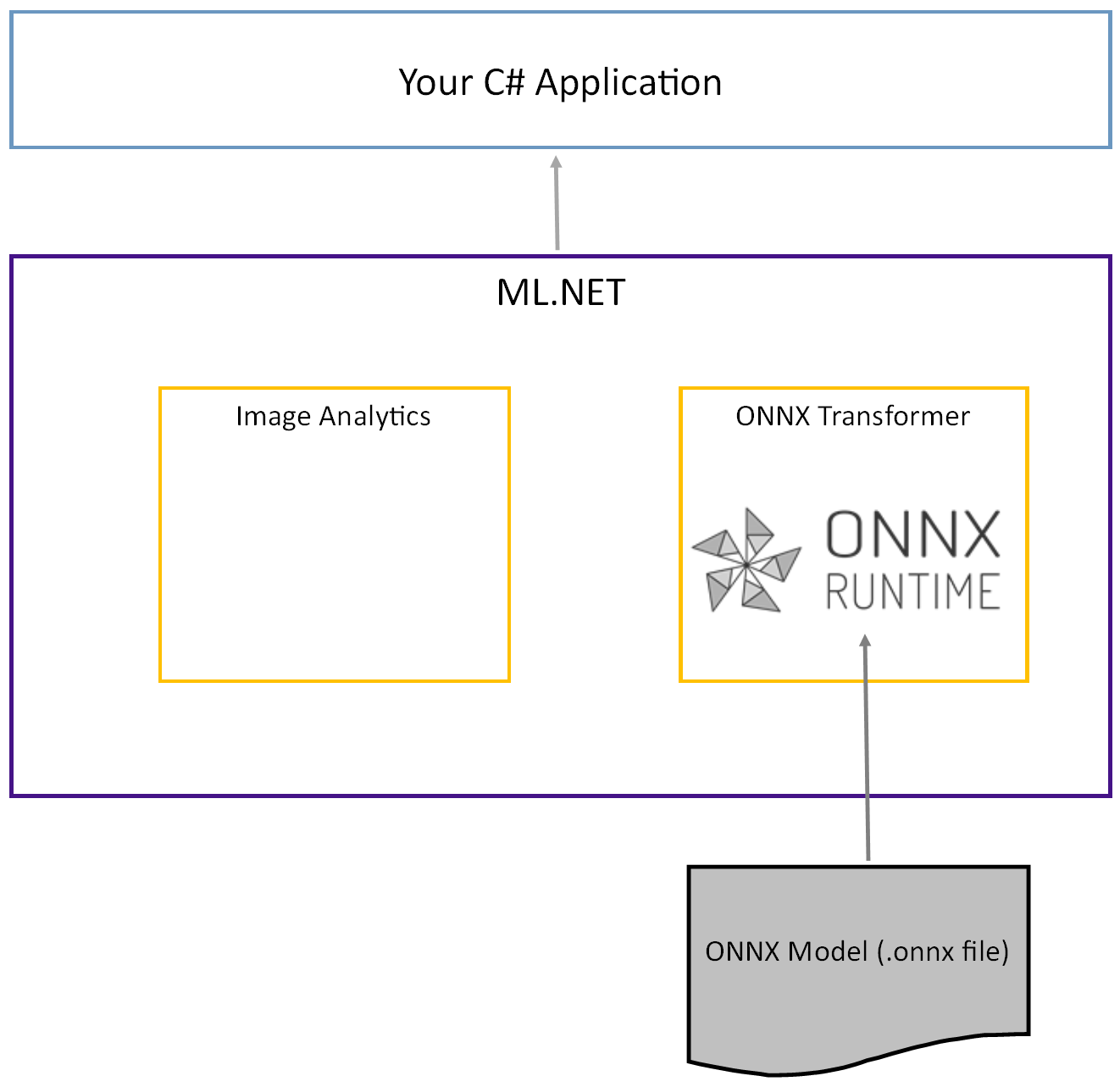
Konfigurowanie projektu konsoli .NET
Teraz, gdy masz ogólne zrozumienie, co to jest ONNX i jak działa Tiny YOLOv2, nadszedł czas na skompilowanie aplikacji.
Tworzenie aplikacji konsolowej
Utwórz aplikację konsolową języka C# o nazwie "ObjectDetection". Kliknij przycisk Next (Dalej).
Wybierz platformę .NET 6 jako platformę do użycia. Kliknij przycisk Utwórz.
Zainstaluj pakiet NuGet Microsoft.ML:
Uwaga
W tym przykładzie użyto najnowszej stabilnej wersji pakietów NuGet wymienionych, chyba że określono inaczej.
- W Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt i wybierz polecenie Zarządzaj pakietami NuGet.
- Wybierz pozycję "nuget.org" jako źródło pakietu, wybierz kartę Przeglądaj, wyszukaj Microsoft.ML.
- Wybierz przycisk Zainstaluj.
- Wybierz przycisk OK w oknie dialogowym Podgląd zmian, a następnie wybierz przycisk Akceptuję w oknie dialogowym Akceptacja licencji, jeśli zgadzasz się z postanowieniami licencyjnymi dla pakietów wymienionych.
- Powtórz te kroki dla programów Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer i Microsoft.ML.OnnxRuntime.
Przygotowywanie danych i wstępnie wytrenowanego modelu
Pobierz plik zip katalogu zasobów projektu i rozpakuj go.
assetsSkopiuj katalog do katalogu projektu ObjectDetection. Ten katalog i jego podkatalogi zawierają pliki obrazów (z wyjątkiem modelu Tiny YOLOv2, który zostanie pobrany i dodany w następnym kroku) wymagany w tym samouczku.Pobierz model Tiny YOLOv2 z zoo modelu ONNX.
model.onnxSkopiuj plik do katalogu projektuassets\ModelObjectDetection i zmień jego nazwę naTinyYolo2_model.onnx. Ten katalog zawiera model wymagany do tego samouczka.W Eksplorator rozwiązań kliknij prawym przyciskiem myszy każdy z plików w katalogu zasobów i podkatalogach, a następnie wybierz pozycję Właściwości. W obszarze Zaawansowane zmień wartość kopiuj do katalogu wyjściowego, aby skopiować, jeśli jest nowsza.
Tworzenie klas i definiowanie ścieżek
Otwórz plik Program.cs i dodaj następujące dodatkowe using instrukcje na początku pliku:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Następnie zdefiniuj ścieżki różnych zasobów.
Najpierw utwórz metodę
GetAbsolutePathw dolnej części pliku Program.cs .string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }Następnie poniżej instrukcji using utwórz pola do przechowywania lokalizacji zasobów.
var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Dodaj nowy katalog do projektu, aby przechowywać dane wejściowe i klasy przewidywania.
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt, a następnie wybierz polecenie Dodaj>nowy folder. Gdy nowy folder pojawi się w Eksplorator rozwiązań, nadaj mu nazwę "DataStructures".
Utwórz klasę danych wejściowych w nowo utworzonym katalogu DataStructures .
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy katalog DataStructures, a następnie wybierz polecenie Dodaj>nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Klasa i zmień pole Nazwa na ImageNetData.cs. Następnie wybierz przycisk Dodaj .
Plik ImageNetData.cs zostanie otwarty w edytorze kodu. Dodaj następującą
usinginstrukcję na początku pliku ImageNetData.cs:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Usuń istniejącą definicję klasy i dodaj następujący kod dla
ImageNetDataklasy do pliku ImageNetData.cs :public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetDatato klasa danych obrazu wejściowego i ma następujące String pola:ImagePathzawiera ścieżkę, w której jest przechowywany obraz.Labelzawiera nazwę pliku.
Ponadto zawiera metodę
ReadFromFile,ImageNetDataktóra ładuje wiele plików obrazów przechowywanych wimageFolderokreślonej ścieżce i zwraca je jako kolekcjęImageNetDataobiektów.
Utwórz klasę przewidywania w katalogu DataStructures .
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy katalog DataStructures, a następnie wybierz polecenie Dodaj>nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Klasa i zmień pole Nazwa na ImageNetPrediction.cs. Następnie wybierz przycisk Dodaj .
Plik ImageNetPrediction.cs zostanie otwarty w edytorze kodu. Dodaj następującą
usinginstrukcję na początku pliku ImageNetPrediction.cs:using Microsoft.ML.Data;Usuń istniejącą definicję klasy i dodaj następujący kod dla
ImageNetPredictionklasy do pliku ImageNetPrediction.cs :public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPredictionto klasa danych przewidywania i ma następującefloat[]pole:PredictedLabelszawiera wymiary, wynik obiektów i prawdopodobieństwa klas dla każdego pola ograniczenia wykrytego na obrazie.
Inicjowanie zmiennych
Klasa MLContext jest punktem wyjścia dla wszystkich operacji ML.NET, a inicjowanie mlContext tworzy nowe środowisko ML.NET, które może być współużytkowane przez obiekty przepływu pracy tworzenia modelu. Jest ona podobna, koncepcyjnie, do DBContext w programie Entity Framework.
Zainicjuj mlContext zmienną przy użyciu nowego wystąpienia MLContext , dodając następujący wiersz poniżej outputFolder pola.
MLContext mlContext = new MLContext();
Tworzenie analizatora do danych wyjściowych modelu po przetworzeniu
Model dzieli obraz na siatkę 13 x 13 , gdzie każda komórka siatki to 32px x 32px. Każda komórka siatki zawiera 5 potencjalnych pól ograniczenia obiektów. Pole ograniczenia ma 25 elementów:
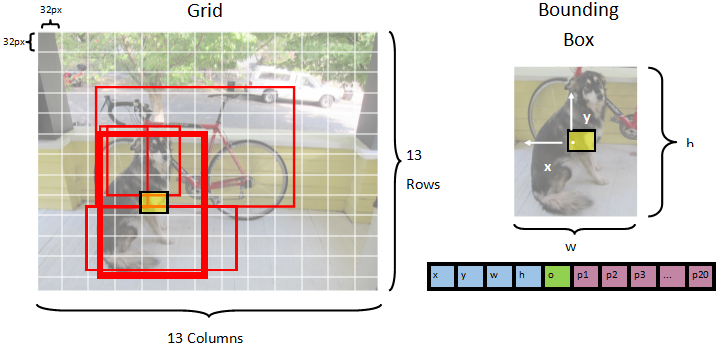
xpołożenie x środka pola ograniczenia względem komórki siatki, z którymi jest skojarzona.ypołożenie y środka pola ograniczenia względem komórki siatki, z którymi jest skojarzona.wszerokość pola ograniczenia.hwysokość pola ograniczenia.owartość ufności, że obiekt istnieje w polu ograniczenia, znany również jako wynik obiektów.p1-p20prawdopodobieństwa klas dla każdej z 20 klas przewidywanych przez model.
Łącznie 25 elementów opisujących każde z 5 pól ograniczenia składa się z 125 elementów zawartych w każdej komórce siatki.
Dane wyjściowe generowane przez wstępnie wytrenowany model ONNX to tablica zmiennoprzecinkowa długości 21125, reprezentująca elementy tensor z wymiarami 125 x 13 x 13. Aby przekształcić przewidywania wygenerowane przez model w tensor, wymagana jest część pracy po przetworzeniu. W tym celu utwórz zestaw klas, aby ułatwić analizowanie danych wyjściowych.
Dodaj nowy katalog do projektu, aby zorganizować zestaw klas analizatora.
- W Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt, a następnie wybierz polecenie Dodaj>nowy folder. Gdy nowy folder pojawi się w Eksplorator rozwiązań, nadaj mu nazwę "YoloParser".
Tworzenie pól i wymiarów ograniczeń
Dane wyjściowe modelu zawierają współrzędne i wymiary pól ograniczenia obiektów na obrazie. Utwórz klasę bazową dla wymiarów.
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy katalog YoloParser, a następnie wybierz polecenie Dodaj>nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Klasa i zmień pole Nazwa na DimensionsBase.cs. Następnie wybierz przycisk Dodaj .
Plik DimensionsBase.cs zostanie otwarty w edytorze kodu. Usuń wszystkie
usinginstrukcje i istniejącą definicję klasy.Dodaj następujący kod dla
DimensionsBaseklasy do pliku DimensionsBase.cs :public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBasema następującefloatwłaściwości:Xzawiera położenie obiektu wzdłuż osi x.Yzawiera położenie obiektu wzdłuż osi y.Heightzawiera wysokość obiektu.Widthzawiera szerokość obiektu.
Następnie utwórz klasę dla pól ograniczenia.
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy katalog YoloParser, a następnie wybierz polecenie Dodaj>nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Klasa i zmień pole Nazwa na YoloBoundingBox.cs. Następnie wybierz przycisk Dodaj .
Plik YoloBoundingBox.cs zostanie otwarty w edytorze kodu. Dodaj następującą
usinginstrukcję na początku pliku YoloBoundingBox.cs:using System.Drawing;Tuż nad istniejącą definicją klasy dodaj nową definicję klasy o nazwie
BoundingBoxDimensions, która dziedziczy zDimensionsBaseklasy, aby zawierała wymiary odpowiedniego pola ograniczenia.public class BoundingBoxDimensions : DimensionsBase { }Usuń istniejącą
YoloBoundingBoxdefinicję klasy i dodaj następujący kod dlaYoloBoundingBoxklasy do pliku YoloBoundingBox.cs :public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxma następujące właściwości:Dimensionszawiera wymiary pola ograniczenia.Labelzawiera klasę obiektu wykrytego w polu ograniczenia.Confidencezawiera pewność klasy.Rectzawiera prostokątną reprezentację wymiarów pola ograniczenia.BoxColorzawiera kolor skojarzony z odpowiednią klasą używaną do rysowania na obrazie.
Tworzenie analizatora
Teraz, gdy klasy wymiarów i pól ograniczenia są tworzone, nadszedł czas, aby utworzyć analizator.
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy katalog YoloParser, a następnie wybierz polecenie Dodaj>nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Klasa i zmień pole Nazwa na YoloOutputParser.cs. Następnie wybierz przycisk Dodaj .
Plik YoloOutputParser.cs zostanie otwarty w edytorze kodu. Dodaj następujące
usinginstrukcje na początku pliku YoloOutputParser.cs:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;Wewnątrz istniejącej
YoloOutputParserdefinicji klasy dodaj zagnieżdżona klasę zawierającą wymiary każdej z komórek na obrazie. Dodaj następujący kod dlaCellDimensionsklasy dziedziczonejDimensionsBasez klasy w górnejYoloOutputParserczęści definicji klasy.class CellDimensions : DimensionsBase { }YoloOutputParserWewnątrz definicji klasy dodaj następujące stałe i pole.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;ROW_COUNTto liczba wierszy w siatce, na które obraz jest podzielony.COL_COUNTto liczba kolumn w siatce, na które obraz jest podzielony.CHANNEL_COUNTjest całkowitą liczbą wartości zawartych w jednej komórce siatki.BOXES_PER_CELLjest liczbą pól ograniczenia w komórce,BOX_INFO_FEATURE_COUNTto liczba funkcji zawartych w polu (x,y,height,width,confidence).CLASS_COUNTto liczba przewidywań klas zawartych w każdym polu ograniczenia.CELL_WIDTHto szerokość jednej komórki w siatce obrazu.CELL_HEIGHTjest wysokością jednej komórki w siatce obrazu.channelStrideto pozycja początkowa bieżącej komórki w siatce.
Gdy model tworzy przewidywanie, nazywane również ocenianiem, dzieli
416px x 416pxobraz wejściowy na siatkę komórek o rozmiarze13 x 13. Każda komórka zawiera wartość32px x 32px. W każdej komórce znajduje się 5 pól ograniczenia, z których każda zawiera 5 cech (x, y, szerokość, wysokość, pewność). Ponadto każde pole ograniczenia zawiera prawdopodobieństwo każdej z klas, co w tym przypadku wynosi 20. W związku z tym każda komórka zawiera 125 elementów informacji (5 cech + 20 prawdopodobieństwa klasy).
Utwórz listę kotwic poniżej channelStride dla wszystkich 5 pól ograniczenia:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Kotwice są wstępnie zdefiniowanymi współczynnikami wysokości i szerokości pól ograniczenia. Większość obiektów lub klas wykrytych przez model ma podobne proporcje. Jest to cenne, jeśli chodzi o tworzenie pól ograniczenia. Zamiast przewidywać pola ograniczenia, przesunięcie ze wstępnie zdefiniowanych wymiarów jest obliczane, dlatego zmniejsza obliczanie wymagane do przewidywania pola ograniczenia. Zazwyczaj te współczynniki kotwic są obliczane na podstawie używanego zestawu danych. W takim przypadku, ponieważ zestaw danych jest znany, a wartości zostały wstępnie obliczone, kotwice mogą być zakodowane na twardo.
Następnie zdefiniuj etykiety lub klasy, które będzie przewidywać model. Ten model przewiduje 20 klas, które są podzbiorem całkowitej liczby klas przewidywanych przez oryginalny model YOLOv2.
Dodaj listę etykiet poniżej .anchors
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
Istnieją kolory skojarzone z poszczególnymi klasami. Przypisz kolory klasy poniżej elementu labels:
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Tworzenie funkcji pomocnika
Istnieje szereg kroków związanych z fazą przetwarzania końcowego. Aby pomóc w tym, można stosować kilka metod pomocnika.
Metody pomocnicze używane w analizatorze to:
Sigmoidstosuje funkcję sigmoid, która generuje liczbę z zakresu od 0 do 1.Softmaxnormalizuje wektor wejściowy do rozkładu prawdopodobieństwa.GetOffsetmapuje elementy w danych wyjściowych modelu jednowymiarowego na odpowiednią pozycję w125 x 13 x 13tensor.ExtractBoundingBoxeswyodrębnia wymiary pola ograniczenia przy użyciuGetOffsetmetody z danych wyjściowych modelu.GetConfidenceWyodrębnia wartość ufności, która określa, w jaki sposób model jest pewien, że wykrył obiekt i używaSigmoidfunkcji, aby przekształcić go w wartość procentową.MapBoundingBoxToCellużywa wymiarów pola ograniczenia i mapuje je na odpowiednią komórkę na obrazie.ExtractClasseswyodrębnia przewidywania klas dla pola ograniczenia z danych wyjściowych modelu przy użyciuGetOffsetmetody i przekształca je w rozkład prawdopodobieństwa przy użyciuSoftmaxmetody .GetTopResultwybiera klasę z listy przewidywanych klas z najwyższym prawdopodobieństwem.IntersectionOverUnionfiltruje nakładające się pola ograniczenia o niższym prawdopodobieństwie.
Dodaj kod dla wszystkich metod pomocnika poniżej listy classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Po zdefiniowaniu wszystkich metod pomocnika nadszedł czas, aby użyć ich do przetworzenia danych wyjściowych modelu.
IntersectionOverUnion Poniżej metody utwórz metodę przetwarzania ParseOutputs danych wyjściowych wygenerowanych przez model.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Utwórz listę do przechowywania pól ograniczenia i zdefiniuj ParseOutputs zmienne wewnątrz metody .
var boxes = new List<YoloBoundingBox>();
Każdy obraz jest podzielony na siatkę 13 x 13 komórek. Każda komórka zawiera pięć pól ograniczenia. Poniżej zmiennej boxes dodaj kod, aby przetworzyć wszystkie pola w każdej z komórek.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
Wewnątrz pętli najbardziej wewnętrznej oblicz pozycję początkową bieżącego pola w danych wyjściowych modelu jednowymiarowego.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Bezpośrednio poniżej tej metody użyj ExtractBoundingBoxDimensions metody , aby uzyskać wymiary bieżącego pola ograniczenia.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
Następnie użyj GetConfidence metody , aby uzyskać pewność dla bieżącego pola ograniczenia.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
Następnie użyj MapBoundingBoxToCell metody , aby zamapować bieżące pole ograniczenia na przetworzoną bieżącą komórkę.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Przed wykonaniem dalszego przetwarzania sprawdź, czy wartość ufności jest większa niż podana wartość progowa. Jeśli nie, przetwórz następne pole ograniczenia.
if (confidence < threshold)
continue;
W przeciwnym razie kontynuuj przetwarzanie danych wyjściowych. Następnym krokiem jest uzyskanie rozkładu prawdopodobieństwa przewidywanych klas dla bieżącego pola ograniczenia przy użyciu ExtractClasses metody .
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Następnie użyj GetTopResult metody , aby uzyskać wartość i indeks klasy z najwyższym prawdopodobieństwem dla bieżącego pola i obliczyć jego wynik.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Użyj polecenia , topScore aby po raz kolejny zachować tylko te pola ograniczenia, które znajdują się powyżej określonego progu.
if (topScore < threshold)
continue;
Na koniec, jeśli bieżące pole ograniczenia przekroczy próg, utwórz nowy BoundingBox obiekt i dodaj go do boxes listy.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
Po przetworzeniu wszystkich komórek na obrazie zwróć boxes listę. Dodaj następującą instrukcję return poniżej zewnętrznej pętli for-loop w metodzie ParseOutputs .
return boxes;
Filtrowanie nakładających się pól
Teraz, gdy wszystkie wysoce pewne pola ograniczenia zostały wyodrębnione z danych wyjściowych modelu, należy wykonać dodatkowe filtrowanie, aby usunąć nakładające się obrazy. Dodaj metodę o nazwie FilterBoundingBoxes poniżej ParseOutputs metody :
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
FilterBoundingBoxes Wewnątrz metody zacznij od utworzenia tablicy równej rozmiarowi wykrytych pól i oznaczeniu wszystkich miejsc jako aktywnych lub gotowych do przetworzenia.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Następnie posortuj listę zawierającą pola ograniczenia w kolejności malejącej na podstawie pewności.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
Następnie utwórz listę do przechowywania filtrowanych wyników.
var results = new List<YoloBoundingBox>();
Rozpocznij przetwarzanie każdego pola ograniczenia, iterując nad każdym z pól ograniczenia.
for (int i = 0; i < boxes.Count; i++)
{
}
Wewnątrz tej pętli dla sprawdź, czy można przetworzyć bieżące pole ograniczenia.
if (isActiveBoxes[i])
{
}
Jeśli tak, dodaj pole ograniczenia do listy wyników. Jeśli wyniki przekraczają określony limit pól do wyodrębnienia, należy przerwać pętlę. Dodaj następujący kod wewnątrz instrukcji if.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
W przeciwnym razie przyjrzyj się sąsiednim polam ograniczenia. Dodaj następujący kod poniżej pola wyboru limitu.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Podobnie jak pierwsze pole, jeśli sąsiadujące pole jest aktywne lub gotowe do przetworzenia, użyj IntersectionOverUnion metody , aby sprawdzić, czy pierwsze pole i drugie pole przekracza określony próg. Dodaj następujący kod do najbardziej wewnętrznej pętli for-loop.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
Poza najbardziej wewnętrzną pętlą, która sprawdza sąsiadujące pola ograniczenia, sprawdź, czy istnieją jakiekolwiek pozostałe pola ograniczenia do przetworzenia. Jeśli nie, przerwij zewnętrzną pętlę for-loop.
if (activeCount <= 0)
break;
Na koniec, poza początkową pętlą for-loop FilterBoundingBoxes metody, zwróć wyniki:
return results;
Świetnie! Teraz nadszedł czas, aby użyć tego kodu wraz z modelem do oceniania.
Używanie modelu do oceniania
Podobnie jak w przypadku przetwarzania końcowego, w krokach oceniania znajduje się kilka kroków. Aby to ułatwić, dodaj klasę, która będzie zawierać logikę oceniania do projektu.
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt, a następnie wybierz polecenie Dodaj>nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Klasa i zmień pole Name na OnnxModelScorer.cs. Następnie wybierz przycisk Dodaj .
Plik OnnxModelScorer.cs zostanie otwarty w edytorze kodu. Dodaj następujące
usinginstrukcje na początku pliku OnnxModelScorer.cs:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;OnnxModelScorerWewnątrz definicji klasy dodaj następujące zmienne.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Bezpośrednio poniżej utwórz konstruktor dla
OnnxModelScorerklasy, która zainicjuje wcześniej zdefiniowane zmienne.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }Po utworzeniu konstruktora zdefiniuj kilka struktur, które zawierają zmienne powiązane z ustawieniami obrazu i modelu. Utwórz strukturę o nazwie
ImageNetSettings, aby zawierać wysokość i szerokość oczekiwaną jako dane wejściowe dla modelu.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }Następnie utwórz kolejną strukturę o nazwie
TinyYoloModelSettings, która zawiera nazwy warstw danych wejściowych i wyjściowych modelu. Aby zwizualizować nazwę warstw danych wejściowych i wyjściowych modelu, możesz użyć narzędzia takiego jak Netron.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }Następnie utwórz pierwszy zestaw metod używanych do oceniania. Utwórz metodę
LoadModelwewnątrzOnnxModelScorerklasy.private ITransformer LoadModel(string modelLocation) { }LoadModelWewnątrz metody dodaj następujący kod do rejestrowania.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET potoki muszą znać schemat danych, który ma działać po wywołaniu
Fitmetody. W takim przypadku zostanie użyty proces podobny do trenowania. Jednak ponieważ nie ma rzeczywistego trenowania, dopuszczalne jest użycie pustegoIDataViewelementu . Utwórz nowyIDataViewdla potoku z pustej listy.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());Poniżej zdefiniuj potok. Potok będzie składać się z czterech przekształceń.
LoadImagesładuje obraz jako mapa bitowa.ResizeImagesponownie skaluje obraz do określonego rozmiaru (w tym przypadku416 x 416).ExtractPixelszmienia reprezentację pikseli obrazu z mapy bitowej na wektor liczbowy.ApplyOnnxModelładuje model ONNX i używa go do oceny podanych danych.
Zdefiniuj potok w metodzie
LoadModelponiżej zmiennejdata.var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));Teraz nadszedł czas, aby utworzyć wystąpienie modelu na potrzeby oceniania. Wywołaj metodę
Fitw potoku i zwróć ją do dalszego przetwarzania.var model = pipeline.Fit(data); return model;
Po załadowaniu modelu można go użyć do przewidywania. Aby ułatwić ten proces, utwórz metodę o nazwie PredictDataUsingModel poniżej LoadModel metody .
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
W pliku PredictDataUsingModeldodaj następujący kod na potrzeby rejestrowania.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Następnie użyj Transform metody , aby ocenić dane.
IDataView scoredData = model.Transform(testData);
Wyodrębnij przewidywane prawdopodobieństwa i zwróć je do dodatkowego przetwarzania.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Po skonfigurowaniu obu kroków połącz je w jedną metodę. PredictDataUsingModel Poniżej metody dodaj nową metodę o nazwie Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Prawie gotowe! Teraz nadszedł czas, aby umieścić to wszystko do użycia.
Wykrywanie obiektów
Teraz, gdy wszystkie konfiguracje są ukończone, nadszedł czas, aby wykryć niektóre obiekty.
Generowanie wyników i analizowanie danych wyjściowych modelu
Poniżej tworzenia zmiennej mlContext dodaj instrukcję try-catch.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
try Wewnątrz bloku rozpocznij implementowanie logiki wykrywania obiektów. Najpierw załaduj dane do elementu IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Następnie utwórz wystąpienie OnnxModelScorer i użyj go do oceny załadowanych danych.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
Teraz nadszedł czas na krok przetwarzania końcowego. Utwórz wystąpienie elementu i użyj go do przetwarzania danych wyjściowych YoloOutputParser modelu.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
Po przetworzeniu danych wyjściowych modelu nadszedł czas, aby narysować pola ograniczenia na obrazach.
Wizualizowanie przewidywań
Po dokonaniu oceny obrazów i przetworzeniu danych wyjściowych należy narysować pola ograniczenia na obrazie. W tym celu dodaj metodę o nazwie DrawBoundingBox poniżej GetAbsolutePath metody w pliku Program.cs.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
Najpierw załaduj obraz i uzyskaj wymiary wysokości i szerokości w metodzie DrawBoundingBox .
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Następnie utwórz pętlę for-each, aby iterować po każdym z pól ograniczenia wykrytych przez model.
foreach (var box in filteredBoundingBoxes)
{
}
Wewnątrz pętli for-each uzyskaj wymiary pola ograniczenia.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Ponieważ wymiary pola ograniczenia odpowiadają danych wejściowych 416 x 416modelu , skaluj wymiary pola ograniczenia, aby dopasować rzeczywisty rozmiar obrazu.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Następnie zdefiniuj szablon tekstu, który będzie wyświetlany powyżej każdego pola ograniczenia. Tekst będzie zawierać klasę obiektu wewnątrz odpowiedniego pola ograniczenia, a także pewność siebie.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Aby rysować na obrazie, przekonwertuj Graphics go na obiekt.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
using Wewnątrz bloku kodu dostosuj ustawienia obiektu grafikiGraphics.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
Poniżej ustaw opcje czcionki i koloru tekstu i pola ograniczenia.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Utwórz i wypełnij prostokąt nad polem ograniczenia, aby zawierać tekst przy użyciu FillRectangle metody . Pomoże to porównać tekst i poprawić czytelność.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Następnie rysuj tekst i pole ograniczenia na obrazie przy użyciu DrawString metod i DrawRectangle .
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
Poza pętlą for-each dodaj kod, aby zapisać obrazy w pliku outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Aby uzyskać dodatkową opinię, że aplikacja wykonuje przewidywania zgodnie z oczekiwaniami w czasie wykonywania, dodaj metodę o nazwie LogDetectedObjects poniżej metody w pliku Program.cs, aby wyprowadzić wykryte DrawBoundingBox obiekty do konsoli.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Teraz, gdy masz metody pomocnicze do tworzenia wizualnych opinii na podstawie przewidywań, dodaj pętlę for-loop, aby iterować na każdym z ocenianych obrazów.
for (var i = 0; i < images.Count(); i++)
{
}
Wewnątrz pętli for-loop pobierz nazwę pliku obrazu i skojarzone z nim pola ograniczenia.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Poniżej użyj DrawBoundingBox metody , aby narysować pola ograniczenia na obrazie.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Na koniec użyj LogDetectedObjects metody , aby wygenerować przewidywania w konsoli programu .
LogDetectedObjects(imageFileName, detectedObjects);
Po instrukcji try-catch dodaj dodatkową logikę, aby wskazać, że proces jest wykonywany.
Console.WriteLine("========= End of Process..Hit any Key ========");
I już!
Wyniki
Po wykonaniu poprzednich kroków uruchom aplikację konsolową (Ctrl + F5). Wyniki powinny być podobne do poniższych danych wyjściowych. Mogą pojawić się ostrzeżenia lub przetwarzanie komunikatów, ale te komunikaty zostały usunięte z poniższych wyników, aby uzyskać jasność.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Aby wyświetlić obrazy z polami ograniczenia, przejdź do assets/images/output/ katalogu. Poniżej znajduje się przykład z jednego z przetworzonych obrazów.

Gratulacje! Udało Ci się utworzyć model uczenia maszynowego na potrzeby wykrywania obiektów, ponownie używając wstępnie wytrenowanego ONNX modelu w ML.NET.
Kod źródłowy tego samouczka można znaleźć w repozytorium dotnet/machinelearning-samples .
W tym samouczku zawarto informacje na temat wykonywania następujących czynności:
- Omówienie problemu
- Dowiedz się, czym jest ONNX i jak działa z ML.NET
- Omówienie modelu
- Ponowne używanie wstępnie wytrenowanego modelu
- Wykrywanie obiektów za pomocą załadowanego modelu
Zapoznaj się z repozytorium GitHub przykładów usługi Machine Edukacja, aby zapoznać się z rozszerzonym przykładem wykrywania obiektów.